一种基于统计的地质专业词语识别方法
2020-06-19王宏朱学立曾涛乔东玉郭甲腾
王宏 朱学立 曾涛 乔东玉 郭甲腾


摘要:中文分词是地质大数据智能化知识挖掘难以回避的第一道基本工序。基于统计的分词方法受语料影响,跨领域适应性较差。基于词典的分词方法可以直接利用领域词典进行分词,但不能解决未登录词识别问题。在领域语料不足的情况下,为提高地质文本分词的准确率和未登录词识别率,提出一种基于统计的中文地质词语识别方法。该方法基于质串思想构建了地质基本词典库,用以改善统计分词方法在地质文本分词上的适应性。采用重复串查找方法得到地质词语候选集,并使用上下文邻接以及基于位置成词的概率词典,对地质词语候选集进行过滤,最终实现地质词语识别。实验结果表明,使用该方法对地质专业词语识别准确率达到81.6%,比通用统计分词方法提高了近60%。该方法能够识别地质文本中的未登录词,并保证地质分词的准确率,可以应用到地质文本分词工作中。
关键词:地质文本;中文分词;质串;重复串;上下文邻接;位置成词概率
DOI: 10. 11907/rjdk.191648
开放科学(资源服务)标识码(OSID):
中图分类号:TP391
文献标识码:A
文章编号:1672-7800( 2020)004-0211-08
0 引言
地质大数据是信息时代背景下大数据理念、技术和方法在地质领域的应用与实踐,地质调查工作是获取地质大数据的主要途径。地质调查工作产生了诸如地质图件、文本、表格等类型资料。目前,基于大数据平台的非结构化地质数据组织、存储和快速发现问题已基本得到解决,但在此基础上构建智能化的地质知识挖掘系统仍需探索。
文本是地质大数据重要的数据形式,自然语言是文本信息的重要载体。词是最小的能够独立运用的语言单位…,但由于中文词汇之间没有明确的分界符,需要先进行分词才能作进一步的自然语言处理[2]。从信息处理角度看,地质文本是利用自然语言编写的地质特点鲜明的语义数据[3]。中文分词是智能化地质知识挖掘基础,对地质文档全文检索、文本分类、自动文摘、地质文档信息抽取及自动翻译等应用具有重大意义。
在通用领域分词中,基于统计的分词方法应用广泛。隐马尔科夫模型( Hidden Markov Model,HMM)[4]、条件随机场模型( Conditional Random Fields,CRFs)[5]和最大熵马尔科夫模型( Maximum Entropy Markov Model,MEMM)[6]等是统计分词方法中主要的分词模型。在专业领域分词中往往存在大量的专业词汇,使得分词效果不佳。为了改进专业领域中文分词效果,学者们开展了大量研究工作。如Huan等[7]采用一种新型的个性化分词词典对网络个性化服务中用户的浏览文档进行分词。该方法受专业词典所限,对未被收录进词典中的词汇识别率较低;Qi等[8]将专业词典特征与字向量相结合,使用神经网络模型解决跨领域分词适应性问题,但该方法受训练语料影响较大。Bao等[9]通过使用双向马尔科夫链对正向最大匹配算法和词频统计算法进行改进,实现对特定领域文本快速、较为准确的分词,但没有考虑词语的上下文信息,分词效果仍有改进空间。
中文分词技术在地质领域应用不够广泛,相关研究不多。Lan等[10]基于条件随机场模型构建了针对地学领域的分词方法,较好地识别出地质矿产类术语,但其采用自定义的方法对训练语料进行标注,在语料库标注、定义规范程度方面有待提高。陈婧汶等[11]使用一种基于双语料库条件随机场模型方法对地质矿产文本进行分词,取得了较好的分词效果,但所采用的语料规模较小,分词性能仍有改进空间。通常情况下,获取大量、规范的领域语料进行模型训练较为困难。因此,针对地质领域语料不足的情况,如何准确识别出地质专业词语从而获得较好的分词效果值得研究。本文基于质串思想构建地质基本词典库,对通用分词器的核心词典库进行扩充,在此基础上提出一种基于统计的中文地质词语识别方法。采用重复串查找方法得到地质词语候选集,使用上下文邻接以及基于位置成词的概率词典对地质词语候选集进行过滤,最终实现对地质词语的识别。
1 中文地质文本分词
