基于改进LSTM的儿童语音情感识别模型
2020-06-19余莉萍梁镇麟梁瑞宇
余莉萍,梁镇麟,梁瑞宇
(1.复旦大学 计算机科学技术学院,上海 201203; 2.东南大学 信息科学工程学院,南京 210096;3.南京工程学院 信息与通信工程学院,南京 211167)
0 概述
儿童情感识别是情感计算的重要部分[1]。儿童在情感发泄和应对不同情感时作出合理举措的能力远不如成年人,如果儿童情绪无法进行合理宣泄并及时得到疏导会导致其产生情绪障碍,进而引发焦虑症等心理健康问题。因此,运用适当的算法或模型对儿童情绪进行智能判断和合理疏导具有重要意义。
研究人员从声学特征、机器学习和深度学习等方面对儿童情感识别进行深入研究。文献[2]提出利用支持向量机和卷积神经网络来构建检测儿童二级情绪状态的系统。文献[3]利用基于多智能体的交互系统对儿童的情感状况进行实时定义。文献[4]创建儿童双模态情感数据库并采用双模态情感识别方法衡量儿童情感的贡献比例,指出婴儿(或幼儿)的情感比大龄儿童的更难判断,婴儿通常用哭泣向父母或者监护人表达自身需求。文献[5]提取婴儿哭声的梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)并基于隐马尔科夫模型(Hidden Markov Model,HMM)对婴儿哭声进行分类,以识别婴儿是否处于健康状态。文献[6]将语谱图作为特征向量,选取卷积神经网络(Convolutional Neural Network,CNN)作为分类模型,对婴儿在疼痛、饥饿和困倦时的哭声进行分类和有效识别。文献[7]将支持向量机(Support Vector Machine,SVM)作为分类器对婴儿在饥饿、疼痛及困倦时的哭声进行分类,取得较好的识别效果。
虽然上述算法被成功应用于儿童情感识别,但是传统机器学习算法以及深度学习中的自编码器和卷积神经网络都只能接受具有固定维度的数据作为输入,这与实际中有效语音长度不断变化存在一定矛盾。针对该问题,文献[8-10]从短时语音帧中提取情感相关特征(以下称为帧级特征),将静态统计函数(如均值、方差、最大值、线性回归系数等)作用于帧级特征上,最终串联形成具有固定维度的特征向量来表示该帧语音的特性。虽然该方法解决了模型输入的问题,但是通过统计分析处理后的语音特征丢失了原始语音的时序信息。
本文提出一种基于改进长短时记忆(Long Short-Term Memory,LSTM)的儿童语音情感识别模型,在LSTM网络结构的基础上,将帧级语音特征取代传统统计特征,用注意力门替换传统的遗忘门和输入门,并在多个时刻的细胞状态上加权注意力构建深度注意力门,以取得更好的识别性能。
1 相关工作
1.1 LSTM网络
