基于GoogLeNet 的手写体汉字识别*
2020-06-08倪建成
侯 杰,倪建成
(曲阜师范大学 软件学院,山东 曲阜 273165)
0 引 言
脱机手写体汉字识别已有近50年的研究历史,因为汉字类别数较大(参照GB2312-80 标准,常用汉字有6763 个类别)、易混淆的相似字形多以及书写风格的多样性使其一直是模式识别领域的研究难点。传统的手写体汉字识别分为三个步骤:图像预处理、特征提取与分类。预处理一般通过模糊化、灰度化、二值化以及归一化等方法来实现,目的是加强图像的有用特征、去除其他无关的噪声,从而使得特征提取更加方便[1]。特征提取是从原始输入中提取能表达特定汉字本身而又区别于其他汉字的无冗余性低维图像特征,目前效果较好的是一些统计特征,如Gabor 特征、Gradient 特征、HOG特征[2-3]。传统方法中常用的分类器有SVM[4]、线性判别分析(LDA)[5]和修正二次判别函数(MQDF)[6]。近年来基于修正二次判别函数的方法依然是研究热点,然而作为效果最优的传统识别方法,修正二次判别函数在典型手写体汉字数据集CASIA-HWDB 和ICDAR2013 上的识别准确率都还没有达到93%[6-8]。
随着计算资源性能的提高和大量标注数据集的出现,基于深度学习特别是卷积神经网络(CNN)的方法在计算机视觉和模式识别领域取得了巨大的成功[9~11],对手写体汉字的识别也逐渐由传统方法转变为基于神经网络的方法。多列深度神经网络(MCDNN)[12]被认为是第一个将CNN 成功应用到手写体汉字识别的模型,在ICDAR2013 数据集上取得了95.78%的准确率,其使用不同的数据集训练了八个网络,每个网络都含有四个卷积层和两个全连接层。Wu 等人[13]采用基于CNN 的模型在ICDAR 数据集上实现了94.77%的准确率,获得了2013 年ICDAR 脱机手写体识别竞赛的第一名,第二年他们通过采用4 种交替训练松弛卷积神经网络(ATR-CNN)的集成模式[14]来改进模型,达到了96.06%的准确率。2015 年Zhong 等人将传统的Gabor 特征提取与CNN 结合提出了HCCR-Gabor-GoogLeNet[15],在ICDAR2013 数据集上的识别准确率为96.35%,是在该数据集上第一个超越人类表现的模型。2017 年Zhang 等人[16]将传统的归一化Gradient 特征映射与CNN 结合,并采用一个适配层后在ICDAR2013 数据集上取得了97.37%的准确率。