1.1 中文分词技术
汉语中的汉字是书面表达的最小单位,但在含义表达和相关信息处理中,词才是最小的语言成分。在汉语文本中,将词与词之间加上区分标记是中文分词的主要目的,也是任何中文自然语言应用都必须进行的第一道基本工序[12]。只有完成了汉语文本的自动分词,才能采用各种后续语言分析手段实现相应的智能应用。目前中文分词已被应用在信息检索、自动文摘、机器翻译、同音字和多音字识别、文本校对、搜索引擎等方面。
基于词典的机械分词、基于语法和规则的分词以及基于统计的分词,是中文分词领域的3种分词方法。基于词典的机械分词在分词过程中利用词典作为主要资源,将文档中的字符串在词典中进行查找。如果找到,则进行切分,否则不予切分。由于可以利用相关领域的专业词典,因此该方法具有较高的领域自适应性,但不能很好地解决未登录词识别以及分词歧义问题,而且词典的完备性不能得到保证。基于语法和规则的分词法,其基本思想是在分词的同时进行句法、语义分析,利用句法信息和语义信息进行词性标注,以解决分词歧义现象。因为语法知识、句法规则十分复杂,基于语法和规则的分词法所能达到的精确程度远远不能令人满意[13]。基于统计的分词法是目前自然语言处理领域的主流分词方法,该方法在已经切分好的分词语料库基础上进行统计训练,建立语言模型并最终实现分词解码。在跨领域使用统计分词方法时,必须根据相应领域的分词训练语料进行语言模型训练,但是分词训练语料需要大量专业人员参与,获取代价高昂。
1.2 中文地质文本特点
地质文本指在各类地质工作中产生的文字性材料,包括各类地质报告、科技文献、观测记录、质量检查记录以及质量体系运行的相关材料等。本文的地质文本包括各类地质报告、地质科技文献等技术性文字材料。地质报告是完成下达的地质工作任务后,在系统整理和综合研究各种相关资料基础上编写的反映地质工作成果的重要技术文件。地质科技文献是分析、研究、阐述地质科学技术问题的文章,是地质研究成果的书面表达,是地质客观事物和科学规律的总结与阐释[14]。
地质文本相较于一般技术性文本,不仅具有结构严密、逻辑关系明显、语言严谨、陈述客观等特点,还具有其自身特点。
(1)地质文本内容涉及知识面广,领域众多。地质学涉及学科广泛,理论知识庞大、纷繁复杂。诸如自然科学中的数学、物理、化学,社会科学中的哲学、历史等,都与地质学研究紧密相关,形成一系列交叉学科,如数学地质、地球物理、地球化学、地史学等[15]。同样,地质工作涉及多种工作手段,如地质填图、钻探工程、物探、化探、岩矿测试等。一项地质工作往往需要通过多种工作手段的实施才能得以完成,因此所形成的地质文本内容涉及专业领域众多,知识面广。
(2)地质文本形式多样。地质文本源于地质工作的实施,地质工作性质决定着地质文本的性质。地质工作实践性很强,在地质工作实施过程中,会产生不同类型的地质文本,如在固体矿产勘查工作实施过程中,会形成地质填图、剖面测量、探矿工程、采样及样品测试分析等工作手段相关的技术类文档资料。在同一工作手段下,也往往包含不同种类的地质文本,如在开展地质填图工作过程中会产生各类野外记录,包括地质观察点记录、实测剖面记录、重砂取样记录、物化探测量记录、物化探取样记录、矿产调查记录等。
(3)地质文本中包含了海量专业词汇。地质学作为自然科学的一大分支,經过长期的认识和探索,形成了一个相对独立的学科体系,包含了大量富有学科特色的专业术语。如文献[16]在地质专业词汇中,矿物名称、岩石名称、化石(古生物)名称占比很大。以岩石名称为例,在沉积岩、变质岩、岩浆岩基础上细分而来的岩石种类有上千种。同时,由于采用的分类方法不同而产生更加繁多的岩石命名。地质学在与不同学科的交叉渗透中形成了众多边缘学科,这些学科的兴起增加了地质词汇量[17]。
