一种基于优化存储格式的DLB_GaBP算法
2020-06-16陈振武兰添才郑汉垣
陈振武,黄 婧,兰添才,郑汉垣
(1.龙岩学院 数学与信息工程学院,福建 龙岩 364012;2.龙岩学院 大数据挖掘与应用福建省重点实验室,福建 龙岩 364012;3.龙岩学院 传播与设计学院,福建 龙岩 364012)
1 概 述
现代多核处理机或多处理机系统速度能力已实现了每秒千万亿次浮点运算的量级,因此,要提高大规模的数值计算的速度与效率,最终均归结于操作系统的任务流调度算法、存储空间存储格式的合理定义与分隔。
对于多核处理机环境中的任务流调度算法可分为全局队列调度算法和局部队列调度算法两种。局部队列调度算法是为每个处理机核心维护一个局部任务等待队列,处理机的利用率较低,在大规模并行计算中一般不予使用;全局队列调度算法从处理机的任务均衡性、存储格式的合理性方面综合考虑充分发挥系统中各处理机核的综合性能,当某一处理机空闲时,系统立即从全局任务等待队列中选取就绪任务分配给该处理机执行,从而提高处理机的利用率,达到提高系统的运算速度与效率的目的。
吉林大学的耿晓中提出了一种动态负载均衡模型,并将影响多核处理器负载均衡的因素分为5类:多核系统的负载均衡环境、用户提交的任务属性、系统的负载评价、系统所采用的调度策略以及系统的调度评价指标[1],为多核动态调度因素提供依据。
文献[2]针对动态调度算法的基本原理和执行过程,结合负载均衡策略,提出了一种基于异构多核处理器的STDS动态任务调度算法,并通过选择调度时间、负载均衡和任务等待时间三个方面证明了STDS算法在保证速度性能的同时有较理想的内核负载均衡效果。
贾燕成等提出了负载动态均衡规则[3]是在任务的调度过程中根据处理器的状态,将较大的任务分解并动态映射到其他节点上,并与该节点的原始任务组进行组合形成后继任务循环执行,使各个节点的任务达到动态平衡,可以避免节点的空闲等待,也缩短了各个节点通信开销,最大化提高了并行效率。
近年来,随着互联网+、物联网、大数据云计算应用领域的不断开展,计算机系统的数据运算量也在不断增加。如电力系统运行控制的潮流计算问题[4]、环境监控、实时评价问题、地震实时监测等领域,均涉及到大规模数值计算问题。而对这些大规模数值问题的求解,大多都是通过相应的数学建模,然后将问题的求解转换成为相应建立起来的稀疏线性方程组Ax=b的求解[5-7]。
迭代法是在稀疏线性方程组求解中常用的方法,尤其是近年来,基于Krylov子空间方法[8-9]的迭代法得到了广泛应用,Ori-Shental等人基于递归更新的概率推理算法提出了GaBP迭代算法[10]。
文献[11-13]针对GaBP迭代算法具有计算复杂度低、并行度高的特性,在GaBP的迭代加速优化方法的基础上给出了对应的多种GaBP迭代加速优化算法,并从动态松驰因子的GaBP算法和MannGaBP迭代加速优化算法的实验,构造多核处理机动态因子。
文中针对多核处理机环境中的大规模稀疏矩阵线性方程组的存储格式、处理机间的任务均衡性、并行算法的优化等进行研究,在优化稀疏矩阵存储格式的基础上,依据文献[3]提出的负载动态均衡规则,对多核处理机环境的并行GaBP算法进行优化,设计实现具有动态负载均衡特性的多核并行GaBP算法(DLB_GaBP算法)。经过实验验证,该算法在对大规模稀疏矩阵线性方程的求解过程中,具有更高的加速效果、更快的计算速度、更好的环境适应能力。
2 高斯置信传播(GaBP)算法
2.1 算法思想
GaBP算法主要包括:初始化和迭代(包括消息累加、消息传播与更新、求解向量三个过程[13])两个步骤。具体可描述如下:
步骤一:初始化。

(2)初始化。
步骤二:迭代计算。
(1)消息累加。
//N(i)为第i行节点编号的集合(不含i);
(2)消息传播与更新。
(3)求解向量。
2.2 GaBP算法的改进

3 存储格式定义
文献[16]在充分分析了ELL、CSR、COO、ELL+COO混合的HYB(Hybrid)等多种存储格式的优缺点的基础上,提出了ELL+CSR混合的HEC存储格式,并进行了相应的实验对比验证,也发现了HEC存储格式比CSR格式多存储了2组分别用以存储格式本身所需设定的值和列数据,对读取带来一定的开销。
为了充分利用GaBP算法的特殊性,文中定义动态负载均衡多核并行GaBP的数据结构,在数据存储格式及数据读取方法上采用列压缩存储格式,格式本身分为两种形式:改进的列压缩存储格式(modified compressed spare column,MCSC)或优化的列压缩存储格式(optimized compressed spare column,OCSC)。
