基于主动学习的离群点集成挖掘方法研究
2020-06-18赵晓永王宁宁
赵晓永,王宁宁,王 磊
北京信息科技大学 信息管理学院,北京100129
1 引言
离群点是指与数据集中的其他数据有明显偏离,使人怀疑这些数据点是由不同机制产生的[1]。离群点检测(Outlier Detection),也称为离群点挖掘(Outlier Mining),因其在金融欺诈、网络入侵、故障检测、生物信息等领域有着广阔的应用前景,受到了广泛关注和研究。
离群点检测任务通常缺少可用的标注数据,且离群数据只占整个数据集的很小一部分,因此,相较于其他的数据挖掘任务,离群点检测的难度较大。目前对于离群点检测的研究主要可分为以下几类:(1)基于概率统计的检测方法,包括基于直方图[2-3]和图基测试(Tukey Test)[4]的检测方法等;(2)基于相似性的检测方法,包括基于聚类[5-6]、近邻距离[7-8]和密度[9-10]的检测方法;(3)基于分类的方法,包括基于浅层神经网络、基于支持向量机的二元分类方法和深度自编码器方法[11-12];(4)对高维数据的子空间划分方法,包括孤立森林等[13-14];(5)基于信息论的检测方法[15-17]。
由于离群点检测任务的复杂性,尚没有单一的算法适合于所有的场景,因此研究人员提出了基于模型集成的检测方法[18],以降低单一算法带来的风险。其中,文献[19]设计了在离群点检测中使用不同的特征子集的方法,并将它们组合以提供更有效的结果。文献[20-22]中展示了如何组合来自离群值检测算法发现的不同子空间的分数,以便提供统一且更稳健的结果。文献[23]借鉴随机森林方法思想,提出了离群点检测的孤立森林(Isolation Forest)概念,并在工业界中得到了广泛的应用。
鉴于领域专家知识的应用对提高离群点的识别效果总是非常明显[1],研究人员尝试将主动学习(Active Learning)应用于离群点检测,使得人类专家可以将领域知识,进而将无监督的离群点检测问题转换为有监督的稀有类别检测问题方面。文献[24]中提出了基于主动学习的离群点检测方法,从未标记的数据迭代主动地学习,在每次迭代中,算法确定有助于进一步分类的“重要的”示例,呈现给人类专家,由其为这些示例进行标注,然后使用这些标记后的数据对数据集进行分类。
结合多样性模型集成和主动学习思想,本文提出了一种基于主动学习的离群点集成检测方法OMAL(Outlier Mining based on Active Learning)。在主动学习框架指导下,首先根据各种基础学习器的对比分析,选择基于统计的HBOS、基于相似性的模型iORCA、基于轴平行子空间划分的Isolation Forest共3个无监督模型作为基学习器;然后,将各基学习器评判的离群分数处于离群和正常边界的数据合并后呈现给人类专家进行标注,这样可以最大化人类专家反馈的信息量[24];从标注的数据集和各基学习器投票产生的数据集中抽样75%训练基于GBM(Gradient Boosting Machine)[25]的有监督二元分类模型,将该模型应用于全数据集,得出最终的挖掘结果;最后,使用文献[26]和[27]中的数据集进行实验,结果表明本文提出方法的AUC(Area Under Curve)有了较为明显的提升,且具有良好的运行效率,具备较好的实用价值。
2 方法设计
2.1 OMAL总体框架
在主动学习框架指导下,本文提出的离群点集成挖掘方法整体流程如图1所示。

图1 OMAL整体流程图
首先使用分析对比后选择的3个无监督基学习器对原始数据进行离群挖掘,根据各基学习器的输出,采用算法1呈现出少量重要数据给专家进行标注,采用算法2的集成方式产生部分带标注的训练数据集,并与专家标注的数据集整合后,去训练基于GBM的二元监督分类模型,然后将该模型应用到原始数据上,得到最终的离群挖掘结果。
2.2 基学习器的选择
目前主要的无监督离群检测算法如表1。
