工业噪声环境下多麦状态空间模型语音增强算法
2020-06-07吴庆贺吴海锋
吴庆贺,吴海锋,沈 勇,曾 玉
(云南民族大学电气信息工程学院,昆明650504)(通信作者电子邮箱whf5469@gmail.com)
0 引言
语音是语言的声学表现,是人类交流信息最自然和最方便的形式。在很多工业环境中,大型设备的作业往往需要多人协同操作,比如一人根据作业环境发出指令,一人根据指令进行操作,而语音通信就成为相互协作中有效的沟通方式。然而,语音不可避免受到环境噪声的干扰,特别当大型设备的动力系统和作业系统所产生的声音强度远远大于语音强度时,相互通信的有效性就会产生影响,严重时还会产生通信失效,导致协同作业的失败。语音增强是通过减轻或抑制背景噪声来相对提高语音功率的一种技术,由于它能减小噪声对通信双方所产生的干扰,因此广泛应用于噪声环境的语音通信场景[1-3]。
早期的语音通信设备常采用单麦克风设计,因此其语音增强也基于单麦技术[1-5]。单麦语音增强由于只使用一个麦克风,缺少参考信号,导致直接从带噪语音中估计的语音与真实语音差异较大,语音增强效果受到影响[4]。为了更准确地估计语音,一种可行的方法是用自回归(AutoRegression,AR)对语音进行状态空间模型(State Space Model,SSM)建模,再用卡尔曼滤波解决该AR模型(AR-Kalman)[5-7]。该方法的性能往往与AR系数的阶次相关,只有较高的阶次才能准确恢复语音,但这又会使得语音增强的计算复杂度增高。多麦克风技术是在语音设备的不同位置配备多个麦克风,相当于产生了多个通道的语音信号[8-9]。相较于单麦技术,多麦语音增强更容易消噪,因此也得到了更广泛的应用[5,10-11]。较早的多麦语音增强采用双麦克风设计,两个麦克风所收集的噪声信号近似相等,收集的语音信号具有不同的衰减,因此两者进行相减就可以将噪声相消(Noise Cancel,NC)[12-14]。这种NC算法简单,易于实施,但若系统本身存在的噪声功率较大,相消后的残余噪声仍然会极大地干扰语音信号。近年来,由于深度神经网络的兴起,深度学习也被尝试用于多麦的语音增强中[8],但是深度学习需要对不同的环境噪声进行大规模的数据训练,而且深度网络的训练参数数目往往极其庞大,这些都使得实施成本变得昂贵。另外,若将工业噪声也看成一个源信号,多麦语音增强也可以是一个盲源分离的“鸡尾酒会”问题[15-17]。盲源分离算法中具有代表性的是独立成分分析(Independent Component Analysis,ICA)[15-18],但ICA需要计算四阶统计量,要求尽可能多的观测值,即使运算速度较快的FastICA[15-18]也需经多次循环迭代才能收敛,其实时性能难以满足即时语音通信的要求[9]。
