基于改进遗传算法的生鲜多目标闭环物流网络模型
2020-06-07霍晴晴郭健全
霍晴晴,郭健全
(1.上海理工大学管理学院,上海200093; 2.上海理工大学上海-汉堡国际工程学院,上海200093)
(∗通信作者电子邮箱huoqingusst@126.com)
0 引言
生鲜产品包括蔬菜、水果、禽、蛋、水产品、肉、奶制品等,由于其高易腐性和短生命周期性的特点,对物流网络的要求相当苛刻。据相关资料统计,我国生鲜产品损耗严重,仅水果蔬菜每年损失就达到1000亿元以上,流通损耗率约为30%,而发达国家的损耗率低于5%[1]。科学合理地规划生鲜物流网络,不仅能减少其配送时间,最大限度地保证新鲜度,而且对实现整个物流网络低成本、高效率运作均有较为重要的意义[2]。曹裕等[3]研究表明零售商与供应商制定成本共担契约可有效降低供应链成本并提高生鲜供应链保鲜水平;王勇等[4]考虑生鲜配送时效强的特征,构建生鲜配送的物流成本和损失成本最小的优化模型。现有文献多在确定性条件下研究生鲜正向或逆向物流成本的最小化,然而不确定参数对物流网络规划具有重要影响[5],基于此,本文考虑生鲜产品退货量的不确定性,统筹正逆向物流,构建生鲜产品闭环物流网络以最小化其成本。
大量的温室气体排放由车辆在驾驶时产生,对环境造成严重污染,低碳城市物流网络配送系统在城市可持续发展中发挥着重要作用[6]。Aljohani等[7]考虑终端物流配送环节中车辆空载率高、配送路线不优等问题,通过规划其回收路径,提高装货率,从而降低碳排放和物流配送成本;Tiwari等[8]考虑了物流区域发展过程中的碳排放问题,揭示了区域物流能源与碳排放之间的关系;李进等[9]基于节能减排的视角,研究了低碳环境下由第三方提供运输服务的车辆路径问题。当前对减少物流网络碳排放的研究多集中在路径规划上,鲜少考虑其节点选址、运营过程的碳排放等,基于此本文考虑闭环物流网络中节点选址、运营碳排放、路径规划,从整体上构建其碳排放模型。
物流活动涉及社会、企业、客户等多个利益主体,资源相对密集[10],基于现实背景的复杂性,在优化其网络时,除了考虑经济成本、碳排放之外,还需要考虑其创造的社会效益[11]。社会效益被认为是增加职业机会和减少工作中的危害[12],虽然它对周围人口福利的影响是重大的,但设计一个具有经济观点的供应链时,通常不会考虑社会效益[13]。Bal等[14]考虑社会效益的最大化,研究了废弃电子电气设备的物流和回收规划;Meyer等[15]考虑社会效益,讨论了阿根廷林业供应链的优化设计模型。基于上述研究,本文在考虑生鲜产品闭环物流网络经济成本最小化、碳排放最小化的同时,以社会效益最大化为目标,构建其多目标闭环物流网络模型。
