一种适用于物联网的在线GP-ELM算法
2020-06-19沈苏彬
张 杰,沈苏彬
(南京邮电大学 计算机学院,南京 210046)
0 概述
自从极限学习机(Extreme Learning Machine,ELM)被提出以来,由于其具有泛化能力强、训练时间短的优点,受到了许多学者的关注。文献[1]证明了ELM的一致逼近性并将ELM直接应用于回归与多分类问题[2]。为处理非平衡数据的学习问题,文献[3]通过引入类别权值,提出了加权极限学习机(W-ELM)。文献[4]提出的在线序列极限学习机(OS-ELM),将ELM延伸至在线学习问题,拓宽其实际应用范围。目前,ELM在语音识别[5]、电力系统[6]等领域已得到初步应用。
作为一种新兴技术,ELM在回归和分类应用中表现出良好的性能,具有较高的运行速度和较好的通用性,但为探索ELM在现实问题中的普遍适用性,需要确定用于解决特定任务的最合适的网络架构。ELM与批量学习方案[7]以及在线顺序学习方案[8]是以固定网络规模开发的,搜索这种固定网络大小的常用方法是通过反复实验。该方法简单明了,但计算成本高,不能保证所选择的网络规模接近最优。文献[9]提出增量ELM(I-ELM)算法,其中隐藏节点被逐一随机添加,并且当添加新的隐藏节点时,现有隐藏节点的输出权重被冻结,证明了I-ELM的通用逼近能力。凸面I-ELM(CI-ELM)[10]采用另一种源于巴伦凸优化概念的增量方法。当添加新的隐藏节点时,这种方法允许适当地调整现有隐藏节点的输出权重。在这种情况下,CI-ELM可以实现比I-ELM更快的收敛速度,同时保留I-ELM的简单性。在I-ELM和CI-ELM的学习过程中,一些新添加的隐藏节点仅在网络的最终输出中起很小的作用,因此可能增加网络复杂性。为避免上述问题并获得更紧凑的网络架构,文献[11]提出增强型I-ELM(EI-ELM)算法。在EI-ELM的每个学习步骤中,随机生成若干隐藏节点,并且仅将导致最大残余误差减少的节点添加到现有网络。此外,EI-ELM还将I-ELM扩展到通用SLFN。文献[12]在SAP-ELM 算法的基础上,结合L2正则化因子和奇异值分解 (SVD),提出一种改进 的SAP-ELM (ImSAP-ELM)算法以提高预测精度和数值稳定性。文献[13]对灵敏度进行修正,提出更符合实际需求的神经网络剪枝算法IS-ELM。
文献[14]提供一种误差最小化ELM(EM-ELM)方法。该方法允许逐个或逐组添加随机隐藏节点(具有不同的大小)。此外,EM-ELM在网络增长期间递增地更新输出权重,降低了计算复杂度。然而,在所有上述建设性ELM的实现中,隐藏节点的数量随着学习进度和最终数量单调增加,隐藏节点的数量相当于学习步骤。如果需要进行许多迭代步骤,最终将获得大量隐藏节点,而一些隐藏节点可能在网络输出中起很小的作用。文献[15]基于和声搜索算法优化极限学习机的方法,结合了和声搜索算法和极限学习机两者的优势,利用和声搜索算法调整极限学习机的输入权值和隐含层阈值,避免了随机设定无效节点而导致预测效果不稳定、泛化能力较差等问题。