用户与项目语义相似性填充的协同过滤推荐方法
2020-06-11秦春秀
祝 婷,秦春秀
(1.西安工业大学 图书馆,西安 710021;2.西安电子科技大学 经济与管理学院,西安 710071)
随着互联网技术的广泛应用和普及,网络空间中的信息资源急剧增长,2012年国际数据集团的一份报告指出,预计到2020年,世界数据总容量将增长至35.2 ZB,是2011年的22倍[1]。由此可见,用户每天都面临着海量的信息资源,很难从中获取有价值且适合自己的资源。在这种背景下,个性化推荐方法便显得越发重要。通常推荐方法主要分为协同过滤推荐方法、基于内容的推荐方法和混合推荐方法[2]三大类。在上述推荐方法中,协同过滤是当前业界普遍应用且推荐效果相对准确的推荐方法[3],其是利用相似性方法计算出目标用户的相似用户,即近邻用户,获取近邻用户的喜好对目标用户产生个性化推荐。其中关键一步是获取近邻用户,但由于用户仅仅对少量项目有评分,这就造成评分矩阵的稀疏性,使得无法准确获取近邻用户,进而影响到推荐的准确性。
为了缓解稀疏性问题,不少学者对其进行了研究,主要方法有矩阵填充、聚类、矩阵降维和分解技术等。在矩阵填充方法上,最常见的是利用缺省值、均值以及众数进行填充。这些方法可以提高推荐精度,但没有考虑到用户的个体差异,使用统一数值表示所有用户的兴趣爱好,没有做到个性化。文献[4]利用关联规则数据填充用户-项目评分矩阵,降低其稀疏性。随着关联数目的增多,推荐的复杂度会越来越大。文献[5]使用BP神经网络算法计算用户-项目评分矩阵中的缺失值,填补空值,从而处理近邻用户集合的稀疏性问题。然而随着计算时间的增长,BP神经网络的收敛会越来越慢,导致查找近邻用户速度变慢。在聚类方法上,文献[6]利用凝聚层析聚类算法对社区进行划分,在目标用户所属的社区范围内利用用户评分及标签计算用户间相似性,最终进行推荐。由于该模型仅在社区内部进行相似性计算,因此可以有效缓解数据稀疏性。聚类可以降低近邻用户的查找次数,但是并没有从根本上解决数据的稀疏性问题。在矩阵降维和分解技术上,文献[7]综合基于用户的协同过滤算法和基于项目的协同过滤算法,同时利用双聚类技术降低矩阵维度。降维虽然能优化矩阵的稀疏问题,但是在降维的过程中会丢失有效数据,影响推荐精度。文献[8]提出了一种结合矩阵分解和延伸相似度的最近邻算法,利用矩阵分解技术降低稀疏性,在计算皮尔逊相似度时增加了延伸相似度,进一步克服了矩阵的稀疏性。但是在矩阵的分解过程中无法保证数据的完整性,同样会造成有效数据丢失。
以上方法提高了推荐的准确性,都没有考虑用户及项目的语义特征,可解释性不强。推荐系统由用户、项目以及评分组成,可见考虑用户和项目的语义特征是非常有必要的。因此,本文从用户及项目两个角度出发,分别通过用户属性特征及项目领域本体计算出未评分项目的预测评分,加权两者作为最终数值填充至评分矩阵,解决其稀疏性问题,最终达到提高推荐准确度的效果。
1 相关工作
1.1 协同过滤技术
协同过滤技术是从用户自身出发,通过计算与其他用户间的相似性,寻找目标用户的近邻用户,进而根据近邻用户喜好的项目对目标用户进行推荐。其核心思想是用户往往会选择和自己兴趣相投的用户喜欢的商品。由于协同过滤推荐过程中用户对推荐的项目是预料不到的,可以挖掘用户潜在的却未发现的喜好,因此具备推荐新项目的能力。协同过滤推荐方法分为基于用户的协同过滤与基于项目的协同过滤两类[9]。基于用户的协同过滤方法是获取用户-项目评分矩阵,在此矩阵上利用相似性算法计算用户间相似性,获取目标用户的近邻用户,根据近邻用户的评分计算目标用户对未评分项目的预测评分,并以此进行推荐。基于项目的协同过滤思想是获取目标用户的高评分项目,在评分矩阵上利用相似性算法计算项目间的相似性,寻找与高评分项目最为相似的项目,并将其推荐给用户。