以上模型虽然取得了不错的识别效果,但大都存在调优参数多、网络收敛慢、存储模型空间大等问题。由此,本文设计了一个基于GoogLeNet 的卷积神经网络HCCR-IncBN,该模型利用了Inception模块稀疏连接的优点,对同一输入特征映射进行多个尺度上的卷积操作,并多次使用1x1 卷积核来压缩数据,在增加网络深度的同时能够保证对计算资源的高效利用;为了加快模型收敛,在整个网络结构中充分应用了BN 算法。在实验阶段,以数据集CASIA-HWDB1.1 为训练集来识别3755 个常用简体汉字,在ICDAR2013 数据集上取得了95.94%的准确率;另外,以数据集MNIST 作为实验数据,在测试集上取得了99.37%的识别准确率。
1 卷积神经网路模型
1.1 Inception 模块
提高深度神经网络表现的最直接方式就是增加网络的深度和宽度,经典的AlexNet 和VGG 网络正是以此设计网络结构达到了更好的效果,但这会使得计算参数过多,消耗大量计算资源甚至造成过拟合问题。文献[10]提出的GoogLeNet 通过向网络中引入稀疏性可以在很大程度上解决上述问题,组成GoogLeNet 的基本模块为Inception,它把相关性强的特征先聚集到一起,每一种尺寸的卷积输出都作为总特征的一部分。
图1(a)和图1(b)分别展示了Inception-v1和Inception-v2 的 模 块 结 构。Inception-v1 模 块采用的卷积核大小分别为1x1、3x3 和5x5。与Inception-v1 相比,Inception-v2 模块将5x5 的卷积操作分成了两个3x3 的卷积操作,使得计算效率进一步提升,本文采用的是Inception-v2 模块。模块中1x1 卷积操作的主要作用是压缩输入数据的通道数从而减少参数计算量,该操作可以使得卷积参数降低到原来的三分之一。为了保证Inception 模块中三个尺寸的卷积操作和最大池化操作的输出可以进行维度上的连接,需要将卷积操作的步长设置为1、Padding 方式设置为‘SAME’,将池化操作的步长也设置为1。
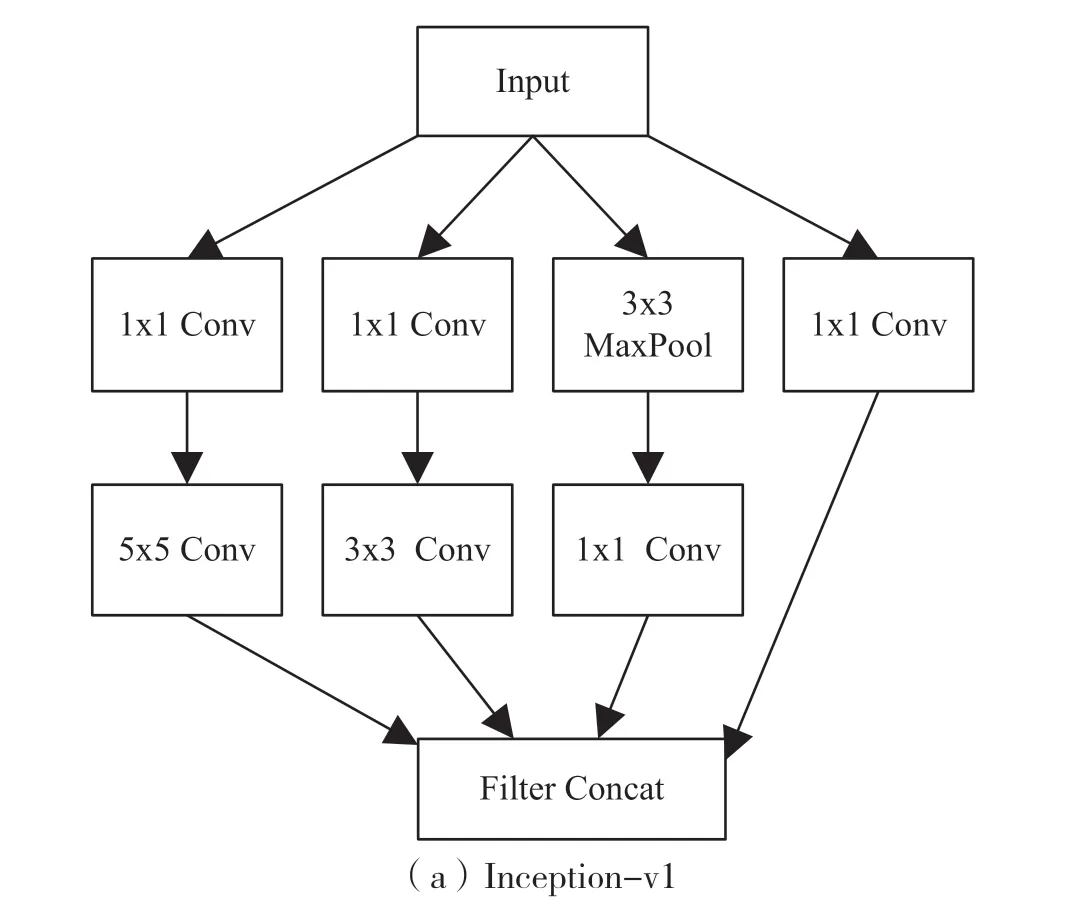
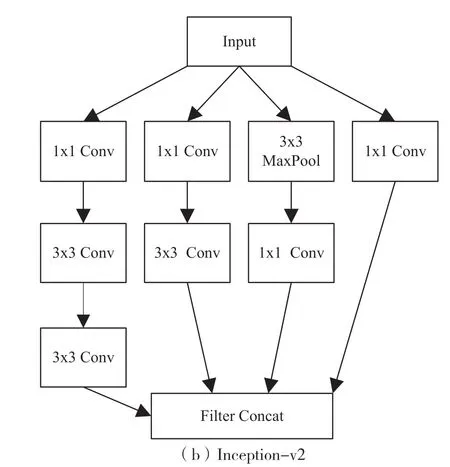
图1 Inception 模块结构图
1.2 HCCR-IncBN 模型结构