3.1 矩阵数据参数设定
设:n阶稀疏矩阵矩阵Α,有非零元素nz个;
另设:存储单元数组ADN、ALN、AUN、NL、NJL、NU、NJU。
其中,ADN用于存放按顺序排列的n个对角矩阵元素值ai;
ALN用于按列存储Α左下三角(nz-n)/2个非零元素值aij(i>j),NL用于存储行号,NJL用于存储非零元素对应列起始行号(NJL=1~n);
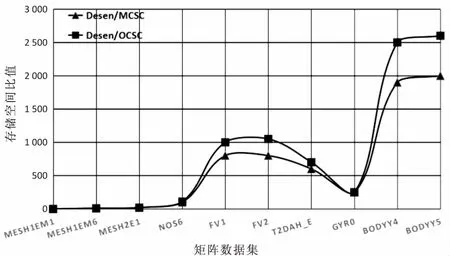
AUN用于按列存储Α右上三角(nnz-n)/2个非零元素值aij(i 由于文中利用UFgett中的稀疏矩阵进行实验验证[17],Α按行号、列号、元素值三个元素组进行存储,可建立如下变换存储格式的左端矩阵数据结构: 条件一:若Α不对称 则:按ADN,ALN,NL,NJL,AUN,NU,NJU的顺序的MCSC格式存储。 条件二:若Α对称 则:按AD,AL,NBL,NBJL顺序的OCSC格式存储。 条件三:若Α是对角稠密矩阵,则非零元素的存取与查找,采用OCSC格式存储结合顺序查找算法可以非常直接地进行。 条件四:若Α是非对角稠密矩阵,非零元素,一般可采用二分查找方法进行。依据GaBP算法稀疏性的特性,形状对称矩阵P、μ、Α(其中Α是左端数值对称矩阵),利用OCSC存储它们,可以将NL、NJL与ALN、ADN的存储格式进行一样的定义。但由于矩阵μij是形状对称的,这需将其上三角元素形成矩阵存储,可以借助MCSC格式进行存储,因此,矩阵μij可对应为:μAD,μAL,μNL,μNJL,μAU,μNU,μNJU。 图1给出了稠密矩阵存储格式与MCSC、OCSC存储格式在存储空间的占比情况。 图1 存储空间比值 从图1可以明显看出,MCSC和OCSC与稠密存储空间的比值随着矩阵阶数、矩阵的稀疏性和非零元素数量规模的增大而增大,说明MCSC和OCSC格式所需的存储空间远少于稠密存储空间,且OCSC格式所需的存储空间比ACSC格式的存储空间更少。 对稀疏线性方程组求解的并行算法首先需对矩阵进行数据划分,划分的方式可以有列划分、行划分。文中采用按列数相同的列块顺序进行存储格式划分,确保各线程进行计算时的列块中的列数相等。 由于Α的每一列中所包含非零元个数不一定相同,对应分配到各线程中的列块中包含的非零元数往往也不一定相同,很明显,各线程对列的计算量与该列中的包含非零元素的个数成正比,这很容易引发线程负载的不均衡,线程负载不均衡势必进一步引发部分处理机的资源空闲浪费。因此,列划分应尽量使分配给各个线程计算列块中所包含的非零元素的个数差异性不大,以确保形成均衡的负载。 系统线程调度、运行过程是动态的,为确保建立动态的负载均衡,而现代操作系统针对线程的调度都是建立在具体算法的基础上,下面是列矩阵块的动态划分算法步骤。 1:partition(seg[],NZ[],n,p) //定义参数,seg[]是存放矩阵列块划分方式的数组,NZ[]是存放非零元素的数组,p为线程数; 2:k=0,q=0,l=0;seg[0]=0 //初始化; 3:for allj∈0,1,…,ndo 4:l=l+NZ[j] //NZ[j]为第j列非零元素个数; 5:end for 6:for allj∈0,1,…,ndo //迭代划分列块; 7:k=k+NZ[j] 8:ifk>[q+1]*l/pthen 9:seg[q+1]=j;q=q+1 10:end if 11:seg[p]=n+1 12:end for 由于p为线程数,其结果是对应于q=0,1,…,p-1时,将稀疏矩阵的第segq到segq+1-1列分配到线程号q中,这就产生两种运行状态需要进行处理。 节点状态处理:每一轮迭代结束均判定节点状态,如果处于消息动态均衡,则不作计算处理,以减少列块中待计算节点的数量。 动态均衡处理:为防止因减少计算节点引起新的负载不均衡,新一轮的迭代需重新对列块进行划分,并重新分配给相应线程,让每一线程重新达到相同的计算量。以此类推,达到动态负载均衡。 DLB_GaBP算法的实现实质上就是将GaBP算法中的消息累加、消息传播与更新、求解向量分别加入到OpenMP的并行制导控制段中,构成三段多核并行控制段,即基于OpenMP的多核并行GaBP算法。