(4)地质文本具有专业的表达形式。任何一门学科都有其特有的表达形式,如化学用分子式表述、电学用正负号表述、数学用方程式表述等。在地质文本中,除了使用自然语言外,还需要大量使用图、表、符号、公式等。其中,图表是地质文本常见的两种表述方法。在地质文本中,表格具有形式简洁、内容丰富、信息可靠、层次清晰等特点,常用来表达背景条件、比较前提、使用方法、实测(或实验数据)、统计资料、误差分析、对比分析等内容。地质图件是地质成果的载体,是地质文本的核心内容,也是地质学最好的表述方式。只要有地质工作,就必然要编绘地质图件,哪里有地质工作,哪里就有地质图件[8]。很多实际应用中,仅靠对文字报告的理解掌握相应的地质资料是比较困难的。相反,一张精确的图件,再配以文字表述才能更好地理解资料。
(5)客观陈述性描述(定性与定量描述)。观察经验事实并加以归纳的认识方法是地质学的基本方法[18],在地质文本中存在大量的定性描述,如在描述一块岩石时,主要从岩石的颜色、结构、构造、主要矿物组成等方面进行描述并获得岩石定名。在地质研究中,只做到定性描述地质现象是不够的,除定性叙述外,还应该有严密的量化数据,比如矿物成分、地质体厚度、矿体品位等。在地质工作过程中,定性描述与定量描述是相互统一、互为补充的。例如,在岩石描述与定名中,除了强调从岩石的各个特征进行描述外,还需要对矿物成分做估算,这有助于提高岩石定名的准确度。
1.3 地质词语特征
地质学是完全由国外输入的一门近代科学[19],因此地质词语中有相当一部分词来自外文直译,如角闪岩、花岗岩、白垩、侏罗、三叠等。与此同时,在地质学发展过程中,有许多名词实际上是物理化学生物及其它有关学科借用而来的,特别常见于矿物和古生物名词,如矿物学中的大批化学名词、结晶学中的几何名词。相关学科对地质学影响很大,不但借用了许多名词,甚至连造名词方法也全部应用。如古生物学上的命名法仍然完全采用生物学上的命名法,即用希腊文用作属名拉丁文用作种名。
地质学经过不断发展产生了大量地质专业词汇,形成了一套严密的命名原则和方法,具有明显的专业性、科学性、简明性和系统性。例如,岩石地层单位可分为正式岩石地层单位(群、组、段、层等)和非正式地层单位(带、凸镜体、岩丘、礁等),非正式岩石地层单位的地理专名不能与“组”、“段”、“层”等术语连用,以区别正式地层单位。
中文地质词汇在构成上遵循汉语规律,大部分词语都是由单音节或双音节构成的,富有汉语特征,简明扼要而含意深刻。有的一字、一词都确切反映出概念的分化原则,清晰地区分出一事物与它事物的不同,表达出事物的特征和属性。地质词汇包含大量的复合词,在这些复合词中,绝大多数是复合名词。在地质词汇中的复合名词(如:地质罗盘、盐丘、钻头等)中,前一个组成部分通常是修饰词,词性多为形容词、名词、动词等,后一个组成部分为被修饰词。除此之外,在地质名词中,往往包含地名、人名,如太原组、山西组、郯庐断裂等。
1.4 地质文本分词粒度
文本应用目标不同,对分词的要求也不同甚至是矛盾的,当前技术水平还做不到百分之百的正确切分。汉语中词语或词组的界定还没有统一确定的标准,从而导致不同的信息处理场景对切分标准有不同要求。
一般将中文分词分为两个粒度:①粗粒度切分,将词语作为语言处理最小的基本单位进行切分;②细粒度切分,不仅对词汇进行切分,还要对词汇内的语素进行切分。
例如:原始串:河南省西南部为南阳盆地,具有明显的环状和阶梯状地貌特征。
粗粒度切分:河南省/西南部/为/南阳盆地,具有/明显的/环状/和/阶梯状/地貌特征。
细粒度切分:河南省/西南部/为/南阳/盆地,具有/明显的/环状/和/阶梯状/地貌/特征。
在实际应用中,粗粒度切分和细粒度切分都有使用范围。粗粒度切分主要用于自然语言处理的各种应用,而细粒度切分常应用于搜索引擎。对于地质文档检索系统,常用的方案是在索引时使用细粒度分词以保证查全率,在查询时使用粗粒度分词以保证查准率。
2 识别方法
基于统计的分词方法在跨领域应用方面存在较大缺陷,而基于词典的方法由于可以直接使用相应领域的词典进行分词,具有较强的领域适应性,且领域专业词典的获取相比语料库而言要容易很多。因此,如果把这两种方法结合起来,采用统计的方法合理应用词典,则可实现对地质专业词语的正确切分。
