基于神经网络的强化学习在服务机器人导航中的研究
2020-06-08陈双李龙罗海南
陈双,李龙,罗海南
(芜湖哈特机器人产业技术研究院有限公司,芜湖241000)
0 引言
随着科技的进步和人们对生活水平的追求,服务机器人[1-2]作为机器人家庭中的新生一员应运而生,在医疗救助、家庭服务、娱乐项目等领域中发挥着重要作用。而自主导航[3]是服务机器人最基本、最重要的能力,也是其他应用的基础;但由于服务机器人应用环境的非结构化和复杂多样化,给其导航能力提出了更高的要求。近年来,随着智能科学的兴起和发展,如何在服务机器人与环境的交互中通过自主学习提高自身的智能水平,使其更好的适应复杂环境己经成为机器人学中研究的热点问题。而强化学习[4-5]无需数学模型和先验知识,只需通过与环境的交互试错便能够得到相应优化控制策略,因此可应用在服务机器人的导航控制中。
1 强化学习算法
1.1 强化学习的基本原理
强化学习[6-8]的思想来源于动物的学习理论,主要解决的问题是:一个能够感知环境的智能体(Agent),如何通过学习选择能力执行能够完成设定目标的最优动作。该算法把学习看做是一个试探的过程,把外界环境状态映射成相应的动作,Agent 通过不断与外界环境交互试错后获得相应的奖惩,在不断学习的过程中,逐步逼近能够获得最大奖赏值的动作策略。在强化学习中,由环境产生的奖赏信号(奖励或惩罚)是对Agent当前动作的评价,它无需告诉Agent 如何产生最优的动作,只需Agent 不断的改变从状态空间到动作空间的映射策略使自身获取正的奖赏值最大即可完成目标任务。图1 为强化学习的原理示意图,Agent 根据当前环境的状态执行一个动作后,外界环境发生改变的同时给予该动作相应的奖赏信号并传递给Agent 本身,然后不断修正动作策略使Agent 得到的奖赏信号最大,从而进行下一步的动作,如此循环,直到Agent 该环境下一直执行最好的动作为止。

图1 强化学习的原理示意图
强化学习包含很多种算法,例如蒙特卡罗算法、动态规划算法、瞬时差分算法、R 算法和Q 学习等,其中,Q 学习是一种与环境模型无关的强化学习算法,因其不需要建立精确的数学模型而被广泛的应用在机器人控制系统中。
1.2 Q学习
Q 学习[9]提供智能系统在马尔科夫环境下利用经历的动作序列选择最优动作的一种学习能力。在Q 学习中,Q(s,a)是状态动作对的值函数,通过不断循环减小相邻状态间Q 估计值的差异来达到一定的收敛条件,即:
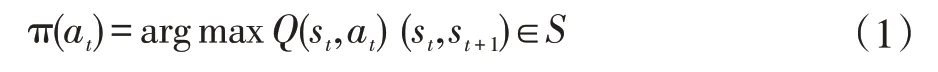
其中,(st,st+1)∈S,S 为状态集;(at,at+1)∈A,A 为动作集;R(st,at)表示在状态st下执行动作at得到的奖赏值;γ为折扣因子;T(st,at,st+1)表示从状态st通过执行动作at后转到状态st+1的概率。通过输出的Q 值得到给定状态所对应的可能动作,从而Agent 选择并执行最大Q值所对应的动作。选择的策略为:

通过式(3)完成Q 值的更新,直至收敛:
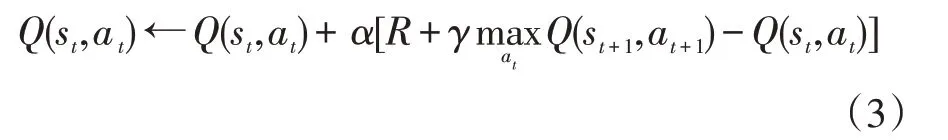
式中α为学习率。
Q 函数的实现方法[10]主要有两种:一种是采用神经网络的方法,另一种是采用lookup 表格方法,即通过lookup 查表法描述离散空间中状态动作对的值函数,表的大小等于S(状态集合)×A(动作集合)的笛卡尔乘积中元素的个数。但当外界状态集合S 或Agent 的动作集合A 较大时,lookup 表将占用较大的内存空间,从而造成Q 学习的收敛速度过慢甚至产生“维数爆炸”等问题;若Agent 规划的是非离散场景的路径时,采用查表法存储Q 值的方法也不具有泛化能力,因此本文将采用神经网络来实现Q 学习算法。
1.3 基于BP神经网络实现Q学习算法
神经网络具有较强的泛化能力,能够逼近任意非线性函数,因此神经网络可以解决Q 学习中大规模的状态空间到动作空间之间的映射关系问题,图2 显示了BP 网络拟合Q 学习算法的结构图。
图2 中可以看出,网络的输入是传感器所检测的当前环境信息量化后的结果st={s1,s2,…,sn},假设服务机器人具有m 个可能的动作ak(k=1,2,…,m),网络的输出是设定动作对应的Q 值(Q(st,ak)),即:

