面向图书主题分类的随机森林算法的应用研究
2020-06-16孙彦雄李业丽边玉宁
孙彦雄,李业丽,边玉宁
(北京印刷学院,北京 102600)
0 引 言
随着科技的快速发展,自从20世纪90年代以来,产生的数据信息越来越多,其中80%的信息是以文本存储的[1]。因此,人们对巨量的文本信息,不能采用之前传统的人工筛选。基于自然语言处理的文本处理应运而生,近年来对文本分类的研究也越来越多,主要集中在朴素贝叶斯、K-means聚类、SVM等算法。随机森林算法(random forest,RF)由于其具有训练速度快、对于大数据时代易于进行并行计算、具有很强的抗干扰能力且抗过拟合能力优秀的优点,被应用在各行各业中,并取得了优于传统方法的效果。
对于文本分类的研究,已有大量的研究成果。比如,周庆平提出了一种基于聚类的改进KNN算法[2];Yang对特征选择函数进行了改进,将几种特征选择函数的准确系数连接起来构成一种新的特征选择函数,最后再使用SVM进行分类[3];张翔提出了使用Bagging的中文文本分类器的改进算法[4]。基于文本信息的增加和文本处理技术的发展,对于文本分类的应用也越来越多。例如舆情监测、情感分析、商品分类、新闻分类等等。
由于随机森林算法的诸多优势,使得专家学者对RF进行了许多改进应用研究。1995年Tinkam-ho首次提出随机森林的概念[5]。之后Leo Boeiman提出RF是一种分类和预测模型[6]。M P Perrone等人提出在分类阶段,RF类标签是由所有决策树的分类结果综合而成,并在投票[7]跟概率平均[8]两个方面是使用最多的方法。在应用方面,在生物信息学中,EI-Atta提出了一种使用RF预测大麻素受体(CB2)激动剂活性的方法[9];生态学中,Eruan等人使用RF对空气预测进行了研究;在遗传学中,Retralia在基因识别上使用了RF。并且,RF在生物芯片、信息抽取等领域,均取得了不错的效果。
1 算法介绍
随机森林算法是由许多决策树构成,通过每个决策树的决策结果进行投票,获得票数最多的类别就是随机森林算法的结果。由于随机森林算法的可并行计算[10],容易泛化应用,不易过拟合等优点,其在生物[11]、医学[12]、信息检索等多个领域得到了广泛的应用。文中主要内容是讲解RF的基本构建流程,决策树的基础知识,为后续对RF的优化做好铺垫工作。
1.1 随机森林算法
要了解随机森林算法,首先就要明白决策树的由来。因为C4.5是决策树的经典算法结构,因此首先分析解释C4.5。虽然决策树有很多变种,但是其核心主函数类似,不同点在于最优特征标准的选择上。
首先了解信息熵,信息熵是香农在1948年提出的概念,用来解决信息的量化度量问题,如式(1)所示。
(1)
其中,i为每个消息,r为消息的个数。
为了便于后面的计算,文中提出将累加符号前面的负号删掉,定义为纯度。相应的信息熵越低,对应数据集的纯度越高。
(2)
式(2)就是文中定义的纯度计算公式,D表示某个数据集,k表示由于某种属性导致的分类,总共分为y类。假设由于属性t导致数据集U分为若干类,由此计算属性t的信息增益,如下式:
(3)
由此,可以使用式(3)作为最优特征标准,得到的是ID3算法,但是由于ID3算法不能处理连续型的变量属性,并且在属性偏好上偏向于属性分类多的属性,影响决策。故而,1993年Quinlan提出了C4.5算法,使用信息增益率作为最优特征标准,从而解决了ID3的属性偏好等问题。信息增益率计算公式如下:
(4)
(5)
C4.5算法的算法步骤如下:
(1)对数据集进行预处理,将连续变量离散化或对缺失的数据进行补充,进行预处理验证结束之后,进行下一步;
(2)判断本训练集中是否已经生成叶子节点,如果已经全部生成,结束算法,进行下一步;
(3)使用式(4)计算叶子节点的信息增益率,进行下一步;
(4)比较得出使信息增益率最大的属性,作为分裂节点,再使用所选属性分割训练集为一个个的子训练集,转为第二步。
由此,可以得到一棵棵的决策树,随机森林算法利用多棵单决策分类器组合而成多分类器的思想,克服了单分类器决策树的种种缺点。通过每棵决策树的结果进行投票,得到最终的分类结果。这就是RF的主要思路,构建过程是,首先利用bootstrap对训练集进行抽样生成多个新的训练集;其次利用生成的训练集产生一棵棵决策树;最后通过每棵决策树的投票得出最终的分类结果。
RF的主要关键点在于两次随机抽样,一次是使用bootstrap有放回抽样,会使得新的数据集中包含2/3旧数据集的内容,从而产生袋外数据,为文中的改进优化提供了数据源。另一次是随机抽样,产生在对特征的选择上,每次生成决策树时,使用的特征并不是完全相同的。从给出的特征中随机抽取少于总特征数的特征进行决策树的生成。将前面生成的决策树,一棵棵的连起来就成为了随机森林。
1.2 RF算法步骤
随机森林算法在文本分类中的算法步骤如下:
(1)文本预处理。首先去除文本中的停用词、符号等“噪声”。然后使用word2vec词嵌入模型,对文本信息进行向量化,生成训练集。
(2)假设训练集中包含有N个样本,T种分类属性。采用bootstrap抽样方法,抽取出样本N个,得到新的样本集。
(3)在给出的T种分类属性中,随机抽取t(t≤T)种属性。使用某种决策树最优特征标准,选择最优分类节点,使得在子样本集中均为叶子节点。
(4)重复进行K次第三步,生成决策树K棵,得到最终的随机森林。
(5)H(x)是分类器的函数模型,决策树用hi表示,Y表示目标变量(分类标签),I(*)表示函数。随机森林的决策公式如式(6)。
(6)
传统随机森林流程如图1所示。


