基于XGBoost与拓扑结构信息的蛋白质复合物识别算法
2020-06-07徐周波刘华东黄文文
徐周波 ,杨 健 ,刘华东 ,2*,黄文文
(1.广西可信软件重点实验室(桂林电子科技大学),广西桂林541004; 2.桂林电子科技大学机电工程学院,广西桂林541004)
(∗通信作者电子邮箱yj18677311628@163.com)
0 引言
蛋白质是构成生命体的关键成分,是细胞中大多数生物过程的重要参与者。由于蛋白质很少以独立个体的方式实现生物功能,即在一个细胞的生物过程中所涉及的蛋白质一般以蛋白质复合物等形式来实现特定的生物功能。识别、预测生物体中的蛋白质复合物对研究生物进程有着重要意义。如何通过计算的方法快速、有效地识别具有生物学功能的复合物成为一项关键的科学问题。
蛋白质相互作用(Protein-Protein Interaction,PPI)[1]网络通常由图的模型来表示,蛋白质复合物可认为是PPI网络中的一个稠密子图。van Dongen[2]通过随机游走的方法提出了蛋白质复合物检测的马尔可夫聚类(Markov CLustering,MCL)算法,MCL算法具有较强的鲁棒性,能够适应网络变化,但是准确性较低,且无法识别重叠簇。Bader等[3]提出的分子复合物检测(Molecular COmplex DEtection,MCODE)算法通过对顶点赋值并选取种子节点,迭代地从种子节点向外扩张加入新节点,最终形成簇,MCODE算法可以产生有重叠的簇,但产生簇的个数较少,使得某些复合物包含的蛋白质数量过大。Nepusz等[4]提出了基于重叠邻居的扩展聚类(Cluster with Overlapping Neighborhood Expansion,ClusterONE)方法,该算法可以有效检测PPI网络中重叠的蛋白质复合物,但算法精准度及敏感度较低。Liu等[5]提出了基于极大团的聚类方法(Clustering based on Maximal Clique,CMC),该算法运用极大团理论从PPI网络中挖掘蛋白质复合物,CMC算法提高了预测的准确性,但对小规模复合物检测效果较差,敏感度较低。Wang等[6]提出的一种快速层级聚类算法(fast Hierarchical Clustering algorithm for functional modules discovery in Protein INteraction,HC-PIN)是通过各个节点的公共邻居节点个数来计算出边的聚类系数,从而找出聚类系数较高的复合物,HC-PIN虽然提高了精准度,但同样存在敏感度较低的问题。此外,上述方法均未考虑复合物内部拓扑结构特点。Wu等[7]提出基于核心-附属结构方法(Core-Attachment based method,COACH)结合蛋白质复合物的拓扑结构,先检测出核心蛋白质,然后将附属蛋白质连接到核心蛋白质上,该方法考虑到了蛋白质结构上的特点,一定程度上提高了预测的准确性。Zhao等[8]提出了一种基于不确定图模型的蛋白质复合物检测方法(Detecting Complex based on Uncertain graph model,DCU),改善了 COACH 方法。Jamali等[9]提 出 了 加 权 核 心 -附 属 方 法(Weighted COACH,WCOACH),利用生物特性先对蛋白质交互网络赋予权重,在此基础上运用COACH算法,近一步提高了预测的准确性。