基于统计的分词方法是目前自然语言处理领域的主流分词方法,比较有代表性的分词系统为ICTCLAS分词系统、Ansj中文分词系统、结巴分词等。如果直接使用通用分词器对地质专业文档进行分词,分词效果往往不佳,主要表现为以下3点:①由于通用分词器所使用的核心词典对地质专业词汇覆盖不全,即便是最基础的地质词汇往往也不能正确切分,所以在这些切分错误中往往会存在分词碎片,如包含一些被切分开来的两个或两个以上的连续单字,一般情况下这些单字组合就是一个地质词汇;②新词判别问题。地质分词是一个反复迭代过程,在这个过程中,需要不断将发现的新词收录到词典当中。基于统计的中文分词器往往具有新词发现功能,需要解决如何判断这些新词是否正确;③有意义串的提取问题。在地质领域中,重要的命名实体包括地层名、岩石命名、断裂名、构造名、矿体名、矿带名等。地质作为一门实践性很强的自然科学,其研究对象通常具有一定的空间特征,这种特征在地质实体命名时也有所体现,如“东昆仑山多金属矿带”、“中天山成矿带”、“栾川钼(钨)矿床”、“龙河林场一满归断裂”等,这些词汇属于地质术语范畴,是对特定地质体的表述,在语义上具有唯一性,在领域内往往不能拆分理解,如“栾川钼(钨)矿床”往往不能理解为“栾川的钼(钨)矿床”。有意义串的提取对提高大数据环境下地质文档查准率具有重要意义。
上述3个问题在自然语言处理领域属于新词识别问题。在地质文档中,具有地学意义的地质词语或短语在文档中会多次使用,即会在文档中反复出现。因此,找出文档中的重复串,便可得到地质词语的候选集合。基于统计的分词法受统计模型影响,大多只能发现4个字以内的词语。基于规则的分析法领域局限性大,如果切换领域就需要重建规则,而通过重复串查找获得的地质词语候选集合不局限于字数和领域。
重复串查找分为基于字的重复串查找及基于词的重复串查找,基于词的重复串查找需要预先对文本进行切分。本次地质词语识别建立在通用分词器切分结果的基础上,因此采用基于词的重复串查找。在使用通用分词器进行切分时,地质词语一般都是被切散,分为以下4种情况:①被切分为单字之间的组合。例如:“区调”被切为“区/调”,“水工环”被切分为“水/工/环”;②被切分为多字词和单字的组合。例如:“古侵入体/”被切分成“古/侵入/体”,“三叠系”被切分成“三叠/系”,“倒转背斜”被切分成“倒/转/背斜”;③被切分为多字词之间的组合。例如:“中国地调局”被切分成“中国/地调局”,“河南省地质调查院”被切分成“河南省/地质/调查院”;④在切分结果中,本应组合成词的多个字与其它字/词组合。例如:“太古宇太华岩群”在切分时切成“太/古宇太华/岩群”,“煤窑沟组”切分成“煤窑/沟组”,“变长石石英砂岩”切分为“变长/石石英砂岩”。
对于前3种情况,当新词在文档中出现不少于两次时,采用重复串查找就可得到。在少量文档下进行地质词语提取时,第4种情况会影响词语发现,这种情况的发生与分词器所使用的语言模型相关。地质分词是一个反复迭代的过程,在这个过程中,分词结果也处于动态修正状态。
虽然重复串查找可以发现文档中出现次数很少的新词,但由于词与词之间的搭配非常多,因而在所获得的集合中存在較多垃圾串。在地质文档中,重复串不仅包含了地质术语,还存在大量垃圾串。地质专业词语识别的实质就是在重复串发现的基础上过滤掉无意义的垃圾串。垃圾串一般分为3类:①冗余子串,例如“碳酸盐”这样的串包含在“碳酸盐岩”中;②有意义串和常用字的组合,如“的地台型基底”;③频繁功能串,如“这是”、“其为”等。对于第一类垃圾串的判断需要依赖它的外部使用环境,采用上下文邻接分析识别。后两类垃圾串的判断要从串本身结构着手,通过字的位置成词概率进行判断、分析。
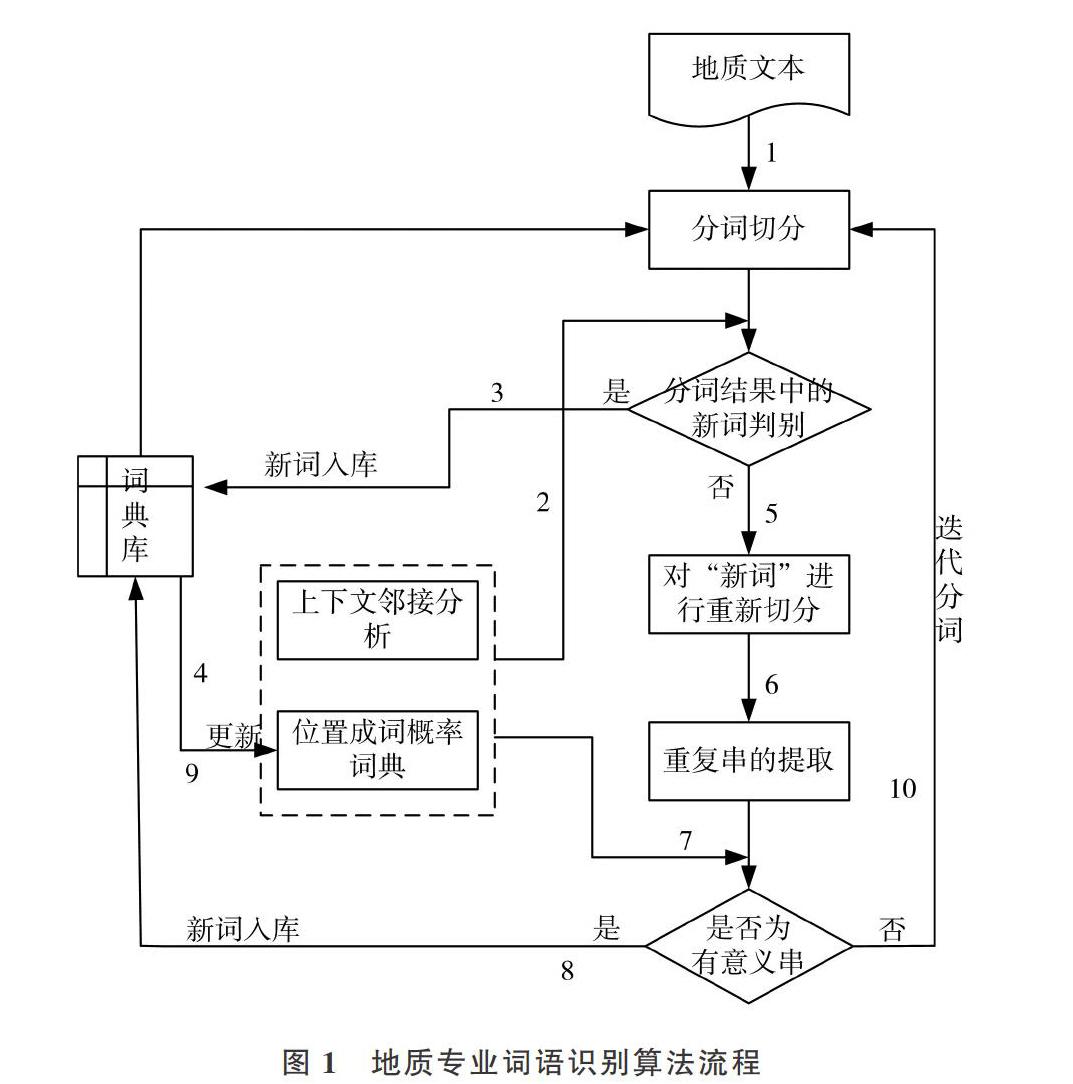
为解决上述3方面问题,本文基于统计方法对地质命名实体进行提取。分词流程如图1所示。
①首先对地质报告进行预处理,转换为txt文本格式,使用Ansj分词工具进行分词,并执行第②步;②提取分词中的新词,并采用上下文邻接分析和基于字的成词概率词典进行新词判别,并执行第③步或第⑤步;③当在第②步中判别为新词时,新词入库,执行第④步;④更新基于字的成词概率词典,执行第⑤步;⑤当在第②步中判别不是新词时,对该词进行分词,并将结果写入文档切分结果中,执行第⑥步;⑥在文档切分结果中提取重复串,形成有意义串候选集合,执行第⑦步;⑦对候选有意义串采用上下文邻接分析和基于字的成词概率词典进行判别;执行第⑧步或第⑩步;⑧当在第⑦步中判别为有意义串时,更新词典库,执行第⑨步;⑨更新基于字的成词概率词典,执行第⑩步;⑩当所有候选有意义串判别完毕后,执行第①步,迭代进行下一次分词。
