基于自编码器和隐马尔可夫模型的时间序列异常检测方法
2020-06-07霍纬纲王慧芳
霍纬纲,王慧芳
(中国民航大学计算机科学与技术学院,天津300300)
(∗通信作者电子邮箱wghuo@cauc.edu.cn)
0 引言
时间序列异常检测是时序数据挖掘的重要研究问题之一,已被广泛地应用于航天[1]、金融[2]、医疗[3]等领域。隐马尔可夫模型(Hidden Markov Model,HMM)作为一种动态时间序列统计分析模型,最早在20世纪60年代末引入和研究。由于其强大的数学基础理论和完善的算法,HMM成为语音识别[4]、经济分析、机械工程等领域的主流技术。Rabiner[4]验证了HMM对具有时序性信息的识别能力较强。近年来,HMM方法已被成功引入到时间序列的故障诊断[5]和异常检测领域[1-3,6]。
基于HMM的时间序列的异常检测方法一般主要包含两个重要步骤:1)符号化可观测时间序列;2)参数学习与概率估计。符号化时间序列作为时间序列表示方法之一,旨在以字符串序列表示原始时间序列。符号化时间序列不但可以达到以低维数据表示高维数据的目的,而且符合HMM算法对观测序列的要求。目前符号化时间序列的方法主要有分段符号化线性表示法[7]和聚类符号化表示方法[8-10]。分段符号化线性表示方法是将原始时间序列分段,并以时域和频域信息表示为符号序列。文献[7]将HMM应用在心电图(ElectroCardioGram,ECG)医疗数据的阻塞性睡眠呼吸暂停(Obstructive Sleep Apnea,OSA)病情检测中,该方法选取均值、方差和偏度等信息构成符号化序列,但是在转化的过程中需要大量的先验知识和丰富的实验经验,这不满足现实对于时间序列异常检测的需要。聚类符号化表示方法采用聚类的方法将时间序列的连续实数值映射到有限的符号表上,使得时间序列转化为有限符号的有序集合[11]。文献[8]将HMM应用在飞机着陆操作数据的异常检测中,采用K-means聚类算法将原始时间序列转化成由K个簇标记表示的符号序列;文献[9]将聚类HMM应用在快速存取记录器(Quick Access Recorder,QAR)数据分析的研究中,采用二次广度优先邻居搜索聚类算法将原始序列转化成由聚类的符号表示的符号序列;文献[10]将HMM应用在多维时间序列上的异常检测中,分别采用模糊C均值(Fuzzy C-Means,FCM)聚类和模糊积分技术将多维时间序列转换成单维的符号序列,且提高了HMM的异常检测能力。
符号化序列分析的结果主要由符号化算法和时间序列的相空间轨迹决定。值得注意的是,如果使用原始时间序列中的所有数据进行分析,在符号化过程之前不进行特征提取,符号序列可能过长,噪声的干扰对计算效率会造成影响[12]。上述文献[7,8-10]在符号化步骤之前均无特征提取过程。文献[12]结合感知重要点(Perceptually Important Point,PIP)[13]和HMM实现对液压泵的故障诊断,该方法寻找对原始时间序列整体运动形状影响较大的数据点,减少了时间序列压缩过程中的信息损失,再根据重要点在符号空间位置划分区域实现符号化。文献[14]采用奇异值分解代替主成分分析中的特征分解对含有高维度的流量数据包进行降维,再应用K-means方法为HMM创建有意义的观测序列。以上两种方法都是在符号化序列之前,对分段后的原始序列进行特征提取和数据降维,并在故障分类和入侵检测的准确度中取得了较好的效果。但是基于感知重要点技术的符号化方法需要计算每个点对于时间序列的影响力,复杂的计算过程降低了异常检测的效率,而基于改进主成分分析的符号化方法在特征提取时会将数据方差较小的数据信息忽略,使得模型对非线性特征提取效果较差。
