基于图上随机游走的离群点检测算法
2020-06-07杜旭升叶乐乐陈嘉颖
杜旭升 ,于 炯 ,*,叶乐乐 ,陈嘉颖
(1.新疆大学软件学院,乌鲁木齐830008; 2.新疆大学信息科学与工程学院,乌鲁木齐830046;3.西安交通大学软件学院,西安710049)
(∗通信作者电子邮箱yujiong@xju.edu.cn)
0 引言
离群点是指那些在数据集中偏离大多数对象,让人不得不怀疑它是由某种不同于其他大多数对象的机制所产生的数据对象[1]。换言之,数据集中的绝大多数对象都服从某种确定的模式P,而离群点是那些不服从模式P的数据对象[2]。离群点检测常用于如网络入侵检测、医疗辅助诊断、金融欺诈检测、交通流中异常行为检测、变质农畜产品检测等,在天文学中离群点检测也被用来发现新天体[3-7]。
传统的无监督离群点检测算法,如基于距离的LDOF(Local Distance-Based Outlier Factor)、CBOF(Cohesiveness-Based Outlier Factor)及基于密度的 LOF(Local Outlier Factor)算法在检测高维数据集和大规模数据集时,存在检测率低、算法执行时间长、对参数敏感等问题。针对上述问题,本文提出了一种基于图上随机游走(Based on Graph Random Walk,BGRW)的离群点检测算法。
基于图上随机游走的离群点检测算法,将待检测数据集中的数据对象建模为图中的顶点,图上各顶点相连边上的权重表示漫步者由某一顶点出发,一步移动到另一顶点的概率。BGRW算法通过计算数据集对象间的转移概率,并通过用户预设的迭代次数和阻尼因子,迭代计算出所有对象的离群值。在UCI(University of California,Irvine)真实数据集与合成数据集实验表明,BGRW算法与无监督检测算法相比,在检测率与执行时间和误报率等指标上效果具有明显的提升。
基于图上随机游走的BGRW离群点检测算法的主要创新之处在于:
1)提出了一种数据集中对象间的转移概率计算方法。对象之间的距离越远,则转移概率越大。
2)提出了利用漫步者在数据集中对象间的随机游走概率求解对象离群值的计算方法。通过计算数据集中对象经t步游走之后的离群值,对象的离群值越高,代表其越可能是离群点;相反,其越不可能是离群点。
1 相关研究
早期针对离群点检测的相关研究主要是为了消除数据集当中的噪声,以提高数据分析的质量[8],但“一个人的噪声可能是另一个人的信号”[9]。离群点不同于噪声点,噪声一般为数据随机分布中的随机误差,因此并不具有很大价值。而离群点由于其隐藏的可重复的产生机制,通过离群点检测发现数据集中的隐藏机制有着重要意义。现阶段人们检测离群点的主要目标是发现数据集中隐藏的有益信息或者未知的知识[10]。