1.2 协同过滤存在的问题
协同过滤方法已经广泛应用于产业界,但由于其自身的算法特性及应用场景导致在推荐过程中仍旧存在一些缺点,主要表现为稀疏性问题、冷启动问题以及扩展性问题[10]。
① 稀疏性问题
在实际场景中,项目的数量往往非常庞大,通常用户仅对不超过1%的项目进行评分[11],而两个用户对同一项目的评分则更少,这样就使得通过评分矩阵计算用户相似性的数据非常稀疏,导致无法准确寻找近邻用户,影响推荐的准确性。
② 冷启动问题
冷启动问题是指新用户没有对系统中的任何项目进行评分,因此无法计算该用户的近邻用户,也就无法进行推荐。同理,当一个新项目进入系统时,由于还没有用户对其作出评价,也就无法将该项目推荐给用户。
③ 扩展性问题
通常系统中的用户和项目规模都异常庞大,这样就导致在计算近邻用户时需要花费大量的时间,即算法时间复杂度高,实时性也很难保证。
2 用户及项目语义相似性填充的协同过滤推荐
为了解决由于用户仅对少量项目评分而造成评分矩阵的稀疏性问题,本文将用户语义相似性及项目语义相似性引入到协同过滤方法中,分别计算用户及项目语义相似性,利用其相似性预测出对应评分,进而完善原评分矩阵,然后根据填充后的矩阵计算近邻用户,最后进行推荐。具体可描述为以下5个步骤:
① 用户语义相似性度量。使用性别、年龄和职业这三项属性将用户进行语义特征表示,根据这些特征计算用户相似性,进而对未评分项目进行预测。
② 项目语义相似性度量。首先构建项目领域本体,然后利用领域本体中的语义关系计算出项目相似性,最后对未评分项目进行预测。
③ 填充评分矩阵。分别将根据用户语义相似性和项目语义相似性计算出的预测评分加权获取最终评分值,利用该值填充评分矩阵。
④ 近邻用户计算。根据修正的余弦相似性算法计算出用户相似性矩阵,进而获取近邻用户。
⑤ 个性化推荐。通过获取近邻用户的评分数据,进而预测项目评分,最终进行Top-N推荐。
2.1 用户语义相似性度量
用户由一些属性特征组成,这些属性特征构成用户的语义表示,可以使用属性特征来计算用户间语义相似性。通常情况下,用户对某种事物的喜好往往受个体特征的影响。性别方面,男性和女性由于心理和思维方式不同,其对事物的选择往往不一致。比如选择观影时,女性一般钟情于情感电影,而男性对战争片比较感兴趣。年龄方面,用户的心理成熟度和认知水平会随着年龄的增长而发生变化,进而对用户的选择产生影响。职业方面,受到不同工作场景和工作内容的影响,不同行业的从业者对事物的认知和理解将有所区别,相反,同一行业的工作群体对某一事物的接受度和喜爱程度将趋于统一,进而影响用户选择和对事物的评价。综上所述,具有相同属性的用户对同一项目感兴趣的概率较大。
本文将用户数据集记为U(A1,A2,A3,…,An),其中U为用户,A为用户属性。经过上述分析,最终选择性别、年龄和职业作为用户的属性特征,将用户表示为U(id,age,gender,occupation),id为用户编号,可唯一识别用户。属性取值见表1。

表1 用户属性取值
设存在用户U1(A1,U1,A2,U1,A3,U1)和用户U2(A1,U2,A2,U2,A3,U2)。则U1和U2间的用户语义相似性为
(1)
式中:n为属性个数;a1、a2、a3分别为年龄、性别和职业在用户属性特征中占用的权重,mi为系数。通常情况下,年龄因素对用户的兴趣爱好影响最大,其次是性别因素,最后是职业因素。因此,属性权重分别取值为a1=0.5,a2=0.25,a3=0.25。
用户相似性计算核心代码如算法1所示。
算法1:计算用户语义相似性矩阵。
输入:用户信息文件User.dat,用户属性权重a1、a2、a3。