3 基于质串的地质基本词典库构建
词语根据词形可分为质词和合词。质词不可再分解为更小的词语,例如“珠穆朗玛”一词,任何组合(“珠穆”或“朗玛”等)都不是词。合词是由质词组合而成的词语,例如“社会保障体系”是由“社会”、“保障”和“体系”3个质词组合而成[20]。
在中文分词系统中必须有一个核心词典,无论是标准分词还是命名实体识别都离不开词典提供的词汇和语言模型资源。核心词典中包含的词汇越多,能够正确分词的语料范围就越大。地质基本词典库是对核心词典的补充,能够保证通用分词器对常用地质词汇的正确切分,便于后续处理。
在地质基本词典收录方面并不是地质术语越长越好。正如前面所述,分词单元粒度大小需要考虑到查全率和查准率的矛盾。本文以《地质矿产术语分类代码》(GB9649-1988)为基础,构建了一个地质基本词典库,用以满足在智能地质调查大数据应用体系下对地质文档的查全率要求。通过重复串提取以及相关统计分析方法,提取地质有意义串以满足查准率要求。
3.1《地质矿产术语分类代码》(GB 9649-1988)分析
《地质矿产术语分类代码》(CB 9649-1988)(以下简称“CB9649”)分为35个部分,涵盖了宇宙地质学、地球物理学、火山地质、地震地质、外动力地质学等地质学领域各个方面。GB9649共包含词语102 433个,地质专业词语可分为二字词、三字词以及多字词(四字词、五字词等等),按词长进行分类如图2所示。
地质词典库主要应用方向是在大数据环境下的地质文档检索,为提高地质文档查全率,倾向于分词单位较小化。当地质词语长度大于4时,往往由多个二字词或三字词组成(例如:地质勘探、俯冲构造等)。本文采用质串思想,对GB9649中的地质词语进行分类,收录符合质串特征的地质词语用以构建地质基本词典库。
3.2 基于质串的地质基本词典库构建
(5)合串。若串S有不少于3种的串分解时(自分解、单字分解、其它分解方式),则称串S为合串。
由质串的相关定义可知,质串中不包含词语,只能分解为单字,多个质串与单字的组合可以构成合串。因此,符合质串特征的地质词语经过组合可以构成其它地质词语,将这些词语收录进地质基本词典库中,既能满足查全率要求,又可通过重复串提取地质有意义串,以满足查准率要求。本文使用通用分词器对GB9649中的地质词语进行分词。如前文所述,当地质词语长度大于4时,往往是由多个粒度较小的词语组成,因此,本次工作仅对长度不大于4的地质词语使用通用分词器进行分词,将符合质串特征的地质词语收录进地质基本词典库。
通用分词器词典中不包含地质词汇,在对地质文本进行分词时,往往只能将分词器所包含的通用词汇分出。对于二字术语(定义“A”、“B”为组成二字术语的单字),其切分方式只有AB(例“项目”一“项/目”)、A/B(例”心滩”一”心/滩”)两种切分类型,”一”表示地质词语被通用分词器切分,下同。
对于三字术语(定义“A”、“B”、“C”为组成三字术语的单字),其切分方式有4种,分别是ABC(例“淡水湖”一“淡水湖”),AB/C(例“安顺组”一“安顺/组”),A/BC(例“假整合”一“假/整合”),A/B/C(例“苦橄岩”一“苦/橄/岩”)。
同理,对于四字术语(定义“A”、“B”、“C”、“D”为组成四字术语的单字),其切分方式有8种,分别是ABCD(例“阿尔卑斯”一“阿尔卑斯”),ABC/D(例“重晶石化”一“重晶石/化”),AB/CD(例“钻进深度”一“钻进/深度”),AB/C/D(例“蚌壳蕨属”一“蚌壳/蕨/属”),A/BCD(例“堇长角岩”一“堇/长角岩”),A/B C/D(例“纸色谱法”一“纸/色谱/法”),AlB/CD(例“砾质粘土”一“砾/质/粘土”),A/B/C/D(例“采场突水”一“采/场/突/水”)。