近年来,一些基于已知蛋白质复合物信息的监督学习方法开始运用于蛋白质复合物的挖掘[10]。这类算法主要分为3步骤:1)从已知的蛋白质复合物中抽取有效的特征,并以矩阵形式存储;2)训练出监督学习分类模型或者得分函数来判定所挖掘出的蛋白质复合物的置信度;3)以训练出的模型为导向,搜索蛋白质复合物[11]。例如,以贝叶斯网络(Bayesian Network,BN)[12]为训练模型及基于回归模型(Regression Model,RM)的蛋白质复合物挖掘算法[13]都是以训练出的模型来对所挖掘出的蛋白质复合物进行评分判定。基于神经网络(Neural Network,NN)[14]模型预测复合物是一种半监督的学习方法,结合深度学习原理从而通过构建神经网络模型来对蛋白质复合物进行预测。
然后采用中国综合社会调查(CGSS)当中对社会信任水平测评的问题对参与者的近邻信任水平进行测量。问题为“在不直接涉及金钱利益的一般社会交往/接触中,您觉得您的近邻当中可以信任的人多不多呢”,答案为“绝大多数不可信”“多数不可信”“可信者与不可信者各半”“多数可信”“绝大多数可信”,分别赋值为1~5 。另外,也同时考察了参与者对陌生人、亲戚、朋友的信任水平。
然而,真实的PPI网络中存在大量的不确定性,并且已知的蛋白质复合物数据并不完备,所以现存的监督模型在准确性上还有待提高。本文提出了XGBoost模型与复合物拓扑结构信息相结合的搜索方法(XGBoost model based for Predicting protein complex,XGBP),有效弥补了传统无监督挖掘算法和监督学习算法的不足。通过实验分析,该算法在精准度、敏感度、F-measure方面显示出良好的性能。
1 相关介绍
1.1 相关概念
定义1 图数据模型可以表示为一个三元组G=(V,E,W),其中V是顶点集合,E是边集,W:E→[0,1]是一个函数,它给每条边e=(u,v)∈E赋予一个权重。
定义2 给定一个子图C,其模块度Q可定义为:

1.2 XGBoost模型
XGBoost[16]是 Boosting算法的其中一种,近年来被广泛使用于数据挖掘领域。Boosting算法的思想是将许多弱分类器集成在一起形成一个强分类器。因为XGBoost是一种提升树模型,所以它是将许多树模型集成在一起,形成一个很强的分类器,有效避免了树模型的过拟合,并在分类精度上也远优于单个分类器。
第五,发挥养老领域社会组织的公益服务功能。非营利性的特征是社会组织区别于企业重要特征,社会组织能够保证养老事业的公益性和福利性,从而克服养老领域资金和人员的不足。为此,各发达国家也充分发挥非营利组织志愿者的积极性。如日本,有超过 10000个养老志愿者服务协会在从事服务于老年人的工作。大量的志愿者的出现,大大减轻了日本这个过渡老龄化的国家的养老负担。
2 XGBP方法