输出:用户语义相似性矩阵UserSimilarity[n][n]。
User[n][3] = Read(User.dat);
fori=0 ton
forj=0 ton
m1=User[i][0]==User[j][0] ? 1:0;
m2=User[i][1]==User[j][1] ? 1:0;
m3=User[i][2]==User[j][2] ? 1:0;
UserSimilarity[i][j]=a1*m1+a2*m2+a3*m3;
end for
end for
通过用户语义相似性计算评分矩阵中的缺失值:
(2)

2.2 项目语义相似性度量
本体作为语义网的重要组成部分,是对世界或者领域知识、概念、实体及其关系的一种明确的、规范的概念化描述[12]。本体具体可以表示为分层的树状结构,其中节点表示项目,节点之间的连线代表项目间的语义距离。项目间的语义关系可以通过本体来表示。在本体的构建过程中,选择核心概念并调整概念间的关系尤为重要,需遵循清晰化、一致性、可扩展、编码偏差最小和最小承诺这五项准则[13],在此基础上,使用本体构建工具即可完成本体构建。Protégé软件是由斯坦福大学生物信息中心研发完成,该软件用于编辑本体与获取知识,实现了构建本体概念类、关系、属性以及实例,同时为用户屏蔽了底层的本体描述语言,用户可快速实现本体模型的构建。
由于《中国图书馆分类法》类目规范、分类准确,是目前使用最为广泛的分类法体系,因此本文对其中“J9 电影、电视艺术”这一类别进行进一步的数据清理及语义调整,将其转化为电影领域本体。在构建过程中,通过增加、删除和修改等操作在该分类部分中选择核心概念。例如,在此分类的基础上增加“动作片”“科幻片”等常见的电影类型。遵从本体对关系的界定原则,调整概念之间的关系,如等同关系、等级关系和相关关系。在以上分析的基础上,通过Protégé 5.5.0软件进行电影领域本体的构建。最终构建结果如图1所示。
本体构建完成后,接着就是计算概念间的语义相似性,基于本体的语义相似性方法包括基于距离的语义相似性计算、基于内容的语义相似性计算、基于属性的语义相似性计算和混合语义相似性计算。其中基于距离的语义相似性可以通过本体树状分类体系中概念之间的路径长度来度量[14],具体方法包含Shortest Path法、Weighted Links法和Wu and Palmer法等。其中Wu and Palmer法并不是通过直接计算项目间的路径长度来衡量其相似性,而是基于项目与其最近公共父节点之间的距离度量项目相似性。考虑到部分项目所属类型不止一种,例如,有的电影既属于爱情片又属于喜剧片。因此本文首先使用Wu and Palmer法计算项目类别之间的语义相似性,然后取项目类别相似性的平均值作为最终的项目语义相似性。计算方法如下:
(3)
(4)
式中:sim_itemType(t1,t2)为项目所属类别t1和t2之间的相似性;N1和N2分别为项目类别与最近公共父节点的距离;H为最近公共父节点与根节点之间的距离;sim_item(I1,I2)为项目I1和I2之间的语义相似性;T1和T2为对应项目所属的类别集合;n1和n2为类别集合中元素个数。
项目语义相似性计算核心代码如算法2所示。

图1 电影领域本体表示
算法2:计算项目语义相似性矩阵。
输入:项目信息文件Movies.dat,项目类别数组Item Type[n],电影领域本体。
输出:项目语义相似性矩阵Item Similarity[n][n]。
Item Type Similarity[n][n] = {{}};
Item Similarity[m][m] = {{}};
Build Tree(Movies);
fori=0 ton