以四字词为例对基本词典库的收录规则进行说明:对于四字词的分词结果来说,ABCD型的切分说明该词已被通用分词器的核心词典收录;对于能被切分成A/B/C/D型的词语,虽然没有被分词器的核心词典收录,但由于其本身被CB9649收录,说明该词是一个地质词汇,符合质串特征,所以该词应被地质核心词典库收录;对于能够被切分成其余类型的词语,说明该词是通用词和字或词的组合,这种类型的词可以使用重复串方法进行识别处理,因此没有收录进基本词典库中。同理,对于能切分成A/B/C类型的三字词以及能被切分成A/B/C/D的词语都应被地质核心词典库收录。
4 地质专业词语识别
4.1 重复串提取算法思想
本文地质词语识别建立在通用分词器切分结果基础上,因此采用基于詞的重复串提取,但基于词的重复串提取算法与基于字的重复串提取算法一致,此处介绍基于字的重复串提取算法思想[21]。
(1)对处理好的字序列建立索引。例如,对于只有5个字符的文本“矿化物矿化体矿化矿井矿矿化物”文本建立单字索引如图3所示。
(2)从单个字索引的信息开始扩展得到所有重复串。因为单字索引过程中已记录好语料中所有出现“矿”的地址集合A,而以“矿”打头的所有重复串地址一定包含在集合A中,那么遍历地址集合A,根据地址扫描语料进行二字扩展、三字扩展……,可以发现以“矿”开头的所有重复串。在上面例子中,扫描所有“矿”后面的第一个字符,扩展得到以“矿”开头的所有两字串(见图4)和三字串(见图5)。
频次为1的串(如“矿井”、“矿矿”)不是重复串,将其删除;对于频次大于1的重复串(如“矿化”),要将所有信息写入重复串文件中且继续对其扩展,发现长度增1的重复串。
(3)新产生的重复串写入文件后继续扩展得到长串,反复迭代,直到出现间隔符号或长度达到指定的阈值。
4.2 重复串提取流程
基于重复串提取算法,需要记录词的ID索引。值得注意的是,在一段话中往往包含停用词。停用词主要包括副词、助词、连词、介词、标点符号等,其本身并无明确意义,仅在句子中起一定作用,例如“在”、“的”、“且”等。采用串查找发现新词时,停用词会导致垃圾串产生,例如:“官/道/口/群/在/测区/内/出露/较/全/,/向/西/延伸/到/卢氏/,/灵宝/一带/,/其/岩石/组合/和/沉积/建/造/特征/均/可/对比/。/”,这句话包含停用词10个(标点4个、“在”、“较”、“其”、“和”、“均”、“可”)。在建立词的ID索引时,需要将上面一段话分为8个部分:“官/道/口/群/”、“测区/内/出露/”、“全/”、“/向/西/延伸/到/卢氏/”、“/灵宝/一带/”、“岩石/组合/”、“沉积/建/造/特征/”和“对比/”,按照这8个部分建立词的索引。因此,需要建立一个文档用于记录依据停用词对文本分割后的结果,并以此为依据建立一个词索引文档,开辟一个缓冲栈用于存放当前扩展串及相关信息。根据索引地址链进行扩展,扩展串中频次大于1的串被认为是重复串,统计词频和邻接对信息后输出到文件中,同时放人缓冲栈中用以后续扩展。当一次扩展结束后再从栈中读取栈顶串进行新一轮扩展。第一次栈空时表示以第一个词打头的所有重复串发现完毕,然后读取第二个词的索引链并放人缓冲栈,依次反复直到所有重复串发现完毕。最后输出一组文件,重复串文件用来存储串的内容、串长、串频、邻接对频次等信息。
4.3 地质专业词语识别方法
地质专业词语识别可以借助通用领域的新词发现方法。新词发现通过采用基于统计和规则过滤的方法对候选集进行过滤得到最终结果[22]。基于规则的新词发现依赖特定领域建立的规则库,其泛化性差,加之人工建立规则库代价较大,规则之间多有冲突发生。基于统计的新词发现目前使用普遍,主要有上下文邻接分析、位置成词概率、双字耦合度、频率比和互信息等。本文主要采用上下文邻接分析和位置成词概率方法识别地质专业词语。
(1)上下文邻接分析。通用的已知词语作为频繁使用的语言单元,在实际生活中具有一定的流通度和广泛性。一般来说,一个词语的内部结合度较高,其与外部上下文中的词语关系就较为松散,例如“断层”、“产状”中的两个字总是一起出现。地质词语作为独立使用的语言单元,在地质文本中具有一定的流通度,能够应用于多种不同的上下文环境。上下文分析是从串的上下文人手分析其使用环境,主要通过上下文邻接种类、临界熵、邻接对种类以及邻接对熵等邻接特征量判断。本文受文本大小限制,采用邻接种类进行判断。