自编码网络是Hinton在2006年提出的一种由编码器和解码器构成的无监督学习算法,旨在从大量无标记的数据中学习数据的有效信息,并实现对输入数据的非线性压缩和重构[15]。为克服目前已有HMM建模时间序列符号化过程中特征提取方法的不足,本文通过自编码器提取时间序列片段中的非线性特征。具体方法为:通过滑动窗口对时间序列样本进行分段,据此生成若干时间序列分段样本集,由正常时间序列上的不同位置上分段样本集训练自编码器。利用训练后的自编码器得到每个分段时间序列样本的低维特征表示。低维特征表示向量集采用K-means算法进行聚类处理,从而实现时间序列样本集的符号化。正常时间序列的符号序列集构建HMM,并通过待测样本在生成的HMM上的输出概率值进行异常检测。单变量和多变量时间序列数据集上的实验表明了文中所提方法具有较好的异常检测效果。
1 AHMM-AD方法
本文提出的基于自编码器和HMM的时间序列异常检测(Autoencoder and HMM-based Anomaly Detection,AHMM-AD)方法的具体流程如图1所示。该方法首先把样本集划分为带有正常时间序列样本的训练集、带有正常和异常时间序列样本的验证集和测试集;其次采用滑动窗口将正常时间序列样本集进行等长有重叠分段,由相同位置的正常时间序列片段样本集训练自编码器,训练集样本通过训练后的自编码器进行特征表示,并得到低维特征表示向量集;然后采用K-means聚类算法对向量集进行聚类处理,并实现对训练集样本的符号化;最后采用Baum-Welch算法对样本符号化序列集进行HMM建模,得到HMM的模型参数。验证集和测试集的样本经过与训练集相同的符号化处理过程得到符号化序列。验证集的每个样本通过训练完成的HMM计算输出概率,并在输出概率的最大值和最小值之间均匀划分1 000个值,根据F1值最大原则来确定阈值。根据测试集样本符号化序列的输出概率和验证集样本计算所得阈值对测试集进行异常检测。
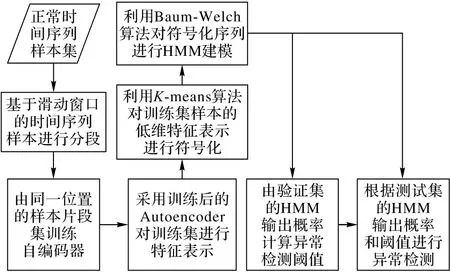
图1 本文时间序列异常检测方法流程Fig.1 Flowchart of the time series anomaly detection method in thispaper
1.1 基于滑动窗口的时间序列分段
时间序列的分段方法通常有两种:序列关键点(间断点和突变点)分段[12,16]和等长有重叠时间窗口分段[11,17-18]。第一种方法通过序列中的间断点和突变点来分段描述时间序列,然而当数据在连续上升或下降的幅度较小时,序列存在的转折点或突变点无法识别[9],这将会影响时间序列的分段表示。为此,大部分的方法研究采用第二种方法将原始时间序列创建为固定大小的段。这样的方法不仅能够保证将持续时间较长的数据模式被完整地分割出来[17],还保持了原有时间序列数据在时序上的依赖性[11]。文献[11]采用固定滑动窗口的方法分段并分析分段中存在的形态模式特征,较好地实现时间序列局部特征的符号化。文献[17]采用有重叠滑动窗口分段视频数据,并建立行为识别模型。本文采用等长有重叠时间窗口分段方法的具体实现为:设包含N个多维时间序列的样本集记为其中单个长度为T的样本可表示为表示第n个样本t时刻m维的向量。样本集中每个样本X n应用滑动窗口以窗口大小w和步长s滑动截取,样本的划分表示如下:
其中:X sn表示第n个样本片段集,表示分段后第n个样本的第i个时间序列片段,f(x)表示滑动窗口函数,d为切片后的时间序列的片段总数,d=(T-w)s+1。
1.2 基于autoencoder的时间序列符号化
自编码器能够在压缩高维数据的同时保留数据中重要特征,本文采用多个自编器提取不同时间序列片段中的特征。图2为本文的自编码器训练过程示意图。