针对以上传统语音增强应用于工业噪声环境下的问题,本文提出了一种采用多麦的卡尔曼算法(Multi-Microphone Kalman Algorithm,MMKA)来进行语音增强。与传统的ARKalman相比,其状态方程采用较为简单的差分方程来减少AR系数数目,同时利用多麦技术,在状态空间方程中构建了混合矩阵。该算法的实时性和复杂度优于ICA类算法和传统的AR卡尔曼滤波。另外,为了进一步降低计算复杂度,本文还根据多麦技术构建混合矩阵,采用最小二乘方法进行语言增强(Least Square Speech Enhancement,LSSE)。实验中,本文采用公开数据库中的一组纯净语音信号和来自两组不同环境的工厂噪声信号,模拟了多麦技术下多通道的带噪语音。实验结果表明,本文的MMKA的输出语噪比(增强后的语音与残留噪声之比)优于传统AR卡尔曼滤波约2 dB,而运行时间仅不到其2%。同时,MMKA还能够满足实时性要求,其延迟时间为毫秒级别,而FastICA和AR-Kalman却存在约平均半秒的延迟。另外,当考虑低复杂度的语音增强算法时,本文提出的低复杂度的LSSE运行时间与传统NC算法相当,但输出语噪比却优于其约1 dB。
1 相关工作
早期的通信设备多采用单麦克风对语音的采集,由于缺少参考信号,因此需要对语音信号建模。较流行的方法是通过AR建模,得到状态空间方程[5,7],表示为:

其中:X k=[Sk Nk]为第k时刻的状态矢量,Sk为纯净语音信号,Nk为环境噪声信号(k=1,2,…,K);φk=[ρkυk]T为状态高斯白噪声矢量,ρk为纯净语音信号AR模型所含噪声,υk为环境噪声信号AR模型所含噪声;μk为测量过程噪声;A为AR模型系数相关矩阵;H1、H2分别为状态方程和测量方程系数矩阵。
根据式(1)、(2),卡尔曼滤波求解该AR状态空间模型[5],完成语音增强;然而,对Sk和Nk进行AR建模时需要分别对信号分帧,这会直接影响矩阵A维度大小,从而影响卡尔曼滤波的复杂度与延迟时间。若模型阶数取得过大,矩阵A的维度增大,计算复杂度增加;若阶数过小,AR建模信号又会与真实值偏差过大。
为提高语音传输的质量,语音设备可配备多个麦克风。相比单麦语音,多麦克风可采集多个通道的语音信号,相当于有更多的观测值,以减小降噪和去噪的难度。较早的多麦语音增强采用双麦克风设计来实现噪声相消[10-12],若两个麦克风采集的语音信号间所存在延迟仅可以避免造成符号间的干扰,则可表示为:

其中:y1k和y2k分别为主麦克风和参考麦克风接收的带噪语音信号,h1和h2分别为主麦克风和参考麦克风对应的语音信号衰减系数,N1k和N2k分别为主麦克风和参考麦克风接收到的环境噪声信号,w1k和w2k分别为主麦克风和参考麦克风接收到的高斯白噪声。
双麦克风的配备使得Sk经过了h1和h2的不同衰减,而N1k和N2k又近似相等,因此若不考虑延迟,两麦克风相减信号y1k-y2k理论上仅剩纯净语音信号。然而实际应用过程中,当环境噪声信号功率远大于语音信号时,N1k-N2k会远大于Sk,同时还会存在白噪声残余信号w1k-w2k。
另外,若将n个麦克风接收的语音信号看成多源信号的混合叠加,则式(3)、式(4)可以表示为:

其中:Y k=[y1ky2k…yNk]T,N为麦克风总数;B为混合矩阵,由各语音信号和环境噪声到各麦克风的衰减系数构成;w k为高斯白噪声矢量。从式(5)求解Sk是一典型的盲源分离问题[17-18],求解该问题的一种代表性算法是ICA类算法,而其中快速ICA算法(也称为FastICA)的计算速度和鲁棒性都比较高,表示为:
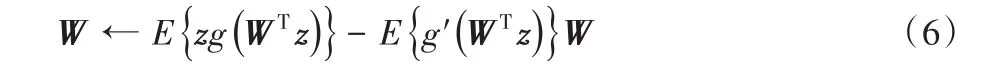
其中:W为分离矩阵,z为Y k白化后所得到的,g(⋅)为负熵的鲁棒近似函数的导数,g'(⋅)为g(⋅)的导数。从式(6)可以看到,FastICA算法需要计算负熵函数,其一般为四阶统计量,而且其分离矩阵W需要循环迭代。因此,将其应用于实时性较高的语言通信系统中,会出现计算复杂度高和收敛速度慢的缺点。同时,多麦克风的带噪语音信号不含有关于源信号排序信息,分离的噪声和语言信号的顺序也是不确定的[17-18]。
2 问题提出
在工业环境中,语音是人们在协同工作中完成沟通的常用方式,然而各种复杂生产环境产生的噪声极易对语言信号的通信造成干扰,例如机械设备的动力系统或传动系统产生的噪声。这些噪声远比普通生活场景中的噪声强度高,其信号功率也通常大于语音信号功率,而语音增强可以有效降低噪声对语言通信造成的不利影响。
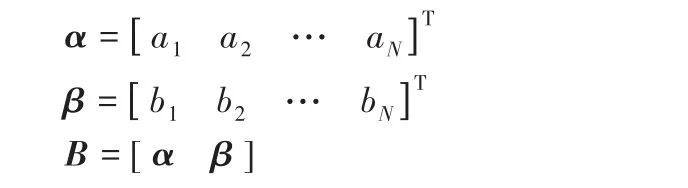
多麦技术配备多个麦克风来增强语音,如图1所示,第k时刻的语言源信号Sk和噪声源信号Nk分别经a1,a2,…,a N和b1,b2,…,bN的衰减到达麦克风1,麦克风2,…,麦克风N,并与白噪声w k叠加形成含有白噪声的带噪语音信号Y k=[y1ky2k…y Nk]T。若令则Y k由式(5)来表示,而语音增强的问题就是从观测的语音信号Y k中尽可能得到纯净语音信号Sk。由于语音通信的实时性要求,采用的语音增强算法应该具有处理速度快和延迟时间少的特点,另外,为了满足可应用于工程实践的要求,算法还应该具有较低的计算复杂度,以保证较低的系统实现成本。下面主要从以上要求来介绍本文的语音增强算法。
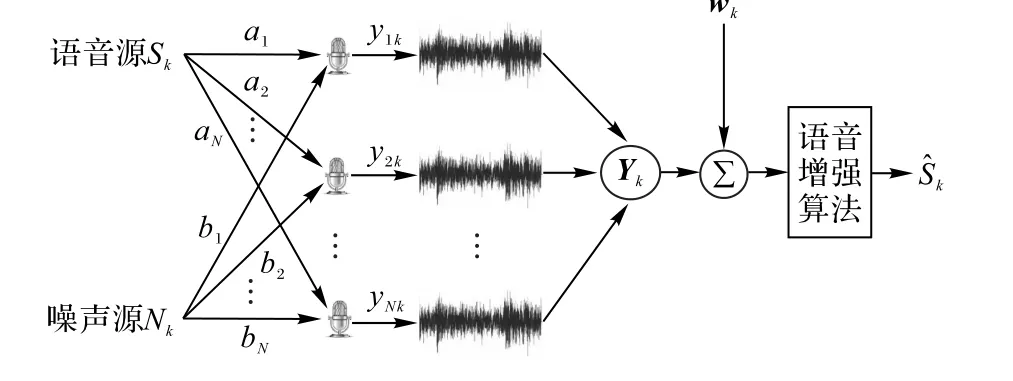
图1 多麦克风的带噪语音增强问题Fig.1 Multi-microphone noisy speech enhancement problem
3 MMKA
3.1 状态空间模型
由于语音信号本身的非平稳性,可以利用状态空间模型来表示语音信号不同时刻的相关性[7];同时,卡尔曼滤波是一种通过状态空间模型和贝叶斯准则来估计隐藏状态的一种算法[7],因此建立有效的SSM方程就可以采用卡尔曼算法来对语音增强。SSM方程通常可以表示为:

其中:h(⋅)为状态函数,f(⋅)为测量函数,ωk是状态噪声矢量,μk是观测噪声矢量。通过式(5)估计X k,需要知道函数h(⋅)和f(⋅),若它们均为线性函数时,可以利用线性卡尔曼滤波法估计X k;若为非线性函数,可以利用扩展卡尔曼、粒子滤波或积分卡尔曼等非线性滤波[7]。但是,无论采用何种方法估计X k,必须知道这两个方程。
3.1.1 状态方程
下面,先来构造状态方程(7)。对语音信号Sk进行归一化,令:

若ω1k∈ [Sl,Sr],则将[Sl,Sr]分成 2L个区间l1,l2,…,l2L,分 别 统 计ω1k落 在 各 个 区 间 的 概 率P(ω1k∈li)(i=1,2,…,2L)。当采样周期Δt较小时,其概率分布图近似于高斯分布。图2(a)给出了来自IEEE语音库中一个语音信号的P(ω1k∈li)概率分布,其中Δt=0.5 ms。由图2(a)可以看出,该语音信号ω1k值越小,发生的概率越大,分布曲线近似于零均值的高斯分布。接着,计算ω1k的自相关函数R1(τ),其中τ=k1-k2,k1、k2∈ {1,2,…,K},其波形近似单位冲击响应函数δ(τ),符合白噪声特性。图3(a)给出了图2(a)中语音信号的R1(τ)的波形,由图中可以看到,当τ=0时,R1(τ)取得最大值,而τ取其他值时,R1(τ)均较小,因此,可以推断ω1k为一近似高斯白噪声。另外,对工业噪声信号Nk进行归一化,令:

当采样周期Δt较小时,ω2k同样满足高斯白噪声特性。图2(b)和图3(b)分别给出了一个工厂噪声信号的P(ω2k∈li)和ω2k的自相关函数R2(τ)波形图,其中Δt=0.5 ms。从图中可以看到,其概率分布和自相关函数图也近似于高斯分布和单位冲击相应函数。
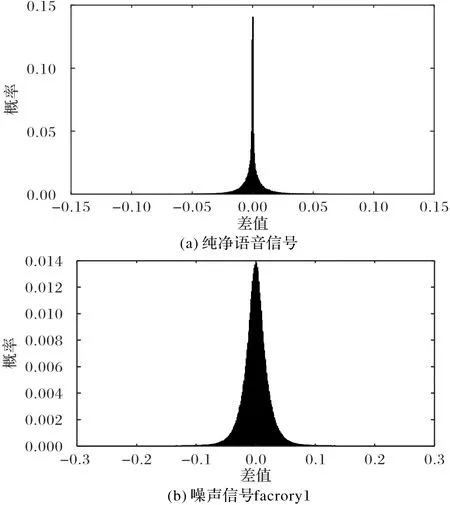
图2 纯净语音信号和噪声信号factory 1相邻两时刻差值的概率分布Fig.2 Probability distribution of thedifference between two adjacent timesof purespeech signal and noisesignal factory 1
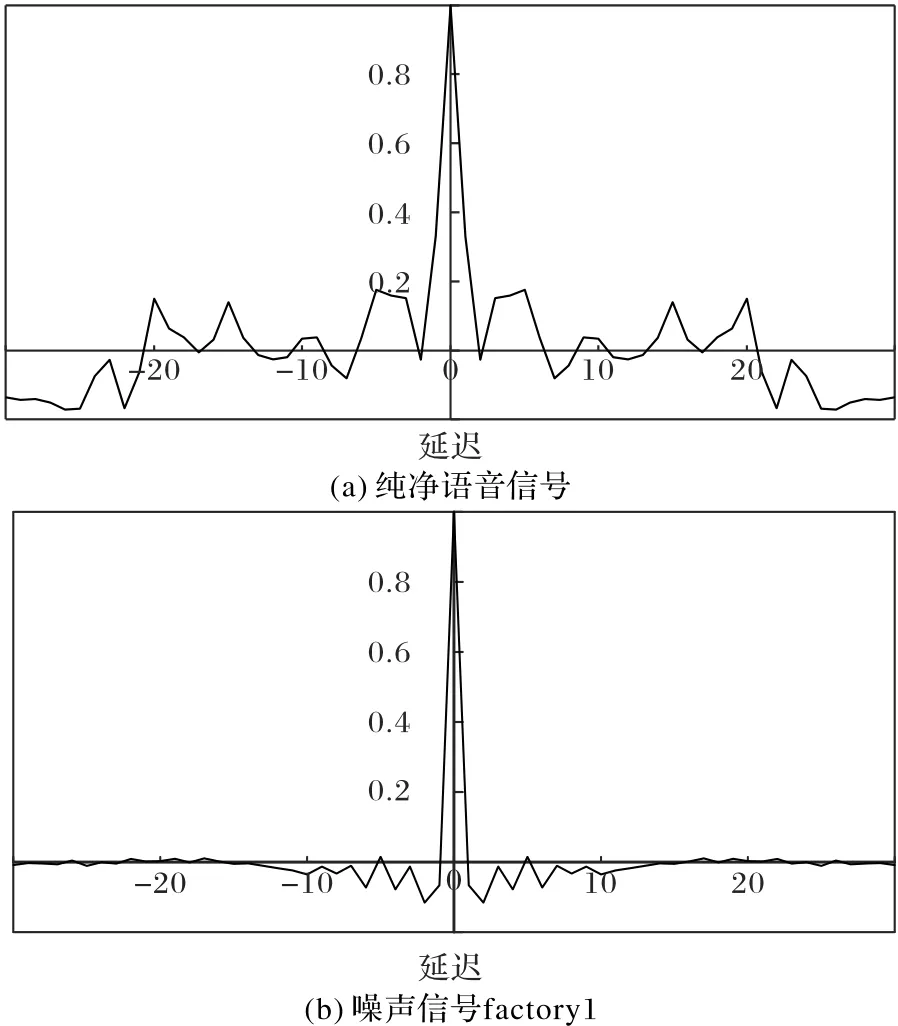
图3 纯净语音信号和噪声信号factory 1相邻两时刻差值的自相关分布Fig.3 Autocorrelation distribution of the difference between two adjacenttimesof purespeechsignal and noisesignal factory 1

其中ωk=[ω1kω2k]T是高斯白噪声矢量。
3.1.2 测量方程
根据式(3),测量值Y k为各麦克风接收到Sk和Nk的线性
根据以上分析,可以将式(7)改写为:叠加,因此测量方程(8)可改写为:

其中μk=[μ1kμ2k…μNk]T是方差矩阵为Qμ的高斯白噪声为对角阵。若方程(12)能够确定,则混合矩阵B需已知。在多麦语音系统中,语音的衰减随其与麦克风距离的波动而波动[19],距离麦克风较远的语音衰减系数大于距离近的语音。同时,由于两个麦克风安装在同一个电话上,因此其距离不会超过电话本身长度,设两麦克风间距离为10-2m,若噪声到麦克风的距离在10 m,则噪声源到不同麦克风的相对距离差在10-2/10=10-3的量级,若噪声到麦克风的距离在1 m时,距离差在10-2/1=10-2的量级。由此可确定,只要噪声源离电话距离相对较远时,距离差可近似看作零。因此在工业环境中,若语音源与多个麦克风的距离相对固定,例如手持电话的一个麦在下端,一个在背面[10-11],那么衰减系数也相对不变。此时,可预先对B进行测量,以保证B为已知。至此,确定式(11)、式(12)为本文语音增强的SSM方程,其中式(11)中状态过渡矩阵仅仅是常数1,相比于式(1)的AR-Kalman的状态过渡矩阵A具有更小的维度。
3.2 卡尔曼滤波法
