基于XGBoost 算法的复杂碳酸盐岩岩性测井识别
2020-06-17孙予舒季汉成向鹏飞徐新蓉
孙予舒,黄 芸,梁 婷,季汉成,向鹏飞,徐新蓉
(1.中国石油大学(北京)地球科学学院,北京 102249;2.中国石油大学(北京)油气资源与探测国家重点实验室,北京 102249;3.中国石油华北油田分公司勘探开发研究院,河北任丘 062550)
0 引言
岩性识别是储层评价中重要的研究内容之一。目前识别岩性最可靠的方法为钻井取心,然而,受取心成本较高以及取心率不高等问题的限制,常常不能做到全井段取心。因此,在实际勘探过程中,利用测井资料间接对目的层进行岩性解释成为了研究储层的重要手段。
目前利用测井数据进行岩性解释的方法主要分为传统的测井岩性解释方法,以及基于机器学习的智能化方法[1]。前者包括:基于测井曲线响应特征的定性解释方法、基于测井响应方程的定量解释方法、图版法;后者则包括:支持向量机、神经网络和分类决策树等方法。对于碳酸盐岩来讲,由于其矿物成分较为单一,测井岩电响应特征不明显[2]。同时,由于各测井曲线间存在着大量的信息冗余,导致其相关性较高,因此仅运用测井曲线资料难以全面而准确地识别岩性。因此,传统的测井解释方法在判断复杂碳酸盐岩岩性上有很大的局限性,大部分方法仅能识别出灰岩和白云岩或3~4 种岩性[3-4]。随着机器学习技术的不断发展,采用机器智能化学习的手段识别复杂碳酸盐岩岩性成为了研究的热点,不少学者已经采用向量机[5-6],神经网络[7-9],模糊识别[10-11]和传统决策树方法[12-14]识别复杂碳酸盐岩岩性或碳酸盐岩成岩相,然而这些方法普遍采用单一学习器进行学习,不能对错误样本进行二次学习,对复杂碳酸盐岩的岩性识别具有一定的局限性。近年来,Chen 等[15]在梯度提升决策树算法(GBDT)的基础上进行了改进,提出了一种设计高效、灵活并且可移植性强的最优分布式决策梯度提升库XGBoost。其原理是通过弱分类器的迭代计算从而实现准确的分类效果,具有高效性和扩展性强的特征[16]。其优势主要在于在代价函数中引入了正则化项,控制了模型的复杂度,降低了模型的方差,防止模型过拟合。同时该算法会在完成一次迭代之后,将叶子节点的权重与缩减系数相乘,来进一步缩减某一个决策树对整体的影响,从而使得后面有更多的学习余地,使其判断的准确性较同类方法得到有效提升。同时,该方法之前也鲜用于测井解释。鉴于此,笔者以测井、录井资料为基础,采用XGBoost 系统对廊固凹陷北部奥陶系建立碳酸盐岩识别模型,并以最终分类结果的准确率作为评价标准,验证XGBoost 算法应用于测井岩性识别的可行性,以期为复杂碳酸盐岩岩性的测井识别提供新思路。
1 XGBoost 算法的原理
GBDT 算法由决策树和梯度提升两部分组成,是Friedman[17]提出的一种Boosting 算法。该算法通过让每一轮迭代得到的损失函数沿着梯度方向下降来构造一个弱分类器函数,然后把多个弱分类器的结果以一定权重组合形成强分类器作为最终的预测输出[18],其训练过程如图1 所示。
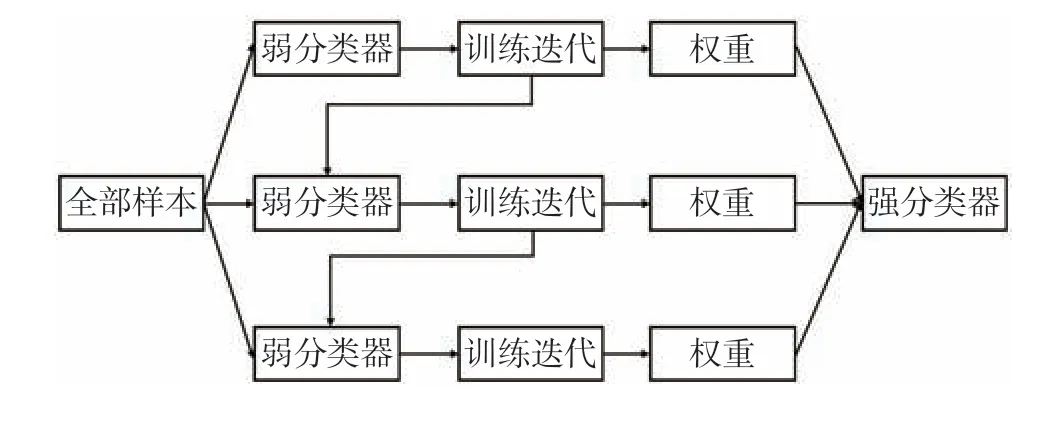
图1 GBDT 的训练原理(据文献[17]修改)Fig.1 GBDT training principle
XGBoost 是GBDT 算法的优化。其特点在于模型能自动利用CPU 进行多线程并行计算,提高运算速度,并且对损失函数进行泰勒公式二阶展开使得预测精度更高,在损失函数后面增加正则项,可以约束损失函数的下降和模型整体的复杂度[19]。XGBoost 的目标函数T为