LSTM网络是循环神经网络(Recurrent Neural Network,RNN)的一种变体,主要用于处理时间差较长的序列信息[11-13]。LSTM网络通过加入遗忘门单元可以解决反向传播时RNN存在的梯度消失造成长期信息难以存放的问题。LSTM网络已成功应用于自然语言处理[14-16]问题。为强化LSTM网络在特定任务中处理数据的能力,研究人员进一步对LSTM网络内部构造进行优化。文献[17]通过门控循环单元(Gated Recurrent Unit,GRU)将LSTM网络的输入门和遗忘门进行融合降低了模型参数,但是在大规模的数据集上,LSTM网络在所有机器翻译任务上的指标均优于GRU[18]。文献[19]通过ConvLSTM网络结构将LSTM的门结构计算方式由矩阵相乘改进为卷积,该方法在图像领域取得成效,但是对语音效果的改善十分有限。文献[20]通过前馈型序列记忆网络(Feedforward Sequential Memory Network,FSMN)将RNN的无限脉冲响应滤波器(Infinite Impulse Response Filter,IIR)记忆块改进为有限脉冲响应滤波器(Finite Impulse Response Filter,FIR)记忆块,并在语音识别和合成方面取得显著成效,但是FSMN通常需要堆叠很深的层数,因而FSMN较单向的LSTM网络存在延时[21]。文献[22]提出高级长短期记忆(Advanced LSTM)网络,利用注意力机制对多个细胞状态进行加权,能有效用于情感识别。但是文献[23]指出该方法并没有改变LSTM网络内部的门结构,且所需训练时间较多。 此外,研究人员在如何堆叠LSTM结构以实现更可靠的情感识别方面不断探索。文献[24]通过卷积神经网络(Convolutional Neural Network,CNN)从6 s长的语音波形中提取多通道语音特征作为LSTM网络的输入,实现了端到端的情感识别。文献[25]通过CNN从6 s长的语音波形中提取1 280种抽象特征,与表情特征融合后作为LSTM网络的输入,实现了多模态情感识别。
传统的LSTM网络使用的计算公式如下:
ft=σ(Wf·[ht-1,xt]+bf)
(1)
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
(4)
ot=σ(Wo·[ht-1,xt]+bo)
(5)
ht=ot*tanh(Ct)
(6)
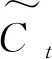
1.2 注意力机制
注意力机制是在人类视觉注意力机制基础上形成的。注意力使得人类对视觉捕获到信息的重要部分给予更大关注,尽可能获取所关注目标的细节信息,同时减少对目标周围无关信息的关注,即对无关信息产生抑制。为有效利用LSTM网络历史时刻输出的信息,文献[26]将软注意力机制引入到LSTM网络模型(以下称为LSTM模型)中,并将其成功应用于机器翻译领域,通过对LSTM模型在不同时刻的输出进行注意力加权,可表达当前待翻译单词与其他单词的关联程度。文献[27]提出基于注意力机制的encoder-decoder结构,其应用于语音识别的效果优于HMM解码系统。文献[28]在encoder-decoder结构的基础上提出局部注意力模型,首先预估一个对齐位置,然后在对齐位置处尺寸为L的窗口范围取类似于软注意力模型的概率分布。文献[29]将单头注意力机制改进为多头注意力机制,通过Transformer模型显著地提升了机器翻译的质量。