诸多学者已经对上述算法进行了多种对比研究,Sugiyama等人对比了iForest、FastVOA、iORCA、One Class SVM、LOF和子采样Sugiyama-Borgwardt方法在多种数据集上的表现,其中Sugiyama-Borgwardt、iORCA和iForest效果最佳,表明采样能大幅提升处理性能,同时保证准确性[7];Lazarevic等基于KDD Cup99数据集,对比了LOF、k-NN、PCA和One-Class SVM算法[19];Campos等人对基于距离(k NN k NNW)、密度(LOF、SimplifiedLOF、LoOP、COF、LDF、INFLO、LDOF、ODIN、KDEOS)和角度(FastABOD)的方法进行了对比,结果表明k NN k NNW和LOF是这些方法中统计最优的,特别是在离群点数量较多的情况下更为突出,在离群点数量较少的情况下,SimplifiedLOF和LoOP效果与LOF相近;LDF在某些情况下有最好的效果,但非常不稳定,FastABOD非常稳定,但效果较差[26]。Goldstein等人的研究表明,局部离群检测算法(LOF、COF、INFLO、LoOP、LOCI、LDCOF、CMGOS)只适合于仅包含局部离群点的数据集,在包含有全局离群点的数据集上,会产生许多误检;相反,全局离群检测算法(HBOS、Robust PCA、K-NN、uCBLOF、One-Class SVM)不仅可检测全局离群点,对于局部离群问题,可至少达到平均水平,在对数据集没有先验知识的情况下,建议优先选择全局离群检测算法[27]。Ding等人对比了SVDD、K-NN、K-Means和GMM在10个不同数据集上的离群检测效果[28];Liu等人对比了iForest、SciForest、ORCA、One Class SVM、Random Forest和LOF在多个数据集上的表现,指出iForest对全局离群点检测问题最有效,SciForest对局部离群点检测问题最有效[29-30]。Zimek等的研究表明,在无监督的离群点集成算法中,采取多样性的基模型有助于提升最终的效果,且不同类型的模型集成优于不同参数的同类模型集成[31]。

表1 主要的无监督离群检测算法
综合上述文献的研究成果,结合本文研究方法的特点,给出基学习器的选择原则:
(1)近线性时间复杂度。主动学习框架中需要人类专家参与,时效性是保证闭环顺利进行的核心要素,因此,各基学习器的时间复杂度是第一重要的选择指标。
(2)模型的鲁棒性。各基学习器需要在不同数据集上有稳定的表现。
(3)模型的多样性。多样性的模型集成可发现不同原因产生的离群点,提升最终检测效果。
(4)模型可解释性。模型可解释性允许领域专家更好地理解基学习器发现的离群点,从而更好地进行标注。
因此,本文选择了基于统计的HBOS、基于相似性的模型iORCA、基于轴平行子空间划分的Isolation Forest共3种类别的、近线性时间复杂度的、无监督模型作为基学习器。
2.3 监督模型训练集的构造
为了将离群点检测转换为有监督的过程,需要构造出用于训练的有标注数据集,标注主要来源于两个方面:人类专家的标注、基学习器的结果整合。
为了减少人类专家的标注工作量,同时最大化标注的价值,需要将能够为系统带来最多反馈信息的数据呈现给人类专家[32],算法1描述了人类专家标注训练集构建的具体过程。
算法1人类专家标注训练集构建算法
输入:各基学习器的输出S1~S3
输出:带标注的数据集D
(1)从各基学习器的输出S1~S3中,根据学习器的评分,获取处于离群和正常边界的离群数据各m(m=min(10,可用数据))条、正常数据各n(n=min(5,可用数据))条,则从S1~S3中可得到待标注离群数据集A1~A3(不超过30行)和待标注的正常数据集N1~N3(不超过15行);
(2)将A1~A3 N1~N3分别合并去重后可得待标注离群数据集A、待标注的正常数据集N;
(3)在A和N中重复的数据,将其从N中删除;
(4)将A和N按照离群程度降序排列后呈现给人类专家进行标注;
(5)A和N合并为D并输出,算法结束。
