个性化推荐算法在农产品电商中的应用研究进展
2020-06-08孟秋晴童兆莉丁红发
孟秋晴,童兆莉,丁红发
(1.华中师范大学信息管理学院,武汉403792;2.贵州财经大学信息学院,贵阳550025;3.湖北交通职业技术学院图书馆,武汉430079)
0 引言
农产品电商继图书、服装、3C 三大电商热潮后,成为第四轮电商热潮,标志着我国农产品互联网化进入高速成长阶段[1]。农产品的季节地域性、易腐性、数量大等特殊性质对农产品交易要求苛刻,让传统的线下交易面临巨大的阻力,而农产品电商的发展则让农产品交易焕发了新的活力。如今各种农产品网站层出不穷,大规模的农产品信息给人们的购物带来了便利,与此同时,也增加了用户的信息负载。个性化推荐技术主要依据用户的历史行为数据,挖掘出用户感兴趣的内容,并自动推送给用户,减少了用户的人工搜索量,提高检索效率。将个性化推荐算法[2]应用到农产品电商领域,能够挖掘用户兴趣,使用户快速找到符合自己需求的农产品信息,降低了购物的盲目性,促进农产品的销售,对农村电商的发展有着重要意义。
目前,个性化推荐算法虽然已经应用到农产品电商中,但相关研究才刚刚起步,并不成熟。农产品电商中推荐算法的分类、模型、适用场景等都没有系统的研究成果,无法较好地支持推荐算法在农产品电商中的应用研究。基于此现状,本文对个性化推荐算法在农产品电商中的应用研究进行了梳理和总结,分类阐述了个性化推荐算法的模型、特征和应用优势,分析了推荐算法在农产品电商中的应用研究及其评价指标,并进一步梳理分析了面向农产品的推荐算法应用所存在的问题,提出了进一步的研究方向,以期为个性化推荐算法在农产品电商的深入应用和普及提供有力支持。
1 个性化推荐算法
20 世纪90 年代中期,在美国人工智能协会上,“Web Watcher”和“LIRA”两个个性化推荐系统[3]的出现标志着个性化推荐技术的研究正式开始。Resnick 等人[4]在1997 年针对个性化推荐系统首次给出了定义,认为完整的推存系统具体包括三个构成要素,即用户模型、产品模型以及推荐算法。其中,用户模型主要是用于储存用户的历史行为信息,信息获取方式一般分为显示获取和隐式获取两种。显式获取采用用户的评分来衡量用户对产品的偏好程度,隐式获取是通过用户的网页浏览信息,购买日志等隐式信息获取用户的偏好。产品模型主要用于表示产品的特征信息。个性化推荐系统流程如图1 所示,包括数据输入、个性化推荐算法和生成推荐列表三个步骤[5]。其中,个性化推荐算法是推荐系统的核心环节,主要通过对用户历史行为数据进行挖掘,揭示用户的消费习惯以及兴趣偏好,从而进行个性化推荐。

图1 个性化推荐系统流程
目前,个性化推荐已广泛应用于电子商务、广告服务以及社交媒体等领域当中。其中,以在电商中的应用最为成熟,如在亚马逊、eBay、淘宝网、当当网等电商网站中,个性化推荐技术的使用已经产生了巨大的商业价值。尽管不同的应用领域使用到了不同的推荐算法,从推荐策略的角度,可将推荐算法分为协同过滤推荐、基于内容的推荐、基于知识的推荐以及混合推荐等不同的推荐方案[6]。
1.1 协同过滤推荐
协同过滤的概念最先由Goldberg 等人在1992 年提出[7],最初应用于过滤电子邮件,目前在推荐领域中应用最为广泛。协同过滤算法由三个步骤组成:第一步,获取“用户-项目”评分矩阵;第二步,通过相似度计算得到目标用户的最近邻用户集合或目标项目的最近邻项目集合;最后,通过上一个步骤得到的最近邻集合,计算目标用户对目标项目的预测评分,根据评分生成最终推荐结果,如图2 所示。协同过滤算法主要分为基于用户的协同过滤推荐、基于项目的协同过滤推荐、基于模型的协同过滤推荐三种。

图2 协同过滤推荐算法流程