3.2.4 性传播疾病(sexually transmitted diseases,STD) STD患者生殖道黏膜常有破损和炎症反应,HIV靶细胞--CD4+细胞常浸润在此,为HIV入侵提供了有利条件[19],而有生殖道感染的HIV患者,其生殖道分泌物中的HIV病毒含量也会显著增加[26],从而增加HIV感染风险。有研究发现阴性配偶最近一年有生殖道异常的HIV感染风险增加3.74倍(HR=3.74,95%CI:1.05~13.33)[25]。
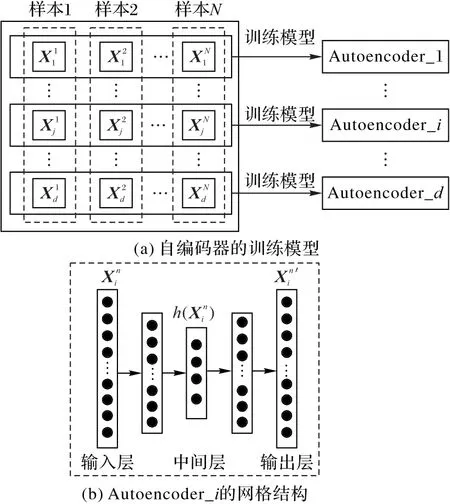
图2 自编码器训练过程示意图Fig.2 Schematic diagram of training process of autoencoder

第n个样本X sn经自编码器特征表示后得到的特征序列

1.3 本文的时间序列异常检测算法
本文时间序列异常检测的算法具体为:HMM是由隐藏状态序列和观测序列构成的双重随机过程,序列的每一个位置对应一个时刻的隐藏状态和观测状态。HMM由G,M,π,A,B来确定,其中,G表示HMM的隐藏状态集合;M表示时间序列符号化后有限的观测状态集合,且M中的观测状态个数由肘部方法确定;π表示初始状态概率向量,是由各个隐藏状态的初始概率组成;A表示状态转移概率矩阵,是由隐藏状态之间的转换概率组成;B表示输出概率矩阵,是由隐藏状态下输出观测值的概率组成。
文中将样本集按比例划分为训练集Xtrain、验证集Xval和测试集Xtest。Xtrain用于训练HMM,目的在于对训练集的正常时序行为建模。由1.2节描述的基于autoencoder模型的符号化方法处理Xtrain,得到训练集的样本符号化序列Otrain。由于在HMM的训练数据只包含观测序列没有对应的隐藏状态序列,所以HMM的训练过程运用非监督学习算法——Baum-Whelm算法,学习HMM的参数λ=(π,A,B)。验证集Xval用来计算本文异常检测方法的阈值τ,测试集Xtest用来测试本文方法的异常检测效果。Xval和Xtest同样经符号化处理后得到Oval和Otest,并依次输入到训练后的HMM中,计算每个样本的输出概率。在验证集样本的输出概率的最大值与最小值之间均匀划分1 000个值作为异常检测的阈值候选值,F1值最高时所取的τ值即为本文方法的阈值,F1值的计算如式(4)~(6)所示。测试集的符号化样本序列Otest计算的输出概率表示为Ptest={ptest1,ptest2,…,ptestn,…,ptestN},其中ptestn表示测试集的第n个样本的输出概率。结合阈值τ,当ptestn<τ时,判定当前样本为异常样本;否则,判定其为正常样本。由于本文是采用正常时间序列建模,所以ptestn的值越小表示发生异常的可能性越大。

其中:TP(True Positives)表示检测为正常的正常样本数;FP(False Positives)表示检测为正常的异常样本数;FN(False Negatives)表示检测为异常的正常样本数;TN(True Negatives)表示检测为异常的异常样本数。
算法描述如下所示:
输 出 测 试 集 样 本 的 输 出 概 率Ptest={ptest1,ptest2,…,ptestn,…,ptestN}。


将最大F1值对应的概率值Pvaln作为文中的阈值τ;在(min(Pval),max(Pval))范围内均匀划分1000个值,将每个值作为异常检测阈值,根据式(4)、(5)、(6)分别计算Xval上的F1值;将最大F1值对应的概率值Pvaln作为文中的阈值τ;


2 实验与分析
2.1 实验设置
为验证本文方法的有效性,选用了6个数据集进行实验。数据集描述如下:
1)雅虎(Yahoo)数据集是记录Yahoo会员的登录状态的单维时间序列数据集。样本数目300,每个样本长1420,样本异常率为33.33%(https://webscope.sandbox.yahoo.com/)。