目前主流离群点检测算法包括:1)基于聚类,2)基于单分类支持向量机,3)基于密度,4)基于自编码器,5)基于孤立森林,6)基于距离。
1)基于聚类的检测算法将离群点检测问题定义为聚类问题。算法通过计算对象与其最近簇的质心之间的距离,给数据集中每个对象的离群程度打分,得分越高,表示该对象越有可能是离群点。该算法主要缺点在于算法的主要目标是发现数据集中的簇,而不是离群点,因此检测效率较低,且算法针对性较强,较依赖于簇的个数[11]。
2)基于单分类支持向量机的检测算法通过学习数据集中绝大多数对象的边界,将边界以外的数据对象定义为离群点。该算法的主要缺点在于算法学习时间长,难以解决稀疏问题[12]。
3)基于密度的检测算法通过计算数据集中对象的局部密度和对象k近邻的局部密度,最后将对象与其k近邻局部密度相差较大的对象定义为数据集中的离群点。基于密度的检测算法主要缺点在于算法在高维数据集和大规模数据集中检测时间长、检测效率低,并且对序列数据和低密度数据不能有效度量[13]。
4)基于自编码器的检测算法首先训练一个输入尽可能等于输出的神经网络,然后将测试数据输入该神经网络进行重构,最后将重构误差最大的对象定义为离群点。该算法的主要缺点在于对数据量较小的数据集,神经网络不能充分学习到正常样本的特征,检测准确率低[14]。
5)基于孤立森林的检测算法通过利用一种名为iTree的二叉搜索树结构来孤立数据集中的对象。离群点会距离iTree的根节点更近,而正常对象会距离iTree的根节点更远。基于孤立森林的检测算法缺点在于树的划分主观性较强[15]。
6)基于距离的离群点检测算法是目前应用最为广泛的检测算法。算法通过计算数据集中两两对象之间的距离,然后计算对象与其k近邻的距离关系,最后得到对象的离群值。基于距离的检测算法主要缺点在于算法在高维及大规模数据集中检测效率低、必须使用全局阈值、检测结果对参数选择较为敏感[16-17]。
随着数据量的增长,现有离群点检测算法效率低的问题逐渐凸显,近年来部分学者提出了许多改进方法:袁钟等[18]针对传统离群点检测算法不能有效处理符号型与数值型属性混合的数据集中离群点的检测问题,提出了一种改进的基于邻域值差异度量的算法;王习特等[19]针对传统集中式的离群点检测方法计算时间长、检测效率低的问题,提出了一种高效的分布式离群点检测算法;Schiff等[20]将离群点检测技术应用到侦测医生对患者开具的处方药潜在的用药错误中,有效降低了患者的用药风险;Huang[21]利用离群点检测技术侦测电子商务系统中商家伪造买家评论,有效降低了评论造假现象;Alaverdyan等[22]将离群点检测技术应用到癫痫病灶的筛查中,为医生快速定位患者疾病提供了较好的解决方案。
2 基于图上随机游走的离群点检测算法
