区域医疗数据采集方法优化
2020-06-10王正宏
王正宏
(合肥工业大学计算机与信息学院 安徽省合肥市 230000)
ETL(Extraction,Transformation and Loading)技术被广泛应用于医疗数据采集领域,是构建区域健康信息平台[1]的核心技术。在过去的研究中ETL任务分配和调度问题已经被证明是一个NP完全问题[2]。对此问题前人已经做了大量的研究,并提出了许多有针对性的方案。其中部分研究基于DAG(Directed acyclic graph)模型模拟任务调度场景,分别从权重、优先级和任务排序几方面考虑寻求关键路径[3~5](即ETL任务的最短执行时间)。不过大部分基于DAG模型的研究在集群环境下的应用效果都不很理想,因为这类研究主要依据确定的执行时间,而在集群环境下精确预测不同任务的执行时间非常困难。文献[7]结合并行元启发式方法与贪婪方案,提出了一种新的最优调度元启发式方法。文献[8]利用遗传算法对任务调度时间片中的应用负载特征采样,并将复杂的迭代过程分配到后续的多个调度采样周期中,以此为依据为任务分配符合计算特性的核心。在集群负载均衡方面文献[9~10]提出在云计算环境下的动态加权和改进的粒子群优化算法,Kokilavani[11]等提出了用于静态MetaTask调度的负载均衡Min-Min算法。业务数据加载、更新及时性高的业务需求方面,文献[12~14]做了任务实时调度方面的研究。为提升ETL任务调度效率本文提出了一种改进的任务调度策略。该策略综合考虑任务紧迫度、负载模式、数据规模以及集群资源占用情况,结合贪心算法思想将每个ETL任务分配到最合适的节点上执行。实验表明该策略能够在满足业务需求的情况下,有效提高ETL任务调度效率,缩短整体执行时间。
1 问题描述
1.1 问题概述
区域医疗数据采集主要是将区域内各级医疗单位的异构医疗数据通过ETL工具集成到统一标准的区域中心数据仓库。在淮南市健康信息平台医疗数据采集过程中,我们发现ETL工具Kettle在集群模式下的数据采集效率相比单机环境得到明显提升,但仍存在以下问题:
(1)不同任务要处理的业务数据重要程度不一,Kettle并未考虑任务本身的业务需求,导致一些急需执行的任务长时间处于等待序列。
(2)集群下Kettle在任务调度时默认使用轮询算法,按照任务序列依次将任务分配给各个执行节点。该算法没有考虑到任务本身的数据不平衡和各执行节点的资源占用情况,容易导致集群负载不均衡。
(3)任务执行时默认使用FCFS(First Come First Server)算法,这种静态的执行顺序不可调整的算法容易导致任务执行时间和等待时间不平衡问题。
1.2 ETL任务集群调度约束

图1:示例ETL任务

图2:拆分后的示例ETL任务

图3:ETL任务调度工作流程图
ETL指将一个或多个异构数据源的数据经过一系列加工处理再输出到一个或多个目标数据存储的流程。本文采用Kettle工具完成整个ETL流程。
Kettle中的ETL任务表现为Job和Transformation两种形式。Kettle中将转换作业作为一个任务调度单位,每个Kettle作业在同一时刻只能在集群中的一个执行节点上运行,不同的Kettle作业可以在集群中并行执行。一个Kettle作业中包含一个或多个具有指定先后顺序的步骤(Step)。步骤是每个Kettle作业的最小单位,一般将一个步骤作为一个线程在执行节点上执行。
ETL任务调度的目标就是在任务约束和资源约束的前提下,通过适当的调度策略将不同的任务分配到最合适的执行节点上,并且在执行队列中采用高效公平的执行策略,使集群环境下的资源得到高效的利用从而缩短ETL任务的执行时间。
2 改进的ETL任务调度策略
2.1 ETL任务相关定义
为了清晰表述文中任务调度的相关概念,这里引入数学模型的方法给出如下的一些定义。
定义5:E表示各步骤之间的先后关系。Pre(Stepj, Stepk)表示Stepj是Stepk的前驱步骤。