遗传算法(Genetic Algorithm,GA)作为发展较为成熟的元启发式算法之一,具有全局搜索优势,在解决大规模路径优化、复杂约束等问题上表现出良好的性能[16],但其局部搜索能力差,迭代过程中可能错过局部最优解[17]。朱杰等[18]将遗传算法与模拟退火算法融合,以改进算法为立体仓库优化提供决策方法;裴小兵等[19]针对流水车间调度问题,提出了一种新型混合改进遗传算法进行优化求解。本文针对生鲜多目标闭环物流网络问题,提出了基于改进优先级的遗传算法:首先,通过对赋予染色体随机权重,产生各编码列的等级;接着,判定其优先级,从而提高其局部搜索能力;最后,通过与粒子群优化(Particle Swarm Optimization,PSO)算法的对比,验证了本文所改进遗传算法的全局与局部搜索能力。
综上所述,本文首先在退货量不确定条件下以经济成本最小、碳排放最小、社会效益最大为目标构建了生鲜闭环物流网络多目标模型;其次考虑多目标优化问题,改进遗传算法,设计基于优先权的遗传编码;最后结合上海市某生鲜企业闭环物流网络实例,分别通过改进的GA与PSO搜索多目标的最优解组合,通过算例分析与算法对比验证所建模型的可行性及所改进算法的有效性。
1 生鲜闭环物流网络多目标模型
1.1 闭环物流网络结构描述
生鲜闭环物流网络结构如图1所示,主要由农户、供应商、配送中心、超市、客户、回收中心、处理厂7部分组成。

图1 生鲜产品闭环物流网络结构Fig.1 Closed-loop logisticsnetwork structureof fresh foods
在正向物流中,各农户将生鲜产品运送至供应商处,供应商对生鲜产品分类包装统一运送至超市的配送中心,配送中心根据各门店需求预测进行配送,客户至超市门店购买产品。
在逆向物流中,超市将退货品送至回收中心,回收中心对退货品分类处理,将具有一定残值的产品运送至供应商处进行再循环工序,将无残值的退货品残渣送至处理厂统一处理[20]。
1.2 多目标模型的建立
1.2.1 模型假设
1)供应商、配送中心、超市、回收中心、处理厂的候选位置与数量已知。
2)供应商分为大、小两种供应类型。
3)各节点之间的运输成本与运输距离和运输量成正比。
4)节点之间的距离是货车行驶的距离,并非两点间的直线距离。
5)碳排放量与货车运输距离和运输量成正比。
1.2.2 符号
m代 表 农 户 ,m∈{1,2,…,M};c代 表 供 应 商 ,c∈ {1,2,…,C};d代表配送中心,d∈ {1,2,…,D};s代表超市,s∈ {1,2,…,S};i代表客户,i∈ {1,2,…,I};r代表回收中心,r∈ {1,2,…,R};p代表处理厂,p∈ {1,2,…,P};k代表供应商类型,k∈ {s,l};v代表运输车辆,v∈V;l代表运输路线,l∈ {1,2,…,L}。
1.2.3 参数
