模型裁剪在车型识别中的应用
2020-06-12王乃洲金连文梁添才金晓峰
王乃洲 金连文 梁添才 金晓峰
(1.华南理工大学 广东省广州市 510640)
(2.广电智能安全研究院 广东省广州市 510656)
视频结构化分析是海量视频实现信息化、情报化行之有效的技术,也是当前智能公共安全中对视频处理的一个指向性方案。随着平安城市、雪亮工程等全国性工程建设的不断推进,我国已经是监控摄像头增长最快的国家。为实现防区全方位实时安全态势智能感知,智能监控摄像设备,往往具有视频(人,车)结构化分析功能。
视频结构化技术融合了机器视觉、图像处理、模式识别、机器学习等最前沿的人工智能技术,随着深度学习技术的发展,基于CNN的应用方案已经成为主流。CNN的计算需要耗费大量的计算资源与存储资源,从而限制了其在边缘设备上的应用。轻量级网络模型的设计与应用成为解决以上问题的重要技术手段,由此衍生出SqueezeNet[1],Shufflenet[2],Mobilenet[3]等模型。实际应用中,轻量级网络模型推动了智能分析模型的前端部署。然而,轻量级网络依然存在参数冗余,在推理速度和资源占用上依然有较大的优化空间。
针对以上问题,本文主要探讨轻量级网络模型压缩与加速技术。目前,深度网络模型压缩与加速的主要手段包括:模型裁剪[4,5,6];模型量化[7];知识蒸馏[8];低秩分解[9];网络结构搜索[10]等,其中,模型裁剪与量化,由于其有效性和高效性,受到学术界与工业界的青睐。
本文基于Thinet裁剪技术[5]提出一种基于轻量级网络Mobilenetv2的车型识别模型优化方法。基于所提出的通道裁剪策略,在几乎不改变原始识别精度的前提下,提高车型识别系统的识别速度。最后,通过实验,证明所提技术的有效性。
1 基于Thinet的通道裁剪策略
基于Channel prune的模型压缩技术,关键在于裁剪通道重要性评估。较早的通道重要性评估方法有L1/L2范数[4]。这种方法的缺点在于,忽略了通道之间的耦合性,没有考虑到裁剪对下一层输出的影响。在2017年ICCV上,文献[5]提出了一种数据驱动型Thinet通道裁剪技术,其核心思想是:如果可以用第i层输出的一个子集就可以在第i+1层上产生和原始输出近似的结果,则该子集之外的其他通道均可以裁减掉。
为考察channel的重要性,需准备N张样本图片。设置压缩率ε,则需保留的第i层通道数为M=ε*C,其中C为第i层输出通道个数,以N张样本图像为系统输入,考察裁剪掉某一channel对输出的影响,这里采用贪婪算法逐个的删除通道,直到保留的通道个数满足要求为止,则裁剪策略可表示如下:
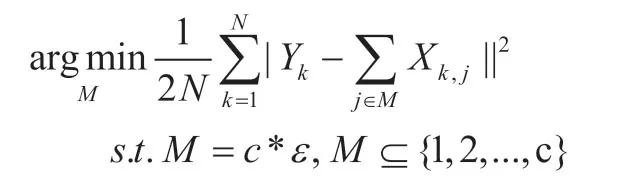
通过上式及贪婪算法确定保留的通道索引后,需要对第i层权重进行重构:

其中,WFilter,j是第i+1层权重的第j个通道。
2 Mobilenetv2模型裁剪
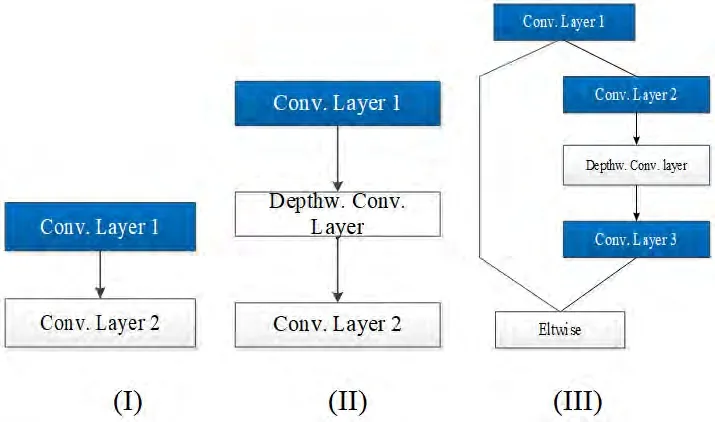
图1:Mobilentv2网络中典型的结构模块