近年来,自注意力机制成为学者们研究的热点。文献[30]计算LSTM模型输出的自注意力,针对不同的时间步数计算出多个分数,进而提出新的LSTM模型,计算公式为:
A=softmax(Ws2tanh(Ws1HT))
(7)
其中,A为注意力分数矩阵,hi为i时刻隐层单元的输出,H为LSTM模型每个时刻输出hi堆叠在一起的结果:
H=(h1,h2,…,hn)
(8)
加权后输出表示为:
M=AH
(9)
注意力机制的引入减小了处理高维输入数据的计算负担,使得任务处理系统更专注于找到输入数据中与当前输出显著相关的信息,从而提高输出质量[28]。近年来,研究人员将注意力机制应用于语音情感效果的提升。文献[31]利用注意力机制在多层LSTM网络之间进行特征筛选和跨越链接,取得良好的情感识别效果。文献[32]在RNN的输出端提出本地注意力(Local Attention)机制,有效地提升了多个数据集的情感识别效果。
2 改进的深度注意力门
2.1 注意力门
本文将注意力机制引入LSTM模型的内部门结构,提出了基于注意力门的LSTM模型,从而大量减少了LSTM的参数数量;将深度的概念引入注意力门使得LSTM模型能更好地学习输入特征而避免信息冗余。本文提出的基于注意力门的LSTM结构使得每个时间步计算时,上一刻的细胞状态自行决定需要注意的特征,并在这一刻输入中利用注意力门修改传统遗忘门和输入门后对需要注意的特征进行加权。
由于传统的输入门和遗忘门仅由一个全连接层实现,因此需要训练足够多次后模型才能注意到需要留下的细胞状态信息和需要加入的新输入信息,从而导致其收敛减速。文献[33]在此基础上增加了窥视连接,将细胞状态也作为输入,在3个门中加入细胞状态信息,而参数的增加造成了训练时间和空间复杂度相应增加。本文对每一刻的细胞状态做自注意力,并对细胞状态不需要注意的部分加入输入的候选信息,自注意力算法用注意力门替换了遗忘门、输入门以及窥视连接所需的3个矩阵。
注意力门at的定义如下:
at=activation(V·tanh(W·Ct-1))
(10)
其中,activation为激活函数(可根据需要自选对应激活函数,但其值域应满足绝对值小于1),更新细胞状态的计算公式为:
(11)