式中:l为损失函数;k为分类回归树的个数,个;i为模型的预测值;yi为样本xi的分类标签;Ω为正则惩罚项函数;fk为第k个树的模型。

式中:J为每个分类回归树叶子节点的数量;ω为该个树叶子节点的权重之和;γ和λ 为惩罚系数,为常数,在具体应用中可以调节。
对于第t轮迭代,模型的目标函数为

式中:ft(xi)表示第t个分类回归树;c为常数项。
对式(3)进行二阶泰勒展开
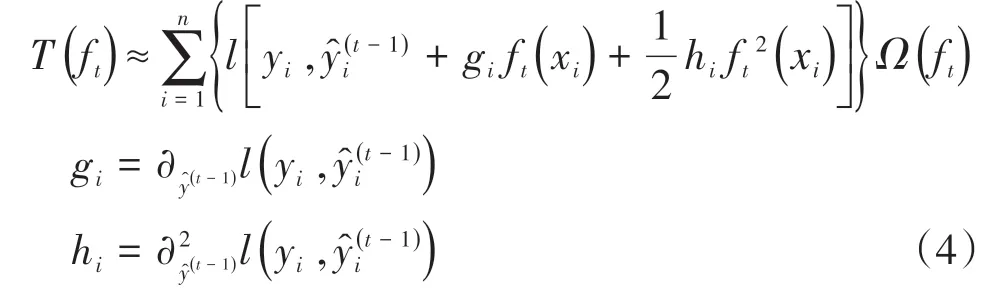
式中:gi表示的一阶导数;hi表示的二阶导数。
化简后,最终目标函数的形式为
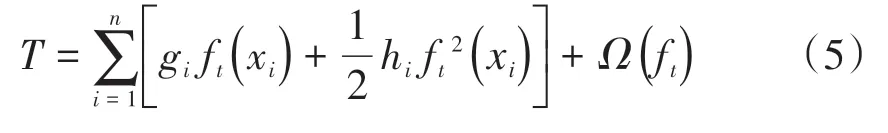
2 应用实例
2.1 研究区概况
本次研究数据来源于廊固凹陷北部奥陶系碳酸盐岩地层,通过层序和岩相古地理分析,整体为潮坪相沉积;研究区地层经历了加里东运动、海西—印支运动、燕山运动和喜山运动等多次构造作用,风化剥蚀作用强烈。因此导致该区地层经历的成岩作用较为复杂,岩性变化较为频繁,形成的岩石类型较为多样。根据研究区取心井段的岩心观察和薄片镜下鉴定结果,识别出该研究区地层主要发育灰岩、泥质灰岩、白云质灰岩、灰质白云岩、泥质白云岩、白云岩等6 种碳酸盐岩类型(图2)。其中,含油气储集层主要发育在白云岩和白云质灰岩段。所以,对于研究区地层岩性有效的识别是储层评价的重要步骤,对后续进行油气储层预测具有重要意义。