对于一个串S,其邻接种类V可分左邻接种类VL和右邻接种类VR,分别表示左、右邻接集合中元素的数目,反映串S所处上、下文语境种类多少。当VL≥n,VR≥n时,该串为词。邻接种类在一定程度上反映字符串的语言环境。
(2)位置成词概率分析。在汉语构词中,每个字都有自己特有的构词作用,并非所有的字都可作为词首、词中、词尾的成分,某些字往往出现在合成词的某个或某几个特定位置上,例如“老虎”、“老师”中的“老”通常出现在词首,“产状”、“鲕状”中的“状”通常出现在词尾,而另一些字总是不会出现在词首或词尾。
地质命名实体开始是某个词的词首,串尾也一定是某个词的词尾。当检测到串首某个字的词首成词概率太低时,该串可能是垃圾串;若串尾某个字的词尾成词概率太低时,该串也可能是垃圾串。
在切分好的语料中统计每个汉字出现在词语中的总次数N和出现在词首、词尾的N1和N2,那么词首成词概率是Nl和N的比值,词尾成词概率是N2和N的比值。
对地质术语中单字成词概率和多字成词的词首、词尾概率进行统计,部分结果如表1所示。若某个字的词首成词概率太低,则认为该字不能作为词首;同样,若某个字的词尾成词概率太低,则该字不能作为词尾,这样能有效过滤新词和常用字组成的垃圾串。如判断“主要岩性为”中的“为”,“在采样过程中”的“在”即可将它们判断为垃圾串而排除。此外,还有一部分频繁功能串也能过滤掉,如“其为”、“这是”等高频串。
5 实验與分析
5.1 测试集与评测指标
中文分词研究旨在提出一种拥有通用性、实用性以及开放性的现代书面汉语自动分词方法,而评测中文分词方法性能优劣的评测标准为分词准确率与分词效率[23]。本文在通用分词器基础上建立地质专业词汇抽取方法,因此对分词效率不作评测。
分词准确率是评估分词方法有效性和合理性的核心评测标准,包括正确率、召回率以及综合指标F值。
准确率P=识别正确的新词数目/ 识别结果的新词数目上×100%
(1)
召回率R=识别正确的新词数目/ 重复串中正确的新词数目× 100% (2)
综合指标F=2×P×R/P+R
(3)
5.2 实验结果及分析
本文实验语料来自《1:25万内乡县幅区域地质调查报告》,约33万字。使用Ansj中文分词器的分词结果与本文提出的地质专业词汇识别方法的结果进行对比,如表2所示。
本次结果抽取重复串14 070个,去除单字、重复结果后,剩余3 704个。经人工判别,正确结果2 513个;经过算法过滤后,重复串剩余2 496个,本方法正确识别结果2 036个。使用分词器进行分词后,分词数量庞大,召回率难以评估。本次仅对Ansj中文分词器所识别的新词正确率进行了计算,识别新词4 478个,正确识别1 050个,正确率23.4%。
通过对比,本文方法对地质词语的识别远远高于通用领域分词器。通过分析发现,由于通用分词器一般在新词发现方面采用基于统计的分词方法,对于出现频率不高的词语,统计的分词方法学习度不够,从而引起错分。而本文方法经过重复串算法,能够将出现频率较低的词语查找出来,经过上下文邻接以及基于位置成词概率过滤后,可有效地将原本错分的词语组合到一起。但本文方法对仅出现一次和出现语境完全相同的新词无法识别,因此需要添加其它策略进一步提高其识别性能。
6 结语
针对基于统计的分词方法受语料影响跨领域适应性较差,基于词典的分词方法虽然可以直接利用领域词典进行分词但不能解决未登录词识别等问题,基于质串思想构建了地质基本词典库,对通用分词器的核心词典库进行扩充,在此基础上提出基于统计的中文地质词语识别方法。采用重复串查找方法得到地质词语候选集,使用上下文邻接以及基于位置成词的概率词典,对地质词语候选集进行过滤,实现地质词语识别。实验证明该方法提高了地质词语识别准确率,可在地质大数据中进行相关应用。
参考文献:
[1]黄昌宁.中文信息处理中的分词问题[J].语言文字应用,1997(1):72-78.