在式(11)、(12)的SSM方程中,由于状态方程和测量方程均为线性函数,因此可以直接采用卡尔曼滤波来估计隐藏状态X k,从而得到语音信号Sk以完成语音增强。又由于ωk和μk均为高斯白噪声矢量,因此卡尔曼滤波可以保证在贝叶斯准则下估计的隐藏状态X k为最优。下文算法步骤给出了本文提出的MMKA步骤,其中引入了符号k|k和k+1|k,表示为给定观测值Y k下对第k时刻和第k+1时刻参数的估计和预测。例如,X̂k|k表示给定观测值Y k下对X k的估计值,X k的最终估计值就由X̂k|k来表示。
算法步骤
输入 观测值为带噪语音信号,即Y k=[y1ky2k…y Nk]T。
已知参数 过渡矩阵为单位矩阵A k=I,测量矩阵B k=B,动态噪声的协方差矩阵Qω,测量噪声的协方差矩阵Qμ。

3.3 最小二乘法
为进一步减少计算复杂度,本文采用最小二乘估计(Least Square,LS)X k来实现语音增强。根据式(12),若混合矩阵B为已知,LSSE表示为:

此时可使白噪声μk的平方对估计造成的影响减少至最小。另外一方面,NC算法将两个麦克风的语音相减,即使能把工业噪声消除,但两个麦克风的白噪声不尽相同,白噪声无法消除,仍然会影响语音的增强性能。
3.4 算法复杂度分析
本节将给出本文提出的语音增强算法与已有算法的一些相关参数,以此说明各算法的计算复杂度。MMKA和ARKalman都采用卡尔曼滤波来对语音信号增强,其复杂度与其状态方程的过渡矩阵密切相关。对于状态过渡矩阵维度,MMKA中,其过渡矩阵为常系数1,因此维度为1×1。对于AR-Kalman算法,其SSM引入了AR建模,因此其过渡矩阵维度为J×J,其中J=p+r,p和r分别为是Sk和Nk的AR模型阶数。由于后者的过渡矩阵维度更大,因此导致采用卡尔曼滤波时的计算复杂度较高。
除此之外,对于各算法的循环次数:FastICA的解混矩阵需要反复循环Kf次才能收敛,通常有Kf>1。并且,FastICA每次循环中计算高阶统计量需对K个数据同时处理,因此只有K个时刻的语音接收完毕才能进行处理,影响了实时性。MMKA、LSSE、NC和AR-Kalman算法均由第k时刻观察值Y k可直接得到语音信号Ŝk,因此不需要循环,其循环次数均为1。
最后,NC和LSSE两种算法既不需要ICA类算法进行循环来收敛,也不需要卡尔曼滤波算法进行迭代,计算复杂度较低。LSSE复杂度集中在对混合矩阵求伪逆,其乘法次数为N3量级,其中N是混合矩阵B的维度。NC是将两个麦克风信号相减,不涉及乘法,复杂度更低。
4 实验与分析
4.1 实验数据
本实验数据为公开数据,纯净语音信号来源于IEEE语音库 ,下 载 网 址 :https://www.cs.columbia.edu/~hgs/audio/harvard.html,本文选取的纯净语音信号为男性所朗读一句英文 :The birch canoe slid on the smooth planks,采 样 率25 000 Hz,时长3.1 s。两段噪声信号factory1.wav和factory2.wav来源于Noisex-92数据库,下载网址为http://spib.linse.ufsc.br/noise.html,其中第一段为工厂车间切板和电焊设备所产生的噪声,第二段为汽车生产车间所产生的噪声,两者的采样率均为16000 Hz,时长235 s。