代表供应商(类型为k)的固定建设成本;Fd代表配送中心的固定建设成本;Fs代表超市的固定建设成本;Fr代表回收中心的固定建设成本;Fp代表处理厂的固定建设成本代表供应商(加工容量为k)的运营成本;Od代表配送中心的运营成本;Os代表超市的运营成本;Or代表回收中心的运营成本;Op代表处理厂的运营成本;U代表单位运输成本;qCO2代表货车载重单位重量的产品行驶单位距离排放的CO2;为类型k的供应商创造的工作岗位数量;fd、fs、fr、fp为配送中心、超市、回收中心、处理厂创造的工作岗位数量;Hck为类型k的供应商的员工因工伤请假的天数;Hd、Hs、Hr、Hp为配送中心、超市、回收中心、处理厂的员工因工伤请假的天数;wf、wH分别为创造的工作岗位,员工因工伤请假天数所占的权重;discd、disds、dissr、disrp、disrc分别代表两节点之间的距离;Qcd、Qds、Qsr、Qrp、Qrc分别代表两节点间的运输量、cad、cas、car、cap分别代表各节点的最大处理能力;α代表退货品的处理率;β代表退货品的循环率;res代表超市s的生鲜产品退货量,模糊值。
1.2.4 决策变量
Yck为0-1变量,若选择候选供应商,则Yck=1,否则为0;Yd为0-1变量,若选择候选配送中心,则Yd=1,否则为0;Ys为0-1变量,若选择候选超市,则Ys=1,否则为0;Yr为0-1变量,若选择候选回收中心,则Yr=1,否则为0;Yp为0-1变量,若选择候选处理厂,则Yp=1,否则为0;YvL为0-1变量,若车辆V在第L条路线运输,则,否则为0为0-1变量,若车辆在两节点间运输时选择第L条路线,则为1,否则为0。
1.2.5 模型构建
1)生鲜闭环物流网络多目标优化模型的第1个目标为经济成本最小化。总经济成本E1由各网点固定建设成本、运营成本及物流过程中的运输成本构成,运输成本为货车在所选节点间运输距离与运输量及单位运输费用的乘积之和。其目标函数为:
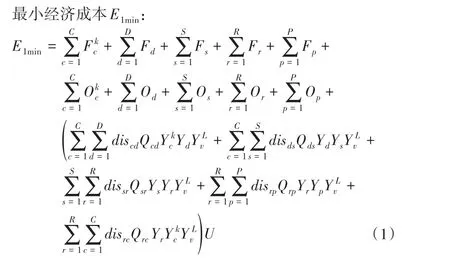
2)生鲜闭环物流网络多目标优化模型的第二个目标为碳排放E2最小化。碳排放目标的设定考虑到了闭环物流网络运输过程中产生的 CO2排放量[21],即 CO2排放最少,CO2排放量为车辆在所选节点间的行驶路程与运载量及单位距离CO2排放量的乘积之和。其目标函数为:

3)生鲜闭环物流网络多目标优化模型的第三个目标为产生的社会效益E3最大。本文参考文献[22],选取为员工提供的工作机会与员工因工伤请假的天数作为社会效益的指标。工作机会为所选各节点提供的工作岗位数量之和,请假天数为所选各节点员工因工伤请假的天数之和。其目标函数为:
最大社会效益E3max:


式(4)~(8)表示流量均衡约束;式(9)~(11)表示容量约束;式(12)~(16)表示至少选择一个供应商、配送中心、超市、回收中心、处理厂;式(17)表示至少有一辆车完成整个物流网络的运输;式(18)表示运输量非负。
2 模型求解
2.1 模糊机会约束清晰化