注意力门能在提高模型识别率的同时减少参数数量和训练时间。在已有的报道中,通常会采用模型蒸馏[34]、8-bit量化[35]、共享参数[36-37]等方法。本文提出基于注意力机制的注意力门,显著地减少了LSTM模型内部的参数。此外,由于在LSTM模型内部进行修改,对于较长的输入序列,基于注意力门的模型能减少更多的训练时间。例如,对于输入维度为512、输出维度为256的一层LSTM模型来说,如果忽略偏置,其通常需要的参数为:1)3个门结构和候选值所需的维度为[512+256,256×4]的权重;2)如果在计算门结构时考虑到上一刻的细胞状态,还需增加3×[1,256]的向量作为窥视门[38]。本文因为直接对细胞状态计算自注意力作为注意力门,所以不需再引入窥视门结构。同时,由于融合了遗忘门和输入门为注意力门,所需参数数量降为[512+256,256×2]和计算注意力的2×[256,256]的权重。对于本层而言,参数数量从最初的787 200降到524 288,减少了33.4%的参数。对于层数更深、模型更复杂、数据量也更大的LSTM模型而言,有效地减少了参数数量。
2.2 深度注意力门
LSTM模型通常用来处理时序信息,但是该信息会随着时间的累积而增加,因而LSTM模型在某一刻的计算(即更新细胞状态c和隐层输出h)都只基于外部输入和上一刻的细胞状态与隐层输出。在注意力机制提出前,如果每一时刻都考虑之前多个时刻,会导致信息过多而遗失重要信息,以及增加计算量并导致梯度爆炸。但是,t时刻细胞状态的信息不仅与t-1时刻的信息有关,还与t-2时刻的信息紧密相关,而t-2时刻的信息在t-1时刻被选择性遗忘(遗忘门)。为此,本文提出了深度遗忘门的概念,并设计对应的输入门。
深度遗忘门不仅关注上一时刻细胞状态的信息(深度length=1),还关注t-2,t-3,…,t-n时刻(深度length=n)细胞状态的信息,即构建Deep-Attention-LstmCell结构,如图1所示。
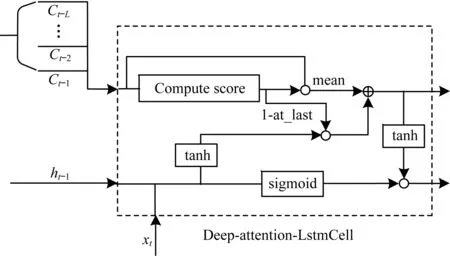
图1 Deep-Attention-LstmCell内部结构示意图
深度遗忘门具体实现如下:
(12)
(13)
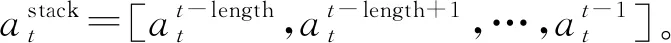
(14)
值得注意的是,“深度”的引入会造成训练时间的增加。这是因为除了前向增加了在循环中对多个细胞状态计算各自的注意力门,反向传播中也增加了更多的链式求导。从模型的参数来看,虽然深度会造成训练时间的增加,但是因为各层深度的注意力门权重V、W共享,所以不会造成模型参数的增加。
本文提出深度的目的是提升语音情感的识别性能,为研究对该性能的提升效果,进行以下实验:
实验1研究深度性能对儿童情感识别率的影响。使用深度为1、2和3的基于注意力门的LSTM模型(以下称为注意力门LSTM模型)进行对比。
实验2研究参数数量和训练时间的降低对语音情感识别性能的影响。使用深度为1的注意力门LSTM模型和传统的GRU模型、LSTM模型进行实验对比。
2.3 训练整体框架