forj=0 ton
N1=Get DepthIn Tree(Movies,Item Type[i]);
N2=Get DepthIn Tree(Movies,Item Type[j]);
H=Get Father Depth(Movies,Item Type[i],Item Type[j]);
Item Type Similarity[i][j]=2*H/(N1+N2);
end for
end for
Movies[n][10] = Read(Movies.dat);
fori=0 tom
forj=0 tom
Item Similarity[m][m]=Cal Similarity(Movies[i],Movies[j],Item Type Similarity[i][j]);
end for
end for
同理,通过项目语义相似性计算评分矩阵中的缺失值:
(5)
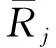
2.3 用户-项目评分矩阵填充
协同过滤方法中用户对项目的喜爱程度通过评分矩阵表示,具体见表2。其中u1到um分别为m个用户,I1到In分别为n个项目,其中数值为评分,大小在1~5之间,为用户对项目的喜爱程度,分值越高表示越喜欢,反之则越不喜欢,“-”为用户还未对该项目发表评价。真实场景中,用户已发表评价的项目占比极小,这就造成了根据评分矩阵计算近邻用户的不准确性,因此,填充评分矩阵是非常有必要的。

表2 评分矩阵
本文分别根据用户语义相似性和项目语义相似性计算出预测评分,然后加权两者获得最终的预测评分对评分矩阵进行填充,计算方法见式(6),其中R_fill为最终的填充值。
(6)
填充矩阵计算核心代码如算法3所示。
算法3:计算用户-项目评分填充矩阵。
输入:评分文件Rating.dat,用户语义相似性矩阵User Similarity[n][n],项目语义相似性矩阵Item Similarity[m][m]。
输出:用户-项目评分填充矩阵Filled Rating[n][m]。
Rating[n][m]=Read(Rating.dat)。
fori=0 ton
forj=0 tom
Similar User[10]=Get Top10 Similar User(User Similarity[i][n]);
SimilarItem[10] = Get Top10 SimilarItem (ItemSimilarity[j][m]);
R_User=Pridect (Similar User[10],Rating[i][j]);
R_Item=Pridect (SimilarItem[10],Rating[i][j]);
Filled Rating[i][j] = (R_User+R_Item)/2;
end for
end for
2.4 近邻用户计算
评分矩阵填充完成后,接下来就是协同过滤最关键的一步,即使用相似性算法识别近邻用户。
通常,相似性大小可以利用Pearson相关系数、余弦相似性方法和修正的余弦相似性进行计算。其中,Pearson相关系数方法只用于计算两个定距变量间联系的紧密程度,并未考虑用户评价过的项目数量对相似性计算的影响,因此,如果用户之间仅存在一个相同项目的评分,则无法计算相似性。余弦相似性方法根据向量夹角的余弦值度量相似性,由于不同用户对同一项目的评价尺度不同,对于相同喜好程度的项目,有的用户习惯给予高分,有的用户习惯给予低分,因此该方法不能准确给出用户相似性,而修正的余弦相似性通过评分的均值来消除评价尺度不同而造成的差异。因此本文采用修正的余弦相似性来计算用户相似性,用户u1和用户u2间的相似性计算方法[15]见式(7)。通过式(7),获取用户相似性矩阵,针对目标用户,根据用户相似度从大到小依次排序,选取前k个用户作为近邻用户,表示为nei=(u1,u2,u3,…,uk)。
