单语数据训练在蒙汉神经机器翻译中的应用
2020-06-16牛向华苏依拉赵亚平仁庆道尔吉
牛向华 苏依拉 高 芬 赵亚平 张 振 仁庆道尔吉
(内蒙古工业大学信息工程学院 内蒙古 呼和浩特 010080)
0 引 言
随着“一带一路”经济带的发展以及国家的大力支持,蒙汉机器翻译的市场需求日趋增大。而神经机器翻译是一种需要数据驱动的方法,其性能很大程度上取决于平行语料库的规模、质量和领域覆盖面。由于神经网络的参数数量巨大,只有当训练数据满足一定的条件时,神经机器翻译的性能才会显著超过统计机器翻译[1]。由于平行语料在质量、数量和覆盖面等方面非常有限,特别是对于像蒙古语这样的低资源语言,因此利用大量单语数据来改善蒙汉神经机器翻译的性能是很有必要的。人类在进行翻译时,首先是理解一句话,然后在脑海里形成对这句话的语义表示,最后再把这个语义表示转化到另一种语言。单语数据训练的思想正是考虑如何缩小人工智能翻译系统和人类翻译之间的鸿沟。基于上述背景,本文提出将单语数据应用到蒙汉机器翻译中。
一般而言,如果没有双语平行数据,而又要实现机器翻译,是非常困难的,主要难点在于如何将目标语言和源语言关联起来。为实现基于单语数据[2-8]训练的蒙汉机器翻译,本文首先通过预训练生成跨语言词嵌入[9];然后利用对抗学习算法[10]构建蒙汉双语字典;接着在训练过程中通过去噪自编码器结合蒙汉单语语料库训练语言模型,并将学习到的双语字典和语言模型相结合初始化蒙汉翻译系统;最后使用回译[11]的方法逐步迭代优化初始翻译系统,使其性能逐渐增强。通过搭建基于单语数据的蒙汉机器翻译系统,并将其性能与基于LSTM[12]神经网络在平行语料库上训练的蒙汉机器翻译系统的性能进行比较,使用BLEU[13]值作为评价指标,实验结果显示,使用123万句对单语数据训练20轮的蒙汉机器翻译系统的性能和使用10万句对蒙汉平行语料库在开源系统OpenNMT上训练8轮的结果相当。本文基于单语语料库训练的蒙汉机器翻译的总体技术路线图如图1所示。
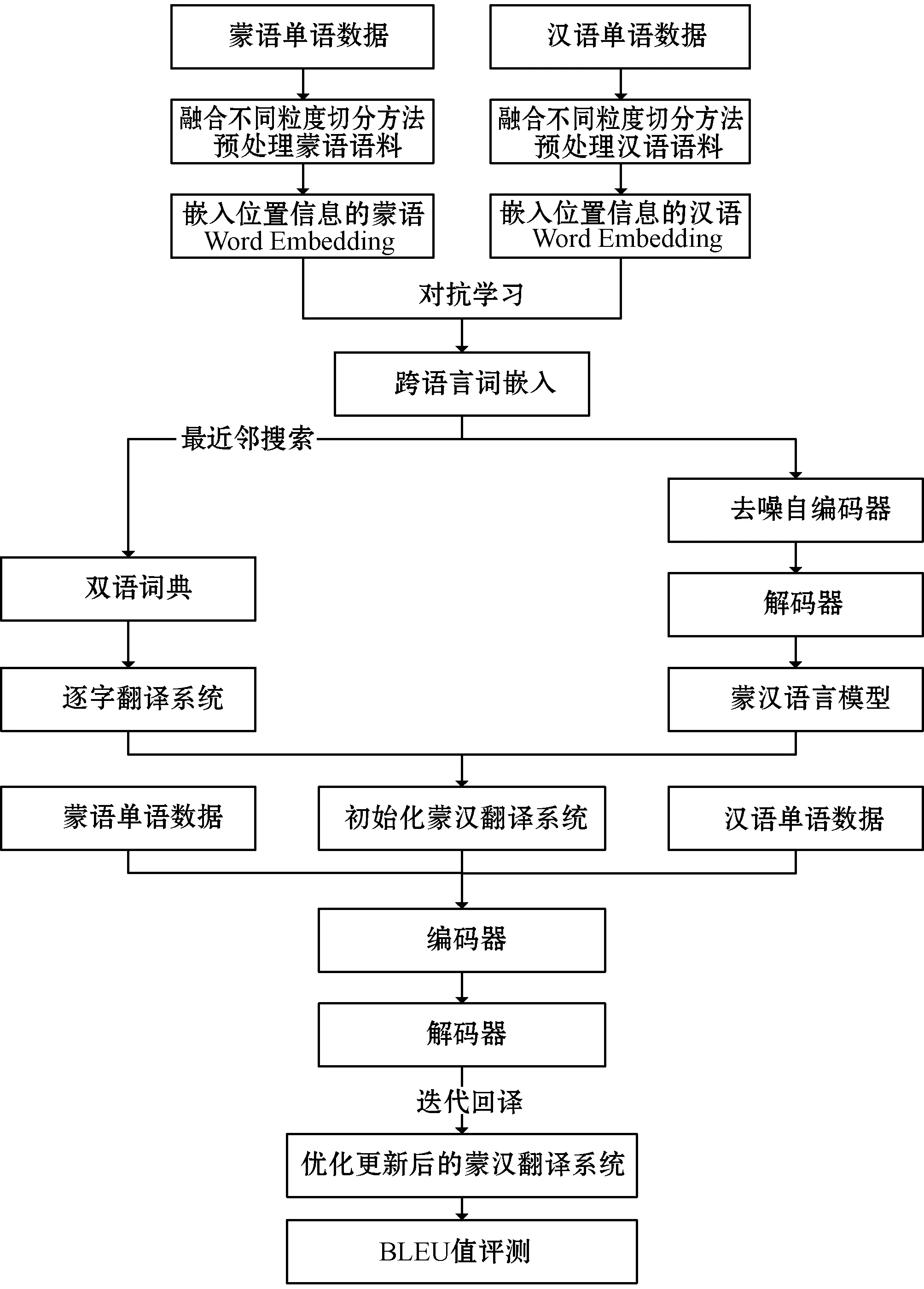
图1 总体技术路线图
1 相关技术
1.1 跨语言词嵌入表示
在端到端的神经机器翻译模型[14]中,如果存在大量的平行数据,只要将数据输入神经网络就能得到两种语言之间的一种对应关系,然而,只有单语数据的情况下,因两种语言的语料之间是毫无关联的,那么使它们产生联系便是实现互译的最重要的一步。本文通过跨语言词嵌入模型将蒙汉两种语言的词向量映射至同一空间,利用对抗训练学习蒙汉两种语言的词向量空间的线性映射,使得蒙汉两种语言的词向量分布在同一空间中时很相似。据此可以假设目标函数为:
(1)
式中:d表示词向量的维度;Md(R)表示实数矩阵空间;M表示蒙古语词向量空间;Z表示汉语词向量空间。通过训练需要学习源语言M和目标语言Z之间的映射关系W,使得两种语言在同一向量空间的分布表示很接近。将任意一个蒙语词S的翻译定义为t=arg maxtcos(Wms,zt)。在实践中,有其他研究者发现如果在W上强制执行正交性约束能够更好地学习到这种映射关系[15],因此式(1)就可以归结为Procrustes问题,从而能够对其做奇异值的分解,以求能更简单地进行求解。
(2)
式中:UVT=SVD(MZT)。
在本文只拥有蒙汉单语语料的情况下,学习映射W过程为:首先通过对抗性训练来学习W的初始值;然后使用两个语料中共享的一些单词作为锚点来进一步对齐向量空间,修正W的值;最后,通过改变向量空间的度量来提高锚点的数量,进一步提高W的准确性。学习映射W的过程如图2所示。
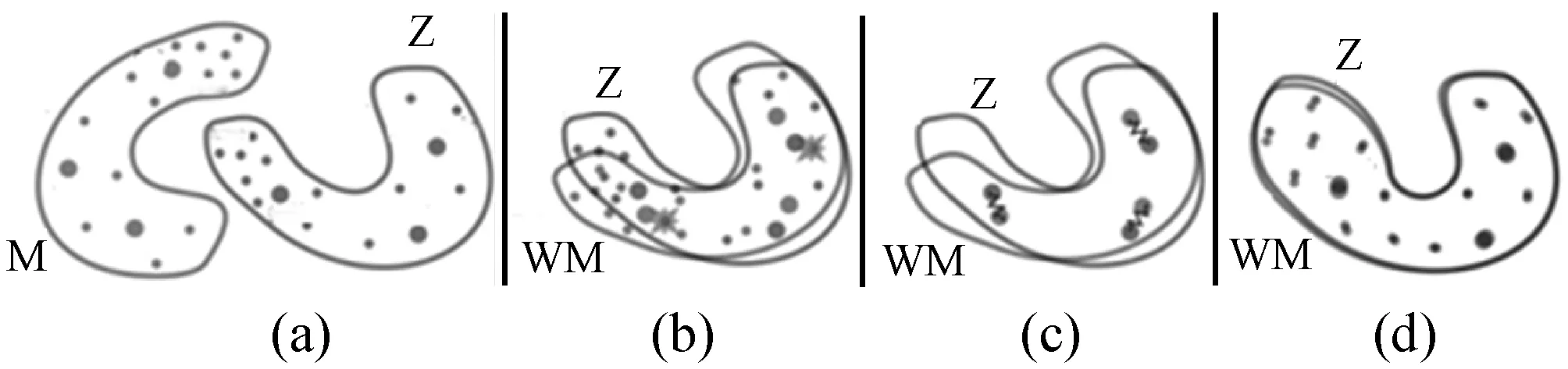
图2 学习映射W的过程
图2(a)表示蒙汉两个词向量分布空间,M表示蒙古语词向量空间,Z表示汉语词向量空间,点代表每一个词向量表示,点的大小表示词在语料库中出现的频率,越大表示出现的次数越多。图2(b)中表示使用对抗训练学习旋转矩阵W,它使得两个分布空间大致对齐,星点表示随机选择的单词,用来被反馈至鉴别器来确定两个词嵌入是否来自同一个词向量分布中。图2(c)中映射W通过Procrustes算法最小化所选择的标点之间的度量系数来进一步修正W,使得两个词向量空间进一步对齐。图2(d)中使用W和空间距离度量扩展锚点数量,进一步提高W的准确性。
1.2 构造蒙汉双语字典
通过预训练跨语言词嵌入模型,本文将蒙汉两种语言映射到了同一词向量分布空间,且学习得到了一个旋转矩阵W。而学习旋转矩阵对齐蒙汉词向量空间的目的就是为了能得到一个蒙汉双语字典,本节主要介绍构造蒙汉双语字典的方法。首先使用最近邻搜索来为一个词找到与之对应的最近邻词,然后使用对抗训练来确保找到的这个对应词是和源词来自不同的词向量分布空间,而不是和它来自同一分布空间的近义词。
1.2.1最近邻搜索