深度注意力门LSTM模型的训练框架如图2所示。其中,LSTM0表示第1层深度注意力门LSTM模型,LSTM1表示第2层深度注意力门LSTM模型。xt为分帧加窗后第t帧语音所提取的INTERSPEECH语音特征[8-10],ht和Ct为其对应的LSTM模型输出的隐层输出和细胞状态。由图2可以看出,传统LSTM模型在t时刻的输入状态是(ht-1,Ct-1),而在本文的训练中,每一时刻的状态扩充为(ht-1,{Ct-1,Ct-2,…,Ct-L}),其中L为注意力门的深度。包含前序所有时序信息的最后一层LSTM的最后一个状态被输入到后续分类网络中,以进行对儿童情感的识别。
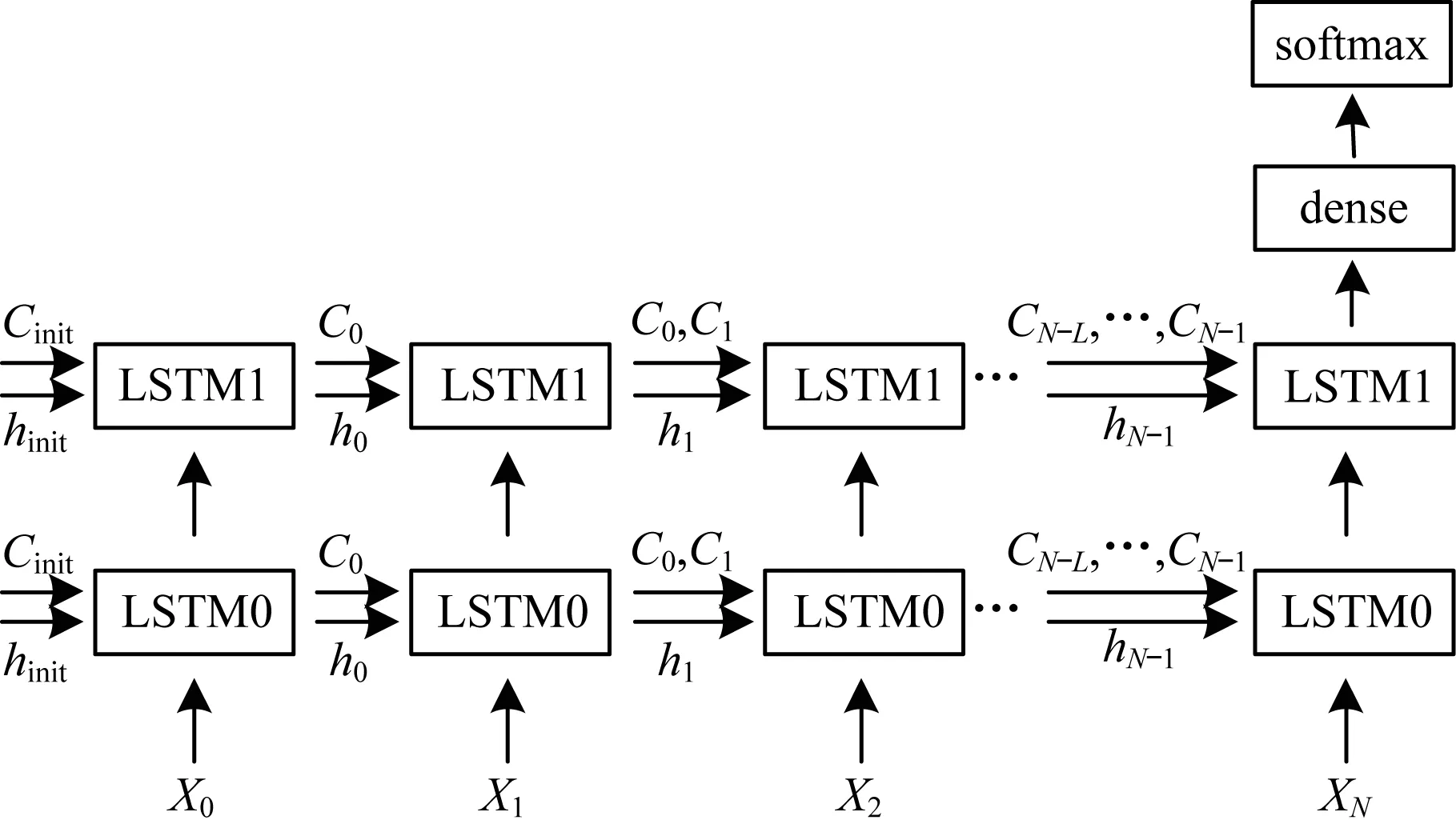
图2 深度注意力门LSTM模型训练框架
3 实验设置与分析
3.1 实验设置
实验使用2个情感表征形式差异较大的数据库来验证本文算法对于儿童语音情感的有效性。为研究本文算法处理其他类型情感识别问题的性能,以及参数数量降低是否能优化时间或降低性能,实验采用Fau Aibo儿童情感语料库、婴儿哭声情感需求语料库和CASIA汉语情感语料库[39]进行验证。
1)Fau Aibo儿童情感语料库:Fau Aibo用高性能的无线耳麦收集并录制了10岁左右的51名儿童和电子宠物 Aibo在游戏过程中的发声,保留其中情感较突出的数据,其中自然语言包含48 401个单词。为了保证标注的准确性,该语料库的每个样本均由5个语言专业的学生试听后通过投票标注情感。本文从该语料库中挑选了INTERSPEECH 2009情感挑战赛中定义的5类标签:即A (Angry、 Touchy、 Reprimanding)、E (Emphatic)、N (Neutral)、P (Motherese、 Joyful)和R (Rest)。
2)婴儿哭声情感需求语料库:由于国际上没有统一的婴儿哭声情感需求语料库,笔者与国内某医院合作录制了婴儿在生气(Angry)、饥饿(Hungry)、疼痛(Pain)、伤心(Sad)和困倦(Tired)5种状态下的哭声语音文件,并对该文件进行了标注。为提高该语料库的质量,笔者通过人工的方法对婴儿哭声情感语料进行筛选,除去婴儿哭泣时夹杂父母安慰孩子的语音相关帧,以及2个和2个以上婴儿同时哭泣的语音相关帧。该语料库经过筛选后包含10名婴儿(男孩和女孩各5名),每位婴儿在每种状态下有20条语料,共计5×10×20=1 000条语料。
3)CASIA汉语情感语料库由中国科学院自动化所录制,由4个相关专业的人员按照生气(angry)、高兴(happy)、害怕(fear)、悲伤(sad)、惊讶(surprise)和中性(neutral)等6种情绪进行发音。该语料库共有9 600条语料。
3.2 帧级特征的选择
