基于BCDV 的视觉传感器算法
2020-06-08黄富嗣陈湘骥
黄富嗣,陈湘骥
(华南农业大学数学与信息学院,广州510642)
0 引言
物联网技术的成熟,使得视觉嵌入式设备应用场景越来越广泛。近年来,研究的热点之一是在嵌入式设备上进行边缘计算,并以物联网传输处理结果,减少服务器运载负载。如秦超等人[1]通过Google Face Comparison API 来实现人脸识别,实现了树莓派的人脸识别校园门禁管理系统。王敬仁等人[2]通过特征脸方法(Principal Component Analysis,PCA)来实现地铁分流系统。许龙铭等人[3]通过Haar Cascade 特征检测算法库中的相关函数,应用到OpenMV 嵌入式视觉芯片来实现商店中对人员人脸的检测来统计客流量。严正国等人[4]通过运用OpenCV 中的FaceRecongnizer 类实现人脸识别,设计出人脸考勤系统。此类算法通过正面人脸识别作为依据,缺少对侧面或背面的人头解析,应用方面缺少对人员流动的运动趋势和姿态分析。蔡征等人[5]在关联匹配中设计出代价函数,并基于运动特性设计出补偿算法,有效解决了重合、消失等对多目标追踪出现的问题。袁海娣等人[6]利用背景差分算法提取候选框区域,再通过识别安全帽的颜色和其他特征来分割、提取目标,并完成形态学处理。最后以匹配区域质心的方法实现对人员的实时跟踪与人员计数,实现了井下人数统计的视觉分析。这类算法对人数进行了追踪和统计,但缺少对人员姿态的信息解析,姿态信息有助于分析井下工作人员是否安危。
近几年,深度学习算法成为热点,深度学习在图像和视觉领域取得很好的效果,例如涂鑫等人[7]改进CNN卷积网络设计出课堂人脸打卡算法。盛恒[8]使用Faster R-CNN 对场景内的人员进行头部检测输出模型的检测成果,再根据IoU 算法滤去重复检测的目标,实现了实验室人数统计与管理系统。