图2 研究区碳酸盐岩岩性镜下识别(a)白云质灰岩,安探2 x 井,5 186.0 m,下马家沟组上段,单偏光;(b)泥晶灰岩,安探101 x 井,5 815.0 m,上马家沟组上段,单偏光;(c)泥质灰岩,安探4 x 井,峰峰组上段,4 805.3 m,单偏光;(d)灰质白云岩,务古1 井,4 865.0 m,峰峰组下段,单偏光;(e)泥质白云岩,安探3 井,4 806.2 m,峰峰组下段,单偏光;(f)粉晶白云岩,安探5 x 井,5 965.0 m,亮甲山组,单偏光。其中蓝色部分为铸体,红色为茜素红染色的方解石Fig.2 Microscopic identification of carbonate lithology in the study area
2.2 样本构建
本文采用研究区内目的层7 口井共2 101 个数据点作为岩性识别模型的数据集,其中将89 个取心样品和537 个随井XRD 数据作为本次模型的训练集,训练集中各个岩性的样本比例如表1 所列,其余1 475 个随井XRD 数据作为测试集来验证XG‐Boost 算法的岩性识别效果。
在建立岩性识别模型时,选取的测井曲线类型会直接影响预测精度,故须要进行测井属性优选。本文调研了前人在碳酸盐岩储层相关研究中常用的测井曲线[20-24],选取了对碳酸盐岩岩性比较敏感的声波时差(AC)、自然伽马(GR)、光电吸收截面指数(PE)、补偿中子(CNL)、补偿密度(DEN)、深侧向电阻率(RLLD)等6 种测井曲线作为模型样本的属性值(表2)。结合研究区不同类型碳酸盐岩典型岩性测井响应特征(图3),挑选研究区内每种岩性中最符合岩性描述的深度段具有的测井响应特征制成图版,使其具有一定的代表性。从图3 可以看出,不同岩性的测井响应特征不同,泥质灰岩和泥质白云岩的GR值与其他4 种岩性相差较大,其典型测井曲线值为80~130 API,灰岩、灰质白云岩、白云质灰岩和白云岩的GR值均较小,为0~50 API;AC,DEN,PE这3 条测井曲线在不同岩性中响应特征的区分度较差,形态上也没有太大波动,具体来讲,研究区灰岩的DEN值稍低,PE值稍高,白云岩的PE值稍低;从CNL上看,泥质白云岩和灰质白云
岩的值稍高,为8%~10%,其次是白云岩,为5%~8%,灰岩、泥质灰岩和白云质灰岩的值十分接近,均为0~5%;RLLD曲线特征主要呈现为泥质灰岩和泥质白云岩的相对低值和白云质灰岩、灰岩和白云质灰岩的相对高值,白云岩的RLLD值位于这两类岩性之间。

表1 训练集不同岩性样本比例Table 1 Proportion of different lithological samples in the training set%

表2 研究区不同岩性原始测井响应特征统计Table 2 Original logging response characteristics of different lithologies in the study area

图3 研究区不同类型碳酸盐岩典型测井响应曲线特征Fig.3 Characteristics of typical logging response curves of different types of carbonate rocks in the study area
和砂岩的岩性识别不同,碳酸盐岩通常由于矿物成分相似,非均质性较强,使用单一曲线往往很难识别其中的过渡类型。虽然泥质灰岩和泥质白云岩的典型测井特征与其他类型碳酸盐岩有所区别,但从整体来看,研究区不同类型碳酸盐岩的测井曲线区别不是十分明显,取值区间较为重叠,说明单一使用某一测井曲线数据无法达到识别碳酸盐岩岩性的目的。为了进一步探究测井曲线的相关性,通过交会分析各类测井响应参数对于储层的敏感性,并用置信椭圆来加以表征(图4)。椭圆越窄,说明2 种测井曲线在该岩性中的相关性较好,对于岩性区分有效性较强。在同一个二维测井交会图中,不同岩性的椭圆离散,说明该二维交会图对岩性的区分度较好。研究样本结果表明,在研究区内的碳酸盐岩样品中,CNL和PE,CNL和RLLD以及GR和DEN的置信椭圆较窄(长轴与短轴之比大于2),总体上看,不同岩性之间的置信椭圆分散程度一般。因此,二维测井曲线交会图版不能将复杂碳酸盐岩岩性很好地区分开,须要采用机器学习的方法进一步识别研究区碳酸盐岩岩性。

