基于并行双向门控循环单元与自注意力机制的中文文本情感分类
2020-06-22崔昕阳邵玉斌杜庆治
崔昕阳 龙 华 熊 新 邵玉斌 杜庆治
(昆明理工大学 信息工程与自动化学院, 昆明 650000)
引 言
随着近年来网络信息技术的不断发展,大量的电子文档通过如网页、社交网络、电子邮件和数字图书馆等新兴应用展示在人们面前。在处理如此大量信息的过程中,文本分类已经成为挖掘和分类文本文档的关键技术。文本分类目前已经在许多领域得到了成功的应用与发展,其中最重要的一个领域便是文本情感分类[1]。文本情感分类是情感分析的重要分支之一,也称为意见或观点挖掘,具有巨大的社会和商业价值,可应用于舆情分析[2],使政府了解人们对某一社会事件的情感趋势,也可用于电商的产品评论[3],分析顾客对某一产品的情感态度(如积极或消极),使厂商获得即时的反馈以便进行产品改良和生产量的调整。
早期的文本情感分类方法主要通过构建情感词典,依据词语的情感程度给予不同的分值,最终得到某一文本或句子的情感倾向即为所包含情感词的分值的加权求和。但这种方法不仅需要人工构建大型的情感词典库,也没有考虑到文本中的语义信息。之后的基于机器学习的文本情感分类方法也取得了一定的效果,如朴素贝叶斯和支持向量机等算法[4]。但传统的机器学习方法通常采用词袋模型进行文本表示,忽视了词语的位置信息和词之间的关联信息,且存在文本向量稀疏、维度过高和需要进行特征选择等问题。近年来,许多学者采用深度学习方法进行情感分类研究,并取得了较好的效果[5]。神经网络模型主要包括卷积神经网络(convolutional neural networks, CNN)和循环神经网络(recurrent neural network, RNN)两大类,其中RNN主要是指长短时记忆(long short-term memory,LSTM)网络和门控循环单元(gated recurrent unit, GRU)网络。对于基于深度学习的文本情感分类研究,对词语进行低维、非稀疏的向量学习表示是极为关键的步骤[6],这个过程也称词嵌入。词向量是指词语经过词嵌入过程得到的低维稠密的向量,其可以有效表征词语的语义信息[7],在自然语言处理领域中被广泛应用,而当前使用最为广泛的词向量生成工具是Word2vec。
目前通常使用预训练的词向量表示文本,从而作为神经网络的输入来对文本进行情感分类。预训练的词向量一般采用Word2vec工具依据原语料或通用语料训练生成,其中原语料为所要研究的情感分类数据集,而通用语料则是由人工整理所得的大型文本数据集,如维基百科、新浪新闻等数据集。由于原语料与通用语料相比数据量较小[8],网络往往不能得到充足训练,而导致生成的词向量语义表征能力较差以及模型泛化能力较差[9]。而由通用语料预训练生成的词向量语义表征能力较强,但是存在未登录词问题,即原语料中的某些词语不存在与之对应的词向量。关于未登录词的解决方法,目前主要采用词向量随机初始化或补零来对未登录词进行表示[9-10]。然而上述解决方法在对文本表示过程中都存在信息量丢失的问题,即不能完全表示文本原有语义信息,从而影响最终的分类效果。因此,本文提出一种并行双向GRU模型,充分利用两种词向量进行文本表示以解决原文本信息丢失问题,通过上下两个通道来学习文本中词语的上下文信息并结合自注意力机制进行情感分类,并通过实验验证了该模型的分类性能。
1 文本情感分类与Word2vec
1.1 文本情感分类