随机游走也称随机漫步,是随机过程的一个重要组成部分。基于图的随机游走是指给定一个图G和一个出发点v(0),漫步者从出发点v(0)开始,随机选择图G中的一个顶点移动,然后以该顶点为出发点,再重新选择一顶点进行移动,依此重复。漫步者在图G中随机选择的顶点集合构成了图中的随机游走。
在给出关于图上随机游走的BGRW算法的相关定义之前,先给出关于随机过程的相关定义与性质。
定义1 随机过程。设(Ω,F,P)为一概率空间,T和S为参数集。若对任意的t∈T,均有定义在(Ω,F,P)上的一个取值为S的随机变量X(ω,t)(ω∈Ω)与之对应,则称随机变量族X(ω,t)为(Ω,F,P)上的一个随机过程,记作{X(ω,t),ω∈Ω,t∈T},简记为{X(t),t∈T}。
定义2 马尔可夫链。若随机过程{X(t),t=0,1,…}对于任意的正整数n及t1<t2<…<tn∈T,其条件分布满足:
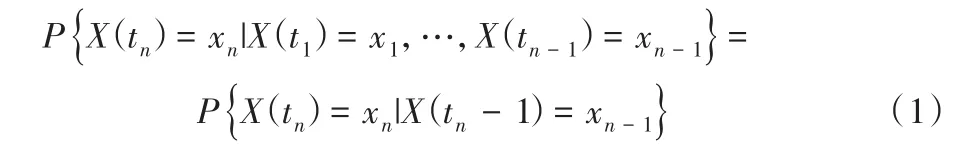
则称随机过程{X(t),t∈T}为马尔可夫链。
定义3 转移概率。称式(1)中的条件概率P{X(tn)=xn|X(tn-1)=xn-1}为随机过程{X(t),t∈T}的一步转移概率,简称转移概率。
性质1 转移概率。
随机过程的状态空间记作S,i、j∈S,则有:

定义4t步转移概率。随机过程经t步由状态i转移到j的概率记作:

称为马尔可夫链的t步转移概率,其中s≥0,t≥1。
2.1 BGRW算法的相关定义
设D={d1,d2,…,d n}表示输入数据的集合,其中di=表示数据集D中的任一数据对象,k表示输入数据的维度。dij表示对象di在第j个维度上的值,E(di,dj)表示数据集D中任意两个对象di,dj之间的欧氏距离。
定义5 顶点集。设V={v1,v2,…,vn}表示顶点集,其中vi表示图中的第i个顶点(在BGRW算法中也表示输入数据D中的第i个对象di),n表示V中所含顶点数。
定义6 边集。设ε={e1,e2,…,ek,…}表示图中各边的集合,ek=(vi,vj)表示顶点vi与顶点vj相连的边,其中ε⊆V×V。
定义7图。设G=(V,ε)表示图,若∀(vi,vj)∈ε,有(vj,vi)∈ε,则称G为无向图;相反,称图G为有向图。
定义8 转移概率矩阵。设wij=w(vi,vj)表示顶点vi,vj相连边上的权重,pij表示数据集D中对象di转移到dj的概率,则有。定义wij的计算方法如式(5)所示:

式(5)中:di、dj、dl表示数据集D中任意一个数据对象,n表示数据集D中所含对象的个数)表示对象di到数据集D中所有对象的欧氏距离之和。由式(5)可知,E(di,dj)占di到数据集中所有对象的距离之和的比值越大,则di转移到dj的概率越大。对象di转移到dj的概率并不一定等于由dj转移到di的概率,即wij≠wji。由wij组成的矩阵称为转移概率矩阵,记作W=[wij]n×n。