基于用户的协同过滤要找出与当前用户过去有相似偏好的其他用户群体,将该用户群体感兴趣且当前用户没有见过的内容推荐给当前用户;基于项目的协同过滤推荐是要找出跟当前用户感兴趣的项目相似度较高的项目,把这些项目作为推荐。基于模型的协同过滤推荐则是基于各种机器学习的方法离线建立模型,然后根据用户兴趣模型,计算用户对产品的预测评分,从而进行推荐。相似度的计算主要的方法有Pearson 相似度计算,修正的余弦相似度计算、欧几里得距离法等[8]。
利用协同过滤算法,可以借助用户评分矩阵R,计算得到用户a 和用户b 的相似度sim(a,b),可利用Pearson 相似度计算得出,如公式(1)所示:
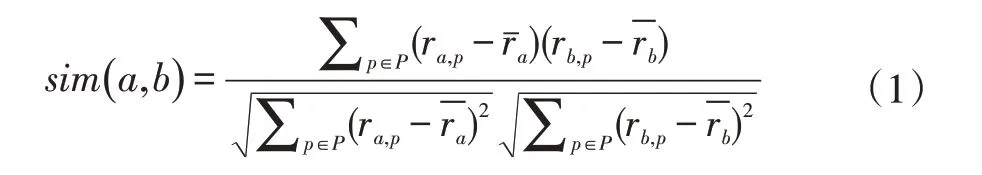
其中,P 代表产品集,ri,j表示评分矩阵R 中的评分项,表示用户i 的平均评分。目标用户a 对目标产品p 的预测评分pred(a,p)可由公式(2)得到:

其中,N 为目标用户a 的最相似的用户集。该预测评分是基于目标用户a 的最相似的N 个近邻用户得到的。计算出目标用户a 对所有目标产品的预测评分,最后将预测评分排序后生成最终的推荐列表。
协同过滤算法最显著的问题是其计算复杂度会随着用户和商品规模的增加而急速增加。近年来,深度学习[9]因为在大规模数据处理方面具有突出表现,目前被广泛应用于协同过滤推荐领域当中[10,11],采用深度学习方法通过学习用户或项目的隐向量,基于隐向量预测用户对项目的评分或偏好,成为协同过滤算法的一大研究热点。
1.2 基于内容的推荐
协同过滤算法主要以“用户-项目”评分矩阵作为用户兴趣偏好,但没有考虑到诸如用户的年龄、职业、社会地位等用户特征信息,以及项目的类别、生产时间、价格等项目特征信息。基于内容的推荐需要依赖对用户或项目的特征描述,在这里把对用户或项目的特征描述称为“内容”。基于内容的推荐能够自动从项目的文本描述中抽取特征关键词,生成与项目内容相关的特征描述,根据特征描述对当前用户过去感兴趣的项目和还没有看到的项目之间的相似度做出评估,借助相似度计算得出最近邻集合,从而生成推荐列表。
在文本信息推荐中,基于内容的推荐算法应用较多。其中,最常使用到的特征描述方式有空间向量模型和TF-IDF 技术[12],即词频和反文档频率。通过TFIDF 值表征向量模型中的特征值。词频是表示一个词在一篇文档中出现的频繁程度,文档j 中关键词i 的归一化词频值TF(i,j)可由公式(3)得到:
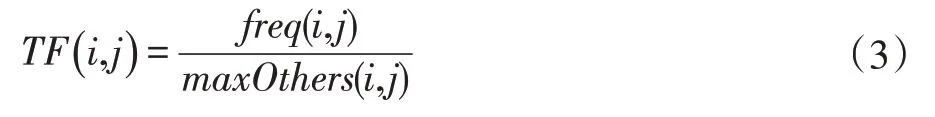
其中,freq(i,j)表示i 在j 中出现的绝对频率,maxOthers(i,j)为最大频率。关键词i 的反文档频率IDF(i)可由公式(4)得到:

其中,N 为所有可推荐文档的数量,n(i)表示的是N 中关键词i 出现过文档的数量。反文档频率的设定是为了降低在所有文档中都会出现的关键词的权重,增大出现在较少文档中的关键词的权重。
文档j 中关键词i 的组合TF-IDF 值可表示为:

目前,基于内容的推荐多应用于社会化推荐[13]领域,即立足于传统推荐算法,将用户或是项目所具备的社会化属性信息(如标签信息和信任关系等)当成关键影响因素,并融入推荐算法里,从而达到提高推荐系统性能与精度的目的[14]。
1.3 基于知识的推荐
基于知识的推荐算法与其他推荐算法存在的最大差异在于,其需要利用特定领域当中的专业知识以及规则约束。基于知识的推荐算法不需要考虑用户评分以及兴趣偏好等因素,因此不会出现数据稀疏性以及冷启动等问题。该算法通常依赖用户的特定需求,或者明确给定的推荐规则。其可以看作是语义推理技术的一种形式,在实际应用中依据知识架构体系实现个性化推荐,因此一般需要针对特定领域建立专业知识库。