文本情感分类是指通过计算机技术挖掘文本所表达的情感倾向[11]。当前采用深度学习与神经网络进行文本情感分类研究已经成为主流,其优势在于无需人工特征选择,机器可自动进行特征提取[12]。深度学习技术早期主要应用于图像和音频处理,而随着词向量的普遍使用,深度学习开始被广泛应用于自然语言处理领域。在基于深度学习的文本情感分类方法中,CNN的优势在于可以有效提取局部特征。而相较于CNN,RNN具有记忆单元,由于当前时刻输出不仅与当前输入有关,更与过去时刻有关,所以其更适用于处理时序数据。学者们针对如何将这两种模型更好地应用于文本分类进行了大量的研究。Kim[13]使用预训练的词向量对文本进行表示,并尝试通过不同尺寸卷积核的CNN来解决文本分类任务,在不同数据集上取得了良好的分类效果。Parwez等[14]提出一种利用两种不同领域预训练的词向量的双通道CNN模型进行文本情感分类,并探究了通道结合方式。Socher等[15]使用RNN进行了电影评论情感分类研究。Nabil等[16]使用GRU进行情感分类,在英文推文数据集上取得了一定效果。Jabreel等[17]使用双向GRU来识别给定推文中特定目标的情感极性。杨玉娟等[18]提出一种加权词向量的LSTM模型,从而突出文本情感分类中关键词的作用。Lai等[19]结合两者优点,首先采用双向RNN学习词语的上下信息,并通过最大池化层来捕捉全文最重要的信息,再进行文本分类。注意力机制由于具有可以发现重要特征的特点,将该机制与神经网络模型相结合可更有效地进行特征提取。Yin等[20]将注意力机制与CNN结合来对句子进行建模,效果优于传统神经网络模型。Padi等[21]使用GRU并结合注意力机制用于文本语言的识别,取得一定效果。Zhou等[22]提出基于双向LSTM和注意力机制的网络模型来进行关系分类。韩虎等[23]通过注意力机制来计算不同词和句子的权重,获取词级和句子级的文本语义信息进行文本情感分类,分类准确率较其他模型有所提升。江伟等[9]采用注意力机制来学习文本中由不同词构成的短语权重,使得文本的语义表示学习更加准确,在多个英文数据集上取得了当前最好的文本分类效果。吴小华等[24]提出基于自注意力和双向LSTM的文本情感分析模型,由于自注意力机制(self-attention)参数依赖较少,最终分类效果优于其与注意力机制结合的方法。
当下大部分研究均注重于通过调整模型结构来更深层次挖掘文本语义信息,而忽视了不同词向量对文本语义表达的影响。本文借鉴Parwez等[14]的研究思路,通过两种词向量对文本进行表示。原语料生成的词向量可解决未登陆词问题,而通用语料生成的词向量具有较强的表征和泛化能力,结合两者优点,使用双向GRU来对两者表示的文本进行词语上下文信息的学习,并结合自注意力机制学习词语权重;随后通过并行向量融合来充分保留原文信息,从而进行情感分类。
1.2 Word2vec
Word2vec是目前最为广泛使用的词嵌入工具,它使用跳词模型(skip-gram model)或连续词袋模型(continuous bag-of-words model)来生成词向量[7]。对于一个中心词,跳词模型的目的是预测其上下文词语。在数学上,对于一个词语序列{w1,…,wt,…,wT},跳词模型的目标函数是优化平均对数概率,如式(1)所示。
(1)
式中c代表固定的上下文窗口尺寸。
2 基于并行双向GRU网络与自注意力机制的网络模型
本文所提出的网络模型具体结构如图1所示。
首先利用原语料和通用语料训练生成两种词向量,分别经过不同通道对同一文本进行表示,然后通过并行的双向GRU学习不同词向量表示的文本的词语上下文信息,再采用自注意力机制学习词语权重也即找出关键词进行关键词加权,然后通过向量融合对不同通道得到的文本加权向量表示进行融合,最后经过全连接层使用Softmax激活函数进行情感判定。