实验在INTERSPEECH语音情感特征[8-10]的基础上选用了部分帧级特征。文献[8]提取了16种低级描述符(LLD、过零率、均方根帧能量、基音频率和梅尔频率倒谱系数1~12)及其差分系数,针对其中每个描述符,又计算了12个统计函数,因此总特征向量共有16×2×12=384个特征。INTERSPEECH 2010(IS2010)语音情感特征[9]在此基础上,将LLD增加到38种,因而总特征维度扩展到1 582维。INTERSPEECH ComPARE[10]特征集的特征维度则增加到6 373维。
实验所用帧级语音情感特征集如表1所示。与INTERSPEECH语音情感特征相比,该特征集未计算统计函数,这是因为:
1)计算统计函数后的固定长度特征损失了原始语音中的大量信息,如时序信息和序列间的关系等。
2)文献[40]认为深度学习具有自动学习特征变化的能力,能够从底层语音特征中学习到与任务相关的深层特征,由此可知帧级特征更适合作为深度学习网络的输入。
3)包含大量统计信息的特征会大量增加训练模型的参数数量、训练时间和复杂度,对训练设备有一定要求。

表1 帧级语音情感特征集
3.3 实验参数设置
原始数据分为训练集与测试集两部分,这两部分数据相互隔离,且训练集与测试集的比例为4∶1。实验均采用单向两层LSTM堆叠结构,并使用了一个全连接层和一个softmax层作为训练模型。在训练过程中,使用小批量梯度下降法并采用tanh作为激活函数,具体参数如表2所示。为保证实验对比的有效性,相同的语料库和模型实验参数均完全相同。

表2 实验参数
4 算法性能分析
4.1 深度的性能分析
传统LSTM模型通过遗忘门除去多余信息,通过输入门获取新信息。本文利用自注意力和LSTM的基本结构,对细胞状态做自注意力,从而对LSTM的遗忘门和输入门进行对比。同时,考虑到时序信息的关联性,提出基于深度的自注意力门,并在深度为1、2和3的条件下分别进行比较。实验对比了4类模型:即传统LSTM模型、LSTM+deepf_1模型、LSTM+deepf_2模型、和LSTM+deepf_3模型,上述模型对应的深度分布为0、1、2和3,如图3所示。由图3(a)、图3(b)、图4(a)和图4(b)可以看出,采用婴儿哭声情感需求语料库和Fau Aibo儿童情感语料库,利用提出的注意力门替换掉传统LSTM模型的遗忘门和输出门后,注意力门LSTM模型在训练集和测试集上的收敛速度比传统LSTM模型的大幅提高;采用婴儿哭声情感需求语料库时,传统LSTM模型约在第5 000步开始稳定收敛,而注意力门LSTM模型约在2 500步开始稳定收敛;采用Fau Aibo儿童情感语料库时,传统LSTM模型约在第30 000步开始稳定收敛,而注意力门LSTM模型在约17 000步开始稳定收敛;当模型收敛后,注意力门LSTM模型对儿童情感的平均识别率明显优于传统LSTM模型。由图3(c)和图4(c)可以看出,当模型收敛时,注意力门LSTM模型在测试集上的平均识别率、最低识别率和最高识别率均比传统LSTM模型高约5%;当注意力门的深度加大后,注意力门LSTM模型的上述性能得到进一步提升。