基学习器的结果整合是集成学习的关键点,但由于各学习器输出结果的含义和尺度的差异,结果整合仍然是集成学习中的难点[31]。由于本文的方法并不需要将基学习器的模型进行整合,因此无需对输出结果在含义和尺度上进行融合;另一方面,依据没有免费午餐定理NFL[33-34],在分布未知的多种数据集上,各基学习器的平均表现是相当的,因此采用了未加权的简单投票(Major Vote)方法,算法2描述了基学习器投票标注训练集的具体过程。
算法2基学习器投票标注训练集算法
输入:各基学习器的输出S1~S3
输出:带标注的数据集E
(1)将各基学习器的输出S1~S3拆分为离群数据集Sa1~Sa3和正常数据集Sn1~Sn3;
(2)对Sa1~Sa3进行简单投票,将在一半以上数据集中出现的,作为训练用的离群数据集A;
(3)从Sn1~Sn3的交集中抽样75%,作为训练用的正常数据集N;
(4)A和N合并为E并输出,算法结束。
将算法1和算法2的输出结果D和E合并形成最终的训练数据集,当遇到标注冲突的数据时,以D中的标注为准。
2.4 有监督分类算法的选择
首先,由于离群数据的稀有特性,2.3节构造出的训练数据集仍然是不平衡的,而常用的过采样、欠采样方法均不适于离群挖掘场景[35],因此,需要能够支持不平衡数据集的二元分类算法;其次,人类专家标注训练集后,会希望能尽快获得最终的离群挖掘结果,这也就要求有监督模型必须有较高的训练和预测性能。
Friedman等人提出的GBM(Gradient Boosting Machine)是一种Boosting集成学习模型,支持不平衡数据集的二元分类,具有可高度定制的灵活性、训练速度快且可并行化、易于调参和可解释性强等优点[36],在各大数据挖掘竞赛和工业界均有广泛的应用并取得了良好的效果[37],因此,本文选择基于GBM的有监督二元分类算法。
3 实验
3.1 实验环境
本文的实验环境为1台8核32 GB内存,500 GB硬盘容量的Dell R620服务器,操作系统为Ubuntu 16.04。
测试数据为文献[26]和[27]使用的30个公开数据集,这些数据集也被许多离群点挖掘的文献使用,其中kdd99、shuttle和annthyroid数据集在两篇文献中分别做了不同的处理,数据集的情况如表2。
OMAL算法中各基学习器HBOS、iORCA和iForest参数设定分别使用各算法提出者文献中的推荐设定;并基于lightgbm实现有监督二元分类监督模型,设置unbalanced参数后可支持不平衡数据集二分类。将OMAL算法与各基学习器HBOS、iORCA和iForest独立运行时的结果进行对比,各基学习器也采用各算法提出者文献中的推荐设定。采用无监督离群挖掘算法评价的事实标准AUC其作为评价指标[1]。
3.2 实验结果
图2显示了本文使用的基学习器在各数据集上的运行时长情况。得益于此三种基学习器的近似线性时间复杂度(参见2.2节),对于6万行以内的数据集,人类专家需要等待的时间均在3 s以内,由于大脑的短时记忆效应,此时间间隔内人们不会感觉到明显的等待[38]。
图3显示了本文提出的OMAL算法与三种典型的基学习器方法的对比结果,可以看出,得益于人类专家反馈的信息,本文的OMAL方法在这些数据集上的AUC值都有了较为显著的提升。

表2 数据集情况
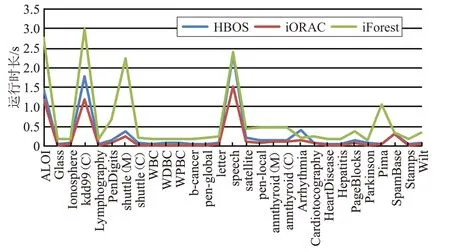
图2 基学习器运行时长
4 结论
针对目前的离群点挖掘方法尚未有效解决专家知识应用、扩展性和准确率三者之间的平衡问题,本文结合主动学习和模型集成,提出一种基于主动学习的离群点集成挖掘方法OMAL,结合多个无监督基学习器的学习结果与人类专家知识,训练出有监督的二元分类模型,在减少工作量、提升扩展性的同时,达到了较高的准确率。实验表明,OMAL方法在提供更好的离群点挖掘效果的同时,具有良好的运行效率,具备较好的实用价值。不过,在主动学习过程中,如果能经过人类专家的多轮指导,可获得更多的反馈信息,有助于提升系统效果,但如何呈现每轮次的待标注数据以优化信息反馈效率,如何处理每轮次标注后的样本集以优化下轮无监督学习器的输出,如何根据每轮次的反馈调整各基学习器的权重,是需要进一步研究的问题。

图3 算法AUC结果对比