生鲜产品的退货量res为模糊参数,模糊机会约束规划方法(Fuzzy Chance Constrained Programming Method,FCCP)可有效规避模糊参数对此类约束条件不清晰的规划问题的影响[23]。首先将退货量res设为三角模糊参数,记res=(res1,res2,res3),其中res1与res3分别为企业给定的置信水平α的上下界,res2为α的最可能值。其次应保证约束条件成立概率控制在企业制定的置信水平之上,根据决策者制定的置信水平,将模糊规划转化为等价的清晰约束。其模糊隶属函数如下表示:

2.2 多目标的模糊化处理
与单目标优化问题不同,多目标的各子目标间往往存在冲突,在改进某个目标函数的同时也会引起其他子目标性能的降低,很难实现多个子目标同时达到最优[25]。模糊多目标规划能使各子目标尽量达到最优,从而获得多目标的最优组合[26]。选择合适的隶属度函数是模糊优化的前提[27],参考文献[28-29]的做法,选择如下隶属度函数,gs表示越小越优型目标函数,gv表示越大越优型目标函数,隶属函数表示为:
式中:μg(x)表示E的隶属度函数,μ(0≤μ≤1)的大小反映了优化结果的满意度,λ和γ分别表示形状系数,gvmin、gvmax和gsmin、gsmax分别表示gv和gs的最小值、最大值,λ、γ>0且不为1。引入变量ζ,将原目标函数转化为约束条件,即μg(x)≥ζ(0≤ζ≤1),则此时模型可转化为maxξ的单目标函数。根据上述原理,本文所构建的多目标模型可表示为maxξ,此时约束条件除包括式(4)~式(18),还包括:

先求出各子目标在所有约束条件下的最优解,再利用这些最优解确定隶属度函数,使交集的隶属度函数取最大值,即为多目标问题的最优解。
2.3 GA与PSO优化算法对比
2.3.1 改进的GA
本文所建模型是一个大规模规划模型,为避免传统的GA在迭代过程中错过局部最优解,从而影响最优近似解的精确性[30],参考文献[31-33],本文采用基于优先权的GA来求解闭环物流网络的多目标模糊规划模型,具体操作如下:
步骤1 染色体编码与初始化。染色体数组表示节点C、D、S、R、P是否被选择,车辆V是否在路线L上运输,节点间生鲜产品运输量。首先赋予每个节点及路线随机权重,随机产生各个节点及路线的等级;接着判定每个节点间线路的优先级,根据邻接矩阵确定节点间的连接关系,连接记为1,不连接记为0。对于连接的点,由起点开始依次选择节点权值大的节点组成路径,且路线不重复,如图2所示。
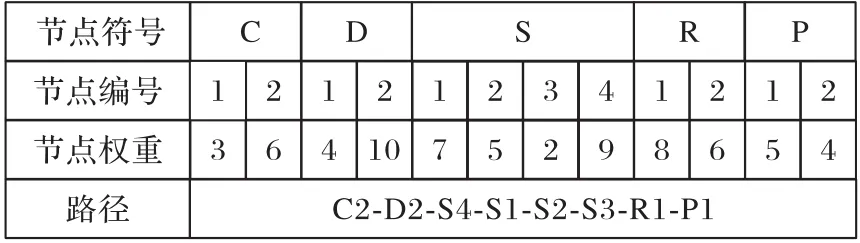
图2 基于优先级的编码及解码Fig.2 Priority based codingand decoding
步骤2 适应度评估与选择。染色体的适应度反映了被选择的概率,在满足约束条件的情况下,利用目标函数(1)、(2)、(3)计算各个体的适应度值,适应度值可直观反映染色体对应规划方案的优劣。选择适应度大的个体复制到子代,重复进行,直至形成整个子代种群。