最近邻算法即K最近邻(k-Nearest Neighbor,kNN)算法,是数据挖掘分类算法中最常用的算法之一[16]。本文为缓解在高维空间中寻找最近邻时出现的hubness问题,使用跨域相似性局部缩放(cross-domain similarity local scaling,CSLS)的方法,以期提升互为最近邻的双语词对。计算过程如下:
首先,对于蒙汉任意语言中的任意一个词,都可以在与之对应的另外一个语言中通过余弦相似度和旋转矩阵W知道K近邻,假设其为NT(s)和NS(t),则对于蒙汉两种语言可以定义距离rT和rS,计算公式如下:
(3)
rS的计算过程与rT类似,这个距离就是评估每个词的hubness的标准,r值越大表示一个词和对应语言中的很多词都比较接近。
然后可定义评价来自蒙汉两种语言中两个单词的相似度的CSLS距离如下:
CSLS(s,t)=2cos(Wms,zt)-rT(s)-rS(t)
(4)
从式(4)中可以看出,在计算出Wms和zt的距离之后还对其加入了s和t的hubness惩罚,这样就能缓解某一个词是其对应语言的很多个词的最近邻。因为kNN算法的结果很大程度上取决于K的选择。本文将K设置为5,这样就面临同样分类不精确的问题,所以为了构造一个相对准确的蒙汉双语字典,还使用了对抗训练来区分一个词来自哪一个向量分布空间。
1.2.2生成式对抗网络
生成式对抗网络(Generative Adversarial Networks,GANs)是Goodfellow等在2014年提出的一种无监督学习的训练方法。GANs由生成器和判别器两部分组成,两者都在与对方的对抗中不断提升。生成器和判别器均可以采用深度神经网络实现。GANs的优化过程是一个极小极大博弈问题,优化目标是达到纳什均衡[17],使生成器估测到数据样本的分布。在对抗网络经过对抗过程训练之后,生成网络可以生成接近真实的数据,即接近于训练数据,但又不完全一样。所以,生成网络学习了训练数据的一个近似分布。对于判别网络,也能将其进行训练以达到对数据较好区分的效果。图3展示了对抗学习的过程。
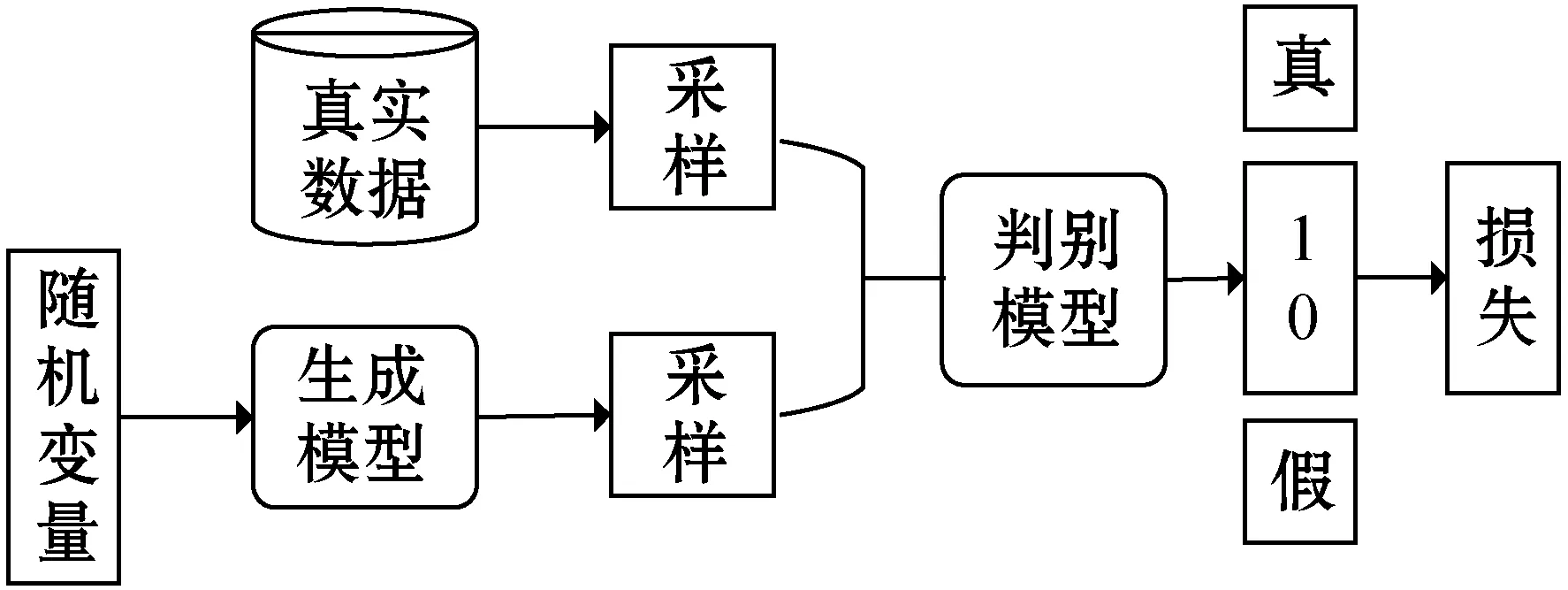
图3 对抗学习过程
设M={m1,m2,…,mn}和Z={z1,z2,…,zn}分别是蒙古语和汉语的词嵌入表示,通过对抗学习来得到一个模型,用来区分随机取出的词是来自WM={Wm1,Wm2,…,Wmn}还是Z={z1,z2,…,zn},这个模型就被称为判别器,而W的目的是使得WM和Z尽可能的相似,所以W就是生成器。因此可将判别器的损失函数和生成器的损失函数定义为:
(5)
(6)
式中:θD为鉴别器参数;W为旋转矩阵;PθD(source=1|z)表示源语言词嵌入和目标语言词嵌入是相互映射的概率。在实际训练中,本文使用随机梯度下降法迭代训练判别器和映射矩阵W,使得目标函数LD和LW分别最小化。
2 蒙汉机器翻译
为了将单语数据应用到蒙汉机器翻译中,本文将给定单语语料,使用对抗学习的算法预训练跨语言词嵌入来对齐蒙汉两种语言的词向量空间,引入去噪自编码器结合多头自注意力机制使用蒙汉单语和双语语料库预训练跨蒙汉语言模型。最后,将迭代回译应用于基于词典逐字翻译的初始化系统,并结合已经训练好的语言模型优化蒙汉翻译模型。
2.1 训练蒙汉语言模型
在无监督机器学习[18-19]中,最常使用的一类神经网络就是自编码器(Autoencoder),其作用就是通过训练输入无标签的数据X=(x(1),x(2),…,x(n)),得到一个降维后的特征表达H=(h(1),h(2),…,h(n)),就像主成分分析一样。简而言之,自编码器就是一种尽可能复现输入信号的神经网络,目的是通过这种复现过程来学习输入数据的重要特征。自编码器的实现过程如图4所示。其中,将原数据输入一个编码器中,就会得到这个输入的一个特征表示为了判断这个特征表示的是否为输入的数据。本文通过添加一个解码器来实现解码器输出一个信息,如果输出的这个信息和一开始的输入信息是很像的,那么就证明这个特征表示是可用的。所以,通过调整编码器和解码器的参数,使得重构误差最小,就能得到输入信号的一个准确的特征表示。因为是无标签数据,所以误差的来源就是直接重构后的数据与原输入数据相比得到的。
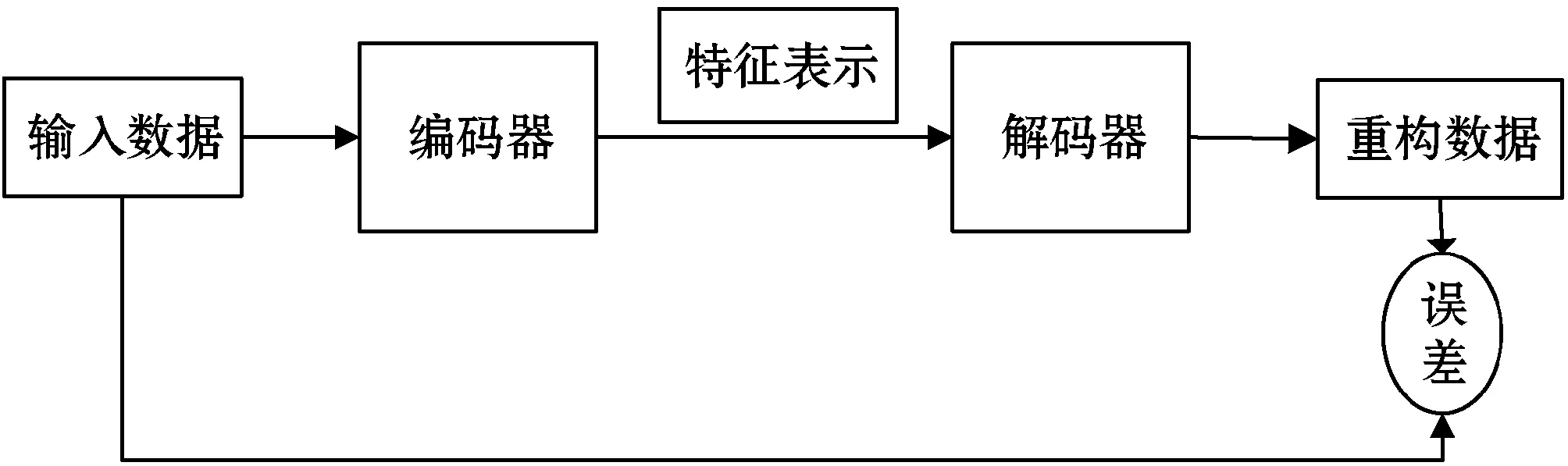
图4 自编码器实现过程
而降噪自编码器(Denoising AutoEncoders,DAE)是自编码器的一个变体,它是在自编码器的基础上,给输入的训练数据加入噪声,此时自编码器就会学习怎么去除噪声而重构出原来没有噪声的数据,从而使得编码器能学习到更加鲁棒的表达,同时也增加了泛化能力。降噪自编码器的工作原理如图5所示。

图5 降噪自编码器工作原理
本节使用DAE的工作原理来训练得到蒙汉语言模型。定义DAE的目标函数为:
(7)

Llm=Ez~T[-logPt→t(z|C(z))]+