2.1 词嵌入层
通过词嵌入层,即使用不同的词嵌入模型将文本中的词转换成对应的向量,捕捉文本的语义信息,形成文本的向量表示。设输入的文本序列为T={wi,…,w|T|},其中每个词语w都来自于词汇表V={w1,…,w|v|}。在词嵌入矩阵W∈R|v|×d查找文本中每个词对应的向量表示x∈R1×d,其中d表示词向量的维度,则此时文本序列T的向量表示为{xi,…,x|T|}∈R|T|×d。
与传统模型不同,本文模型采用并行结构,在词嵌入层通过两个独立词嵌入矩阵Wo、Wp分别表示同一文本序列T,如式(2)和(3)所示。
(2)
(3)
2.2 双向门控循环单元层
Cho等[25]提出的GRU网络是LSTM网络的一种简化变体。GRU仅由重置门和更新门组成,从而调控信息的流动,并没有单独的记忆单元。GRU和LSTM的性能相近,且GRU网络参数更少,可在一定程度上降低过拟合的风险[26],因此本文选用GRU网络。GRU的基本结构如图2所示。
图2所示的标准GRU网络结构由式(4)~(7)定义。
(4)
zt=σ(Wzxt+Uzht-1+bz)
(5)
rt=σ(Wrxt+Urht-1+br)
(6)
(7)
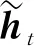
ht=[ht1,ht2]
(8)
2.3 注意力层
注意力机制在开始被应用于自然语言处理领域,最早在机器翻译任务中取得了不俗的效果。注意力机制的主要目的是找出隐藏状态中较为重要的特征,即对RNN每一时刻的输出的重要程度进行判定,从而对每一时刻的输出加权。本文采用自注意力机制对BiGRU中每一刻的隐藏状态的权重进行学习。自注意力的具体计算方法如式(9)、(10)所示。
(9)
(10)
(11)
2.4 向量融合层
不同于传统的序列型网络结构,本文采用并行的双通道结构,对于同一输入在上下两通道使用两种不同的词向量表示。通过上下两个通道的BiGRU和注意力层后可得到同等维度的加权输出向量co和cg,在向量融合层对两个向量并行融合,其中co和cg分别为对上下两个通道的文本表示To和Tp进行上下文信息学习和隐状态权值计算后的最终加权向量表示。对于两个通道的加权输出向量,本文采用拼接(concatenate)和平均(average)两种不同的运算操作进行向量融合,提出了两种模型结构,并就其情感分类效果进行比较。
2.4.1SAT-BiGRU-CON结构
模型SAT- BiGRU- CON采用concatenate运算操作进行向量融合,如式(12)所示。
v=co⊕cg
(12)
式中符号⊕表示向量的拼接操作即向量和,v为经过向量融合层的最终文本向量表示,并作为全连接层的输入向量。
2.4.2SAT-BiGRU-AVA结构
模型SAT- BiGRU- AVA结构与模型SAT- BiGRU- CON类似,其融合向量co和cg采用对应元素相加取平均的计算方法,如式(13)所示。
(13)
同样,此时的最终文本向量表示v将作为全连接层的输入向量。
2.5 全连接层
模型最后一层为全连接层,输入为特征融合层的输出,该层的输出为类别的概率分布。类别的概率分布通过Softmax激活函数计算得出,具体算法如式(14)所示。
(14)
式中wk和bk分别为权重和偏置向量,K为类别数,对于二分类问题,K=2。
3 实验分析
3.1 实验数据与环境