文献[16]提出了一种新的隐含层节点的选择算法SHN-ELM。通过对隐含层节点的选择,提高了ELM 算法的稳定性和分类准确率。文献[17]提出了以粒子群优化算法搜索ELM隐藏层最佳神经元个数,用极限学习机模型的测试准确率作为粒子群优化算法适应值。文献[18]提出了一种P-ELM算法,通过统计方法去除不相关或相关性较低的隐藏节点,系统地确定学习过程中隐藏节点的数量,但是这样的方法却无法自动地完成。文献[19]设计了一种基于 EFAST 的隐藏层节点剪枝算法(FOS-ELM),利用傅里叶敏感度测试方法对 OS-ELM 的隐藏节点进行分析,能适用于剪枝后的网络参数调整算法。文献[20]针对隐藏节点数量影响ELM泛化性能的问题,提出一种SRM-ELM算法。SRM-ELM在结构风险最小化原则下,建立隐藏节点数与泛化能力的关系函数,利用PSO简单高效的全局搜索能力,优化ELM的隐藏节点数,避免了传统方法反复进行调节实验的繁琐。但是上述算法耗时比较长,不适用于物联网的特性。为此,本文提出一种适合物联网的在线GP-ELM算法。该算法能够在添加多个节点的同时进行剪枝、删减节点,以提高ELM的准确性。
1 极限学习机及其相关理论
1.1 极限学习机
在ELM中,只需要预先确定隐藏神经元的数量,而隐藏神经元的参数(如RBF节点的中心和影响因子或附加节点的偏差和输入权重)是随机分配的。因此,给出如下ELM预测公式:
(1)
其中,β=[β1,β2,…,βk]是连接隐藏层和输出层的输出权重的向量,H(X)=[H1(X),H2(X),…,Hk(X)]是隐藏层相对于样本X的输出。 根据Bartlett理论,对于训练误差较小的神经网络,权重范数越小,网络的泛化性能越可能更好,因此,将训练误差与输出权重的范数最小化:

(2)
其中,H是隐藏层的输出矩阵:
(3)
并且:
(4)
将最小范数最小二乘法用于经典ELM的原始实现中,即:
β=H†T
(5)
其中,H†是H的Moore-Penrose广义逆,即伪逆。
如果使用标准优化方法,则基于约束优化的ELM可以写成:
受限于:
ξ=T-Hβ
(6)
根据KKT条件,可以通过以下双重优化来解决:
(7)
其中,αi∈α=[α1,α2,…,αN]对应于训练样本的拉格朗日乘数。KKT最佳条件如下:
(8)
(9)
(10)
根据训练集的大小可以实现不同的解决方案:
1)训练样本数量很大的情况
如果训练数据N的数量非常大,如比特征空间L的维数大得多,即N> >L,则以下解决方案是优选的。
(11)
在这种情况下,ELM的输出函数为:
(12)
2)训练样本数量少的情况
在这种情况下,通过将式(8)、式(9)代入式(10),可以等效地将式(11)、式(12)写为:
(13)
由式(4)~式(8),有:
(14)
ELM的输出方程为:
(15)
1.2 EM-ELM算法