图2:Mobilentv2网络裁剪流程
Mobilenetv2网络与Mobilenet一样都属于小网络模型,都采用了Depthwise Convolution+1x1 Convolution结构,极大简化了卷积参数复杂度,达到加速卷积的效果。所不同的是,Mobilentv2采用的是“扩张-卷积-压缩”的形式,并运用了Resnet的shortcut结构。因此,在精度上,较前者更高,广泛应用于边缘端图像分类系统中。Mobilenetv2中典型的几种结构模块,如图1所示。实现对图1中(Ⅰ)、(Ⅱ)、(Ⅲ)三种典型结构的裁剪,基本可实现对Mobilenetv2整体网络的压缩。针对I,II型的结构,我们裁剪Conv.Layer 1层,并对余下网络层,相应地,调整weight参数;而对于III型结构,我们顺序裁剪Conv.Layer 1和Conv.Layer 2层,并相应调整模块余下部分weight参数。我们采取“由上而下”、“逐层微调”的裁剪策略,具体流程如图2所示。
3 实验结果与分析
3.1 实验数据集简介
实验数据来源于路边、岔口等摄像机采集的视频数据。将视频数据按帧抽取,并进行手工标注,共获得57338张前向车辆类型图像,如图3所示,其中47738张图像作为训练集,其他9600图像作为测试集,测试集与训练集图像数量之比约为1:5。各类车型数量分布如表1所示。

图3:车辆类型数据集
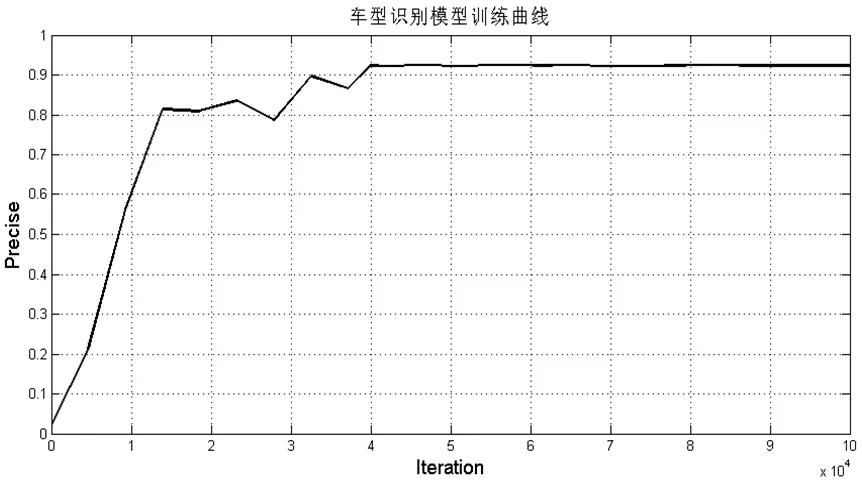
图4:车型识别模型训练曲线
3.2 实验结果与分析
模型裁剪在Ubuntu16.0.4环境下进行,所使用的服务器安装有4块NVIDIA Tesla V100显卡。首先,采用Caffe[11]框架进行实验,训练了Mobilenetv2车型分类模型。网络的训练参数设置如下:采用Multistep学习策略,初始学习率为0.001,每20个epoch,学习率缩小10倍,权重衰减为0.0005,训练时Batchsize为32,测试时Batchsize为16,采用均方根反向传播(RMSProp)学习策略提高收敛速度,rms_decay设置为0.98。获得原始分类精度0.9222,如图4所示。在此基础上,进行模型裁剪与性能评估。然后,对Mobilentv2模型进行裁剪。裁剪后,微调参数设置与上文所述完全一致,仅仅初始学习率调整为0.0001,共对26层网络进行了裁剪,具体结果,如表2~3所示。裁剪后模型精度0.9160,减小6.7%,推理时显存节约66MB,推理时间节约6.12ms。