为验证模型有效性,选用两个公共数据集进行实验。数据集1是公共中文数据集[6],该数据集由酒店评论文本构成,共包含6 000条数据,分为正向和负向两类各3 000条评论文本。数据集2为NLPCC2014任务2中文情感分类数据集[27],由正、负向各5 000条网络商品评论文本组成。两个数据集的部分文本内容如表1所示。本文在两个数据集上均采用5折交叉验证进行实验。

表1 数据集1和数据集2部分示例
全部实验均在Google Colaboratory上完成,其为谷歌开发的一款云计算平台,主要用于机器学习的开发与研究。平台操作系统为Ubuntu 18.04.2,内存12 GB,GPU为Tesla K80。采用Python语言以及Keras框架实现本文所提模型,Python版本为3.6.8,Keras版本为2.2.4。
3.2 评价指标
本文采用传统的文本分类评价标准,包括查准率P(precision)、查全率R(recall)、准确率A(accuracy)和F1值[28]。
(15)
(16)
(17)
F1值为查准率和查全率的调和均值,用于对查准率和查全率进行整体评价。
(18)
式中,TP为被正确判定为正向的文本个数,FP为被错误判定为正向的文本个数,FN为被错误判定为负向的文本个数,TN为被正确判定为负向的文本个数。
3.3 超参数设定
固定输入文本的长度,对于数据集1最大长度设置为60,数据集2最大长度为50。若文本长度大于该值则进行截断,小于该值则进行补零。每个BiGRU的隐藏层节点数为128。为防止过拟合,Dropout设置为0.5。采用Adam优化器进行参数更新,初始学习率(learning rate)为0.001,批处理数量(batch size)为32。
3.4 实验预处理
3.4.1数据预处理
采用Jieba分词工具分别对数据集1酒店评论文本和数据集2网络评论文本进行分词,词与词之间用空格隔开,完成分词的文本数据集作为词向量的训练语料。
3.4.2原语料词向量构建
完成数据预处理后,分别对两个数据集生成的训练语料使用Word2vec工具生成原语料的词向量,从而构建词嵌入矩阵。本文选择Word2vec中的skip- gram模型来预训练原语料生成词向量,上下文窗口尺寸设置为5,采用负采样算法进行模型训练,剩余参数的设置为默认值。Word2vec的具体参数值设置如表2所示。

表2 Word2vec具体参数设置
3.4.3通用语料词向量
通用语料词向量选择则使用Chinese Word Vector中的中文维基百科预训练词向量[8],该预训练词向量同样采用skip- gram模型生成。
3.5 实验设计
将所提模型与多个模型进行对比,参数设置与本文相同,均采用通用语料的预训练词向量。对比模型主要包括以下几种模型。
(1)GRU 采用标准的GRU网络对文本进行情感分类[16]。
(2)BiGRU 采用BiGRU网络,同时从正向和逆向两个方向对词语进行上下文学习,然后预测情感类别[17]。
(3)双向长短时记忆网络(bidirectional long short-term memory, BiLSTM)模型 采用BiLSTM网络进行情感类别判定,与BiGRU结构类似。
(4)基于预训练词向量的双向门控循环单元与自注意力机制结合的网络模型(SAT- BiGRU) 通过通用语料的预训练词向量来表示文本,并采用BiGRU网络进行词语上下文学习,结合自注意力机制对每一时刻状态进行学习,给予不同权重,最终得到文本的加权向量表示来进行类别判定。
(5)基于原语料预训练词向量的双向门控循环单元与自注意力机制结合的网络模型(SAT- BiGRU- ORG) 结构与SAT- BiGRU相同,不同点在于使用原语料构建的词向量对文本进行表示,作为BiGRU的输入。