图1 随机森林算法流程
1.3 RF优缺点分析
随机森林算法采用的是bootstrap抽样,对数据集进行有放回抽样生成子数据集。正是如此,会产生大约1/3的袋外数据,这些袋外数据对分析随机森林算法的性能具有很高的研究价值。Breiman指出,袋外数据可以替换数据集的交叉验证法,并且袋外数据的估计就是RF泛化误差的无偏估计。文中正是利用袋外数据,对RF的决策树在相似程度高的情况下会掩盖真实分类的缺点进行了改进。
随机森林算法是一种集成学习算法,将多个弱分类器组合使用,得到一个分类性能更强的强分类器。RF正是因为分开生成决策树,所以便于并行化处理数据[13-14]。在大数据时代,可以并行化处理数据的优势,使得该算法极具诱惑力。
2 改进的RF算法
首先传统的随机森林算法没有考虑文本数据的特殊性,进而在处理文本数据时,往往由于特征提取质量差,不能提高文本分类的水平[15-16]。其次,随机森林算法本身存在着相似决策树会掩盖真实分类决策的问题。文中针对以上两个方面进行改进。
2.1 提高文本特征质量的Tr-K方法
传统的随机森林算法在进行分类决策时,特征选择个数、质量的问题并不突出。但是对于图书等大容量的文本进行分类的问题来说,文本特征(分类决策树属性)数量越多、质量越高,得到的分类效果就会越好。为此,文中提出一种TF-IDF、TextRank、K-means三种方式结合的Tr-K方法,以提高文本分类效果。
TF-IDF方法的全称是term frequency-inverse document frequency,是用来进行信息检索和数据挖掘的常用技术。TF值是指在文件j中,第i个词的重要程度。
(7)
其中,分子表示第i个词在文件j中的出现频数,分母表示文件j中包含有k个单词出现的总频数。
(8)
其中,|D|表示语料库中的文件总数,ti表示要检验的第i个词,dj表示文件j包含的词汇集合,|{j:ti∈dj}|表示包含ti的所有文件频数。之所以在分母需要加1操作,是为了避免出现无意义的除零情况的发生。
TFIDFij=TFij×IDFij
(9)
通过式(8)、式(9),对某一文件内的高词语频率和在文件集中的低文件频率,产生权重高的TF-IDF。从结论可以看出,该算法倾向于过滤掉常见的词语,保留重要的词语。缺点是,文本的开头跟结尾对于语义具有不同的重要性,不能体现词语的位置信息。
TextRank算法来源于Google的PageRank算法,PageRank算法是用来评判一个网页的重要程度,采用有向无权图进行打分[17-18]。设定Vj表示网页j的节点,In(Vj)表示指向网页j的节点集合,Out(Vj)表示网页j指向其他网页节点的集合。|In(Vj)|表示集合的节点数量。对网页重要性的打分如式(10)。
(10)
d表示阻尼系数,当极端情况下没有人访问的网页,会使公式无意义,因此加入阻尼系数,避免此情况的发生。
TextRank是针对文本关键词的提取方法,相对于网页,最大的不同在于生成的是有向有权图。使用一个可变窗口对文章句子进行扫描,去掉停用词之后,认定窗口内的每个词之间都是互相联系的,并计算相邻词语之间的余弦相似性,计算每个词汇之间的权重。由此,计算公式如下:

WS(Vj)
(11)
其中,WS(Vi)表示节点Vi的得分,Wji是指用余弦相似度计算的节点Vj对Vi的权重。此种关键词的提取方法的优点在于计算复杂度小,容易处理。
K-mean算法是无监督分类算法,因为其计算简单聚类效果优,故而应用广泛。但是使用K-means算法,关键在于找到合适的k值,即初始化质心。选择的恰到好处,会明显提高算法的效率和准确度。为此,文中采用TF-IDF与TextRank提取出的特征集作为K-means算法的k值输入,再进行聚类分析。综上所述,提出的Tr-K文本特征抽取模块的流程如图2所示。

图2 特征提取Tr-K方法的结构
2.2 加权投票提高决策树质量的机制
文中使用Tr-K得到子特征集,采用C4.5算法得到决策树节点集合。基于投票与余弦相似性原理提出优化随机森林机制,改进内容主要包括如下两点:一方面,对训练集通过word2vec训练为词向量,再将得到的决策树节点集合转换为词向量,通过使用余弦相似性公式,判定出各个决策树的相似性;另一方面,由于随机森林算法在对训练文本集进行bootstrap抽样时,会遗留1/3的袋外数据,故而使用袋外数据对决策树节点集合生成的决策树进行准确率测试。
相似度的计算公式如式(12):
(12)
其中,A与B分别表示两个节点集合词向量组合,n表示词向量的维数。通过计算各个节点集合的相似性,选择最优参数d进行比较,抽取出相似性较小的节点集合作为备选决策树集合。
当使用训练集bootstrap抽取子文本集合时,随之生成袋外数据,因此使用这部分袋外数据,对决策树进行准确率测试,从而找出最优的决策树作为备选。公式如下:
(13)
其中,N是总体样本数(袋外样本数),Ncor是正确分类数,Weight(i)表示决策树i的正确率,e是用于判定决策树优劣的阈值。
实现流程如图3所示。
3 实验仿真及分析
3.1 实验环境
算法性能分析的实验环境以Windows 7操作系统作为整个实验的支撑,使用Python语言作为程序设计的编译语言。相关配置:Intel(R)Core(TM)i5-3470 CPU处理器,处理器为3.20 GHz,内存为8 G,开发工具为PyCharm Community Edition 2017.5.1。
3.2 实验数据集
文中共使用了两种数据集,为验证文中算法在不同文本中的分类能力,特选取中英文两种不同的数据集。20 Newsgroups数据集共有18 000篇文章,涉及到20种主题,分为训练集和测试集,两者无交叉。通常是用来进行文本分类、信息检索和文本挖掘相关研究的国际通用标准数据集。20 Newsgroups数据集文档分布如图4所示。