2)电力需求(Power Demand)数据集是记录一个家庭一年的电力需求的单维时间序列。实验中将长为35000的数据集等长截为100个样本,每个样本长350,样本异常率为9%(https://www.cs.ucr.edu/~eamonn/discords/)。
3)呼吸(Respiration)数据集是记录病人醒来时胸腔扩张频率的单维时间序列。实验将长为42 000数据集等长截为140个样本,每个样本长300,样本异常率为7.86%(https://www.cs.ucr.edu/~eamonn/discords/)。
4)简易电子传输协议(Simple Mail Transfer Protocol,SMTP)数据集是记录网络流量和攻击手段的三维时间序列。实验将长为95 040数据集等长截为264个样本,每个样本长360,异常样本占有率7.86%(https://www.openml.org/)。
5)基于多传感器数据融合的活动识别系统(Activity Recognition system based on Multisensor data fusion,AReM)数据集记录了一个人七种动作的六维时间序列数据集,样本数目78,每个样本长480,实验使用动作类型作为标签,其中将走路动作的15个样本作为异常样本,样本异常率为19.23%(https://archive.ics.uci.edu/ml/datasets/)。
6)美国国家航空航天局飞行(NASA Flight)数据集是美国宇航局在多核异常检测(Multiple Kernel Anomaly Detection,MKAD)项目中记录B_777飞机飞行过程的五维时间序列数据集。样本数目300,每个样本长1000,样本异常率为4%(https://c3.nasa.gov/dashlink/resources/136/)。
实验的软件环境为:tensorflow1.10.0,Python3.6.2,Windows10 64位操作系统;硬件环境为:Intel Core i7-3770处理器,4 GB内存。
2.2 参数选取
影响本文异常检测方法的性能主要有两个参数:一个是时间序列分段个数d;另一个是符号化序列所需符号的个数K。下面以Yahoo数据集的实验为例,讨论上述两个参数的选择过程。
实验选择10~50长度范围的重构序列来测试计算效率、平均重构误差和F1值,结果如表1。从表1中可看出,当样本序列随着时间序列分段个数的增多,训练时间将会变长,但时间持续较短对模型整个训练影响较小;平均重构误差也相差较小;F1值在序列长度为23时最高为0.63,综合分析Yahoo数据集的重构长度可设置在20~30范围内较为合适。
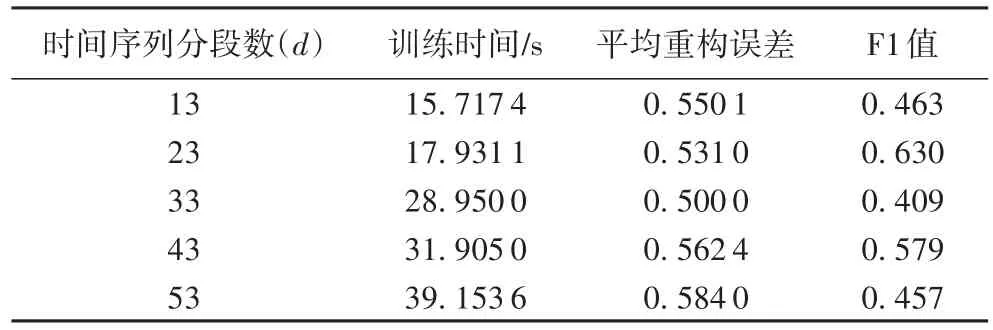
表1 时间序列不同分段个数的实验结果对比Tab.1 Experimental results comparison of different time series segmentation number
实验使用K-means聚类方法对经过特征表示的样本序列进行符号化,K值由肘部方法确定。图3为Yahoo数据集在对比实验基于HMM异常检测方法中符号化的肘部曲线,当K=8时,平均畸变程度变化较高,即符号个数取为8。图4是该数据集在本文异常检测方法中符号化的肘部曲线,由图4可看出K值被确定为40。
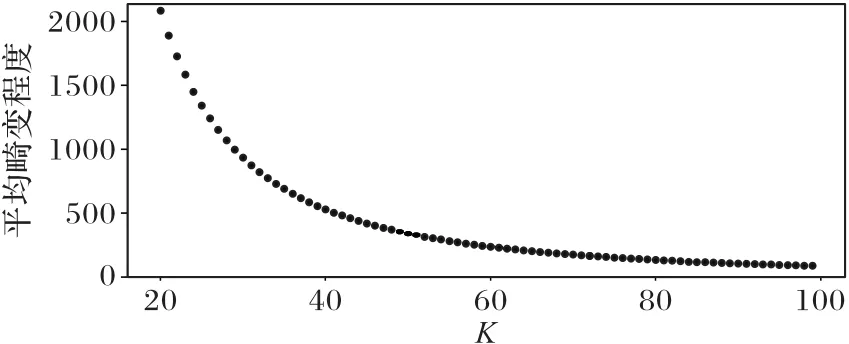
图3 肘部方法确定基于HMM异常检测方法的K值实验图Fig.3 Experimental diagram of K value of HMM-based anomaly detection method determined by elbow method