游忍等人[9]通过TINY-YOLO 算法用于识别人脸,结合了NCNN 框架,设计出实验室人数统计管理系统。这类算法识别率高,但是需求的资源过大,需要昂贵的设备才能满足算法的资源需求,一般的嵌入式设备无法提高到应用需要的帧数。
本文算法融合了背景差分和三帧差算法,通过计算分块质心位移方差(Block Centroid Displacement Variance,BCDV),实现了固定场景下的多移动物体识别,输出目标的位置、运动或挥手等姿态信息。
1 基于BCDV的视觉传感器算法
固定监控场景如校园实验室监控、井下平台人员安全监控,需要远距离传输并人工提取监控信息、或是提供人数信息。本文算法运行在嵌入式设备上,将视频信息处理成动态数据,包括人数、人物运动趋势和姿态分析等信息,方便后台服务器进一步作分析。
算法首先对原图进行背景差分和三帧差算法处理,获得的二值图做分块置信度计算和图像融合。将图像特征聚类处理获得ROI 区域并计算区域的质心,通过当前质心与匹配的历史质心的计算得出ROI 区域的运动趋势。以质心为中心点将ROI 区域分成八个区域,通过区域质心与质心的计算与分析得出姿态信息。完整流程图如图1 所示。
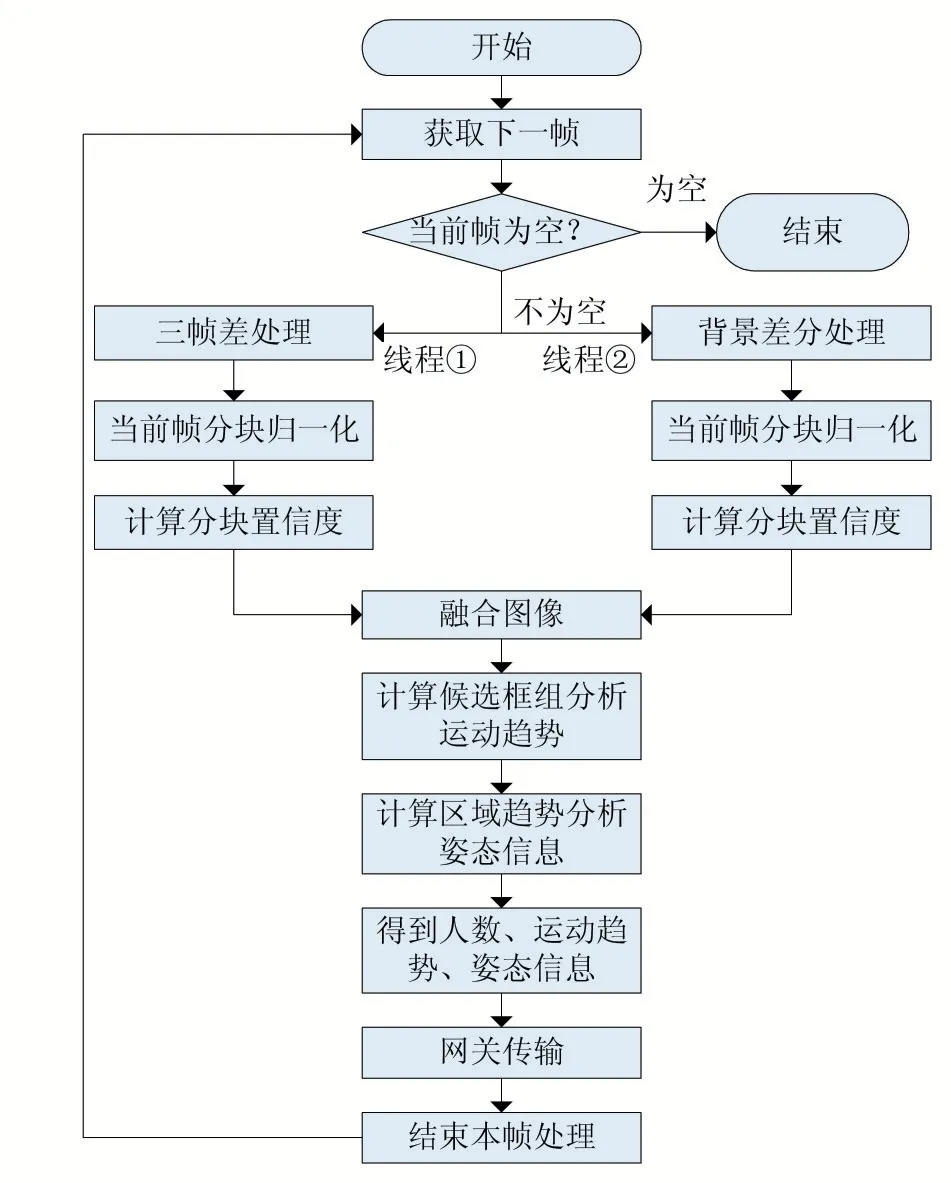
图1 算法流程图
1.1 分块计算块置信度
首先需要获取图像中感兴趣的区域,采用背景差帧处理原图获得有特征的二值图,并通过轻微的腐蚀膨胀来消除背景差分产生的噪点。接着把该图像网格化成n×n 个大小的块,n 为像素单位。通过USCD 数据集(UCSD Pedestrian Database)测试,当n 设置为8 效果较好,即网格化成8×8 个大小的块。接着遍历整个图像,对每一个块分别计算块置信度,块置信度公式如公式(1)所示。