图3 加权投票模块
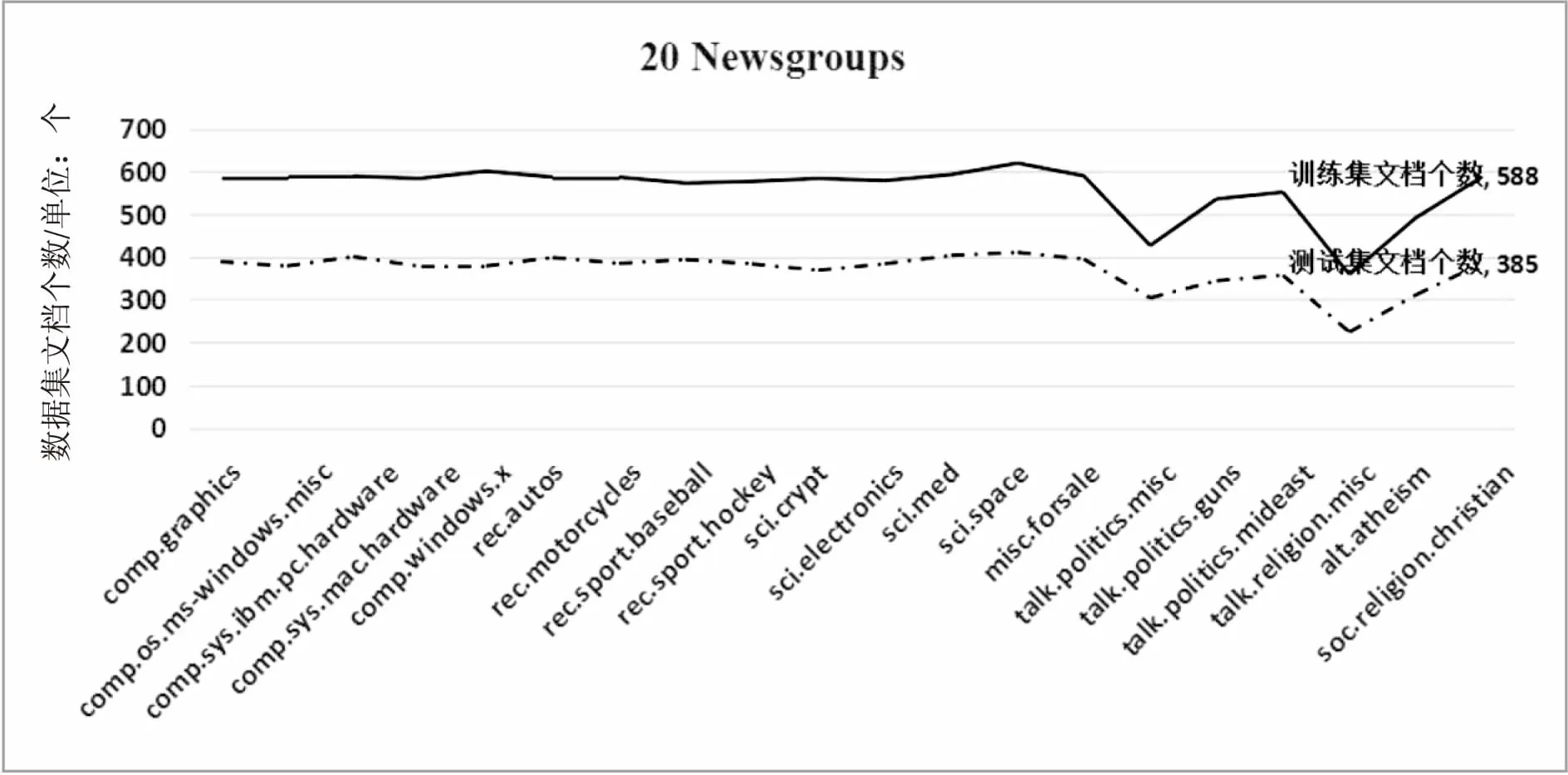
图4 20 Newsgroups数据集分布
中文数据集来自搜狗实验室提供的中文分类语料库,随机选取部分语料作为训练集跟测试集。中文数据集包含体育、财经、娱乐等八类新闻文档,共计四万篇。各个类别的数量分布较均匀,大约每类5 000篇文档。图4横坐标表示20个主题的分类名称,纵坐标表示每类主题所包含的文档个数。
3.3 实验设计与分析
利用传统随机森林算法、仅采用TF-IDF进行文本特征提取的TF-RF算法,与文中设计的TRk-SW-RF模型进行对比实验分析。实验对比主要分为以下几个方面:运行时间、分类准确率和F1值。并且为保证实验数据的稳定性,在决策树数量分别是50、70、100、200、300、400时进行对比实验,并且在实验环境不变的前提下运行10次,取平均值作为最终的实验结果。
如表1所示,当控制决策树的个数时,记录20 Newsgroups数据集在不同模型上的训练时长,可以看到,虽然TRk-SW-RF模型的训练时长跟传统随机森林的训练时长相差不大,虽然增加了特征选择跟投票的时间,但是由于缩小了文本长度从而使得总的训练时长增长并不明显。并且当决策树的数量增长到一定量时,训练时长的增长速度明显小于决策树的增长速度。

表1 20 Newsgroups数据集下各模型运行时长
同时计算了20 Newsgroups数据集在三种有效模型下的准确率,如图5所示。从图上可以清楚地看到,使用TRk-SW-RF模型的准确率明显高于传统随机森林算法和IDF-RF算法。

图5 不同模型下的文本分类准确率
同时,为丰富文中模型在不同数据集上的泛化性,对搜狗实验室提供的中文文本分类语料库,使用F1值的评价标准对三种模型进行评测。结果如图6所示,可以看出在中文语料库中文中模型的分类能力仍然高于其他两种算法。

图6 不同RF模型在中文数据库下的F1值
4 结束语
通过对随机森林算法的输入文本数据集进行处理,从而提高分类效果。并使用剩余的袋外数据,对得到的决策树做进一步的检测提取,从而提高了决策树的质量,进而提高了最终生成的随机森林的分类准确率。通过中外两种不同的数据集,验证了该模型在没有明显提高训练时间的前提下,有效地提高了分类准确率和F1值。
下一步的研究可以在计算文本相似度方面引入目前很热门的深度学习算法,虽然会延长训练时间,但是从传统机器学习的分类效果上看,如果能够有较大的提高,还是很有必要的。