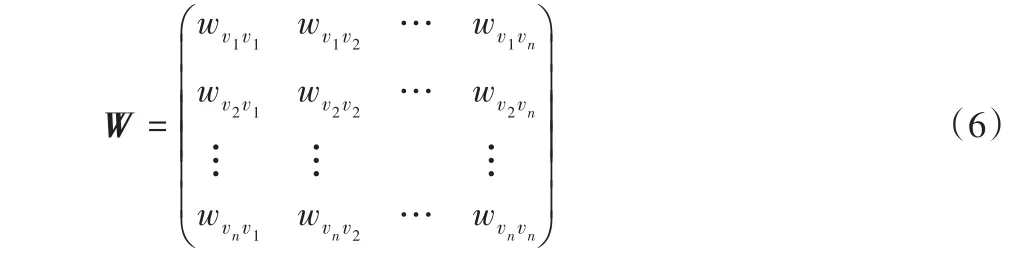
在转移概率矩阵W中任一元素wvi vj表示顶点vi转移到vj的概率,根据式(2)可知,矩阵W中的每一行总和为1。为避免在图中形成自循环,将顶点转移到自身的概率设置为0,即wvivi=0。
如图1所示,d1、d2、d3、d4为输入数据D中的4个对象,任意两个顶点相连边上的数字表示顶点间的一步转移概率。由任一顶点出发转移到图中其余所有顶点的转移概率之和为1。图1中若以d2为出发点,则漫步者下一步转移到d1的概率为2/14,转移到d3的概率为5/14,转移到d4的概率为7/14。图1中所有对象一步转移到d1的概率之和为2/14+4/18+1/17=0.423 9,转移到d2的概率之和为0.975 2,转移到d3的概率之和为1.4579,转移到d4的概率之和为1.1428。
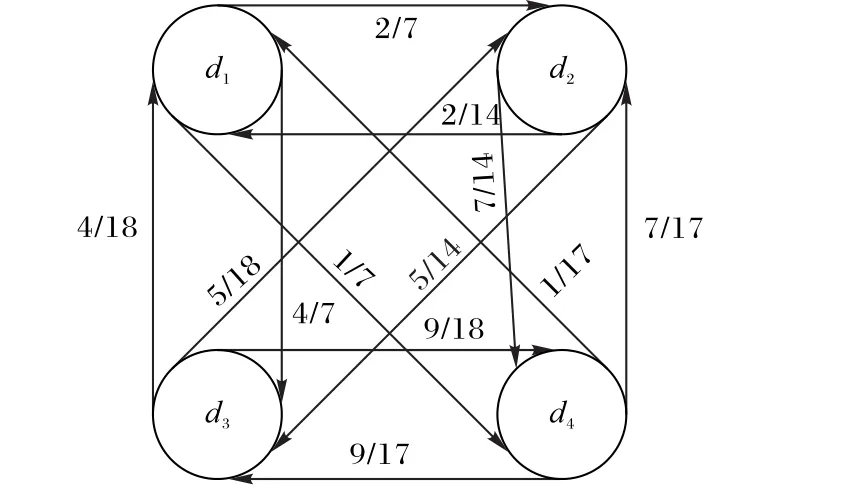
图1 基于图的随机游走示例Fig.1 Exampleof graph-based random walk
定义9 离群值矩阵OD。
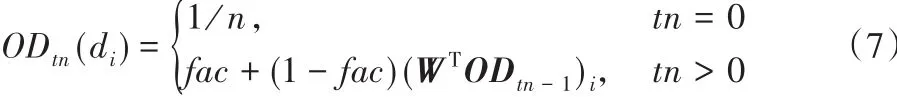
其中:tn为迭代次数,n为输入数据D含有的对象个数,fac为阻尼因子。OD tn-1表示在tn-1次迭代后,数据集D中所有对象的离群值构成的离群值矩阵,WT表示转移概率矩阵的转置。
阻尼因子fac在图中表示不以当前顶点为出发点进行随机游走,而重新选择另一顶点进行随机游走的概率。1-fac表示漫步者仍以当前顶点为出发点,再进行随机游走的概率,fac一般取0~1的一个较小值。(WTOD tn-1)i表示第tn-1次迭代运算后,数据集D中对象的离群值矩阵乘转移概率矩阵WT后第i行的值。
当tn=0时,BGRW算法初始化输入数据D中所有对象的离群值。WTOD tn=0如式(8)所示:
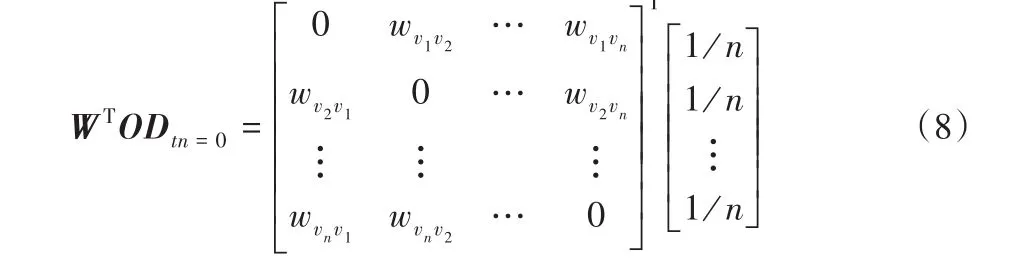
转移概率矩阵W是n×n矩阵,数据集D的离群值矩阵OD是n×1矩阵,二者相乘后所得WTOD矩阵是n×1矩阵,离群值OD矩阵中任意一行i的值表示数据集D中对象di的离群值。
基于图上随机游走的BGRW离群点检测算法,将输入数据建模为图中的顶点,各顶点之间的转移概率建模为图上各顶点相连边上的权重。BGRW离群点检测算法根据用户预设的迭代次数与阻尼因子,首先初始化待检测数据集D中所有对象的离群值,然后计算各对象之间的欧氏距离,并利用式(5)计算出各对象之间的转移概率,构建转移概率矩阵W。最后利用式(7)求得对象的离群值,将计算完成后离群值最高的前g个对象的编号输出。
2.2 BGRW算法描述