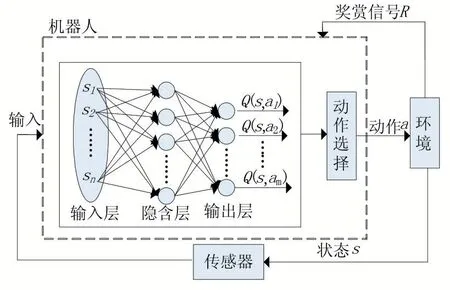
图2 BP网络拟合Q学习算法的结构图
采用较常用的ε-Greedy 探索策略来解决探索与利用之间的平衡关系,即服务机器人以ε的概率随机选择某一动作,以1-ε的概率按式(2)选择最大Q 值对应的动作。当机器人执行完该动作后,将当前的状态st+1输入到网络中,得到下一动作对应的Q 值(Q(st+1,at+1)),同时网络给予该动作相应的奖赏值r(st,at),此时得到输出误差e 为:
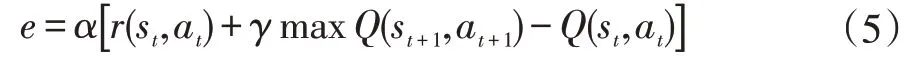
在得到网络的输出误差后,利用式(5)修正调整BP 网络的各个权值大小,当误差满足设定的条件后机器人进行下一步动作,重复上述步骤直至学习结束,即服务机器人已到达目标点完成导航任务。该算法的流程图如图3 所示。

图3 BP网络拟合Q学习算法的导航流程图
2 实验与仿真
2.1 服务机器人感知系统模型及环境模型的建立
在MATLAB 环境下模拟仿真较为常见的两轮差动式服务机器人,通过控制其质心处的转角使车体完成前行、左转及右转的动作,服务机器人感知系统的模型结构如图4 所示。首先,车体的右方、前方和左方均安装了三个超声波传感器,从而能够检测车身右方30°、前方30°及左方30°的环境信息。为了确保机器人在完成导航任务时自身的安全性,取sright、sfront和sleft分别表示机器人与车体右方、前方及左方障碍物之间的最短距离,即 sright=min(l1,l2,l3)、sfront=min(l4,l5,l6)、sleft=min(l7,l8,l9),同时需要测量机器人与目标点间的距离(sgoal)以及当前车身方向与目标点之间的夹角(sangle),计算公式如下:

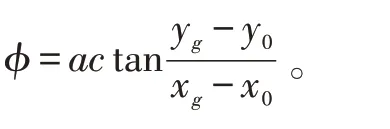
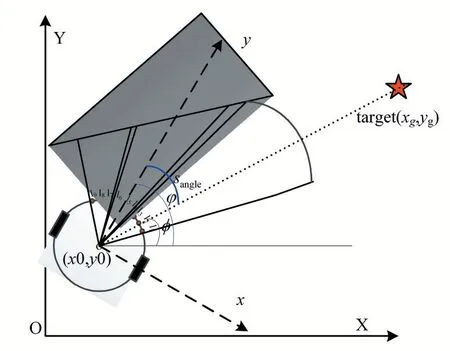
图4 机器人感知系统模型
在MATLAB 中建立了100×100 单位距离的仿真界面,假设每个超声波传感器的检测范围为0~5 个单位,当机器人周围无障碍物或机器人与障碍物之间的距离大于5 个单位时,传感器的示数显示为5。在MATLAB 图形用户界面中仿真模拟外界环境,图5(a)中显示了所建的GUI 仿真界面,将外界环境信息存储在mat 文件中,通过导入障碍物按钮完成对设定外界环境的加载;在设置起点按钮和终点按钮中,可使用鼠标点击确认的方式获得起点及终点的位置;清除路线按钮的作用是清除机器人的路径轨迹;保存仿真图形菜单可实现对仿真结果的存储。
在路桥工程施工过程中,水泥结构设计对混凝土强度要求比较低,一般情况下使用低强度的混凝土,此外还应结合环境因素对混凝土结构实施全面的设计,能够有效避免对外部产生影响,而且在较大程度上可提升混凝土设计质量。在对混凝土结构进行设计的过程中,最为重要的是避免裂缝的产生,这就需要施工企业在施工过程中不断创新和优化施工工艺,在最大程度上保证乃至提高工程质量。
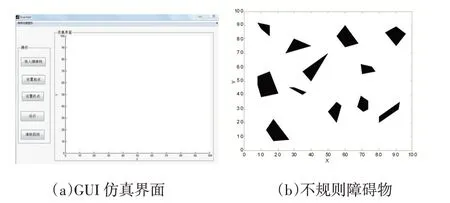
图5 仿真环境
2.2 输入输出参数的量化
在马尔科夫环境下,Q 学习的输入和输出均是离散的变量,因此需要对从外界系统中获取的输入输出数据进行量化处理。本文采用了由Michie 提出的BOX 算法,其基本思想是将输入状态空间划分为确定数量的非重叠区域,不同的输入状态激活不同的区域。本文在综合考虑传感器所测距离的范围后,将网络的输入量划分为9 个区域,不同的区域代表机器人面临不同的环境信息。量化后的结果为:
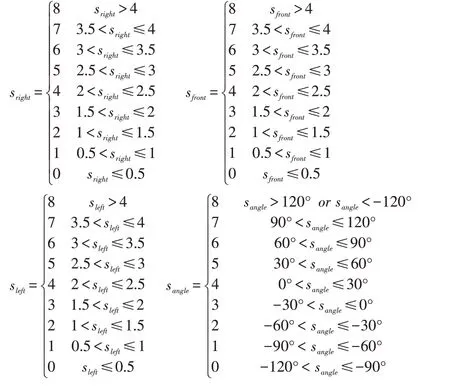
为了使服务机器人运行的路径较平滑,把服务机器人的执行动作分为左转30°、左转15°、直行、右转30°、右转15°这5 个动作,网络的输出变量即为该5 个动作对应的Q 值。
2.3 奖赏信号的设定
奖赏信号是Q 学习的主要元素之一,合理的设定奖赏信号有利于提高网络的收敛速度。服务机器人导航的主要目的是使车体完成接近目标和远离障碍物两种行为:机器人接近目标应给予奖励,即正奖赏值,远离目标应受到惩罚,即负奖赏值;同样,机器人越接近障碍物,受到的惩罚就越大,越远离障碍物,获取的奖励就越多。本文将奖赏信号分为三部分:第一部分为障距奖赏值Rod,即根据服务机器人相对于障碍物的距离设置的奖赏值;第二部分为方向奖赏值Rdo,即根据服务机器人车体方向相对于目标点的夹角(简称,目标方向夹角)设置的奖赏值,第三部分为目距奖赏值Rgd,即根据服务机器人相对目标点的距离设置的奖赏值;三部分奖赏值的取值分别为:

当服务机器人与障碍物之间的距离不同时,机器人需要考虑选择执行两种行为(逼近目标与躲避障碍物)的优先权。在未检测到障碍物时,即sright=sfront=sleft=5,应优先逼近目标点,此时车体每步改变5°从而逐渐减小目标方向夹角并接近目标。当检测到障碍物时,本文根据经验知识,以安全距离为分界点,引入障距动态权值以及目距动态权值,两个权值取值的大小决定了执行逼近目标和躲避障碍物两个行为的优先权,按如下规则设置动态奖赏值:
(1)当服务机器人与障碍物之间的距离小于设定的安全距离时,应给予机器人一定的惩罚(Rpu),设置Rpu=-5;同时,在该状态下,机器人主要以躲避障碍物为主,因此,设置障距动态权值Wod=0.9、目距动态权值Wgd=0.1。
(2)当服务机器人与障碍物之间的距离大于等于所设的安全距离时,机器人主要以接近目标点为主,在该状态下,主要考虑机器人与目标点之间的距离及目标方向夹角,因此,设置Wod=0.1、Wgd=0.9。

式中,Wdo为目标方向动态权值,其值Wdo=1-[Wod]。
2.4 不同环境下的仿真结果
在仿真实验中,假定最初服务机器人的车体前进方向朝向目标点,设定网络的最大学习次数为2000次,机器人每完成一个动作后便调整一次网络的权值,当机器人的学习次数超过最大学习次数或碰到障碍物时,则返回至最初设定的起点位置开始新一轮的训练。服务机器人行驶的速度取决于车体与周围障碍物之间的距离,当周围无障碍物时,机器人具有最大的行驶速度;当检测到障碍物时,机器人会降低行驶速度。机器人行驶速度v 的计算公式为:

式中,smin=min(sright,sfront,sleft);ζ 为速度比例系数。
在学习的初始阶段,Q 值是随机设定的,为了探索到所有的动作,采用ε-Greedy 探索策略选取动作,以1-ε的概率选择最大Q 值对应的动作,以ε的概率随机选择任一动作,随着学习的不断进行,逐渐降低ε的大小。网络中各个参数的设定值如表1 所示。

表1 网络参数的设定值
服务机器人采用BP 网络拟合Q 学习的算法应用于静态环境下的导航系统中,仿真的结果如图6 所示。
在仿真实验中,当周围无障碍物时,机器人以最大的速度行驶并靠近目标点,当遇到障碍物时,将采取避障措施。从图6(a)可以看出,在学习的初始阶段,服务机器人主要以探索环境为主,此时选择随机动作的概率较大,因此机器人无法正确的选择并执行最佳的动作,导致行驶的路线比较乱,而且出现了与障碍物相撞的现象。从图6(b)可以看出,在训练中期,随着与环境交互的不断进行,服务机器人随机选取动作的概率在逐渐减小,并慢慢学会了如何避开障碍物并趋向目标点,但是,机器人在此时并没有完全熟悉环境,因此规划的路径并不是最优路径。从图6(c)中可以看出,在训练的后期,机器人经过了大量的实验与学习,对环境完全掌握的情况下,走出了一条相对较优的路线,并顺利到达目标点。最后,服务机器人利用所提的算法在上述环境下完成100 次的导航路径,输出每次行使路径所耗时间及步数,设定当机器人与障碍物相撞时,机器人的输出步数为0,结果如图7 和图8 所示。
从图7、图8 可以看出,由于BP 网络的初始权值是随机设定的,在训练初始阶段,网络极易陷入极小值问题,致使机器人消耗较长时间到达目标点,甚至出现碰撞障碍物次数较多的现象,随着学习的进行,逐渐适应所在的环境,最后花费了较少的时间走出相对较优的路线。
3 结语
服务机器人在家庭服务、医疗服务、娱乐项目等方面发挥着重要的地位和作用,在服务机器人发展的同时,对其智能化程度的要求也越来越高,因此通过自主学习来提高智能水平是未来服务机器人走进千家万户必须深入研究的问题。学习是智能产生的基本条件,基于强化学习的导航方法将会在机器人系统的设计中发挥重要的作用,本文提出了基于神经网络的强化学习算法,并应用在机器人的导航控制中,该算法充分考虑机器人所需完成的避障和趋向目标的任务,在MATLAB 仿真环境下验证了该算法的可行性。
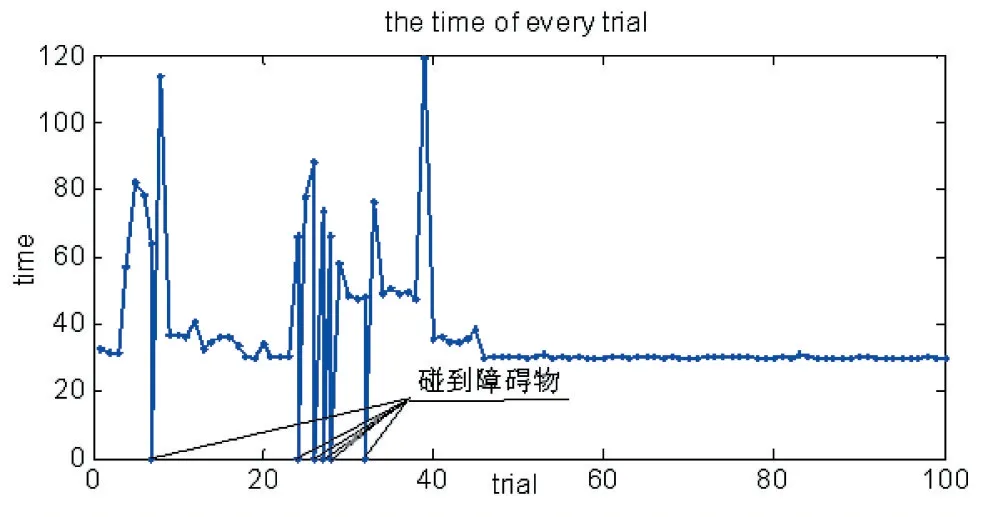
图8 时间