实验中所使用的噪声信号为从factory1.wav和factory2.wav中随机截取,并使其与纯净语音信号的时长和采样频率等时长,最终的信号长度均为K=77 499,采样率fs=25 000 Hz。然后,对语音信号和噪声信号做归一化处理后得到Sk和Nk。
麦克风采用双麦克风设置,因此衰减系数B为2阶方阵。把Sk和Nk经过不同的线性叠加信噪比和B进行线性叠加并加入高斯白噪声得到观测信号Y k。为了接近真实的工业噪声环 境 ,本 文 设 置 衰 减 系 数 矩 阵B=[αβ]=[0.5 0.8;0.1 0.9],此时的纯净语音信号几乎淹没于噪声之中,达到人耳基本无法分辨的程度。最后,利用语音增强算法对Y k处理得到增强后的语音信号对归一化之后进行相关实验指标的分析。
4.2 实验设置
实验中,将本文提出的MMKA和LSSE算法与已存在的MMKA、AR-Kalman和FastICA算法进行对比,以评判本文算法的性能。除4.3.1节中语谱图的结果外,其余均为运行200次后结果的平均,其中选择factory1.wav或factory2.wav作为工业噪声各100次。以上相关算法的参数设置如下:
1)MMKA。过程噪声协方差Qω=[1 0;0 1],测量噪声协方差Qμ=[0.1 0;0 1],滤波误差协方差矩阵[1 0;0 1],初值。
2)FastICA。双麦克风设置,并且将带噪语音信号分为约40段,对每段进行盲分离,则处理的延迟时间为每段语音占用时间与盲处理该段语音占用时间之和,以确保处理的实时性。
3)AR-Kalman。单个麦克风设置,Sk和Nk的AR模型阶数p=r=10,帧长l=500,帧移比例ξ=40%(相邻帧的重叠值),卡尔曼滤波的
过程噪声协方差Qω=0p×p,测量噪声协方差Qμ=0p×p,滤波误差协方差矩阵,初值。
4)NC。双麦克风设置。
5)LSSE。双麦克风设置,伪逆矩阵采用B†。
在对比中,本文分别测试了在不同输入语噪比(输入的语音信号与工业噪声功率之比)SNRi和输入信噪比(输入的语音信号与高斯白噪声功率之比)SNRw下的输出语噪比(增强后输出的语音信号与残留噪声功率之比)SNRo的性能,分别定义如下:
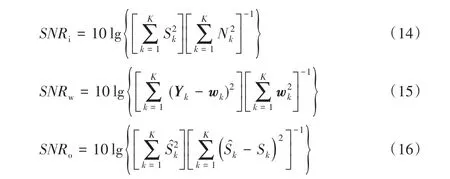
另外,实验还给出了主观语音质量评估(Perceptual Evaluation of Speech Quality,PESQ)[20]和算法运行时间等指标。
4.3 实验结果
4.3.1 语谱图
图4给出了语音增强前后的语谱图,其中图4(a)给出纯净语音信号的语谱图,图4(b)和(c)给出了两个麦克风接收的带噪语音信号的语谱图,其工业噪声为factory1.wav在SNRi=5 dB时得到,白噪声为SNRw=30 dB时得到(factory2.wav情况类似)。通过对比,图4(b)和(c)中带噪语音在频率2 000 Hz以下具有较大的功率,其他频率段功率较小,但无论在哪个频率段,功率分布均匀、没有显著的差异,这表明语音的功率已淹没于噪声功率之中。