sim(u1,u2)=
(7)

2.5 个性化推荐

(8)
3 实验与评价
3.1 实验数据
MovieLens数据集由users.dat,movies.dat和ratings.dat三个文件组成。users.dat中存储了用户具体信息,如编号、性别、年龄以及职业等。movies.dat存储了电影信息,包括电影编号、名称和类别。ratings.dat包含了6 040名用户对3 883部电影的1 000 209个评分(分值为1~5分),其中每位用户的评分数量均大于等于20次。为验证本文方法的个性化推荐效果,考虑到计算量等因素,本实验的测试数据大小设置为5 000条,从上述数据集中随机获得,具体涉及426名用户对248部影片评分,随机选取其中80%作为训练集,其余作为测试集进行推荐效果验证。通过训练集生成的矩阵计算用户相似性和获取近邻用户,对测试集中的项目进行预测评分,与相应的实际评分进行对比来衡量推荐的准确性。该实验选取的数据集稀疏性级别计算结果为95.267%。
3.2 实验评估策略
本文采用平均绝对误差(Mean Absolute Error,MAE)和接收者工作特性(Receive Operating Characteristic,ROC)曲线作为评估方法的标准。
3.2.1 平均绝对误差
MAE可以根据预测评分和实际评分的差值衡量推荐精度,MAE越小,代表推荐效果越好。将预测评分数据集表示为{p1,p2,p3,…,pn},真实评分数据集表示为{q1,q2,q3,…,qn},则平均绝对误差计算方法[6]为
(9)
3.2.2 ROC曲线
在推荐过程中,项目可以理解为用户喜欢和非喜欢这两种类别,对应的混淆矩阵见表3。其中的“1”表示正类,即用户喜欢的项目,“0”表示负类,即用户不喜欢的项目。如果评分大于某一阈值,则定义该项目为正类,否则为负类。MovieLens数据集中评分区间为[1,5],本实验对用户的真实评分取阈值为3,即认为评分值在[3,5]区间内为用户真实喜欢的项目,评分值在[1,2]区间内为用户真实不喜欢的项目。
若一个项目是用户真实喜欢的,并且该项目也被预测为用户喜欢的项目,那么该项目被归类为真正类项目(True Postive,TP);若一个项目是用户真实喜欢的,但是预测结果表明该项目是用户不喜欢的项目,那么该项目被归类为假负类项目(False Negative,FN);若一个项目是用户真实不喜欢的,但是预测结果表明该项目是用户喜欢的项目,则把该项目归类为假正类项目(False Postive,FP);若一个项目用户实际不喜欢,并且预测结果表明该项目是用户不喜欢的,则将该项目归类为真负类项目(True Negative,TN)。

表3 混淆矩阵
真正类率(True Postive Rate,TPR)定义为真实是正类的项目中预测为正类的比例,假正类率(False Postive Rate,FPR)定义为真实是负类的项目中预测为正类的比例。TPR、FPR相应计算方法如下:
(10)
(11)
以FPR作为横轴、TPR作为纵轴的二维空间即定义为ROC空间。当阈值在某一区间内取值时,根据项目的预测评分及式(10)、(11)计算可得出若干(FPR,TPR)点,将这些点的连线即定义为ROC曲线。当ROC曲线越接近左上方时,即曲线下方的面积AUC(Area Under ROC Curve)越大时,该推荐系统性能越好。
3.3 实验结果与讨论