图2 展示了HCCR-IncBN 模型的结构以及每层输出特征映射的维度。该模型一共有15 层(只计算卷积层和全连接层),包括3 个卷积层、5 个Inception 模块和2 个全连接层。原始输入为64x64大小的灰度图像。模型开始是两组“卷积+最大池化”操作,卷积核大小为3x3,步长为1,最大池化操作的池化窗口为2x2,步长为2,整个模型中的四次卷积操作都采用此参数配置。第二个池化操作后是5 个Inception 模块,其中在Inception2和Inception4 后设置了最大池化层,在最后一个Inception 模块后设置了1x1 的卷积操作,该操作将4x4x608 的特征映射压缩为4x4x256。1x1 卷积操作完成后需要将特征映射扁平化为4096 维的向量,之后开始全连接层的操作,第一个全连接层包含1024个神经元,输出层神经元的具体个数根据不同的数据集来设置(HWDB 数据集设置为3755)。在HCCRIncBN 模型中,所有卷积层(包括Inception 模块中的卷积层)和全连接层后面都连接了一个BN 层,即在ReLu 激活函数之前先执行BN 算法。HCCR-IncBN 模型涉及的计算参数数量为6849035,按照存储一个浮点数需要4 个字节计算,存储模型所需的存储空间约为26.12MB。表1 列出了5 个Inception 模块中各卷积操作滤波器个数的具体设置。
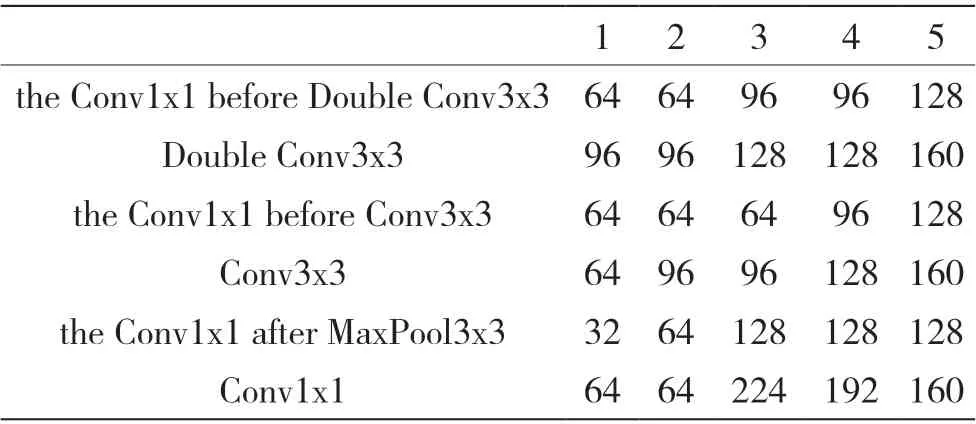
表1 Inception 模块各卷积操作的滤波器个数
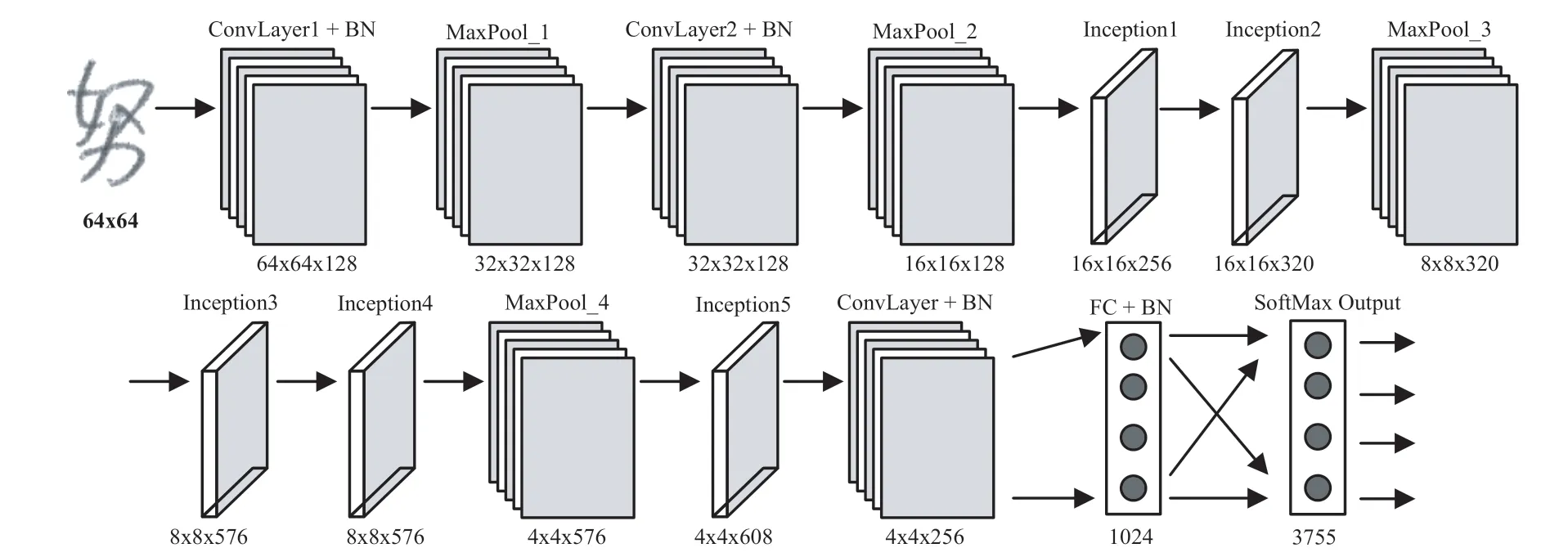
图2 HCCR-IncBN 手写体汉字识别模型
1.3 批量标准化层
批量标准化(Batch Normalization, BN)[17]方法用来解决神经网络在训练过程中出现的内部协变量转移问题(Internal Covariate Shift),由于在训练神经网络的过程中前一层参数一直更新,导致后一层输入不断变化。如果神经网络在每次迭代中都要重新学习不同的数据分布,网络就会很难收敛,深层网络的训练困难就在于此。针对此问题,在每一层的输出后面增加一个BN 层,将网络下一层的输入都标准化为均值为0、方差为1 的分布,从而可以达到固定数据分布、降低内部协变量转移的目的。对于神经网络的某一层,假设输入为d维的数据:x=(x1,…,xd),对每个维度进行归一化的公式为:

式中y(k)代表最终标准化后的数据,参数γ(k)和β(k)分别代表缩放参数和偏移参数,x^(k)是基于整个训练集的直接标准化结果,其计算细节如下:

在实际训练过程中,难以让每一个训练步骤都使用整个训练集,在神经网络的训练中优化损失函数一般都采用最小批次梯度下降法,对于BN 算法,只要每一个批次都取样于相同的分布,那么也可以使用一个批次数据的均值和方差来完成BN 标准化过程。考虑样本数为m的最小批次B:B={x1…m},整个BN 算法过程描述如下。
算法1 BN 算法
输入:最小批次的样本数据:B={x1…m}以及要被学习的参数γ,β输出:{yi=BNγ,β(xi)}
2 实验结果与分析
2.1 实验参数设置
本文使用TensorFlow 深度学习平台来实现HCCR-IncBN 模型,初始学习率设为0.001,按照指数衰减的方式更新学习率,使用Adam 梯度下降算法最小化损失函数,最小批次设置为128。为了避免过拟合,在全连接层后面使用了dropout 机制以及对权重参数添加了L2 范数约束,dropout 数值设置为0.6,权重衰减率设置为10-4,另外也使用了‘早停’机制来控制训练过程。实验的硬件条件为Intel(R) Xeon(R) Gold 6130、NVIDIA Tesla P100;操作系统为Ubuntu 16.04,系统内存为256G,基础配置为CUDA9.0,python3.7,TensorFlow1.14。
2.2 手写体汉字识别结果
实验使用包含3755 个类别的大规模数据集CASIA-HWDB1.1 来训练模型,该数据集由300 人书写,共有1 121 749 个样本。测试数据为数据集ICDAR2013,由60 人书写,共有224 419 个样本。输入图片大小为64x64,设置训练周期为6 个epoch(一个epoch 含有8 763 次迭代),训练时间仅为3个小时。
图3(a)和(b)显示了数据集HWDB1.1 训练过程中准确率和损失函数的变化,可以看出模型在训练迭代到3000 次左右时损失函数就降到了1.0以下,第20 000 次迭代后测试准确率普遍保持在95%以上,对数据集ICDAR2013 的最终识别准确率如表2 所示。
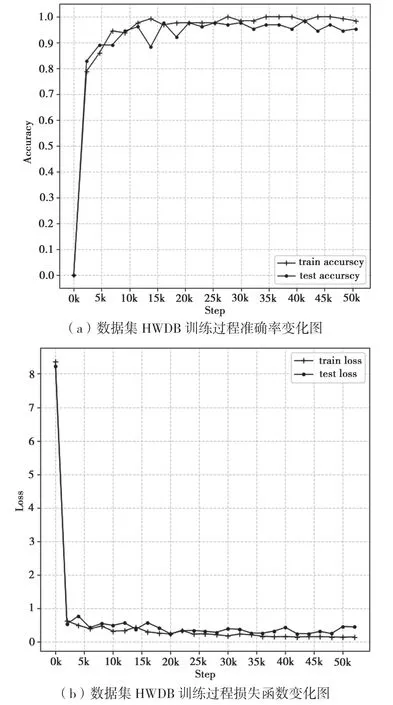
图3 数据集HWDB1.1 训练过程中准确率和损失函数变化

表2 ICDAR2013 数据集识别结果