2.3 BGRW算法时间复杂度分析
在BGRW算法描述中,步骤1)~3)初始化数据集D中对象的离群值,时间复杂度为O(n);步骤4)~8)计算数据集D中两两数据对象之间的距离,时间复杂度为O(n2);步骤9)~13)运用式(5)计算对象之间的转移概率并构建转移概率矩阵,所需时间复杂度为O(n2);步骤16)~24)运用式(7)迭代计算每个对象的离群值,所需时间复杂度为O(n2);步骤25)中对数据对象的离群值排序,所需时间复杂度为O(nlbn)。综上可得BGRW算法的时间复杂度规模为O(n2)。
3 实验
3.1 实验环境及评价指标
实验的硬件环境为:Intel Core i7-7700 CPU 3.60 GHz,内存为16 GB。操作系统环境为:Microsoft Windows 10 Professional,算法的实现环境为:Matlab 2017A。
实验所用数据集分为真实数据集与合成数据集,真实数据集均采用UCI公开数据集,分别为:KDD-CUP99(Data Mining and Knowledge Discovery in 1999)、Glass Identification、WDBC(Wisconsin Date of Breast Cancer)、Shuttle。 为 验 证BGRW 算法的有效性,将其与 LDOF[16]、CBOF[17]、LOF[13]三种算法在各数据集中进行对比实验,采用准确率ACC(Accuracy)、检测率(Detection Rate,DR)、误报率(False Alarm Rate,FAR)以及执行时间(Execution Time,ET)作为算法性能的评价指标。
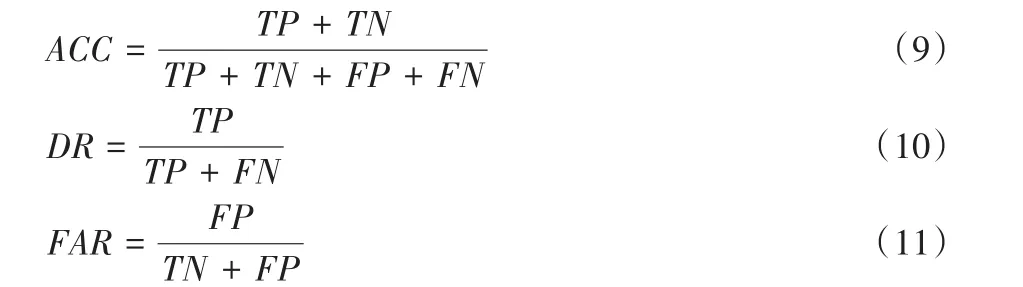
其中:TP(True Positive)是指算法将异常样本正确标记为异常样本的数量,TN(True Negative)是指算法将正常样本正确标记为正常样本的数量,FP(False Positive)是指算法将正常样本错误标记为异常样本的数量,FN(False Negative)是指算法将异常样本错误标记为正常样本的数量。
3.2 KDD-CUP99数据集
KDD-CUP99数据集是离群点检测研究中常用的网络入侵检测数据集,数据集中每个对象有41个特征,其中38个特征为数值型,3个特征为字符型。KDD-CUP99共包含有四种攻击类型,分别为:DoS(Denial of Service)、Probe、U2R(User to Root)、R2L(Remote to Local)。数据集的详细信息如表 1所示。
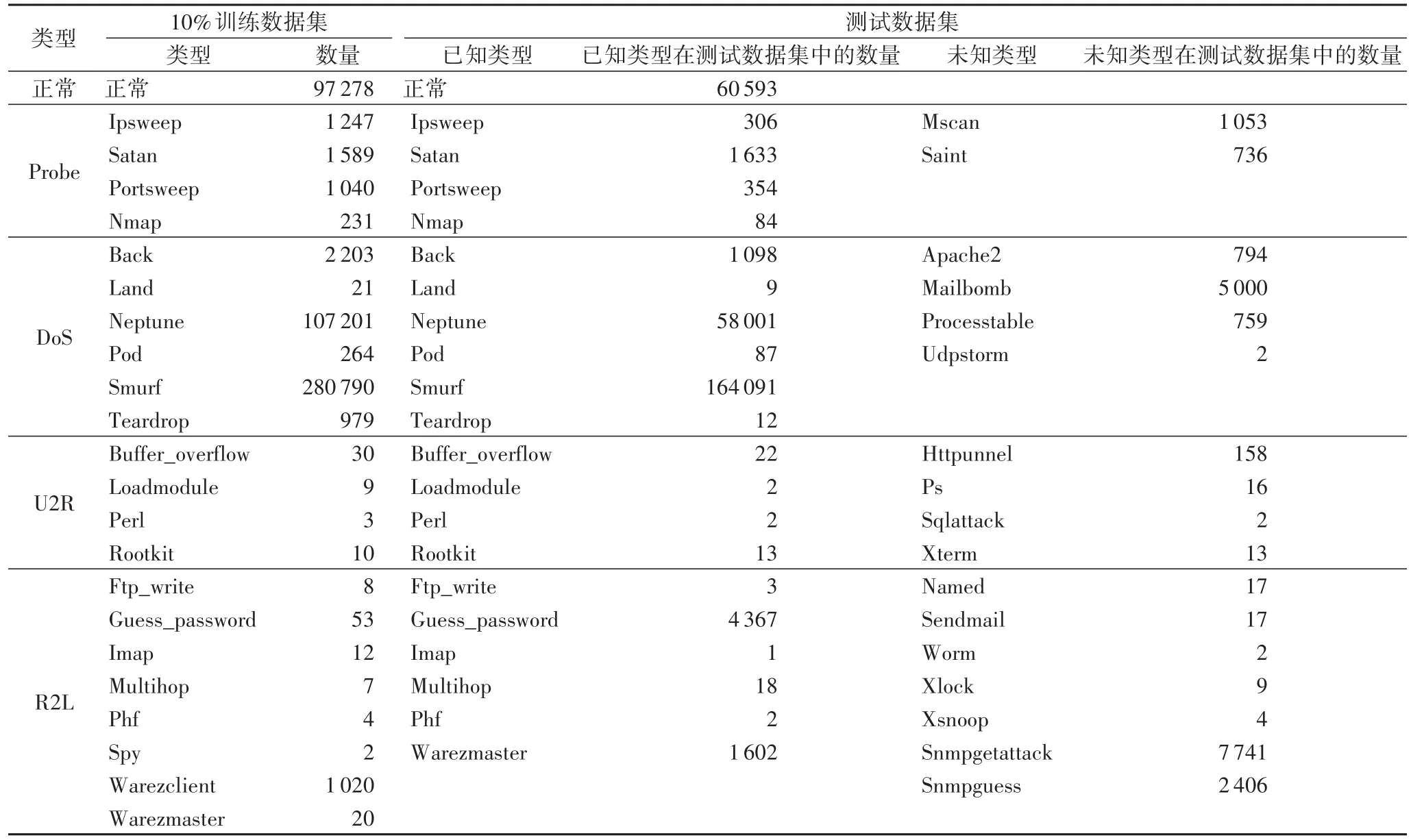
表1 KDD-CUP99数据集详细信息Tab.1 Details of KDD-CUP99 dataset