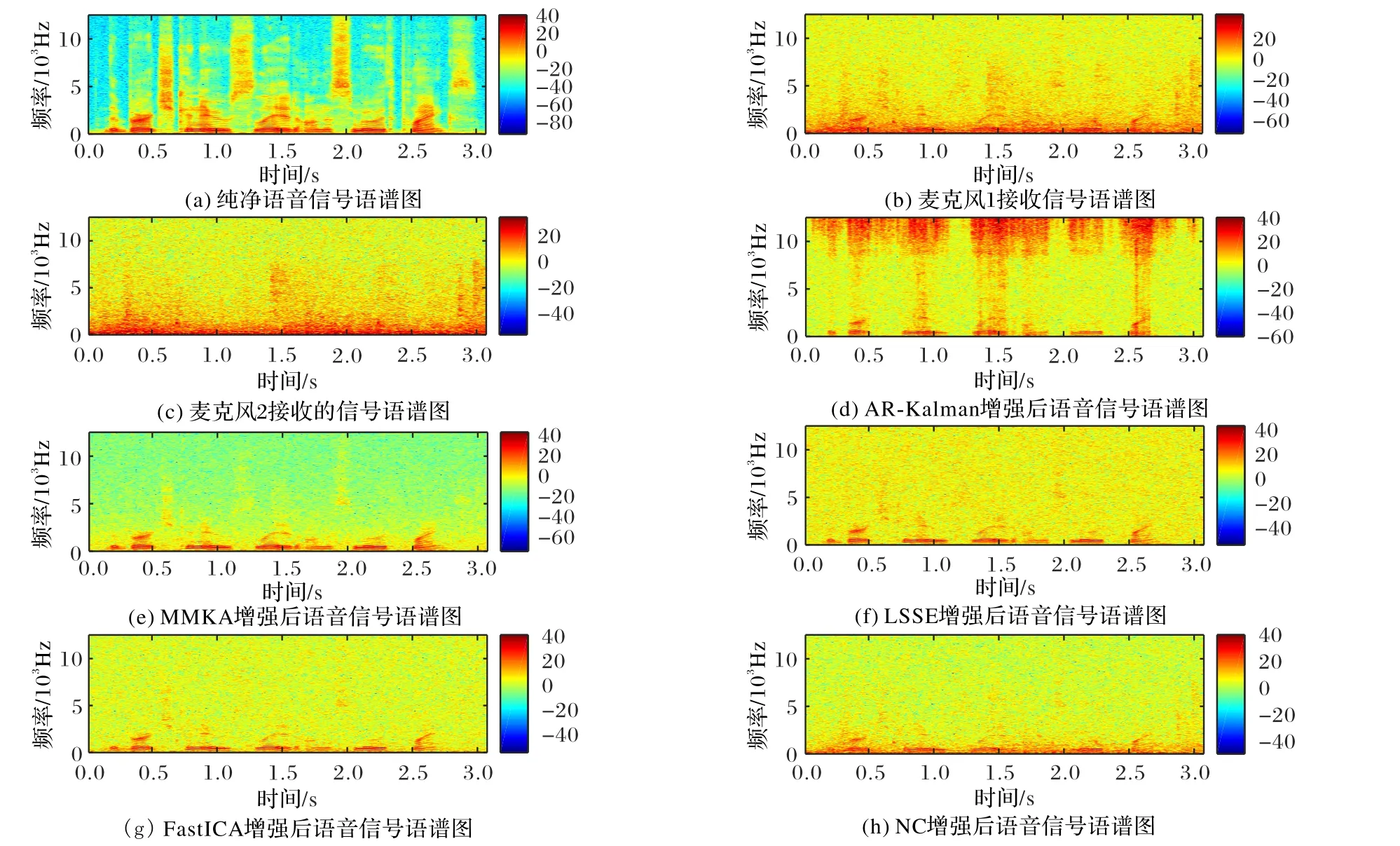
图4 含有高斯白噪声的带噪语音信号经不同算法增强后语音信号语谱图对比Fig.4 Speech signal spectrogram comparison of noisy speech signal containing Gaussian white noise enhanced by different algorithms
由图4(d)可以看出,AR-Kalman算法增强后的语音信号在0.5、1、1.5、2.5 s时刻和1 000 Hz频率附近处有较大功率,其功率分布与纯净语音信号的语谱图一致。同时,图4(f)~(h)中通过MMKA、LSSE和FastICA增强后的语音信号在1 000 Hz附近的功率分布也与纯净语音信号的一致。该结果表明,经过以上算法增强的语音信号在低频段确实保留了原纯净语音信号的功谱分布特性。除此之外,图4(h)的NC算法得到的增强语音在1 000 Hz处,功率在各时刻上分布较为均匀,因此可推知它还原纯净语音信号的语谱特性较弱。另外,从图4还可以注意到,以上几种算法在5 000 Hz附近的功率在各时间段的分布较为均匀,与纯净语音信号的语谱不太一致。然而,由于人耳对1 000~3 000 Hz的语音信号最为敏感[20],因此,该频段信号对语音通信的干扰不会很大。
4.3.2 信噪比和PESQ
图5给出了各算法在不同SNRi和SNRw下SNRo的性能对比,从图中可以看到,除FastICA算法以外的几种算法的SNRo曲线由上到下排列大致为:MMKA、AR-Kalman、LSSE和NC,造成这一结果的原因如下:NC将两个麦克风信号相减仍然无法完全消除工业噪声信号和白噪声信号,因此输出信噪比值较低;LSSE通过对混合矩阵求逆可以较好地消除工业噪声,因此输出信噪比高于NC;但是,LSSE只能在最小二乘原则上去消除白噪声的影响,而卡尔曼滤波是在最优贝叶斯准则下消除白噪声的影响,因此,其输出信噪比低于AR-Kalman和MMKA;另外,MMKA采用双麦克风建模,相较于单麦克风AR-Kalman的输出信噪比值要高;FastICA算法情况稍显复杂,它采用盲分离对带噪语音进行增强,若将白噪声也看成一个源信号,那么源信号数将变为3,此时分离的信号将不可避免产生信号混叠,因为接收的麦克风数只有2,因此,当白噪声SNRw小于5 dB时,其输出SNRo低于其余几种算法。
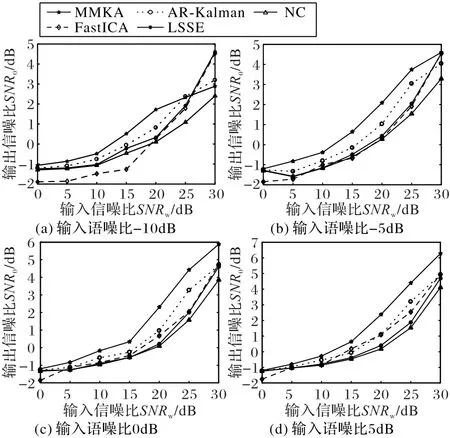
图5 含有高斯白噪声的带噪语音信号在不同算法下的输出语噪比Fig.5 Output speech-to-noise ratio of noisy speech signal containing Gaussian white noise under different algorithms
图6给出了各算法在SNRw=30 dB下,PESQ随SNRi从-10 dB变化至5 dB的曲线。从图中可以看到,当SNRi大于-5 dB时,各算法的PESQ值由高到低的排列顺序基本与图5的一致,这也表明各算法在不同评价指标下所展示的性能具有一致性。