Em~S[-logPs→s(m|C(m))]
(8)
综上所述,使用降噪自编码器可训练一个不错的语言模型,本文首先输入无噪声的嵌入表示记录位置信息,再添加噪声通过DAE学习噪声特征和有用信息特征,最后得到表达流畅的语言模型。以中文训练语言模型的过程为例,具体训练过程示例如图6所示。
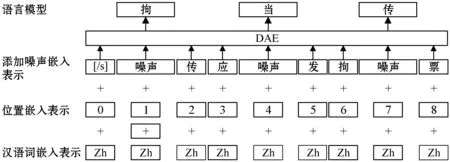
图6 降噪自编码器训练过程示例
2.2 初始化蒙汉机器翻译模型
实现两种语言之间的互译,最简单的方法就是当这两种语言间存在一个字典时,对照字典,把每一个源语言的字翻译出来,即使基于这种方法翻译得到的结果会很差,但是至少保证了翻译的实现。通过对抗网络学习到一个蒙汉对照的字典,通过搭建一个端到端的神经网络模型,得到了一个最原始的蒙汉翻译模型,但它翻译出来的句子不是很流畅,因为只是单词互译的堆叠。本文通过DAE学习到了蒙汉语言模型,可以缓解翻译出的句子不流畅的问题。所以将语言模型加入最初的蒙汉翻译模型,完成了初始化蒙汉机器翻译系统。
2.3 迭代回译
回译,也称为反向翻译,这是缓解平行数据缺乏的最有效的方法之一,其本质上是为了构造伪平行数据,将无监督学习的方法转化为有监督学习的方法。本文假设目标语言句子z是目标语言单语语料库Z中的任意句子,即z∈Z,用u*(z)来表示从目标语言中推断出的源语言句子,则u*(z)=arg maxPt→s(u|z)。同样,可以用v*(m)表示从m∈S中推断出目标语言句子,则v*(m)=arg maxPt→s(v|m)。如此一来,(u*(z),z)和(m,v*(m))就可以构成伪平行句子,那么遵循反向翻译原则,可定义回译算法的损失函数为:
Lback=Ez~T[-logPs→t(z|u*(z))]+
Em~S[-logPt→s(m|v*(m))]
(9)
迭代的目标是使得式(8)和式(9)之和最小。使用随机梯度下降算法进行多次迭代,以此来更新每个模型的参数使得初始化的翻译模型的性能逐渐增强。
3 实 验
本文主要以“基于深度学习的蒙汉统计机器翻译的研究与实现”中构建的123万句的蒙汉对齐语料库中的蒙古语作为源语言端单语数据,以全球AI挑战赛(AI Changer)中给出的1 000万句英汉对齐语料库中的汉语作为目标语言端单语数据为实验数据,验证基于单语语料库训练的蒙汉机器翻译方法的可行性。训练集为123万句对蒙汉单语数据,验证集为3千句对,测试集为1千句对。