目前,基于知识的推荐方法的研究热点是基于本体[15]理论构建模型的方法。
1.4 推荐算法的常见问题
个性化推荐算法存在的问题主要包括用户评分矩阵的稀疏性、可扩展性以及冷启动等[16]。用户评分矩阵的稀疏性问题主要是因为用户对物品进行的评分会存在大量的数据缺失,所以用户评分矩阵是一个稀疏矩阵。冷启动问题指的是当新用户刚进入系统时,由于还没有任何购买行为,因此缺乏相应的评分数据。可扩展性是指随着数据量及数据结构的扩展,构造适应的训练模型的能力。
1.5 混合推荐
每一种个性化推荐算法都会存在自身独有的优点和缺点,以上几种形式的推荐算法对比如表1 所示,因此在解决实际问题的时候,多会采用多种推荐算法相互融合的方式以达到更好的推荐效果,也即是混合推荐算法。混合推荐方案通常有三种:整体混合、并行混合以及流水线混合。其中,整体混合是把多种推荐策略纳入到一个算法中的混合设计方案,这种算法设计是通过对算法进行内部组合调整,从而能够利用不同类型的输入数据进行推荐;并行混合是指同时用到几个推荐算法的结果,利用加权或其他特殊的混合机制将他们的输出结果整合起来做出最后的推荐;流水线混合具体是把推荐过程划分成多个阶段,多种技术顺序作用,上一个阶段推荐算法的输出作为下一个阶段推荐算法的输入,直到产生最后的推荐结果。

表1 主流推荐算法对比
2 面向农产品的推荐算法应用
面向农产品的推荐主要是在传统推荐算法的基础上,结合农产品电商的特征来进行推荐算法的选择和优化设计。以下从协同过滤、基于内容的推荐、基于知识的推荐和其他推荐四个角度详细介绍面向农产品的推荐算法应用。
2.1 面向农产品的协同过滤推荐
目前,国内外基于农产品的推荐算法应用最广泛的是协同过滤算法以及对其的改进算法。李宁[17]、郑云飞等人[18]都选取基于项目的协同过滤推荐算法设计并实现了农产品推荐系统。于金明[16]通过分析农产品和其他产品的特征差别,通过ICP-IPSS 方法改进了项目间的相似性度量,设计了基于项目谱聚类的优化协同过滤推荐算法。李圣秋[19]提出了农产品商城系统中的整体式混合推荐模式。其中,针对用户在不同时期做出的评分进行不同的权重设置,设计了一个引入时间因子的协同过滤算法,这种算法优化了传统算法没有考虑特征的问题,降低了推荐算法的平均绝对误差。郭安邦[20]使用Item CF-Time Grade 协同过滤推荐算法构建了Grecs 农产品电商系统,该算法在基于项目的协同过滤算法基础上增加了时间和评分因子两个影响因素,该算法生成的基于物品相似度的推荐结果具有更快的物品更新速度,取得了较好的用户反馈。裘进[21]同样将原有计算物品间相似度的余弦相似度公式加入时间、用户评分等内容,从而调整预测权重值得到较好的推荐结果。
在面向农产品的协同过滤推荐中,大部分研究是对协同过滤算法中相似度计算的部分进行改进,根据农产品具有的特性,针对评分矩阵的稀疏性等问题优化协同过滤推荐算法。但现有算法中并没有采用深度学习等目前协同过滤算法中的最新研究成果,使得在农产品及其用户规模异常庞大的电商环境下,推荐效果并不理想。
2.2 面向农产品的基于内容的推荐
管庆超[22]进行了农产品电商推荐系统的设计与实现。其根据线上农产品交易的特点,构建了基于农产品属性和类别的农产品推荐模型,该模型对农产品属性相似度的计算使用了一种融合信息熵的加权Jaccard系数[23]的相似度改进算法,对农产品类别的相似性计算引入了用户偏好度因子,将计算的结果作为权值来调整最后的计算结果,由此能够有效解决数据稀疏方面的问题。彭洁[24]提出一种基于潜在类回归模型(LCRM)的农产品推荐方案,从用户评价的角度,通过LCRM 将具有相同兴趣爱好的用户划分为一个组群,构建组群偏好,再通过与目标用户的相似度计算来定位组群和定位农产品,实现较为准确的农产品推荐,并且具有较低的计算复杂度。