定义8:Type(Stepi)表示任务负载类型。

2.2 ETL任务预处理策略
2.2.1 ETL任务紧迫度权值模型
基于淮南市健康信息平台的实际业务需求,可以发现平台对数据需求的紧迫程度基本符合二八定律,即只有20%的中心库业务表数据是急需的。也就是说完成这部分数据的处理整个数据采集工作中最紧迫的。因此需要在任务调度之前根据实际业务需求为每个任务设定一个紧迫度,保证高紧迫度任务优先处理。
本文基于统一标准下的中心数据仓库表结构,为每个业务表赋予一个紧迫度权值α,α值越大说明该业务表紧迫度越高。当调度器读取ETL任务资源库时,根据每个ETL任务目标表的α值中的最大值为该任务赋予紧迫度权值θ
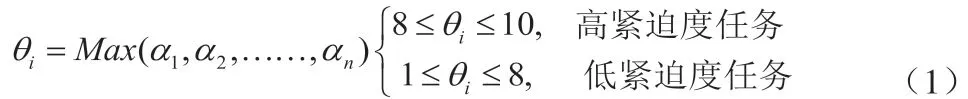
ETL任务调度器根据θi对ETL任务排序,并按上述定义分为高紧迫度任务和低紧迫度任务。
2.2.2 ETL任务划分策略
为了保证高紧迫度任务的高效执行,本文对此类任务进行了任务划分处理,从而提高任务并行度,缩短任务执行时间。根据ETL任务的定义可知每个ETL任务中包含多个具有先后顺序的处理步骤,正常调度情况下会将一个任务作为一个主体分配到一个执行节点进行处理。事实上每个任务中的这些处理步骤我们可以看作一个将每个步骤作为一个结点,步骤与步骤之间的先后关系作为边的DAG。本文采用深度遍历思想将一个复杂的ETL任务划分成多个线性顺序执行的简单ETL任务。图1所示是一个用DAG图表示的ETL任务,通过任务拆分可以得到图2所示的三个可以并行执行的ETL任务。将任务划分后得到的ETL任务重新赋予紧迫度权值,并根据紧迫度权值大小插入已排序的ETL任务列表。

表1:集群配置信息
2.2.3 ETL任务负载模式分类
在实际环境中每个ETL任务都包含大量的数据处理步骤,例如:值映射、格式转换、合并计算等。由于每个步骤要实现的功能不同,对处理资源的需求也存在很大的差异。比如有些步骤实现的功能需要进行大量的计算,那么就应该将该类型的任务放在CPU利用低的执行节点上执行。因此本文给出如下定义:

ETL任务调度器在任务分配时根据λi值的大小,将计算密集型任务分配到CPU使用率较低的执行节点上执行。
2.3 ETL任务调度分配策略
本文结合区域医疗数据ETL任务的本身特性和集群中各执行节点的资源使用情况提出一种基于贪心算法思想的任务调度分配策略。基于该策略设计的ETL任务调度工作流程图如图3所示。
贪心算法是一种求解近似最优解的方法,其核心思想就是从一个初始解出发不断选择当前的局部最优解,并最终通过这种贪心选择策略得到一个近似的整体最优解。本文贪心调度分配算法具体步骤如下:
(1)从待处理ETL任务集合T中取出高紧迫度任务并放入子任务集T1。
(2)将子任务集T1中的ETL任务依据λi值分别存入计算密集型任务队列Q1和内存资源消耗型任务队列Q2。
(3)根据每个ETL任务待处理源数据量大小分别对Q1和Q2从大到小排序。