首先融合不同粒度的方法对语料库进行预处理,使用词级粒度的方法对中文语料进行切分,再使用BPE[20]进行子词级切分,BPE操作数设为60 000,初始化共享查找表。模型使用基于LSTM和Transformer的基本架构,编码器和解码器都设置为4层,共享其中3层的参数。给语料添加噪声时,随机丢弃单词的概率为2%,每6个词之间调换顺序,学习率设为0.000 1,epoch_size设置为500 000,batch_size设置为32,使用Adam优化算法进行优化。
3.1 实验结果
实验经过20个epoch实验自动停止,统计到翻译模型在测试集上的BLEU值如表1所示,相应的BLEU值的变化趋势如图7所示。

表1 翻译模型BLEU值
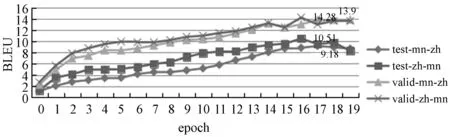
图7 BLEU值的变化趋势3.2对比实验
表1中:Mn-zh表示蒙汉翻译模型的结果;Zh-mn表示汉蒙翻译模型的结果;Test表示在测试集上的结果;Valid表示在验证集上的结果。
从图7可以看出,基于单语语料库训练的蒙汉机器翻译模型的BLEU值在20个epoch上呈现增长趋势,在测试集上蒙汉翻译性能在epoch17时表现最好,此时BLEU值为9.18,在验证集上蒙汉翻译性能在epoch17时表现最好,此时BLEU值为14.28。
3.2 对比实验
对比实验直接使用了哈佛大学开源的神经机器翻译系统OpenNMT。这是一个使用平行语料库在基于LSTM神经网络和注意力机制上实现机器翻译的系统,主要包括四个步骤:语料预处理,翻译模型训练,使用训练好的翻译模型翻译测试集以及对翻译结果的BLEU值评测。
对比实验同样使用了10万句对的蒙汉平行数据作为训练集,3千句对作为验证集,3千句对作为测试集。实验环境为Ubuntu16.04 Linux系统,利用pytorch 0.4.3进行神经网络的搭建,在OpenNMT中参数做如下设定:蒙古语词典大小为50 002,汉语词典大小为50 004。编码器和解码器中LSTM神经网络的网络层数设置为4层,词向量维度设置为500,解码器中全局注意力机制中输入特征设置为500,输出特征设置为500,归一化函数选择Tanh()。Dropout设置为0.3,迭代轮数epoch设置为20轮,学习率设置0.1,学习率衰减速率设置为1。
为了和本文的主体实验做对比,统计出了基于LSTM神经网络的蒙汉机器翻译模型的20个epoch上的BLEU值以及其变化趋势,如表2和图8所示。