该算法可表述如下: Initialization: //初始化 1:init(): Iteration 2:repeat 5:if(iters mod D_LOOP==0)then//列块划分迭代步数条件判断 6:partition(seg,NZ,n,Nthreads) 7:end if 8:#pragma omp parallel private(tid,p,j)threads(NTHREADS) 9:{tid=omp_get_thread_num() 10: for(i=seg[tid];j &&Ti==0;i++)do 11:if(Ti==0)then 13:for allj∈N(i)jdo 15:end for 16:end if 17:end for 18:} 19:#pragma omp parallel private(tid,p,j)threads(NTHREADS) 20:{tid=omp_get_thread_num() 21: for(i=seg[tid];j 23:xi=μi/Pi//xi为收敛精度 24:if(Ti==0)and(xiconverged)then //xi满足设定的收敛精度,该节点的Ti值设定为1 25:Ti=1;NZj=0 26:end if 27:end for 28:} 29:until convergence:allxiconverged 30:output:x*=[xi] 为能够尽量好地提高计算效率,文中通过迭代步来控制上述的有效组合,具体是通过将迭代的次数限制一定数量范围内,超过即重新进行列块划分。即在Partition()函数前面添加了迭代步控制,每隔D_LOOP迭代步重新进行列矩阵块的划分。D_LOOP的取值一般是依据划分列块中的列数,当然也可以是定量或变量,这只要在算法中进行相应的定义即可。 当收敛精度xi满足设定的精度要求时,返回该节点Ti=1,NZ[j]=0,下一轮迭代计算时跳过该节点,同时,负载均衡处理中也不统计该节点的邻居节点数,这可以大大减少节点的计算负载量,但是需要进行列块的重新划分以实现新的负载均衡。 新一轮迭代计算前进行新的列块均衡划分,总体上减少了计算量,也保持了各线程的计算量相对均衡,进而解决了因线程同步造成的大量线程的长时间等待问题,同时加速了迭代计算。 实验在高性能集群系统中进行,系统环境配置如下: CPU:Intel Xeon E5-2650;内存:96 GB; 众核加速卡:Intel MIC卡(61核,8 G共享存储); 操作系统:Redhat Linux 6.3 X64; 编译器:支持Intel MIC应用开发的Intel编译器。 测试数据采用稀疏矩阵集(UFget)[17],文中所提算法是基于对角占优线性方程组的求解,选取的用于测试算法的稀疏矩阵集见表1。 表1 用于测试算法的稀疏矩阵集列表 图2给出了DLB_GaBP算法与并行GaBP算法在相同的计算环境中的计算时间对比,可以看出DLB_GaBP算法具有更好的计算效率。 图2 DLB_GaBP与GaBP算法计算时间对比 图3给出了DLB_GaBP算法在相同运算规模而不同的运算线程或核心数环境中的加速比对比,从图中可看出随着算例计算规模的加大加速比也明显增大,表明算法具有良好的线程数或核数变化的加速效果。 图3 DLB_GaBP在不同线程数或核数中的加速比 图4是DLB_GaBP与GaBP算法前后加速比对比图,算例矩阵名称是按其非零元素规模大小排列。 从图中可清楚看出,两种算法的加速比随着非零元数量的增大而提高,尤其是非零元素规模不大的环境中,DLB_GaBP的加速优势并未呈现出来,随着非零元素个数的增加,即计算问题数据规模的增大,DLB_GaBP算法明显比GaBP算法有更好的加速比。 结合用于测试算法的稀疏矩阵集列表1,观察图4的DLB_GaBP算法的加速比对比曲线,稀疏矩阵的行数小于104,非零元小于105的小规模计算问题,算法并没有加速效果,这是由于多核并行算法在启动多核并行占用的时间远比小规模算例实际求解计算的时间长。这说明问题求解的规模越大,算法的优越性越明显。 图4 DLB_GaBP与GaBP算法加速比对比 通过建立列数相同的列块顺序进行存储格式定义划分,以确保各线程进行计算时的列块中的列数相等的基础上,实现在有限的内存空间对大规模稀疏线性方程组的左端矩阵存储,可降低算法的空间复杂度。同时通过挖掘基于GaBP的迭代加速优化方法本身的特性,建立具有负载均衡特性的DLB_GaBP算法,具有适应性更好、迭代收敛速度更快的优势,更适用于大规模数值问题的计算,具有一定的推广应用价值。3.2 存储格式定义
3.3 存储格式的比较
4 基于列压缩存储格式的动态负载均衡
4.1 负载均衡存储格式划分
4.2 动态列矩阵块的划分算法
4.3 DLB_GaBP算法

5 数值试验
5.1 实验环境
5.2 测试结果及分析




6 结束语