图4 二维测井响应参数置信椭圆交会图(90%置信区间)图中置信椭圆表示90%的点所落到的区域,椭圆越窄,说明2 种测井曲线相关性越好,椭圆越分散,说明测井响应参数对岩性的判别越敏感Fig.4 Two-dimensional logging response parameter confidence ellipse intersection graph
2.3 数据处理
由于XGBoost 在进行建模时不能识别字符串类型的文本,为了方便编程处理以及避免简单用数值替换后数值的大小对模型产生影响,本文对岩性标签采用了One-HotEncoding 进行了编码,通过One-Hot 编码将岩性的n个取值转换为n个二元特征,以稀疏矩阵的形式储存在模型的标签列中。在进行算法识别岩性时,不同类型的测井曲线具有不同的量纲和数量级,其差异性会对模型的识别精度产生影响,故对6 种测井曲线进行了标准化处理,由于不同井的测井曲线属性值大小不一,也不存在统一的上下限标准,因此本文采取标准分数的方法进行标准化,其计算式为

式中:z为标准化处理后的数据;x为样本数据;μ为样本数据均值;σ为样本数据的标准差。
2.4 模型应用及对比
2.4.1 模型参数设置
通过XGBoost 算法建立岩性识别模型,其中对模型性能影响较大的参数主要为:迭代次数,即生成决策树的个数t,若迭代次数太大则容易使得模型过拟合,从而导致模型的泛化能力下降;学习率eta,用于控制每一次迭代的步长,提高模型的稳定性,学习率太高会降低模型识别的正确率,太低则会影响模型的运算速度;最大树深度Dmax与子节点中最小样本权重和Wmin,如果一个叶子节点的样本权重和小于设置的Wmin,则此次叶子节点的拆分过程结束。该参数用于控制模型的复杂度,树太浅会降低模型的准确率,树太深则会使得模型过拟合,降低模型的泛化能力;叶子节点所需的最小损失函数的下降值γ,γ值越大,算法越保守,计算时间越长;以及用于增加模型随机性的参数随机采样训练样本的比例S,若将S设置为0.5 表示XGBoost 将随机从整个样本集合中抽取50%的子样本建立树模型,通过调整S的大小,可以提高模型的稳定性,增加最终识别的正确率。
由于本次模型所用数据规模较小,故采用k-折交叉验证的方法对模型的参数进行调优。k-折交叉验证的过程是将数据集分成k份,轮流将其中k-1份作为训练数据,剩余的1 份作为测试数据进行试验。每次试验都会得出相应的测试正确率,k次测试正确率的平均值作为最终的测试正确率[25],在本次调优中根据样本量较小的特点将k的值取5。在模型参数为默认值的情况下(eta=0.3,Dmax=6,Wmin=1,S=1,γ=1)对迭代次数进行调优(图5),从图中可以看出,随着迭代次数的增加,模型测试集的对数似然损失值逐渐下降,迭代到420 次左右逐渐稳定在0.27 左右;模型的错误率随着迭代次数的增加先下降后上升,迭代到660 次左右后错误率取得最小值,为0.112,以选取最小误差和迭代精度不再出现明显变化为原则,最终选定岩性识别模型的迭代次数为660 次。
在确定迭代次数的基础上,对模型的其他参数进行调优,其中对eta,S,γ的调优步长设置为0.1,Dmax,Wmin的调优步长设置为1,并按照eta,Dmax,Wmin,S和γ的顺序依次进行调节,最终调节完成后模型的参数为eta=0.1,Dmax,=10,Wmin=6,S=0.5,γ=0.1。

图5 模型的对数似然损失值(a)和错误率(b)随迭代次数的变化Fig.5 Logloss value(a)and error rate(b)of the model vary with the number of iterations
2.4.2 实验结果及方法对比
通过交叉检验对模型参数调节后,进行模型的训练,并采用测试集样本对建立的岩性识别模型预测效果进行验证,结果如表3 所列。