本文分别将传统的协同过滤方法(Traditional Collaborative Filtering,TCF)、基于缺省值填充的协同过滤方法(Collaborative Filtering Based on Default Filling,CFBDF)、基于均值填充的协同过滤方法(Collaborative Filtering Based on Average Filling,CFBAF)与本文方法(Collaborative Filtering Based on User and Item Semantic Filling,CFBUISF)进行平均绝对误差(MAE)和ROC曲线对比。
3.3.1 平均绝对误差对比分析
本节实验旨在对比分析本文方法和其余3种方法在选取不同近邻用户数目时MAE值的变化情况,实验设置近邻用户数初始值为2,每次以2为间隔进行递增,直至近邻用户数为24,总计运行12次,MAE值如图2所示。

图2 预测精度对比
图2表明,随着近邻用户数的增加,MAE值先减小后稳定。这表明在一定范围内,随着近邻用户数的增加,用户评分预测的精准性进一步提高,直到近邻用户数增加到一定程度,对推荐的准确性影响趋于稳定。在不同的近邻用户数下,文中方法对应的MAE值均低于其余3种协同过滤推荐方法。
3.3.2 ROC曲线对比分析
本节实验旨在对比分析本文方法和其余3种方法在不同阈值下对应的ROC曲线。由于本文实验数据中的评分区间为[1,5],因此设定阈值初始值为5,每次以0.01为间隔进行递减,直至阈值为1,分别利用文中方法和其余3种方法循环计算(FPR,TPR)点500次,将各自计算所得坐标点在ROC空间中标注并通过平滑曲线连接,即可得ROC曲线如图3所示。
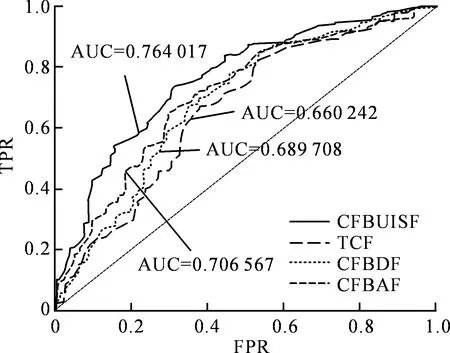
图3 ROC曲线对比
图3表明,本文方法和其余3种方法计算所得ROC曲线均在ROC空间对角线左上方(其中对角线表示随机判断项目为喜欢或非喜欢两种类别的ROC曲线),说明本文方法和其余3种协同过滤方法均具有一定的推荐意义。另外,本文方法对应的ROC曲线较其余3种方法对应的ROC曲线更靠近ROC空间左上角,即AUC值更大。
综合图2和图3可以得出,对于推荐结果的准确性,CFBUISF>CFBAF>CFBDF>TCF。分析其原因为TCF由于数据稀疏性导致无法准确寻找近邻用户,从而影响推荐精度。CFBDF利用缺省值0对矩阵进行填充,解决了评分矩阵的稀疏性问题,因此推荐精度大于TCF。但是相对使用0值进行填充,利用评分均值对矩阵填充更具有实际意义,因此CFBAF的推荐精度大于CFBDF。无论是利用缺省值0还是评分均值,其都是对所有用户一概而论,使用同一数据填充评分矩阵,并没有考虑到个体差异,也就是没有考虑用户和项目的语义特征,使得推荐结果产生偏差。CFBUISF充分利用用户属性及项目特征,通过用户语义相似性和项目语义相似性填充用户-项目评分矩阵,可以较为精确的寻找近邻用户,最终使得推荐结果更为准确。
4 结 论
针对实际场景中用户仅对极少数项目评分而造成评分矩阵的稀疏性问题,研究者们提出了多种改进方法,其中包括对矩阵进行降维处理和利用预测评分对矩阵进行填充。本文利用用户和项目间的语义相似性预测项目评分,加权两者获得最终评分,使用最终预测评分填充用户-项目评分矩阵。实验表明,本文方法能有效提升推荐精度,但是由于前期需要计算用户和项目语义相似性,导致推荐过程耗时较长,这个问题可以通过矩阵降维技术和矩阵填充技术相结合来解决。在互联网的快速发展下,人工智能、数据挖掘和机器学习等技术越来越成熟,将这些技术与推荐技术结合,可以使推荐更加智能化、个性化。另外,协同过滤技术还面临一些新的问题及挑战,例如安全问题、隐私保护问题等,均为下一步工作需要研究的问题。
