改进的协同过滤算法在商品推荐中的应用
2020-06-10刘鑫李家乐赵敏
刘鑫 李家乐 赵敏
(吉林建筑科技学院 吉林省长春市 130114)
随着互联网信息的爆炸式增长,人们在享受丰富的数据带来更多方便的同时也要忍受寻找自己真正需要的信息的时间越来越长所带来的困扰。推荐系统为解决这一问题应运而生,推荐系统是针对不同用户的兴趣、爱好为其进行个性化推荐商品的服务,个性化推荐技术在一定程度上可以节省用户搜索信息的时间,提高信息获取效率,目前在个性化推荐算法及相关技术和应用领域方面,已经成为国内外大批学者研究的热点问题。其中主要研究的推荐算法有协同过滤算法、基于知识的推荐以及混合推荐算法等,而协同过滤一直是研究最多的技术之一,它通过维护用户-商品评分矩阵,通过相似度计算公式,建立邻居用户集,产生推荐列表。
本文结合传统的协同过滤推荐算法在打分稀疏,推荐正确率较低等问题,结合二部图函数设计改进的协同过滤推荐算法,给出了基于用户和基于商品的混合列表推荐方式。使用户更快、更方便地获取到自己所想要的资源。
1 现有的协同过滤算法及算法存在的问题
1.1 协同过滤算法的问题描述
协同过滤推荐(collaborative filtering recommendation)是应用最广泛的一种推荐技术之一。它假设的前提是:若要向一个用户推荐商品,首先找到与本用户兴趣爱好相似的其它用户群,然后将相似用户感兴趣的商品推荐给本用户。如图1所示,user-B选择了item-a、item-b和item-d,而user-C选择了item-b和item-d,认为user-B和user-C是相似用户,因此将user-B选择的item-a推荐给user-C。通常协同过滤算法分两类:一类是基于记忆,基于记忆的又分为基于用户的协同过滤和基于物品的协同过滤,另一类是基于模型。具体推荐过程分为三个阶段:用户兴趣表示、相似用户产生、商品推荐。
1.2 协同过滤算法分析
1.2.1 协同过滤算法的优点
协同过滤推荐是基于相似用户的兴趣选择进行推荐,因此最大的优点是对于推荐商品的资源类型不限,不需要对商品进行内容信息提取,而只需要用户对选择的商品进行简单的评分,通过采集评分矩阵,通过相似度计算,得到相似用户的邻居集合,从而根据邻居集中用户选择的物品预测目标用户感兴趣的物品,向用户推荐,推荐的商品可以是视频、美食或其他日用品等。
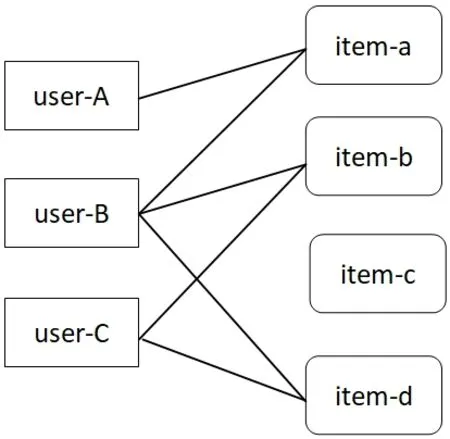
图1:基于用户的协同过滤
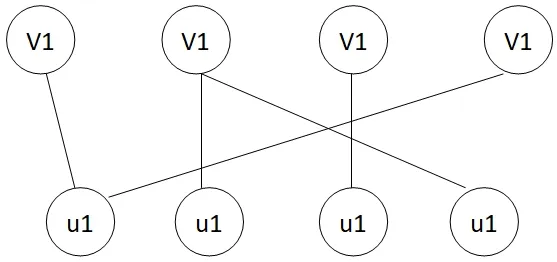
图2:用户-商品关系拓扑结构图
1.2.2 协同过滤算法的缺点
通过分析传统的协同过滤技术,一方面由于协同过滤推荐算法需要用户的评分进行推荐,对于新用户和新商品产生时,由于没有用户-商品的评分数据,导致出现冷启动或数据稀疏问题,无法进行推荐;另一方面随着用户及商品的数量增加、商品的类型更加多样化、使得用户-商品之间的关系更加复杂,通过计算相似度构建用户邻居集合的效率会越来越低,因此传统的协同过滤算法就存在数据稀疏、可扩展性和冷启动等几个问题的制约,影响最终商品的推荐结果和推荐效率。
2 改进的协同过滤算法

图3:算法流程图
传统的协同过滤推荐算法在寻找相似用户时由于只是参考了邻居集合中相似用户进行评分的商品,而当相似用户进行评分的商品数量太少,获得的评分矩阵稀疏时,最终产生的推荐列表可靠性较低,因此本文对二部图模块函数的理论进行研究,在协同过滤算法中引入二部图模块函数(Bipartite Modularity)对用户和商品进行相似性划分,扩大了用户间相似性计算的范围,提高了相似性的可靠性和准确度,以商品社区划分为例,具体步骤如下:
第一步:为每个商品初始化不同的社区,初始时商品数与社区数相同;