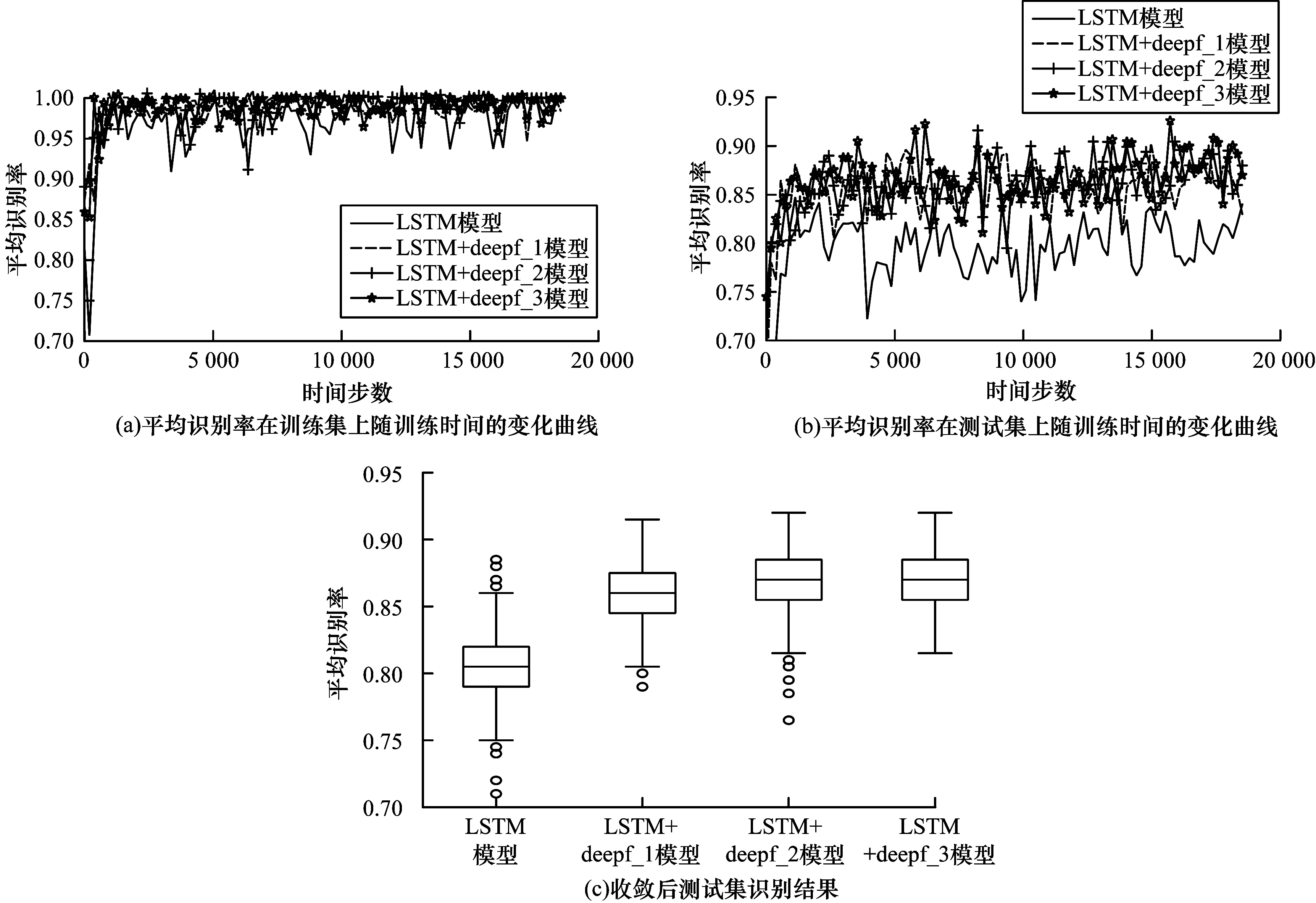
图3 不同LSTM模型采用婴儿哭声情感需求语料库的性能情况
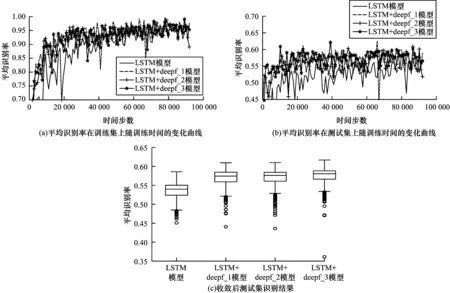
图4 不同LSTM模型在采用Fau Aibo儿童情感语料库的性能情况
通过上述分析可知,注意力门LSTM模型的性能得到改善是因为其修改了传统LSTM模型的遗忘门和输入门,使得LSTM模型能针对上一刻的细胞状态通过自注意力来留下重要信息,并将不重要的信息作为新加入的输入在对应位置进行补充,从而提升LSTM模型性能;注意力门LSTM模型引入深度概念后,使得每次遗忘操作由多个细胞状态决定而不是由其中某一个细胞状态决定。
为定量分析不同模型在测试集中对每类情感的识别性能,取各模型在测试集上从训练开始到结束识别率最高一次的模型性能指标进行对比,采用婴儿哭声情感需求语料库和Fau Aibo儿童情感语料库得到的性能指标如表3和表4所示。可见对于测试集而言,注意力门LSTM模型的性能指标均优于传统LSTM模型。
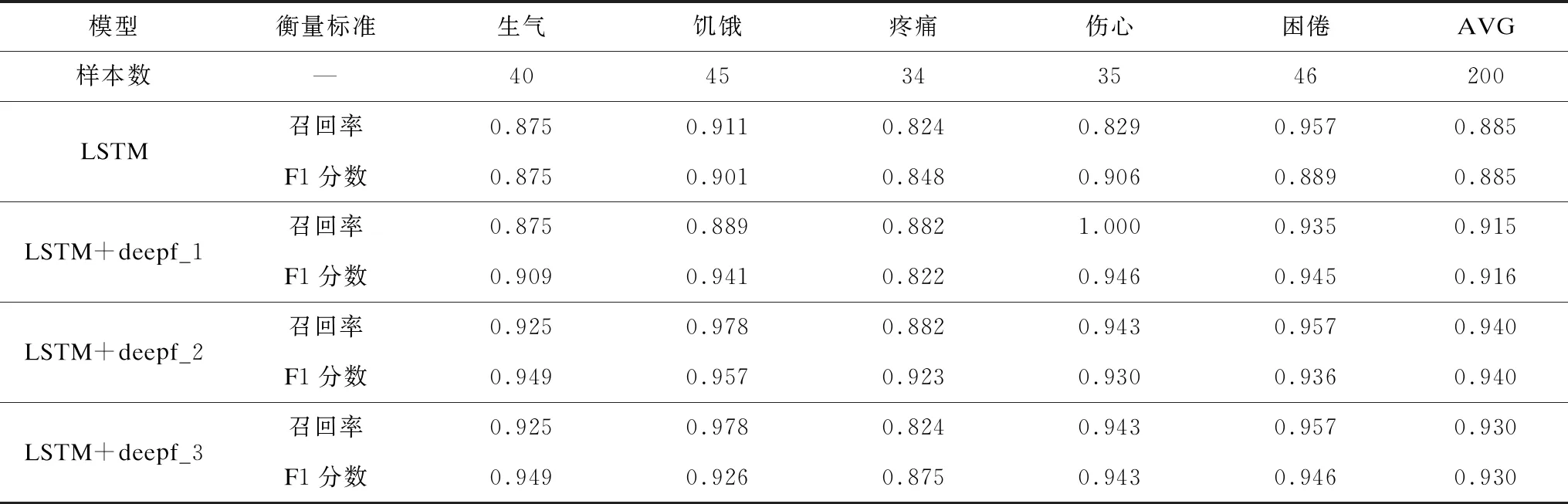
表3 不同LSTM模型采用婴儿哭声情感需求语料库的性能指标
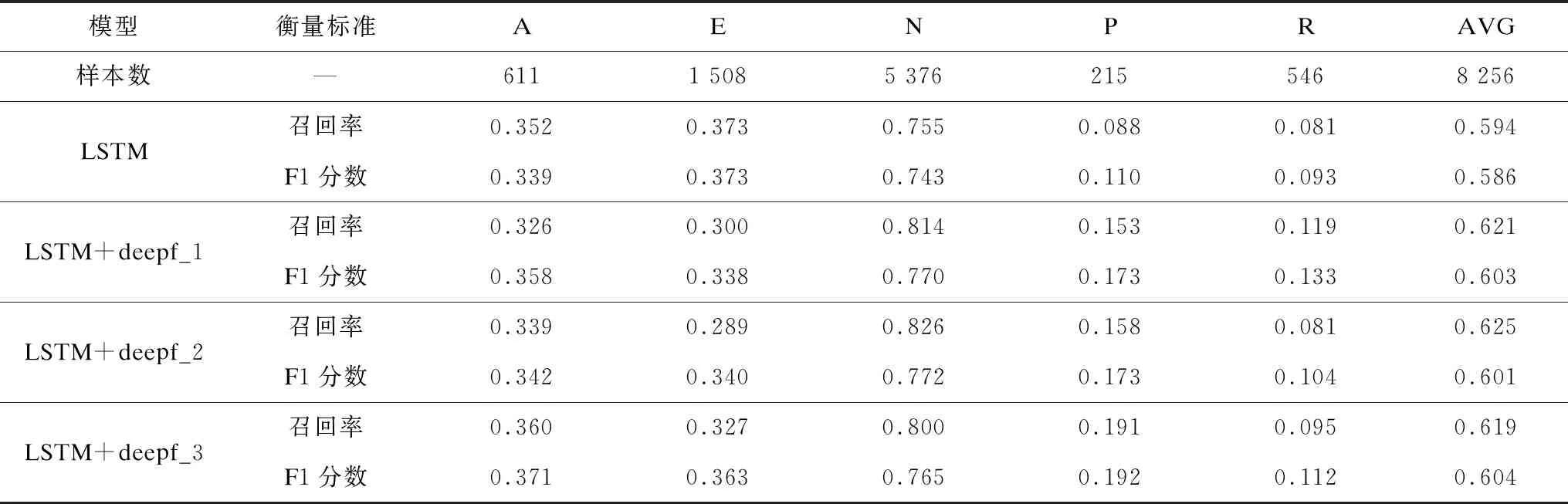
表4 不同模型采用Fau Aibo儿童情感语料库的性能指标
由表3可以看出,采用婴儿哭声情感语料库时,注意力门LSTM模型召回率除了“困倦”项和传统LSTM模型较接近外,其他4项均优于传统LSTM模型;而注意力门LSTM模型的F1分数在5类情感上均优于传统LSTM模型。在深度方面,深度3和深度2的注意力门LSTM模型的性能接近,除了“伤心”外,上述模型其他4项的召回率和F1分数均优于深度1的注意力门LSTM模型。
由表4可以看出,采用Fau Aibo儿童情感语料库时,注意力门LSTM模型的召回率和F1分数除了E类比传统LSTM模型要低,其他4项均优于传统LSTM模型。在深度方面,深度3和深度2的注意力门LSTM模型性能接近,除了R类外,上述模型其他4项的召回率和F1分数均优于深度1的注意力门LSTM模型。
值得注意的是,Fau Aibo儿童情感语料库各类别的样本数量不均衡,其中N类最多有5 376个样本,而P类最少只有215个样本。由上述分析可知,随着深度的加大,可以增强模型对少量样本的学习。和传统LSTM模型相比,采用婴儿哭声情感语料库时,LSTM+deepf_2模型的召回率提高5.50%,F1分数提高5.49%;采用Fau Aibo儿童情感语料库时,LSTM+deepf_2模型的召回率提高3.14%,LSTM+deepf_3模型的F1分数提高1.84%。
4.2 注意力门的时间和性能分析