步骤3 交叉与变异。交叉使子代同时继承父母代的基因,保持更高的适应性。变异使某个基因以一定的概率随机发生突变。交叉和变异不仅产生新个体,而且提高种群局部搜索能力。先随机将父代染色体两两分组,再随机选择染色体的某一节,交换后半段,具体操作如图3所示。
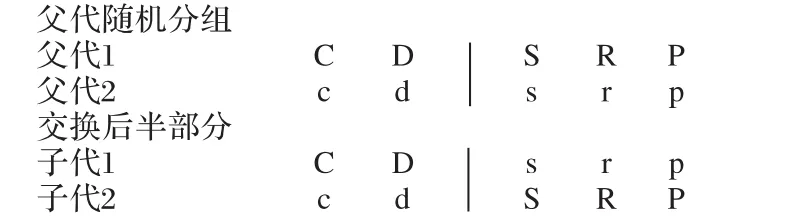
图3 单点交叉变异示例Fig.3 Example of single point cross variation
步骤4 终止条件。若达到预先设定的最大进化代数,终止算法,否则转向步骤2。设置最大迭代次数为400,交叉概率为0.8,变异概率为0.05。
2.3.2 PSO算法
粒子群优化(PSO)算法作为一种智能寻优算法,不需要选择、交叉、变异等复杂操作[34],通过追随当前搜索到的最优值来寻找全局最优,粒子收敛速度快,可高效寻找到多目标选址、路径规划问题的最优解[35]。具体操作步骤如下:
1)初始化算法的各项基本参数。
2)对各节点间的路径进行搜索,根据各节点间路径的比较,确定节点的选址。
3)按照约束条件,每只蚂蚁构建路径对选中的节点与相应路径进行调整。
4)检查每只蚂蚁的函数值,并进行排序,得到最小值,即为此次迭代的最优解。
5)判断最优解是否满足终止条件,若满足条件则停止搜索,输出最优解;否则继续执行步骤3)。设置最大迭代次数为400,蚂蚁数量50。
3 算例
3.1 数据来源
本文以上海市某生鲜企业为例,由企业调研得知,2家候选供应商c1、c2坐标分别为(10.5,4.2)、(3.7,52.1);2个配送中心d1、d2坐标分别为(14.5,25.2)、(5.7,41.0);2个回收中心r1、r2坐标分别为(8.2,50.0)、(12.1,14.2);2个处理厂p1、p2坐标分别为(2.5,20.2)、(17.7,8.1)。5个超市门店s1、s2、s3、s4、s5位置坐标及退货量的三角模糊量如表1所示,其他参数数值见表2。

表1 超市位置坐标及退货模糊量Tab.1 Supermarket location coordinatesand return fuzzy numbers
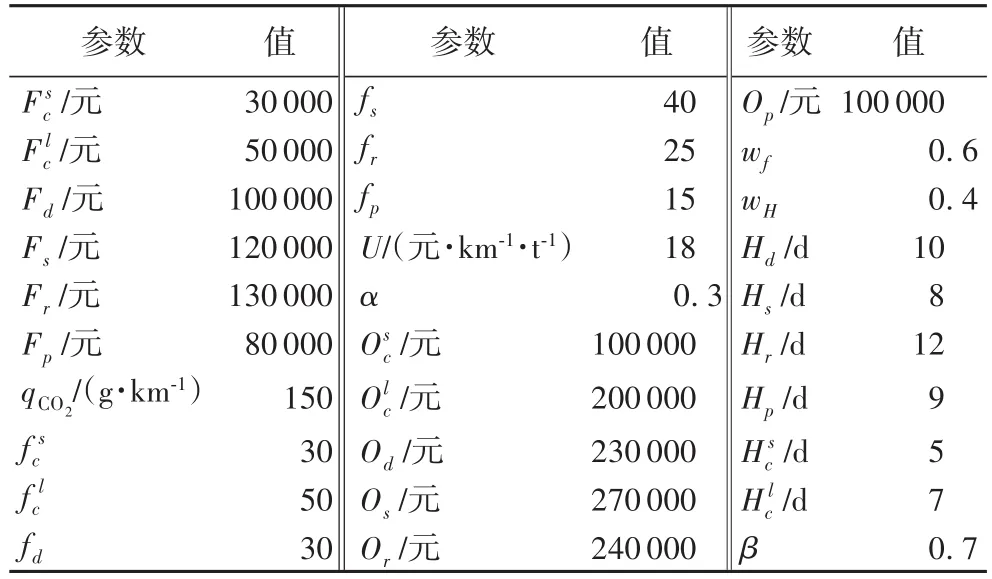
表2 其他相关参数数据Tab.2 Other relevant parameter data
3.2 算例结果分析
利用Matlab2018a分别编写基于优先级的GA代码与PSO代码。考虑退货量的三角模糊量对企业最优决策的影响,采用均匀分布法对企业制定的置信水平影响αr赋值70%、80%、90%,在不同置信水平下将单目标与多目标优化结果进行对比,并给出PSO算法的Pareto最优结果与改进的GA满意度。