EM-ELM是一种简单而有效的算法,可以逐个或逐组地随机添加隐藏节点。在网络增长期间,基于误差最小化方法递增地更新输出权重。
(16)
可以等效地以矩阵形式表示:
Hβ=T
(17)
其中:
(18)
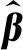
(19)
其中,H†是H的Moore-Penrose广义逆,即伪逆。
(20)
(21)
(22)
其中:
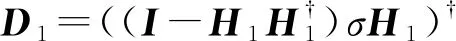
(23)
然后计算β2:
(24)
同样,输出权重可以逐步更新为:
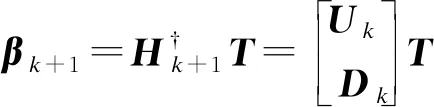
(25)
1.3 在线序列学习机
训练数据可以在实际应用中逐块或逐个(块的特殊情况)到达。在线序列学习机(OS-ELM)算法针对在线学习案例,并在短时间内不断更新输出权重。
当新的采样数据到来时,ELM的数学模型应该被修改为:

(26)
其中,δH和δT是新生成的隐藏层输出矩阵,使用当前学习参数和由新获得的观测值组成的输出矩阵,β′是修改后的输出权重矩阵。OS-ELM算法分为两个阶段,即初始化阶段和顺序阶段。初始化阶段与普通ELM算法相同,而输出权重矩阵β将通过迭代方式在顺序阶段中更新。
OS-ELM算法步骤如下:

2)计算初始隐藏层输出矩阵H0:
4)设置k= 0,其中k是表示呈现给网络的数据块数量的索引。
步骤2(序列阶段) 给出第(k+ 1)个新观察结果:
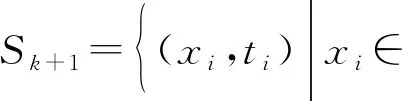
其中,nk表示k块中新获得的观察的数量。显然,可以得到N0=n0。
1)计算部分隐藏层输出矩阵hk+1:
hk+1=
2)计算输出权重矩阵βk+1:

设置k=k+ 1,然后返回序列学习阶段。
2 GP-ELM算法
2.1 算法描述
最早的ELM应用是预先设定好隐藏层节点的个数,存在准确率不稳定等不足。该类算法主要有2种:1)逐渐增加一个或者多个节点,这种算法将节点添加之后,隐藏层的参数即固定,这样一些不必要的节点或者贡献很小的节点会增加计算量;2)先设定一个较大的值作为隐藏层节点的个数,根据第一次训练节点的权值删减一些节点,然后再训练,这种算法必定要设置一个非常大的值,这对不同的数据的适应性就非常低,因为一些数据只需要较少的节点,而有些则需要较多的节点。
本文算法是在EM-ELM[12]算法模型的基础上,固定每轮增加节点的个数,增加了每轮对整体节点进行剪枝的过程,能够保证节点的质量。本文算法结合上文两类算法的优点,既能动态地根据数据来生成隐藏节点,又能剔除那些没有起到作用的节点,先生成固定数值节点,在这些节点加入之后进行一次训练,根据权值矩阵β来计算每个节点的贡献值:
1)如果β是一维的,则直接将这一列换算成比例。
2)如果β是n维的,则先将每一列换算成比例,然后将每一行取平均值。
根据计算出的贡献值来选择删去哪些节点,然后返回到增加节点的步骤,如此循环,直到达到一定的标准停止循环。