(6)SAT- BiGRU- CON与SAT- BiGRU- AVA 即本文所提出的两种模型,基于BiGRU网络,通过双通道对两种不同词向量表示的文本进行语义学习,并结合自注意力机制学习隐藏状态的权重分布。对于两个通道的加权输出向量,分别采用concatenate和average两种方法进行向量融合。
3.6 结果分析
从表3和表4的结果可以看出,本文所提出的两种模型SAT- BiGRU- CON和SAT- BiGRU- AVA均达到了最好的分类效果,即使用两种词向量对文本进行表示作为神经网络的输入,获得的分类效果要优于传统序列模型。同时采用自注意力机制可进行每一时刻的隐状态进行加权,获得更加精准的文本向量表示。与采用单一语料的SAT- BiGRU和SAT- BiGRU- ORG模型相比,在两个数据集上分类效果均提升明显,其中在数据集1上准确率分别提高1.5%和1.75%,同时F1值也有明显提升;数据集2上则最多分别提高了1.80%和1.85%。这说明通过上下两个通道采用通用语料和原语料两种词向量对文本进行表示,然后进行词语上下文信息学习和特征加权,可有效弥补采用单一语料对文本进行表示存在的不足,既充分利用预训练词向量的泛化能力,也使原语料训练词向量不存未登录词的优点得以发挥,从而使准确率和F1值均有所提升。
而通过表3和表4中SAT- BiGRU与SAT- BiGRU- ORG的实验结果对比也可以看出,采用通用语料预训练词向量的模型分类结果要略微好于原语料训练词向量,主要原因是通用语料文本数量较多,学习到的词向量用于网络学习,得到的模型泛化能力较强。但由于中文语料存在分词等问题,通用语料会存在未登录词,所以相对原语料来说,不能较好地对文本进行表示。从而在两个数据集上的实验效果来看,两者差异较小,只是采用通用语料预训练词向量分类效果较优。
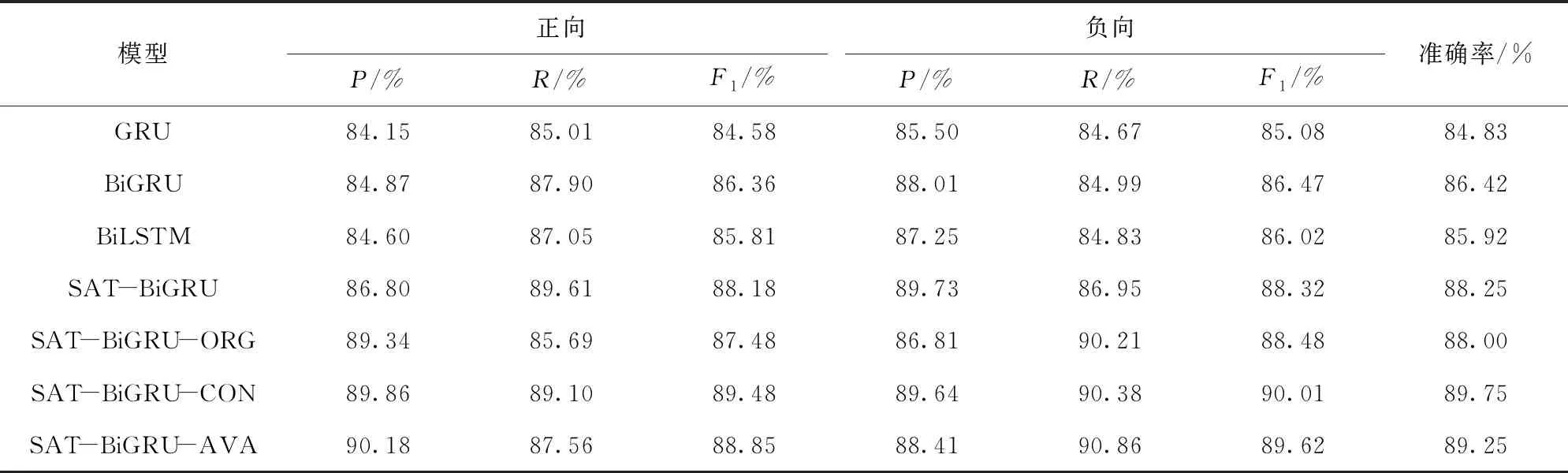
表3 酒店评论数据集下不同模型的实验结果
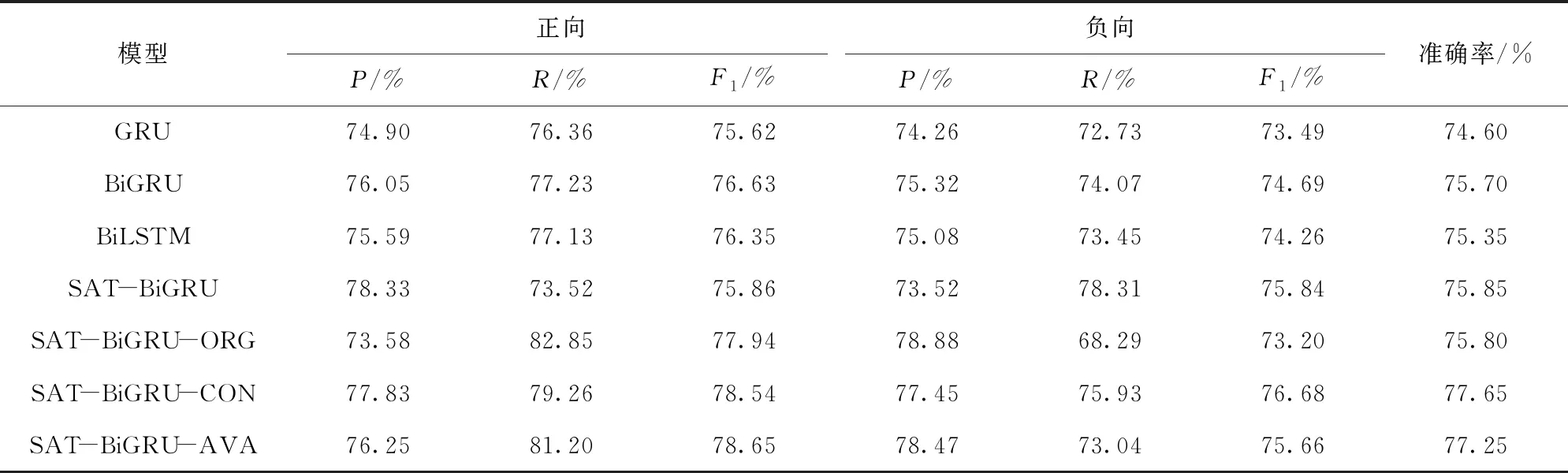
表4 商品评论数据集下不同模型的实验结果
同时,SAT- BiGRU- CON比SAT- BiGRU- AVA在两个数据集上的分类准确率分别高出0.4%和0.5%,说明采用concatenate操作来进行向量融合相对来说要较优于average操作。原因主要为concatenate操作完全保留了上下两个通道输出的特征加权向量所蕴含的信息,而average操作在运算过程中使某一通道输出向量所含的原始信息产生了损失,所以两者在最终分类效果上产生了微小的差异。
4 结束语
为解决神经网络采用单一预训练的词向量存在未登录词和词语语义学习不充分的问题,本文提出了一种基于并行双向GRU与自注意力机制的情感分类模型,使用原语料和通用语料预训练的两种不同词向量对文本进行表示,作为双向GRU网络的输入;通过上下两个通道分别对文本进行词语上下文信息的捕捉,得到表征向量,再依靠自注意力机制学习每一时刻隐状态权重,最后对双通道的加权输出向量进行向量融合,作为输入进入全连接层来判别情感倾向。在中文酒店评论和网络商品评论两个数据集上进行的相关实验表明,本文所提模型可更好地对文本进行表示并提取特征,相比于其他模型,本文模型具有更好的分类效果。
然而,目前分词技术未能达到100%的准确率,且网络文本的表述并不规范,导致文本在分词后语义发生转变,从而对分类效果产生消极影响。所以在下一步的工作中,将会关注字向量对文本情感分类的影响。