面向农产品的基于内容的推荐中,需要进行文本分析,以及对推荐对象的特征描述等工作。目前,该方面研究成果较少,主要研究着重于特征相似度计算的改进,对农产品的特征描述、特征表示、特征存储等并没有形成成熟的方法与思路。
2.3 面向农产品的基于知识的推荐
魏同[25]设计并实现了大别山农产品电商语义推荐系统。其工作以大别山茶叶产品作为研究对象,通过构建茶叶领域本体,并挖掘用户兴趣,经过本体投影算法形成用户兴趣本体,完成基于茶叶领域本体的用户建模,并基于语义相似度和相关度进行语义推荐。秦志远[26]根据农产品目录信息以及农业物联网感知信息分别构建了农产品上层本体和下层本体,然后依据消费者信息建立消费者兴趣本体,并将消费者兴趣本体和农产品上层本体进行概念语义相似度计算,进而实现个性化推荐。郭安邦[20]设计和构建了基于本体的Greenhouse-Expert 农产品专家系统。通过分析基于本体的专家系统设计方法,并结合农产品的类别特征,提出了Greenhouse-Expert 推荐算法,该算法能够较好地解决推荐系统的冷启动问题,提供更为专业、精准的推荐结果。
当前基于知识的农产品推荐的研究热点是基于本体理论构建模型的方法。基于本体的推荐一方面需要对本体所在的领域和范围进行确定,然后在此基础上构建领域内的物品本体和用户兴趣本体,对其进行相似度计算从而生成推荐。基于知识的农产品推荐研究目前相对较少,主要是目前对基于本体的研究还存在一些问题,如还没有形成统一的构建本体模型的标准;领域本体构建过程中需要一定的领域知识,并且不能实现本体的自动构建,需要大量的人工干预等。
2.4 面向农产品的其他推荐应用
除了上述应用,丁昭巧[27]通过分析农产品购买者偏好,设计了多Agent 策略下的农业电商个性化推荐整体和各部分架构,采用协作过滤完成推荐数据和隐性反馈分析。
3 面向农产品的推荐算法评价指标
目前,对于农产品电商的推荐算法,最常用的评价指标为预测准确率和分类准确率[7]。预测准确率主要由平均绝对误差(MAE)来评估,公式如下:
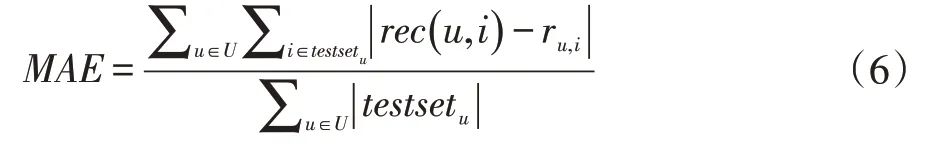
MAE 对所有评估用户u ∈U 和测试集(testsetu)的所有物品,计算推荐得分rec(u,i)与实际得分ru,i的平均偏差。预测准确率还可以由在评分值的范围内归一化后的MAE 或NMAE 和平方根误差(RMSE)来评估。
分类准确率主要有准确率和召回率两个指标来衡量,分类准确率通常也用于衡量信息检索任务的质量。准确率(P)是指命中物品数占推荐物品总数|recsetu|的比例,公式如下:

召回率(R)是指命中物品数在理论上最大的命中数量|testsetu|中所占的比例,公式如下:

在本文第2 节面向农产品的推荐算法应用中,大多数学者都选用了平均绝对误差、准确率或者召回率的全部或部分指标来对推荐算法进行评价。
4 推荐算法在农产品电商应用中存在的问题及展望
目前,个性化推荐算法在电商中的应用已经非常广泛,但针对农产品电商的应用研究相对较少。在农产品电商领域,农产品推荐的效果直接影响了农产品的销售和用户体验,而农产品推荐效果的好坏主要是由其推荐算法所决定。从相关文献的发表时间和数量可以看出,面向农产品电商的推荐算法研究相对较少,且是从近几年才开始逐步增多。同时,将推荐算法应用于农产品电商的关注度正日益增多,还有很大的发展空间,但仍存在着一些问题,需要不断的改进与扩展。
4.1 研究数据质量参差不齐