表3 展示了基于ICDAR2013 数据集的不同识别方法的比较。可以看出,与表中的方法1、2 相比,HCCR-IncBN 模型在识别准确率和模型参数的数量方面都具有较大的优势。方法1 是2013 年ICDAR 手写体识别比赛的冠军,其输入表示很小,但是模型存储量高达2460MB。随着算法的改进和网络的优化,近几年一些成功的模型涉及的计算参数数量逐步降低。方法2 是ATR-CNN 的单一模型,其输入是1x48x48 的二值化图像,但是模型存储量约是我们的两倍。方法3 也是基于GoogLeNet,在识别准确率方面HCCR-IncBN 比其低了0.41%,但是在模型存储方面我们更优一些,具体来说,HCCR-Gabor-GoogLeNet 使 用 的 是Inception-v1 模 块且提取了原图像的Gabor 特征,其输入表示大小为9x120x120,而HCCR-IncBN 模型是基于Inception-v2模块,输入表示大小为1x64x64,且训练集只使用了HWDB1.1。方法4 致力于设计一个紧凑型的CNN 网络来提高手写体识别的效率,在模型存储方面具有很大的优越性,与之相比,HCCR-IncBN模型的输入表示较小,且方法4 的模型在训练过程中要不断的进行卷积层的低秩分解和修剪权重的操作,模型训练期间会耗费大量的时间和计算资源。

表3 各手写体汉字识别方法的比较
2.3 MNIST 数据集实验结果
为进一步评估模型的识别能力,使用MNIST数据集进行了手写体数字的识别实验。HCCRIncBN 模型输入设置为28x28,由于MNIST 数据集较小,为增强泛化能力,将dropout 数值修改为0.5。共训练了14040 次,在测试集上的识别准确率为99.37%。表4 展示了在MNIST 数据集上不同识别方法的比较,可以看出HCCR-IncBN 模型具有最高的识别准确率。

表4 不同识别模型的比较
3 结 语
本文设计了一个15 层的深度卷积神经网络模型HCCR-IncBN 用于汉字的手写体识别。该模型充分利用了Inception 模块稀疏连接的优点,保存整个模型仅需26MB 的存储空间,在获得较优识别准确率的同时能够较快的收敛(使用HWDB1.1 数据集训练模型仅需3 个小时)。HCCR-IncBN 模型在ICDAR2013 和MNIST 数据集上分别取得了95.94%和99.37%的识别准确率,优于当下大部分识别模型。在今后的工作中,我们会尝试设计更紧凑的CNN 模型来提高模型的识别效率,另外,将模型与手写体汉字的特定领域知识(如字符形状归一化、传统Gradient 特征与Gabor 特征提取等)相结合来进一步探索提高模型的识别准确率。