图6 不同算法增强语音信号的PESQ对比Fig.6 Comparison of PESQof speech signal enhanced by different algorithms
4.3.3 算法运行和延迟时间
表1给出了各算法对带噪语音信号进行增强的平均运行时间和算法的延迟时间(当前时刻的带噪语音需要多长时间才能得到增强后的语音),以评判各算法的时间复杂度和各算法的实时性能。在实验中,运行的计算机采用ThinkPad E520,处理器为Intel Core i3-2350M,内存4 GB,操作系统为64位Microsoft Windows 10专业版,处理的软件为MatLab2017b。
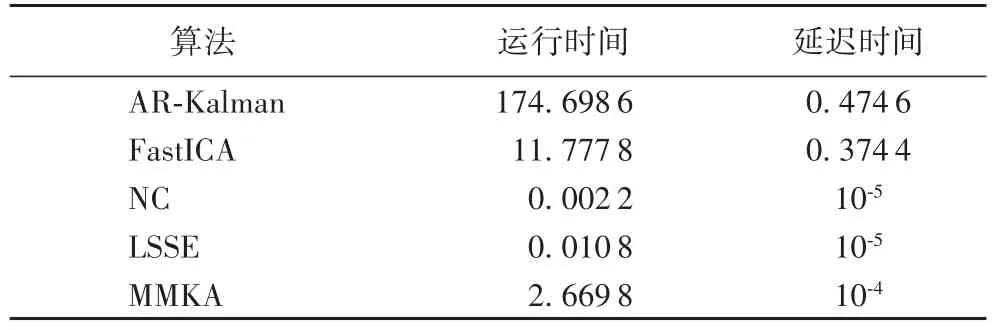
表1 不同算法运行时间与延迟时间的对比 单位:sTab.1 Runningtimeand delay timecomparison of different algorithms unit:s
从表中算法运行时间可见:AR-Kalman的运行时间最长,达到了约175 s,其原因在于它首先需要对信号进行分帧处理,同时还需要对Sk和Nk进行AR建模,而AR建模也需较多的耗时;FastICA运行时间其次,因为它也需要对信号进行分帧处理以保证实时性,同时每一帧信号的处理都需要多次循环以保证收敛;MMKA的运行时间介于NC、LSSE与ARKalman、FastICA之间,该结果与3.4节复杂度分析的一致,即NC和LSSE算法的计算复杂度相对较小,因此所需的运行时间也较少。
而由表中算法延迟时间可知:AR-Kalman滤波采用分帧处理方式,最终得到的增强语音信号是每个帧处理的结果,因此延迟时间为相邻帧重叠部分占用时间与处理该重叠部分占用时间之和;FastICA也采用分帧处理,其延迟时间也是每个帧时间与处理时间之和。因此,该两种算法具有较大的延迟时间;相反,MMKA、NC和LSSE根据每个采样点进行处理,延迟时间仅为对每一采样点信号处理的运行时间,因此延迟时间较少。
多次实验的结果表明,本文提出的卡尔曼算法,即MMKA的输出语噪比平均比传统的AR-Kalman提高约2 dB,而运行时间只有不到其2%。特别地,本文的卡尔曼算法也具有较少的延迟时间,与FastICA平均接近0.4 s的延迟时间相比,MMKA的延迟时间仅是毫秒级别。另外,结果也表明MMKA与较为简单的NC算法相比会有较长的运行时间,但是,本文提出的最小二乘算法,即LSSE算法的运行时间与NC的相当,均是毫秒级别,但输出语噪比平均要比NC高出约1 dB。
5 结语
针对工业噪声环境,本文研究了采用多麦技术的语音增强算法,从降低算法复杂度和提高实时性的角度提出了卡尔曼滤波和最小二乘的算法。实验利用了公开数据库的语音信号和噪声信号来得到最后的带噪语音信号,以此评判本文提出的算法与传统算法的输出语噪比,运行时间和延迟时间等性能,实验结果表明所提出的算法达到了降低算法复杂度和提高实时性的要求。
本文只使用了两个麦克风,增强后的语音信号还含有一定的噪声,如何使用多个麦克风利用深度学习算法训练噪声参数进一步提高语音增强效果和处理的实时性需要进一步研究。