(4)获取集群各执行节点的CPU与内存资源使用情况。
(5)取Q1队列中的首个任务放入当前CPU使用率最低的执行节点,若Q1队列不为空,则继续将队首任务放入当前CPU利用率最低的执行节点,直至Q1队列为空。
(6)取Q2队列中的首个任务放入当前内存使用率最低的执行节点,若Q2队列不为空,则继续将当前队首任务放入当前内存利用率最低的执行节点,直Q2队列为空。
(7)从待处理ETL任务集合T中取出剩余任务并放入子任务集T1,重复步骤2-6直至待处理ETL任务集合T为空时,算法结束。
ETL任务通过贪心调度分配到执行节点后,存储在执行器节点上的待执行队列中。Kettle中默认先来先服务(FCFS)作为待执行队列调度策略,FCFS是一种静态不可调的调度策略。这种策略容易导致执行节点资源长期被某个作业占用,队列中其它作业长时间处于等待状态。高响应比优先(HRRN)算法能够综合考虑执行时间和等待时间,动态调整任务执行优先级,相对FCFS算法而言能够较为公平的为每个任务分配线程资源。因此本文使用高响应比优先算法作为执行节点的执行策略。

表2:高紧迫度任务执行情况

图4:ETL任务执行时间对比

图5:集群节点CPU利用率

图6:集群节点内存利用率
3 实验结果与分析
3.1 实验环境
为测试本文ETL任务调度策略的性能,本实验在4台虚拟机上搭建了包含一个主节点和三个执行节点的集群环境。具体配置如表1所示。本文选取淮南市区域健康信息平台一个月的电子病历数据作为实验测试数据,该测试数据约包含一千万条数据记录。实验中共创建29个ETL任务,其中十万条记录以下的8个,十万至百万条的17个,百万条以上的4个。
3.2 结果与分析
实验通过在相同的集群环境下分别应用Kettle原始调度策略和本文所提的改进策略,从任务总执行时间和集群资源利用率两方面对所提ETL任务调度策略验证分析。ETL任务数量为5、10、20、29个时,使用两种调度策略消耗的时间如图4所示。
由图4可以看出在任务数不同的情况下,本文所提的ETL任务调度策略整体上优于Kettle的原始调度策略,并且随着任务数的增加两者调度执行时间差别不断增大。由此可知本文所提任务调度策略非常适用于大规模的ETL任务调度环境。
根据电子病历业务需求和上文所述的高紧迫度任务判定策略,可知本文测试的29个ETL任务中共有5个属于高紧迫度任务。在执行所有的测试任务情况下,5个高紧迫度任务具体执行情况如表2所示。(其中基于本文所提策略的任务调度开始于2020.1.19-9:14:00,基于Kettle原始策略的任务调度开始于2020.1.19-10:00:00)。
由表2可以发现Kettle原始调度策略在执行高紧迫度任务时,由于其采用的轮询调度策略导致高紧迫度任务长期处于等待状态,非常不利于业务正常开展。本文提出的改进的任务调度策略在满足业务需求方面相对原始调度策略有非常大的提高。在执行29个ETL任务的实验中我们分别统计了两种调度策略在三个执行节点上的CPU和内存平均利用率,具体情况如图5和图6所示。
由图5和图6所示的各执行节点CPU、内存利用率折线图可知本文调度策略下CPU和内存使用率较Kettle原始调度策略而言分配比较均匀,据此判断基于贪心算法的任务调度方案下集群负载较为均衡。综上所述实验分别从任务调度总耗时、业务需求以及集群负载均衡三个方面验证了本文所提改进ETL任务调度策略的优势。
4 结论
本文从淮南市健康信息平台数据采集中的实际问题出发,基于贪心算法思想提出了一种改进的ETL任务调度优化策略。该调度策略着重考虑了平台实际业务需求和集群负载均衡问题。实验证明,高紧迫度任务执行时间大幅缩减,同时ETL任务队列的整体执行时间也有所降低,基本达到了预期目标,并已在淮南市健康信息平台数据采集工作中试用。