第二步:对于任意一个商品Si,首先将其添加到其他不同商品Sj所在的社区,计算社区变化后的每一个函数值,比较Si加入不同Sj所在的社区产生的函数值,找到函数值是正数且最大时对应的邻居商品Sj,则将Si划分到Sj所在的商品社区;如果所得函数值都不为正值时,Si将继续留在初始社区;
第三步:对所有的商品节点Si,重复上述操作;
第四步:更新所有的商品Si社区,并将划分到一个社区的商品进行重新编号作为一个新的商品节点,生成新的二部图,两次的二部图进行比较,如果新的二部图的社区拓扑结构与之前有变化,重复执行第二步,直到两次的拓扑结构没有变化时执行第五步;
第五步:输出最终的商品社区划分。
3 改进的协同过滤算法应用于商品推荐中
3.1 问题表述
将用户-商品评分的二元关系矩阵表示成二部图,描述为G(Vu,Vs,E)表示。其中用户总和表示为:Vu={u1,u2,u3,…,um};商品总和表示为:Vs={s1,s2,s3,…,sn};用户-商品关系矩阵表示为:A={aij},其中,当 aij=1表示ui用户选择了sj商品。即规定任意两个用户(商品)节点之间的边的条数越多就表示这两个用户(商品)节点之间的联系越紧密,同时若任意两个用户(商品)都 与一个公共节点相连,那么这两个节点也一定存在某种程度的联系,建立用户-商品二部图拓扑结构如图2。
3.2 相似性计算
第一步:初始化社区。
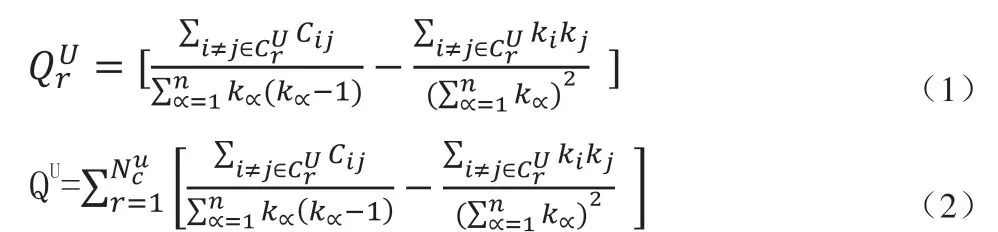
第二步:求取最近邻。
3.3 推荐阶段
针对进行推荐商品的用户,推荐列表的生成方式有三种:第一种推荐列表由被分配到相同的社区的商品构建,第二种推荐列表由邻居用户社区的用户构建,第三种推荐列表是前两种混合方式生成的。
为了描述生成的预测评分过程,设置四个概念:

其中,R(ui)表示同用户ui在相同社区的其他用户的集合,R(sm)表示同商品sm在相同社区的其他商品的集合,L(ui)是被用户ui选择的商品集合,L(sm)是选择了相同商品sm的用户集合。
为了得到推荐列表,对基于邻居用户社区进行推荐,用户ui对商品sm进行预测得到评分值表示为:
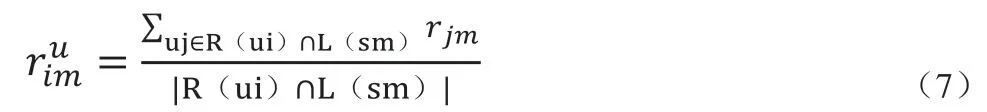
基于商品社区进行推荐,用户ui对商品sm进行预测得到评分值表示为:
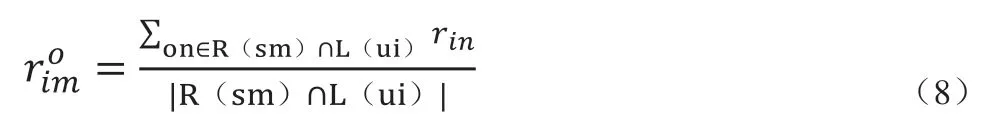
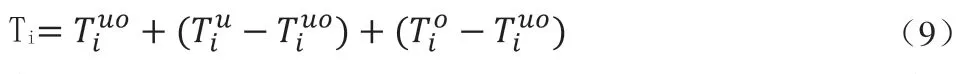
集合中商品的排序按照推荐列表预测得到的评分值进行从高到低排序,取最高值进行推荐。
3.4 推荐算法建模
图3是基于改进的协同过滤推荐算法应用于商品推荐的算法流程图,可以将推荐算法建模过程分成两个部分:用户-商品关系建模和推荐实现建模,在用户-商品关系建模过程中,首先采集用户-商品的评分数据,分别构建用户和商品的二部图拓扑结构,建立用户-商品分类模型,然后搭建用户-商品二部图模型;在推荐系统建模过程中,首先根据二部图模块函数计算用户和商品间的相似值,构建用户-商品相似矩阵,应用改进的协同过滤推荐算法生成推荐列表,将预测得到的商品评分值进行从高到低排序,并对邻居用户推荐商品评分最高的商品,完成商品个性化推荐。
4 结束语
本文分析了传统的协同过滤算法,克服其在评分稀疏、正确率低的问题,在问题表述阶段、相似性计算阶段和推荐阶段,综合了利用二部图模块函数优化的方法构建用户-商品分类模型,搭建用户-商品二部图模型,通过计算用户和商品的相似性,设计得到改进的协同过滤算法。在实验阶段,将改进的协同过滤算法选取MovieLens作为基础数据集,进行基于社区划分的推荐算法与传统协同过滤推荐算法在正确率及稳定性方面的比较,分别在十组数据上运行基于商品社区和用户社区及混合推荐算法,取平均值,整体上看,改进的协同过滤算法正确率高,且可以在多次迭代后快速达到稳定。