其中A 为当前块归一化的分数,B 为相邻块的分数,C 为上一帧该块的Score,α、β、γ为归一化权重,经过UCSD 数据集的数个视频的测试,当α为0.4,β为0.4,γ为0.2 效果较好。
对每个块中的白色像素数与白色像素数最多的块做归一化,得到当前块的分数A 如公式(2)所示。

其中x 为当前白色像素数,xmax为块集合中块中最多白色像素数,xmin为块集合中块中最少白色像素数,最少白色像素数基本为零,x*为归一化结果。
把每个块邻边的八个块的当前分数累加并取平均获得B,算出该块的邻边分数。算出每个块的置信度后,设立一个阈值threshold_connect 为0.2,排除置信度较低的块。
1.2 计算联结块矩形质心并分析人物运动趋势
对有效目标块采用DFS 深度搜索算法把符合threshold_connect 并相邻的块连结起来,组成一个ROI区域,对该矩形区域的白色像素数聚类算质心,如公式(3-4)所示。

其中xc,yc为质心横纵坐标,xi,yi为当前白色像素横纵坐标,m 为矩形区域中白色像素总数。
算出质心后,质心匹配前一帧质心组中最短距离的质心,这里设置一个阈值threshold_centroid=50,不存在该阈值范围内的质心时,则迭代往再前一帧的质心组搜寻匹配质心,匹配后,通过两者之差获取该矩形ROI 区域的运动方向和速度,并用箭头标出运动方向,如图2 所示。
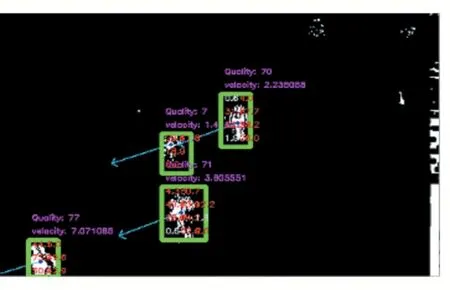
图2 运动趋势
得到人物整体运动趋势后,再将ROI 区域以目标质心为中心分割成八块矩形区域,如图3 所示。

图3 ROI矩形分区
C 为目标质心,以C 的横坐标分成两个区域,两个区域再单独平分两个区域,以C 的纵坐标分割该矩形的四个区域,得到八块矩形区域。分别计算出目标落入每个区域的区域质心,并用公式(3-4)算出每个区域的区域质心,将质心与区域质心分别与矩形长度做归一化,并通过以下公式计算方差。

xic主为前i 帧的质心基于ROI 矩形归一化后的值,xic区为前i 帧的区域质心基于ROI 矩形归一化后的值,m 为前n 帧质心组储存帧数。对质心的xc主和区域质心的xc分进行归一化并相减,得到区域质心相对于质心位移的差,通过公式(5)得到方差S2。设立一个阈值threshold_hand 为5,当图3 中块1 或2 的S2值超过threshold_hand,下面5、6、7、8 块的值均没 有超过threshold_hand,判定为招手姿态如图4 所示。

图4 挥手识别
2 实验效果及分析
测试系统是PC,CPU 为Intel i7 4720Q,系统是Ubuntu 16.04,算法编程语言是C++,采用的视觉库是OpenCV 3.1.0,测试用数据集是UCSD Pedestrian Database 灰度数据集,分辨率为476×316。
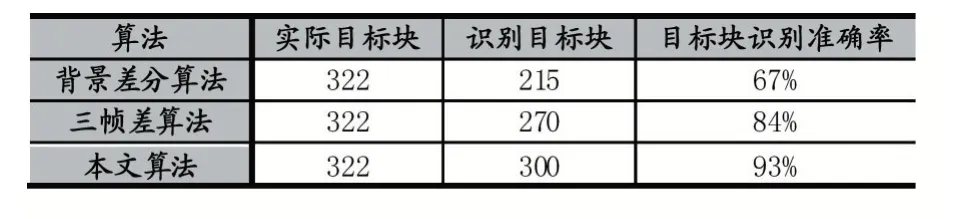
表1 三种算法的实验结果对比
实验中共选用100 帧作为测试数据样本。实验结果表明,背景差分目标块识别率为67%,三帧差识别率为84%,本文算法识别率为93%。实验结果表明,本文算法提高效果较好,提高了9%。

表2 本文算法与OpenPose 算法对比
共选用70 帧作为测试数据样本。深度学习Open-Pose 算法识别率91%,帧率有1.7 每秒。本文算法识别率88%,帧率有55 帧每秒。在识别率相比较低的情况下,帧数明显高于OpenPose 算法。

表3 本文算法挥手识别测试
在自制数据集测试中,两人共挥手23 次,识别护手22 次,通过回放研究发现,一次挥手未识别是挥手方向面向测试镜头垂直挥手导致未识别。
另外,本文算法还在树莓派4 代上测试,2GB 内存配置,在分辨率320×180 中运行达到21 帧。
3 结语
本文采用BCDV 算法,提取视频中移动物体运动趋势以及人物挥手等姿态信息,在树莓派等嵌入设备上也能获得较高的帧数。目前已应用于团队实验室智能监控,在智能监控管理场景有一定应用前景。