上述基于推荐算法在农产品电商的应用研究中,由于农产品电商数据的获取难度较大,只有少数的研究者使用的是农产品电商真实数据来进行推荐算法的测试与评估,大多数研究者使用的实验数据质量参差不齐,甚至有部分学者使用的是其他领域内的电商数据(如MovieLens、Jester 数据集)来进行评估测试,无法良好达到针对农产品进行推荐的目的。电商平台中用户行为数据的获取难度最大,因涉及用户隐私问题往往不作公开,极大制约了学者们的研究。因此,学者们应高度关注农产品电商领域内的商品信息以及用户行为信息采集问题。可以通过跟农产品机构合作构建农产品电商推荐系统,基于系统的运行搜集真实的商品及用户行为数据,以支持面向农产品推荐的研究。
4.2 推荐算法研究范围局限
目前的研究成果大部分都集中在基于协同过滤的农产品推荐方面,旨在解决传统算法中存在的冷启动,评分矩阵稀疏性等问题,且大量研究人员都只关注于对其相似度计算的改进。但是基于协同过滤的推荐算法的最大问题是不能准确揭示用户和项目的语义信息,因此无法揭示其之间的语义关系,无法进一步对用户和项目的关系特征信息进行深入挖掘,因此推荐效果并不理想。面向农产品的推荐算法的研究应该更多的考虑农产品的特征,以及领域知识,从而挖掘他们之间的语义关系。目前基于内容的农产品推荐和基于知识的农产品推荐研究较少,可以作为今后重点关注的研究方向。
4.3 评估策略优化问题
农产品最终推荐效果是由推荐算法评估策略判定,而评估策略的优劣决定着推荐算法的发展方向,从上述研究中可以看出目前评价指标主要采用预测准确率(如:MAE、RMSE)和分类准确率(如:precision、recall)。由于大数据环境下农产品推荐系统的复杂性,使得推荐算法的推荐评估成为一个难题。仅仅靠平均绝对误差、分类准确率和召回率来衡量推荐结果的好坏显然是不够的,因此推荐算法的效果评估仍然是研究领域面临的一个重要的问题,也是学者们需要继续研究的方向。
4.4 大数据背景下的农产品推荐展望
在当今大数据时代的背景下,伴随系统规模的持续拓展以及农产品数量和用户的指数级增长,导致用户对农产品的评分数据更为稀疏,同时,系统的计算开销庞大,算法的实时性难以保证,相应的推荐系统所面临的算法扩展性问题也更加严峻。诸多学者提出的改进算法都在致力于缓解矩阵稀疏性问题和扩展性问题,但大数据环境下,数据的稀疏性问题和扩展性问题依然是推荐面临的一个严峻挑战,学者们有待继续深入研究。同时,大数据环境下,数据来源的多样性,数据的非结构化等特征,需要对农产品电商信息进行信息融合处理以及相应的预处理,融合多源异构数据[28]的混合推荐方法研究是今后学者们要注意的工作。
另外值得注意的是,立足于大数据环境,未来可以基于大数据技术设计分布式并行计算的农产品推荐算法,已经有学者基于分布式工作原理,将推荐算法引入到Hadoop 平台和Apache Spark 平台进行并行化处理[29-31]。通过并行处理,数据能够有效提高推荐系统的响应时间,大大增强推荐系统的性能,生成优化推荐结果,但该方面研究才刚刚起步,并不成熟。可以推测分布式并行计算会是农产品电商推荐系统中应用研究的新方向。
5 结语
推荐算法在农产品电商中的应用意义重大,能够帮助消费者快速识别出自己感兴趣的农产品,提高了购物效率。目前已能够实现基于农产品的推荐系统,现有研究多是对推荐算法中基于协同过滤算法的改进,以及对相似度的计算提出不同优化策略;也有少数学者从语义相似度的角度来进行研究,从而基于语义相似度进行推荐;还有学者基于本体理论进行推荐。现有研究已经能够实现电商领域中农产品的常规推荐,但也存在一些问题,如针对评分矩阵的稀疏性等推荐算法问题依然没有得到较好解决,且研究数据质量参差不齐,推荐算法研究范围较为局限。未来可着眼于大数据环境下数据多源异构的特征,以及基于分布式原理优化推荐算法。可以看出推荐算法在农产品电商中的应用还有待更深入地研究,且还有较大的发展空间。