表2 基于LSTM神经网络的蒙汉机器翻译模型的BLEU值

图8 LSTM机器翻译模型BLEU值变化趋势
3.3 对比分析
实验将基于单语语料库训练的蒙汉机器翻译模型和基于LSTM神经网络的蒙汉机器翻译模型进行了对比。采用BLEU值作为翻译模型的评测指标,通过一轮轮迭代训练,模型学习到的参数越来越好,包含越来越丰富的语义信息,从而提高了翻译模型的表达能力,最终导致测试集上译文评测值的不断提升。对比实验的结果如表3和图9所示。

表3 对比两种蒙汉机器翻译模型的BLEU值

图9 两种翻译模型在测试集上的BLEU值对比
表3中,单语表示基于单语数据的蒙汉机器翻译模型在测试集上的BLEU值;双语表示使用平行数据基于LSTM神经网络的蒙汉机器翻译模型在测试集上的BLEU值。
实验表明,使用123万句对单语数据训练20轮的蒙汉机器翻译系统的性能和使用10万句对蒙汉平行数据在开源系统OpenNMT上训练8轮的结果相当。
由于单语语料库比双语语料库容易得到,所以基于单语语料库训练的方法在提升蒙汉机器翻译系统性能方面有一定的优势。但因为基于单语数据训练的方法依赖于一个好的语言模型,所以应用单语数据训练的方法不适用单语数据较少的情况,需要大量的单语数据才能保证语言模型性能良好。
4 结 语
本文对如何构建基于单语语料库训练的蒙汉机器翻译系统做了介绍,提出基于单语语料库训练实现蒙汉机器翻译的三大步骤:语言模型,初始化翻译系统和迭代回译进行优化。对预训练跨语言词嵌入表示的方法、使用去噪自编码器训练语言模型以及回译算法做了详细的描述。最后,采用机器翻译常用的评测标准BLEU值,对基于单语语料库训练的蒙汉机器翻译模型与基于平行语料库在LSTM神经网络上训练的蒙汉机器翻译模型进行了对比实验。实验表明,基于单语语料库训练的蒙汉机器翻译模型的BLEU值增长缓慢,而使用平行语料库基于LSTM神经网络的蒙汉机器翻译模型的BLEU值增长较快。从模型的测试效果来看,两种方法使用的语料数量相差10倍之多。前者的整体翻译效果依赖于两个方向上翻译模型的性能和两种语言的回译能力,但是汉语的回译效果和蒙古语的回译效果相差较大,这应该是蒙汉两种语言之间差异较大而同一种语言模型训练方法不能完全匹配导致的。所以缓解此问题的方法之一就是预训练一个跨蒙汉的语言模型,使得一个语言模型可以匹配蒙汉两种语言。下一步拟研究如何预训练一个跨蒙汉的语言模型。