由于物联网下的数据是不断产生的,因此在线训练数据更新参数又是非常有必要的,所以本文算法在确定隐藏层结构后,会根据新来的数据更新参数。
2.2 算法步骤
本文算法步骤如下:
步骤1初始化阶段:
2)计算隐藏层的输出矩阵:
3)计算最优的输出权重:
β=H†T
其中,H†为H的广义逆,T为目标矩阵。于是,得到初始函数Ψ1以及相关的误差E1:
步骤2隐藏节点上升并且删减(最大隐藏节点数Lmax,需求的错误率ε):
1)生成M个隐藏节点参数并将其加入到当前模型,然后根据迭代式计算:


2)计算出输出权重,生成模型Ψn(x)=βnGn(x),计算其误差En,如果Ln
3)根据计算出的β计算每个节点的贡献值:
(1)如果β是一维的,则直接将这一列换算成比例。
(2)如果β是n维的,则先将每一列换算成比例,然后将每一行取平均值。
4)删除那些几乎不起作用的节点(两种方案):
(1)节点贡献值低于某一个值会被删除。
(2)对贡献值进行排序,贡献值最小的m个节点会被删除。
5)转到步骤1。
步骤3在线学习阶段:
设置r= 0,其中k是表示呈现给网络的数据块的数量的索引,给出第(r+ 1)个新观察结果:

其中,nr表示r块中新获得的观察的数量。显然,可以得到N0=n0。
1)计算部分隐藏层输出矩阵hr+1:
2)计算输出权重矩阵βk+1:
3)如果还有数据进入,则设置r=r+1,然后返回序列学习阶段,否则程序结束。
2.3 收敛性证明
定理1给定一个SLFN,令H1作为有L0个隐藏节点的SLFN隐藏层输出矩阵,如果L1-L0个节点被加入当前模型,新的隐藏层输出矩阵为H2,于是有:
证明:根据前文的推理,增加σL0=L1-L0可以得到H2=[H1σH1],其中:
σH1=
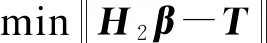
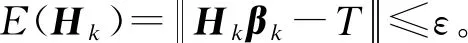
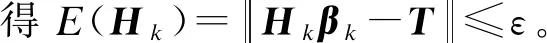
由上面的证明可以看出,本文算法可以使得误差值达到指定小的值,即算法是收敛的,能够迭代终止。
3 实验与结果分析
3.1 实验环境
本文实验的实验平台为 Intel i7-6700 3.4 GHz,16 GB 内存和 1 TB硬盘的PC,实验在 Windows 10 系统上用 Matlab 2016(b)实现。本文实验采用了实际应用的公开的数据集Image Segment(图片分割)、Satellite Image(卫星图片分类)和DNA,如表1所示。
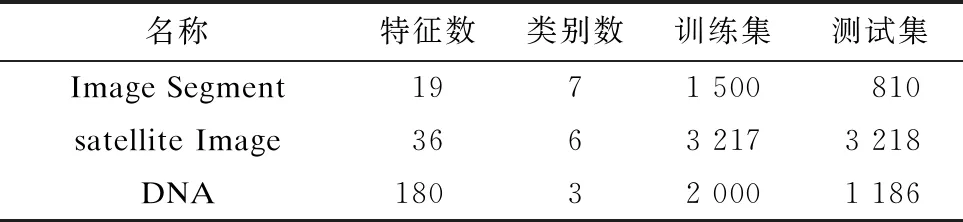
表1 实验所用数据集
3.2 实验结果对比
本文实验将提出的算法GP-ELM与ELM以及各种衍生版本OS-ELM、EI-ELM、D-ELM、EM-ELM进行了对比(本文所有实验结果都是重复实验10次后的均值)。
3.2.1 各个数据ELM网络结构的确定
对每个数据集逐渐增加隐藏节点的个数,如图1所示。