将XGBoost模型应用于蛋白质复合物搜索过程,首先要训练出蛋白质复合物的分类模型;再在蛋白质网络中选取种子节点,运用贪心算法的思想,遍历加入其邻居节点,使其模块度达到最大,输出候选蛋白质复合物;最后将候选蛋白质复合物放入所训练出的模型进行预测分类。
2.1 提取特征
本文将XGBP算法与目前较为经典的八种算法,包括MCODE、MCL、CMC、HC-PIN、COACH、ClusterONE、DCU以及WCOACH在 DIP[18]和 Krogan[19]两个酵母菌相互作用网络相比较(见表3所示)。蛋白质复合物标准库采用了CYC2008[20]和MIPS标准库,两个标准库分别由408个复合物和428个复合物所组成。
叶万军[24]对黄土进行CT和SEM试验,发现冻融环境下试样微结构如内部微裂隙、孔洞等不断发育演化,试样孔径不断增大,微裂纹、微孔洞随之生成,大颗粒不断分解成小颗粒,颗粒间的连接作用减弱,造成细观尺度试样高密度区不断减小,中、低密度区不断增大,这一过程弱化了土的强度。这类似于堆石料在受外界环境如压力作用下,粗骨料的逐渐破碎,骨架结构的破坏,颗粒间的咬合作用减弱,细颗粒逐渐填充孔隙,颗粒进一步被压实,峰值强度的提高与变形的增大相类似,却又因为力的形式而有不同。
首先,从种子节点集合S中选取s,Nv(s)为s的邻居节点集合,此时模块度Q(C)=0。n∈Nv(s),C'=C∪{n},如果Q(C')>Q(C),则将点n加入簇C中,并更新C=C'。遍历集合Nv(s)中所有顶点,直至Q(C)的值达到最大,形成簇,即蛋白质复合物。对种子节点集S中每个顶点执行上述操作,获得蛋白质复合物候选集合candidate_set。
11.1 出芝前管理:埋土扬沙后,盖严棚膜,不盖遮阳网,以增加棚内温度。7天后再喷一次重水,土壤含水量50%~60%,空气相对湿度80%~90%。出芝前应保持覆土干而不燥,湿而不粘;晴天每天喷粗水一次,阴天隔日喷细水一次。温度超过30℃加盖遮阳网或稻草帘。
2.2 训练模型
本文使用MIPS[17]标准库中顶点总数大于2的蛋白质复合物作为正样本,负样本为随机生成的子图。考虑到样本数目不足以及保证正负样本分布一致,本文将每个正样本对应随机生产大小相同的20个负样本。将正负样本结合得到模型的训练集D。构造完训练集后,将训练集作为输入放入XGBoost模型进行训练。XGBoost模型的最佳参数使用网格搜索的方法确定,本文使用的各个参数如表2,模型迭代次数设置为500次。模型训练结束后,得出各个特征在训练过程中的重要性如图1所示。
其中:TP(True Negative)为所预测复合物中与标准库中复合物相匹配的(所预测复合物与标准库中复合物通过式(2)计算OS>w,w为所设定阈值)复合物的数量;FP(False Positive)为所预测复合物总数量减去TP;TN(True Negative)为所预测正确的非蛋白质复合物的数量;FN(False Negative)为标准库中未被预测的复合物数量。阈值w通常设置为0.2[10],本文中采取同样阈值。

表1 提取的特征Tab.1 Extracted features