如表1所示,KDD-CUP99数据集中的四种攻击类型可细分为39种攻击类型:22种出现在训练数据集中,17种出现在测试数据集中。为适应实验需要,先对数据集进行预处理。处理流程如下:
首先将数据集中部分重复数据删除,其次删除特征num_outbound_cmds、is_hot_login(两个特征在数据集中取值均为0,对实验结果无影响),最后对数据集中对象进行离差标准化,标准化方法如下:

其中:d表示某个特征列的值,min是该特征列的最小值,max是该特征列的最大值。在处理后的正常数据对象中,添加Probe、DoS、U2R、R2L四种攻击类型的数据对象,使攻击类型的对象占数据集总个数的5%。处理后的数据集共计85 146个对象,其中:Probe类型1350个,DoS类型2000个,U2R类型300个,R2L类型607个。
表2中第6列参数取值表示各算法在KDD-CUP99数据集中检测率达到最高时,算法对应参数的取值。通过对比各算法在最高检测率时的准确率、误报率及执行时间(Execution Time,ET),可更加公平有效地评价各算法的性能。由表2可知,BGRW算法在迭代217次后,达到最高检测率0.97,LDOF算法在参数k取值71时达到最高检测率0.77,CBOF算法最高检测率为0.92,LOF算法最高检测率为0.83。BGRW算法的准确率与检测率均高于对比的三种算法,误报率0.0015与执行时间422 s明显低于其他三种算法。
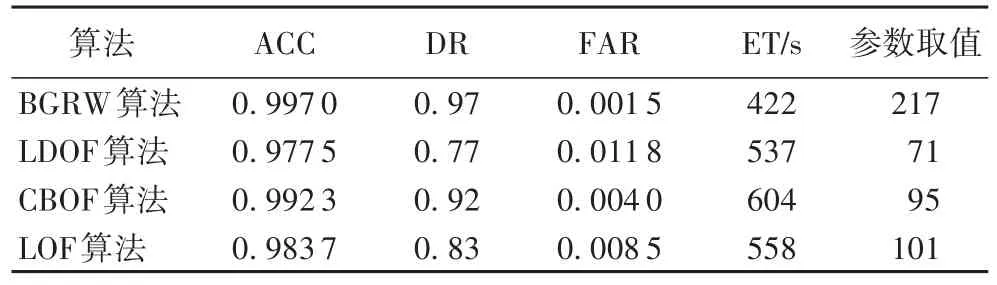
表2 KDD-CUP99数据集中各算法的检测性能Tab.2 Detectionperformanceof each algorithm in KDD-CUP99dataset
3.3 Glass Identification数据集
Glass Identification数据集共包含214个数据对象,分为6种类型。每个对象有9个特征,特征1表示对象的折射率,特征2~9表示对象所含的化学元素在单位重量内所占百分比。对Glass Identification数据集进行处理,删除第4类与第6类部分对象,余留共计10个对象作为离群点。处理后的数据集中对象之间最小距离为0.076 8,最大距离为11.823 3,近邻数k最小为1。
如表3所示,BGRW算法在t=75时达到最高检测率0.8,LDOF算法在参数k取值7时达到最高检测率0.6,CBOF算法在参数k取值13时达到最高检测率0.6,LOF算法在参数k取值11时达到最高检测率0.7。BGRW算法相较于执行时间最短的CBOF算法,所用执行时间缩短为CBOF算法的1/6,相比于执行时间最长的LOF算法,所用执行时间缩短为LOF算法的1/13。