[2] 昊军.数学之美[M].北京:人民邮电出版社,2014:41-49.
[3]
ZHU Y Q, ZHOU W W.XU Y,et al. Intelligent learning for knowledgegraph towards geological data[J].Scientific Programming, 2017(3):1-13.
[4]
ZEINALI H. SAMETI H. BURCET L,et al. Text-dependent speakerverification based on i-vectors, neural networks and hidden markovmodels[J].Computer Speech&Language, 2017( 46): 53-71.
[5]
SHUAI Z, JAYASUMANA S,ROMERA-PAREDES B,et al. Condi-tional random fields as recurrent neural networks[C].IEEE Interna-tional Conference on Computer Vision, 2016.
[6] MENCEL S,Y Q J.Extracting structured data from web pages withmaximum entropy segmental markov models[C].International Confer-ence on Web Information System Engineering, 2009.
[7]
JIANG H J,REN X. LIU K.Research on dictionary for personalizedChinese word segmentation[C].The 4th International Conference onIntelligent System and Applied Material, 2014: 1-4.
[8]
ZHENC Q, LIU X Y. FU J L Neural networks incorporating dictionar-ies for Chinese word segmentation[C].Proceedings of the ThirtV- Sec-ond AAAI Conference on Artificial Intelligence, 2018: 1-8.
[9]
PANC B M, SHI H S.Research on improved algorithm for Chineseword segmentation based on mMarkov chain[C].Xi'an: InternationalConference on Information Assurance and Security. 2009.
[10]
HUANC L,DU Y F,CHEN G Y.CeoSegmenter: a statisticallvlearned Chinese word segmenter for the geoscience domain[J].Com-puters&Geosciences, 2015( 76): 11-17.
[11] 陳婧汶,陈建国,王成彬,等.基于条件随机场的地质矿产文本分词研究[J].中国矿业,2018.27( 9):69-74.101.
[12] 宗成庆.统计自然语言处理[M].北京:清华大学出版社,2013:129-134.
[13] 郑捷.NLP汉语自然语言处理[M].北京:电子工业出版社,2017:88 -117
[14]赵庆.地质科技论文中语言文字表达的几个要求[J].地质找矿论丛.2013, 28(3): 493-498.
[15] 郑孝玉.地质情报的特点及其服务工作的有关问题[J].情报杂志.1991. 10( 4):63-67.
[16] 冀倩,翁望飞.地质学专业英语词汇特点及构词研究[J].皖西学院学报,2011,27(4):116-121.
[17]李廷栋,刘勇,王军,等.略论地质图件的十大功能——纪念黄汲清先生诞辰110周年[J].地质论评,2014,60(3):473-485.
[18]雨岩.概念·定性·定量[J].水文地质工程地质,1991(6):10-14.
[19]杨锺健.地质名词的来源及统-[J].地质论评,1950( Z1):55-59.
[20]何婷婷,张勇.基于质子串分解的中文术语自动抽取[J].计算机工程,2006, 32( 23):188-190.
[21]张华平,高凯,黄河燕,等.大数据搜索与挖掘[M].北京:科学出版社,2014: 104-135.
[22]黄轩,李熔烽.博客语料的新词发现方法[J].现代电子技术,2013,36(2):144-146.
[23] 王威.基于统计学习的中文分词方法的研究[D].沈阳:东北大学,2015.
(责任编辑:杜能钢)
基金项目:国家自然科学基金项目(41671404);中央高校基本科研业务费项目(N170104019);中国地质调查局智能地质调查支撑平台建设项目(DD20160355)
作者简介:王宏(1987-),男,硕士,河南省地质调查院、河南省金属矿产成矿地质过程与资源利用重点实验室工程师,研究方向为地学信息处理与应用;朱学立(1963-),男,硕士,河南省地质调查院、河南省金属矿产成矿地质过程与资源利用重点实验室教授级高级工程师,研究方向为地质信息技术分析与应用;曾涛(1977-),男,河南省地质调查院、河南省金属矿产成矿地质过程与资源利用重点实验室高级工程师,研究方向为地学空间数据库;乔东玉(1975-),男,河南省地质调查院、河南省金属矿产成矿地质过程与资源利用重点实验室助理工程师,研究方向为地学空间数据库;郭甲腾(1980-),男,博士,东北大学资源与土木工程学院讲师,研究方向为数字矿山、数字岩土、数字城市领域的三维地学建模与可视化、三维拓扑关系分析、并行地理计算。