图1 各个特征在XGBoost模型中的重要性Fig.1 Importance of each feature in XGBoost model
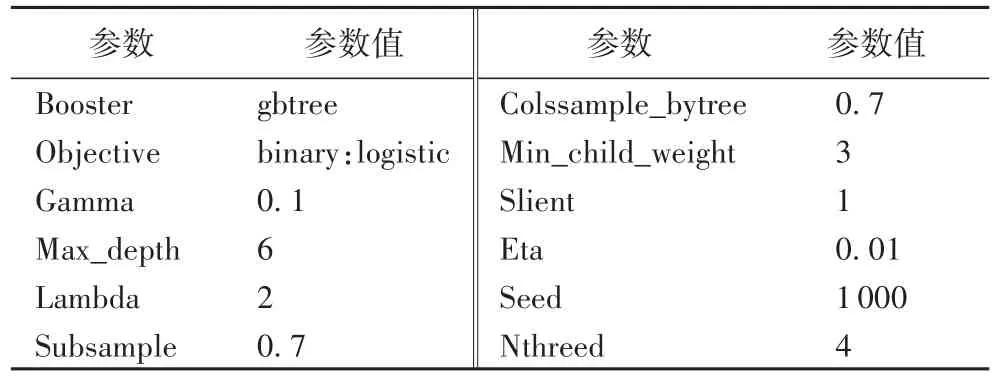
表2 实验参数设定Tab.2 Experimental parameter setting
2.3 种子节点选取
在真实PPI网络中节点度分布服从幂律分布,顶点度较高的节点在网络中起到了关键作用。将顶点度作为选取种子节点的一种简单而常见的选取法则,本文将大于平均度的顶点作为种子节点,通过计算可得种子节点集合S。
2.4 簇的发现
为了避免在算法执行过程中两个复合物高度重合,造成冗余。本文将蛋白质复合物候选集中重合得分超过阈值T,并且模块度较小的复合物丢弃。复合物A和B的重合得分定义如下:
含VSC-HVDC的交直流电网最优潮流计算中,一般以降低网损或发电成本作为优化目标。这里采用机组发电成本之和最小作为目标函数,即:
2.5 去重
许多方法将蛋白质复合物认为是PPI网络中的一个稠密子图,本文也使用该方法来侦测蛋白质复合物。本文使用式(1)作为计算模块度的依据,该定义结合了簇的结构性质及边的权值来衡量簇的密度。一个簇不仅与其他簇相分离,并且簇内边的权值总和应当大于簇外边的权值总和,即weightin(C)>weightout(C)

2.6 复合物的分类
为了更好评估蛋白质复合物预测的质量,本文将所预测的蛋白质复合物与标准库中的蛋白质复合物进行比较。精准度(Precision)和敏感度(Sensitivity)是用来评价预测质量的重要指标。精准度是指识别的复合物中被标识的复合物数量与识别的复合物总量的比值;敏感度是指已知复合物中被标识的复合物数量与已知复合物总数的比值:


3 实验与结果分析
为了方便模型训练,本文将所提取的特征表示为向量的形式,该向量共有16维即提取了16个特征,共可分为7大类,具体为:1)节点个数;2)图的密度;3)顶点度的统计;4)聚类系数;5)通过三角形数统计;6)紧密中心性统计;7)中介中心性统计。所提取的特征如表1所示。

表3 两个蛋白质互作用网络Tab.3 Two protein-protein interaction networks
3.1 评价指标
将去重后的candidate_set向量化后作为输入,放入训练好的XGBoost模型中,对候选集合中的蛋白质复合物进行分类预测,去除candidate_set中置信度小于0.5的蛋白质复合物,所保留的蛋白质复合物即为最终预测结果。具体算法流程如算法2所示。
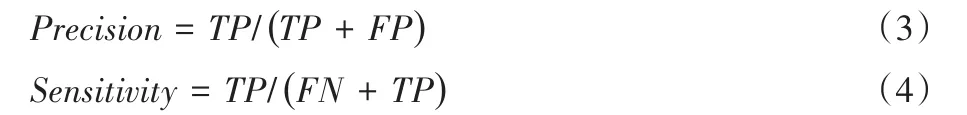
2.1 克氏原螯虾品质变化 使用液体冷却介质急速冻结和常规冷冻克氏原螯虾并在色泽、体表、肌肉、气味以及汤汁方面对其进行评定,结果如图1所示。由图1可见,使用液体冷却介质急速冻结的克氏原螯虾在-18 ℃冷冻贮藏30 d后,感官品质显著高于常规冷冻克氏原螯虾组(P<0.05)。
综合精准度和敏感度两个方面,提出了F-measure,它是精准度和敏感度的调和平均值,计算公式如式(5)所示:
在侦查决策过程中,为了实现侦查目的,人们往往追求最优决策,进而根据最优决策来实施侦查行为。所谓最优决策,是指从全部可行方案中选出的能实现目标的最优方案。但是侦查所面对的是复杂多变的刑事案件,且在侦查过程中存在着侦查人员与犯罪分子之间的活力对抗,因而侦查最优决策往往很难实现,因而侦查决策大多数属于一种满意原则下的决策。

3.2 CYC2008标准库
图2给出了在Krogan数据集下各种算法的精准度、敏感度和F-measure。蛋白质复合物标准库采用CYC2008。从图2可以看出,XGBP算法在三项指标中取得良好的效果,精准度(0.53)在该数据集上并未取得很好表现,敏感度(0.6)及F-measure(0.57)均好于其余算法。
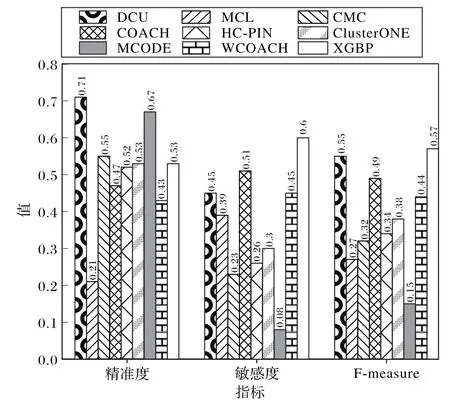
图2 各算法在Krogan数据集性能对比Fig.2 Performance comparison of each algorithm on Krogan dataset
3.3 MIPS标准库
为了进一步分析结果,本节将使用MIPS标准库来代替CYC2008标准库。本文在Krogan数据集上测试上述算法,结果如表4所示。
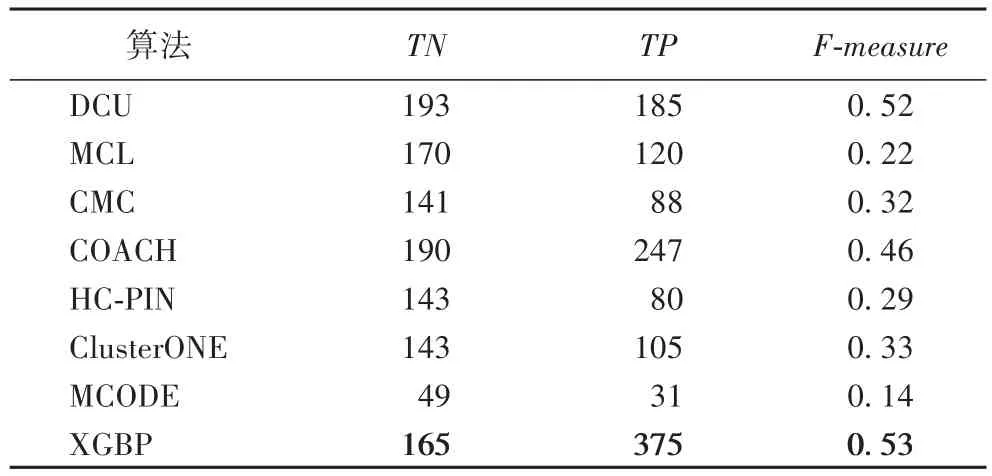
表4 MIPS标准库上各种方法的复合物识别结果Tab.4 Complex identification result of each algorithmon MIPSlibrary
从表4可看出,XGPB算法正确预测出蛋白质复合物的数量最多(375),在标准库中所预测的蛋白质复合物数量较少,F-measure最高(0.53)。
在DIP数据集上测试上述算法,各项指标如图3所示。XGBP算法与传统挖掘算法相比较在多个数据集上均取得良好指标。
3.4 与监督学习算法对比
本节中,XGBP算法与BN、SVM、RM三种算法在DIP数据集上进行比较。四种算法均采用MIPS标准库中蛋白质复合物为正样本用于模型训练。BN、RM、SVM模型参数分别参照文献[12-14]中参数所设置。实验结果如表5。从表5可以看出,与三种监督学习算法相比,XGBP在精准度、敏感度、F-measure上均取得最好效果。
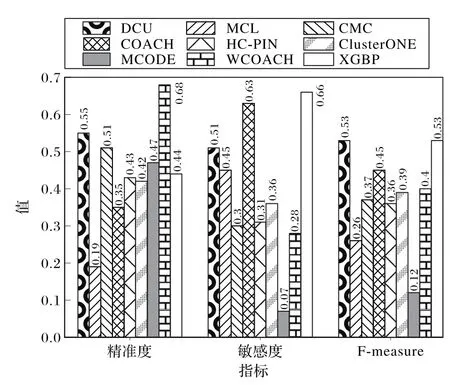
图3 各算法在DIP数据集的性能对比Fig.3 Performance comparison of each algorithm on DIPdataset

表5 MIPS标准库上各监督算法的复合物识别结果Tab.5 Complex identification result of each supervised algorithmon MIPSlibrary
4 结语
针对目前监督学习与非监督学习挖掘算法的不足,本文提出了一种基于XGBoost的搜索算法。该算法结合了非监督学习中利用复合物的结构信息与监督学习的方法,有效提高了蛋白质复合物挖掘的准确性。实验结果表明,该算法与目前流行的监督学习算法与非监督学习算法相比较在F-measure上取得较好的效果。但与传统非监督学习算法相比,在精准度上还有待提高,下一步工作将以此为方向,进一步完善该算法。