表3 岩性识别模型预测结果Table 3 Prediction results of lithology identification model
从表3 可以看出,模型对灰岩和白云岩的识别效果均较好,识别准确率分别达到了91.76%和90%,其次是泥质灰岩、白云质灰岩和泥质白云岩,这3 种岩性的识别率均达到了85%以上,灰质白云岩的识别准确率较低,仅为81.25%。对灰质白云岩识别率较低的问题,本文采取了多种方式调节参数均不能提高其准确率,这可能是因为所选取的测井曲线对灰质白云岩的敏感程度较低。若想进一步优化,可以采取构造测井曲线的特征参数等特征工程进一步提高岩性识别的准确率[26-27]。
同时将采用XGBoost 算法的岩性识别结果与采用分类决策树、支持向量机方法所得到的岩性识别结果进行比较(表4)。其中,分类决策树采用C4.5 算法,表4 中的运行时间为训练和测试模型的总时间,准确率是测试的结果。为进一步证明XG‐Boost 算法对碳酸盐岩岩性识别的优越性,本文在测试集中选取了XRD 测试数据密度较大的安探4 X 井进行了单井预测验证(图6)。与XRD 测试数据的对比结果显示,XGBoost 方法对于碳酸盐岩岩性识别较为准确,尤其是在岩性快速变化及曲线变化特征不明显的井段,XGBoost 相较于SVM 和决策树方法可以更准确地作出响应,识别率更高。