表1:车辆类型数据集样本数量分布
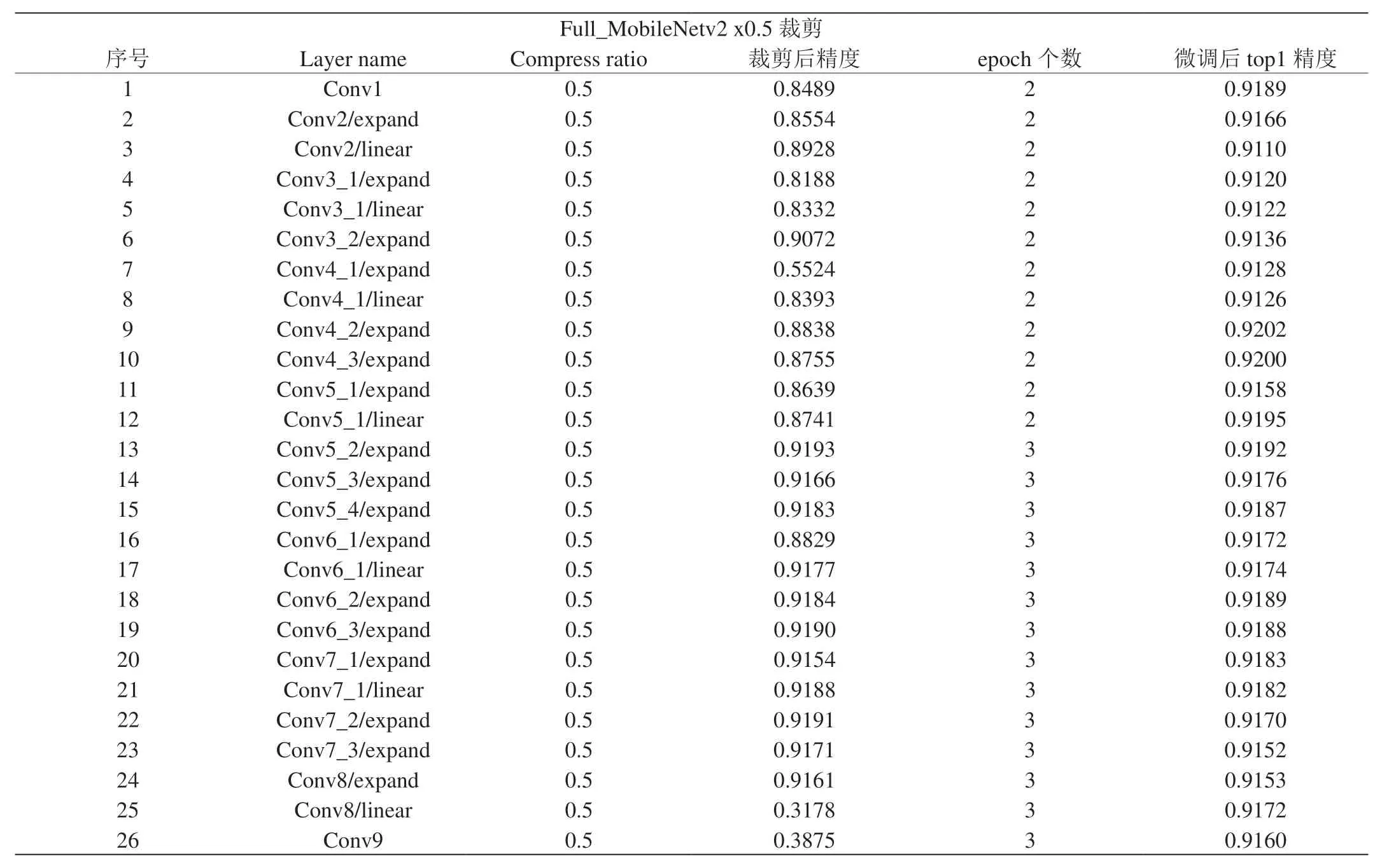
表2:Mobilenetv2模型裁剪

表3:裁剪后模型性能对比
4 结束语
本文研究了面向轻量级网络MobileNetv2的车型识别系统的模型裁剪方法。该方法属于Filter级模型裁剪技术。与基于Lp-norm的裁剪技术相比,该方法考虑了裁剪对后续层输出的应用,保守性较小。最后,在车型识别模型上进行裁剪实验,实现了,在几乎不损失Top1精度的情况,节约显存以及提高推理速度的效果。