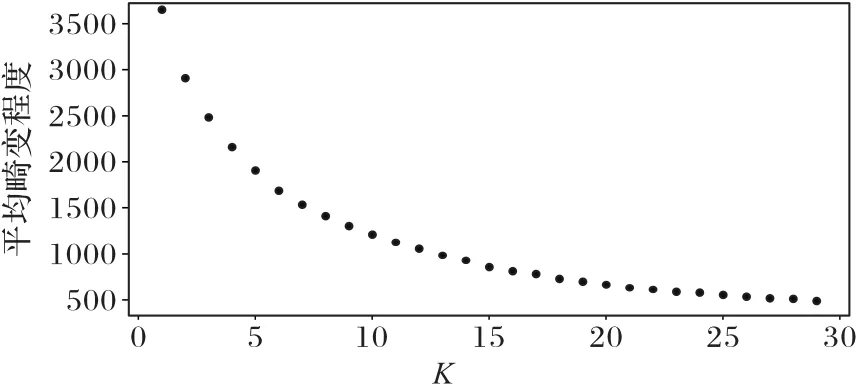
图4 肘部方法确定本文方法的K值实验图FIG.4 Experimental diagram of K valueof themethod in this paper determined by elbow method
按此原理,所有数据集上的时间序列分段个数d和符号化序列所需符号个数K值设置如表2所示。
2.3 实验结果与分析
实验中对比方法有:基于HMM的时间序列异常检测的方法 (Hidden Markov Model-based Anomaly Detection,HMM-AD)[8],该方法中采用聚类方法对原始时间序列聚类处理并进行符号化;基于自编码器模型的时间序列异常检测方法(Autoencoder-based Anomaly Detection,AE-AD)[19],该方法通过学习重构正常的时序行为,并利用重构误差检测异常。采用精确率(Precision)、召回率(Recall)和F1值作为异常检测的评判标准。实验结果如下:
1)在Yahoo、Power demand和Respiration三个单变量时间序列上的实验结果如表3所示。从3个数据集的实验结果可以看出,本文提出的AHMM-AD方法均取得了较好的结果。与HMM-AD模型相比,本文方法在3个数据集的检测中,Precision、Recall和F1值均有所改进,对比实验结果说明仅仅在原始数据进行符号化分析,不能避免噪声的负面干扰,但是在符号化之前的特征表示有利于符号化过程对原始时间序列的表征。然而,与AE-AD方法相比,本文将autoencoder融合于HMM的方法在3个数据集的F1值平均提高0.339,表明先采用自编码器对样本片段分别进行局部提取表示,再用HMM对低维的样本片段建模的方法在时间序列异常检测中是有效的。
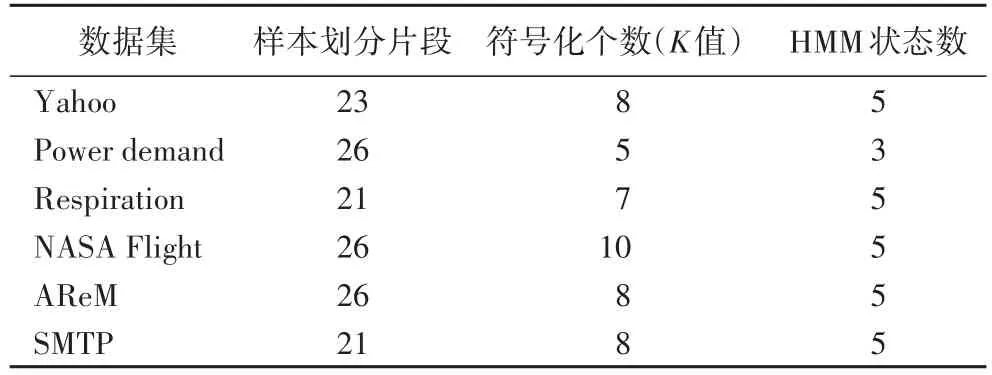
表2 实验参数设置Tab.2 Settingof experimental parameters
2)在NASA Flight、SMTP和AReM三个多变量时间序列的实验结果如表3所示。从表中可看出,AReM数据集的检测效果在多变量时间序列中表现最好,其原因是该数据集的异常样本是不同于正常样本的行为动作,异常样本模式突出。值得注意的是,AE-AD模型在多变量时间序列的检测效果没有和单变量时间序列的样本的一样优于HMM-AD,因此,HMM-AD模型在多变量时间序列的异常检测中有一定的优越性。而本文所提出的模型与HMM-AD模型相比,在Recall值上具有较高的检测得分,分别为0.916,0.700和0.890,且在F1值也有明显的提高。实验表明了文中的AHMM-AD能在HMM-AD的基础上能进一步提高在多变量时间序列集上异常检测效果。

表3 单变量和多变量时间序列实验结果Tab.3 Experimental results of univariate and multivariate time series
3 结语
针对已有基于隐马尔可夫模型的时间序列异常检测模型的符号化方法不能很好地表征原始时间序列的问题,本文提出了基于自编码器和HMM的时间序列异常检测方法。该方法利用自编码器对时间序列片段的特征表示优化符号化方法,进而提高了HMM表达正常时间序列的建模能力。在单变量和多变量时间序列上的实验表明了文中方法的有效性。由
于本文方法在对时间序列片段的特征表示过程中没有考虑片段内的时序关系,下一步将采用长短时间记忆网络学习时间序列片段的特征表示,以进一步提高文中所提方法的异常检测效果。