表4 不同模型的性能比较Table 4 Comparison of performance of different models
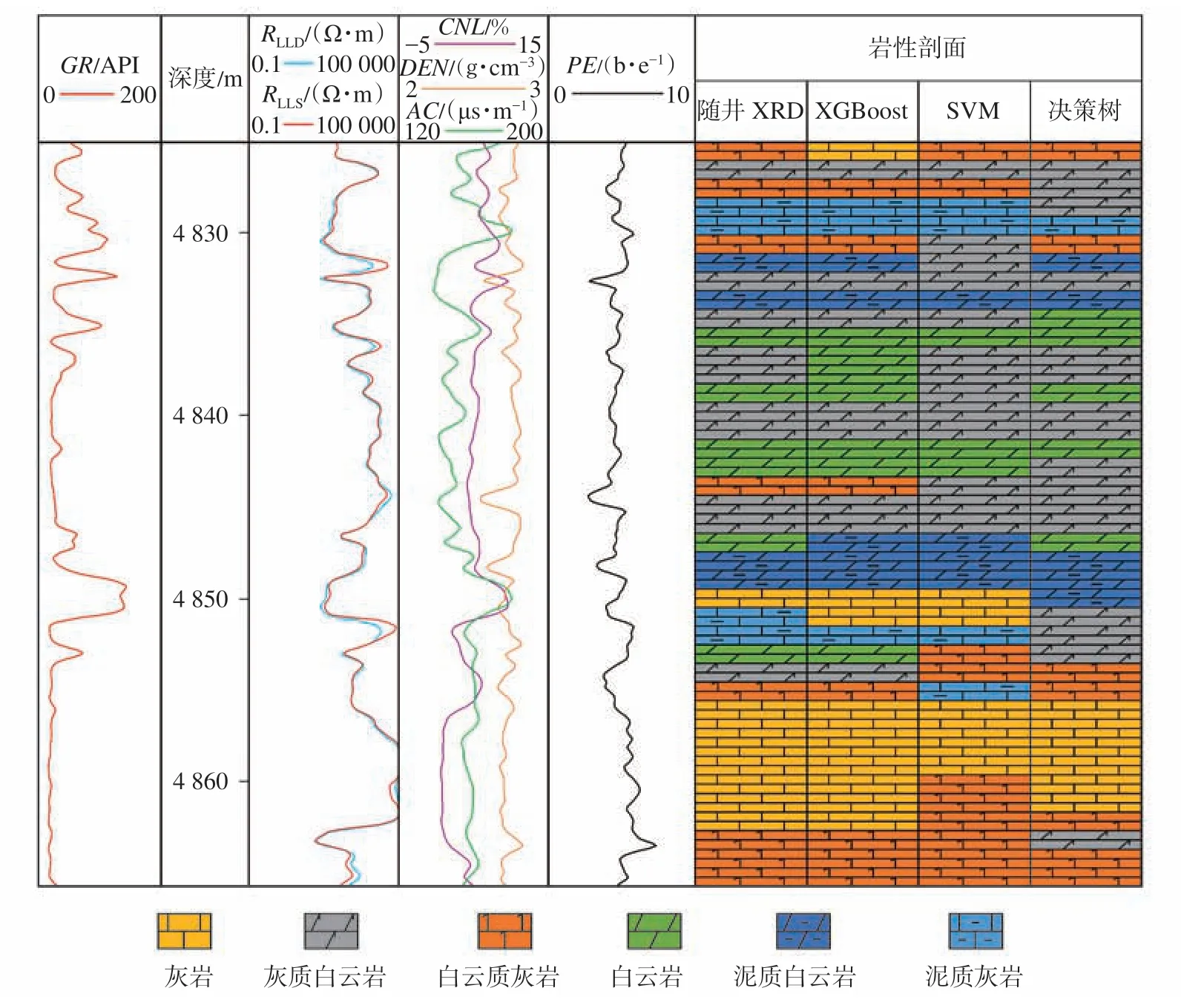
图6 安探4 x 井单井岩性识别效果图Fig.6 Lithology identification results of well Antan 4x
对于廊固凹陷北部奥陶系碳酸盐岩地层,XG‐boost 识别模型对于岩性识别的准确率为三者最高,达到了88.18%(表4)。其次是分类决策树,岩性识别的准确率为76.64%,支持向量机的性能较弱,识别的准确率为73.59%(表4)。从时间上来看分类决策树和支持向量机的耗时相近,分别为2.27 s 和2.45 s,XGBoost 由于采用多个弱分类器组合的方式进行机器学习,其运算相对于其他2 种算法耗时稍长,为3.52 s,由于其采用并行运算,在进行较大模型性训练和测试时并不会大幅度增加运算时间。
综合来看,采用XGBoost 算法构建的复杂碳酸盐岩岩性识别模型,通过采用对多个弱学习器的线性组合以及在损失函数后面增加正则项的方式,在稍微增加了运算时长的情况下提升了其岩性识别的准确率,为复杂碳酸盐岩岩性的测井识别方面提供了新的思路。
3 结论
(1)XGBoost 算法的优势主要在于在代价函数中引入正则化项,控制了模型的复杂度,降低了模型的方差,防止模型过拟合。同时在完成一次迭代之后,将叶子节点的权重,乘上缩减系数,来缩减一颗树的影响,从而使得后面有更多的学习的余地,可以很好地解决常规测井岩性识别方法中过拟合以及准确性不高的问题,使其在利用测井信息在岩性识别的准确性上较同类方法得到有效提升。
(2)模型对灰岩和白云岩的识别效果均较好,识别准确率分别达到了91.76%和90%,其次是泥质灰岩、白云质灰岩和泥质白云岩,这3 种岩性的识别率均达到了85%以上,灰质白云岩的识别率较低,仅为81.08%,且相较于传统的机器学习模型,其准确率提升了10%以上。验证了XGBoost 算法应用于测井岩性识别方面的可行性。
(3)数据的选取和预处理、模型的参数优化对于模型的准确率有着十分重要的影响。通过测井相关专业知识、置信椭圆的分析,确定了6 种与岩性较为相关的测井曲线作为模型的变量数据,并通过交叉验证和对模型参数的调节确定了初步最优化模型,但参数调优进行模型优化存在优化上限,若想进一步优化岩性识别模型,须采用特征工程、模型组合等方法。
(4)基于XGBoost 算法的岩性识别模型对复杂碳酸盐岩岩性的识别的准确率优于分类决策树、向量机这2 种传统的机器识别方法,且由于XGBoost 算法采用多线程和分布式计算的方法,使得训练时间大大缩短,因此该方法可以应用于数据较为庞大的模型。