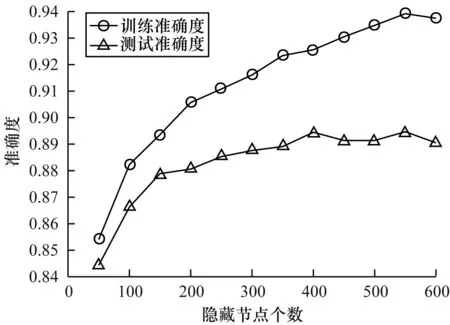
图1 准确度随节点数增长过程
从图1可以看出,随着隐藏节点个数的增长,训练准确度和测试准确度都在逐步上升,测试准确度在500隐藏节点时达到了平稳状态,并且在550左右开始下降,因此,对于数据集Satellite Image,ELM的最优隐藏节点个数在550左右。对于其他两组数据集进行同样的实验得到了相应的节点个数。
3.2.2 与ELM、OS-ELM算法的对比
将本文算法与ELM、OS-ELM算法进行实验对比,结果如表2所示。从表2可以看出,本文算法在增加较少训练时间的代价下,首先完成了隐藏节点个数自动生成的任务,并且在准确度上有了一定的提升,同时需要更少的隐藏节点来完成。这是因为本文提出的算法在每次增加节点之后,对一些不重要的对结果影响特别小的那些隐藏节点都进行删除,这样,留下来的节点都是提取了非常重要的特征,对最后的结果有着很大的影响,所以本文提出的算法能用比较少的节点得到比较高的准确度。
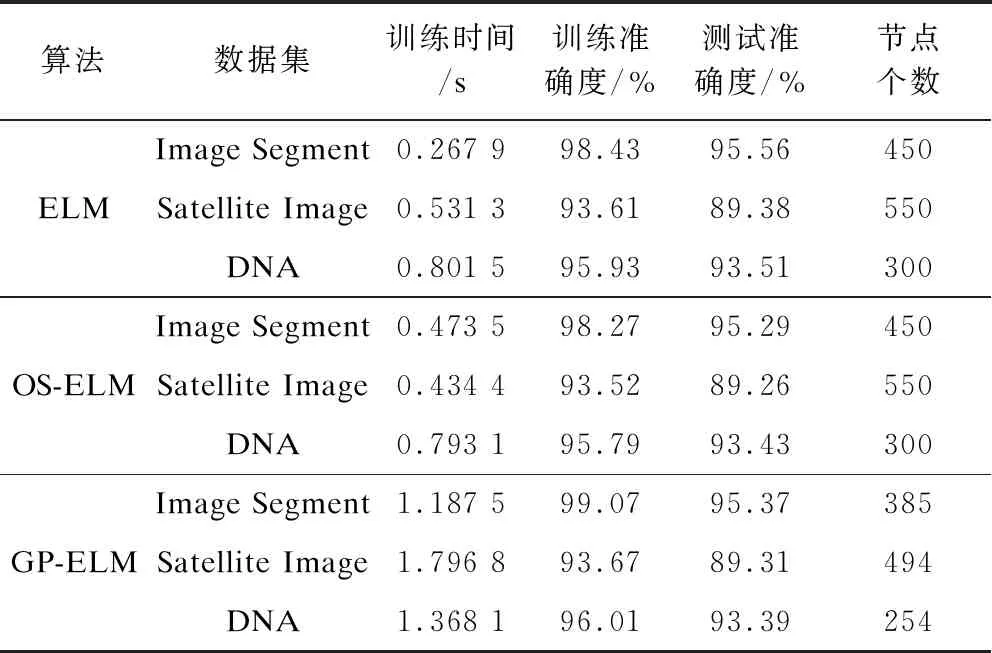
表2 GP-ELM与ELM、OS-ELM算法性能对比
3.2.3 与EI-ELM、D-ELM、EM-ELM算法的对比
本文算法与EI-ELM、D-ELM、EM-ELM算法的性能对比如表3所示。从表3可以看出,本文算法具有更高的准确度,这是因为删去不重要的节点,使得本文算法生成的节点数量基本是最少的。另外,DP-ELM在训练时间上相比其他算法要少,这是由于本文的算法并不是一个一个地增加节点,而是一块一块地增加,这样大幅节省了训练时间,同时,本文算法通过对原有的节点进行删除修剪,这样更有效地对ELM的结构进行组装,提高所选节点的质量,在得到较高准确度的同时节省了随机搜索而进行的大量迭代时间,保证了更少的节点。

表3 GP-ELM与EI-ELM、D-ELM、EM-ELM 算法性能对比
通过观察图2所示的迭代次数与被加入的隐藏节点个数的对比,可以发现GP-ELM是每次增加多个节点然后进行修剪,所以会很快地并以较少的节点完成迭代,可以看出本文算法具有较大的优势。
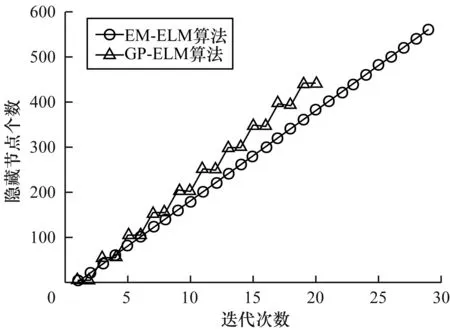
图2 节点个数随迭代次数变化过程
4 结束语
为适应机器学习算法准确、快速以及自适应产生参数的需求,本文通过研究ELM网络结构的确定方法,结合EM-ELM算法节点增加的方式和广义逆的迭代公式,引入节点的修剪删除的阶段,实现达到根据数据本身自动地确定ELM网络结构的能力,并且在确定的过程中不断地删除贡献较低的节点,以保持网络的大小,提高ELM的准确性。实验结果表明,与EM-ELM、D-ELM和EI-ELM算法相比,DP-ELM算法能够保证泛化能力,在准确率、训练时间、模型大小等方面都有着很好的表现,满足物联网下边缘设备对机器学习产生的应用需求。下一步将把该算法拓展到真实的物联网场景下进行应用,以测试实际的效果与适用范围。