不同置信水平下单目标与多目标的对比结果如表3所示;PSO算法对应的多目标规划方案的Pareto前沿的结果如图4所示,改进的GA满意度水平如图5所示;最优置信水平下各子目标的选址路径如图6(a)~6(c)所示,多目标优化的选址路径如图6(d)所示。

表3 不同置信水平下各目标函数值及选址方案Tab.3 Objectivefunction valuesand siteselection schemes at different confidencelevels
从模糊角度分析可知:1)各节点退货量随着对应三角模糊量的置信水平αr的增加而增加,退货量的增加可能需要更多的车辆运输,碳排放也会随运输量及运输车辆增加而相应增加,节点也需要雇佣更多的劳动力。经济、碳排放、社会目标的值随之上升。2)随着置信水平的改变,节点选址及配送路径也做出灵活变化,三角模糊量的置信水平变化对其最优规划有显著影响。最优解;本文结合两种互补的优化算法,有效寻求最优解。2)改进的GA满意度在迭代次数达到200之前增长频率较低,但达到200后增长频率显著上升,说明其更适合大规模问题的求解。
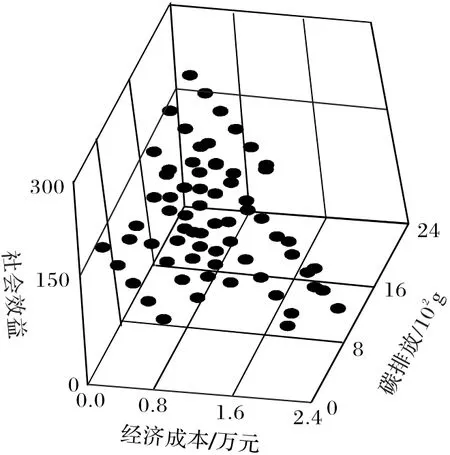
图4 Pareto前沿分布Fig.4 Pareto front distribution
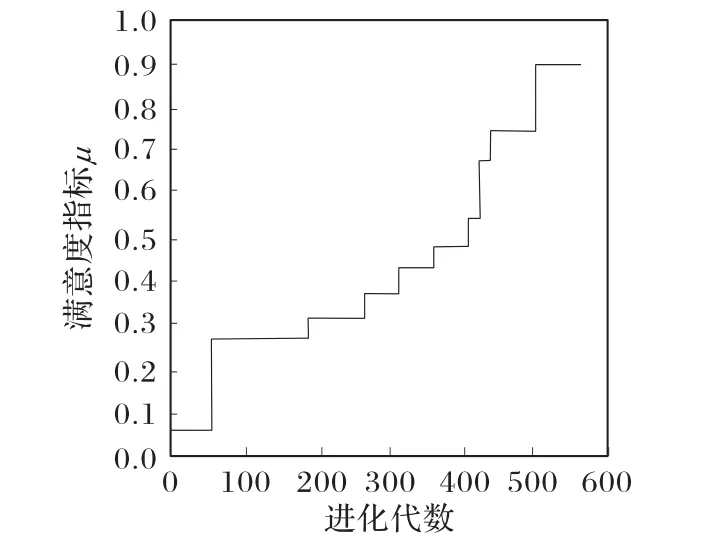
图5 GA收敛性Fig.5 Convergenceof GA
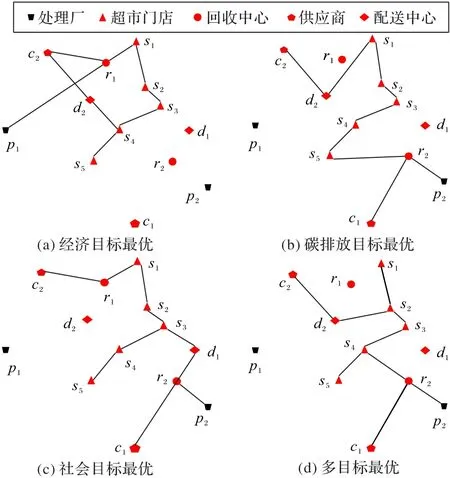
图6 各目标优化路径Fig.6 Optimization path of each objective
综上,生鲜产品可持续闭环物流网络模糊多目标优化使企业成本优化的同时,兼顾环境影响和社会责任,实现企业总体决策满意度最优,而且降低了不确定参数的影响,更符合企业实际决策。改进的GA能有效解决该类大规模求解问题。
4 结语
从多目标角度分析可知:1)与单目标最优相比,多目标最优方案的各子目标均做出一定让步,但多目标最优方案兼顾了三个子目标,优化满意度达到了0.92。2)随着置信水平的上升,多目标优化增长的幅度低于单目标最优的增长幅度,即多目标优化方案能更好地应对不确定参数的影响,对企业实际决策更有益。
从算法的角度分析:1)对于PSO而言,其收敛速度过快易陷入局部最优;对于GA而言,其寻找全局最优时易错过局部
本文以生鲜产品为研究对象,考虑不确定环境下闭环物流网络最小经济成本、最小碳排放、最大社会效益,设计了生鲜产品可持续闭环物流网络模糊多目标模型。改进的GA计算结果表明,多目标总体满意度高于单目标最优且大于0.90,从而验证了本文模型的有效性。
本文在多目标求解方面仅考虑了改进遗传算法(GA)、粒子群算法(PSO),处理多目标的方法是多样的,下一步可考虑如何将鲸鱼算法、萤火虫算法等应用到模型中;且生鲜产品闭环物流网络的不确定参数有多种形式,如何同时考虑多种不确定性还待进一步探讨。