和传统LSTM模型相比,注意力门LSTM模型将注意力机制改进为注意力门机制,并用注意力门替换了LSTM模型的遗忘门和输入门,从而大量减少了LSTM模型的参数。以下实验中将两层LSTM模型和注意力门LSTM模型进行对比。为了和其他低参数RNN进行对比,将LSTM模型、LSTM+deepf_1模型和GRU模型在时间和识别性能方面进行对比。
前文对参数量的减少已进行具体分析(见2.1节)。在以下实验中,两层注意力门LSTM模型将参数数量从“(93+512)×512×4+3×512+(512+256)×256×4+3×256=2 027 776”降低为“(93+512)×512×2+2×512×512+(512+256)×256×2+2×256×256=1 668 096”。此外,还引入深度的概念使得LSTM模型更好地学习输入特征以避免信息冗余。注意力门LSTM结构使得每个时间步计算时,上一刻的细胞状态自行决定需要注意的特征,并在这一刻的输入中利用注意力门修改传统的遗忘门和输入门,从而对需要注意的特征进行加权,以加快网络的收敛速度。
由图5可以看出,采用CASIA汉语情感语料库时,在相同的输入数据、网络参数、批大小和硬件设施下训练1 200次后,LSTM+deepf_1模型所需时间少于传统LSTM模型,同时多于GRU模型。这是因为注意力门减少了模型的参数数量并降低了运算复杂度。此外,当运行时间相同时,因为注意力门LSTM结构使得每个时间步在计算时,上一刻的细胞状态自行决定需要注意的特征,对需要注意的特征进行加权,并在权重较小的地方利用候补值进行补充,所以LSTM+deepf_1模型的收敛速度要明显优于传统LSTM模型和GRU模型。
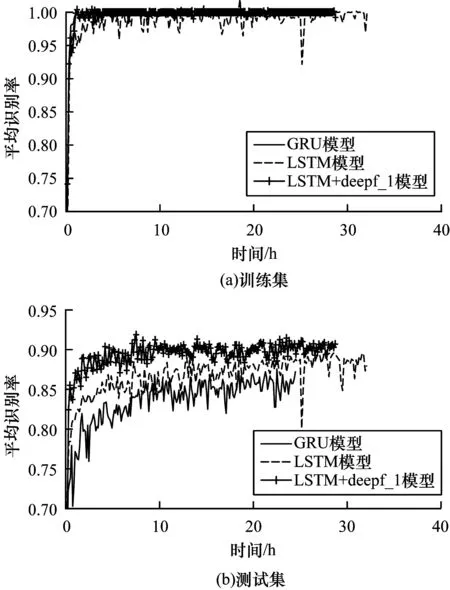
图5 不同模型采用CASIA汉语情感语料库训练 1 200次的所用时间曲线
由图6可以看出,LSTM+deepf_1模型的平均识别率最大,传统LSTM模型次之,GRU模型最小。这是因为虽然GRU模型参数数量减少的更多且训练时间更短,但是随着数据集的不断迭代,其模型结构复杂度比传统LSTM模型更低,平均识别率比传统LSTM模型更小;LSTM+deepf_1模型通过注意力算法在每个时间步对细胞状态进行主动筛选,减少了模型的参数数量和训练时间,显著地提升了识别性能。

图6 不同模型采用CASIA汉语情感语料库的性能情况
5 结束语
本文提出一种基于改进LSTM网络的儿童语音情感识别模型,用帧级语音特征代替传统语音特征,将注意力机制引入LSTM网络模型内部结构的遗忘门和输入门并形成注意力门,按照自定义的深度建立基于深度注意力门的LSTM模型。实验结果表明,在婴儿哭声和儿童情感数据库上,本文模型的识别率显著高于传统LSTM模型,且深度模型的识别率比浅层模型的更高。在包含其他情感的CASIA数据库上,本文模型训练时间短于LSTM模型,且识别率高于LSTM模型和GRU模型。下一步将把本文模型引入语音识别、机器翻译以及测谎等领域,对连续情感的语料库进行测试和研究并改进计算注意力分数的模型,进一步提升儿童语音情感识别率。