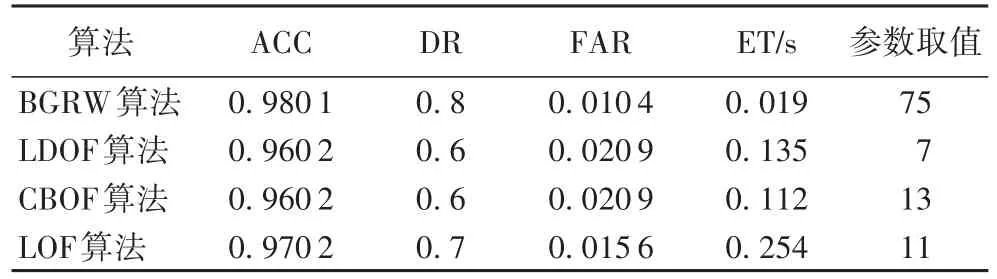
表3 Glass Identification数据集中各算法检测性能Tab.3 Detection performanceof each algorithm in Glass Identification dataset
3.4 WDBC数据集
WDBC数据集含有569个对象,每个对象有32个特征,属于高维数据集。WDBC数据集分为恶性与良性肿瘤两类对象,其中恶性对象数据共计212条。对WDBC数据集进行处理,在良性肿瘤数据中添加20条恶性肿瘤数据,测试BGRW、LDOF、CBOF、LOF四种算法的检测性能。
如表4所示,在迭代25次后,BGRW算法达到了最高检测率0.85,LDOF算法的最高检测率为0.65,CBOF算法的最高检测率为0.75,LOF算法的最高检测率为0.8。BGRW算法在执行时间、准确率、检测率及误报率方面均优于LDOF、CBOF及LOF算法。
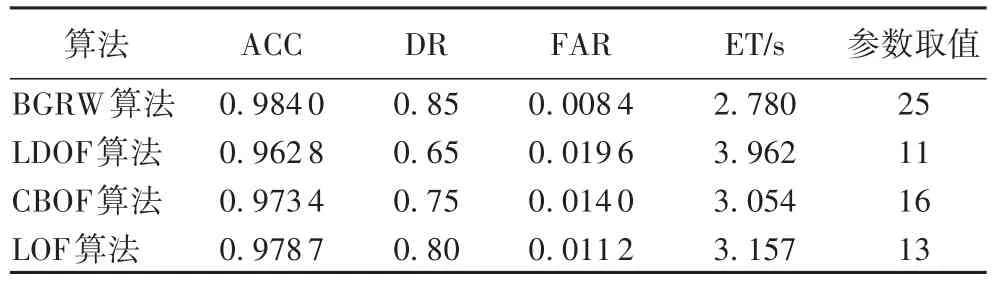
表4 WDBC数据集中各算法检测性能Tab.4 Detection performance of each algorithm in WDBCdataset
3.5 Shuttle数据集
Shuttle数据集共计58 000个对象,共分为7种类型,其中78.59%的对象属于第一类。数据集中每个对象有9个特征,所有特征均为整数型。为适应实验需要,将数据集中2~7类的部分对象删除,余留部分作为离群点,使数据集当中的离群点比例占整个数据集的5%,处理后的数据集共计47985个对象。四种算法的检测结果如表5所示。

表5 Shuttle数据集中各算法的检测性能Tab5 Detection performanceof each algorithm in Shuttledataset
由表5可知,在迭代81次后,BGRW算法在Shuttle数据集中达到了最高检测率0.87,LDOF算法的最高检测率为0.57,CBOF算法最高检测率为0.61,LOF算法最高检测率为0.63。BGRW算法执行时间为195 s,均低于与之对比的三种算法的执行时间。
3.6 合成数据集
为验证BGRW算法在复杂分布的合成数据集当中离群点的检测性能,选取了三组合成数据集,将BGRW算法与LDOF、CBOF、LOF算法在合成数据集中进行对比实验:第一组合成数据集分为7类,由11个离群对象与788个正常对象构成;第二组合成数据集共计404个对象,分为6类,由5个离群对象与399个正常对象构成;第三组合成数据集共计406个对象,分为3类,由399个正常对象与7个离群对象构成。合成数据集如图2所示。
三组合成数据集共计23个离群点中,BGRW算法共计检测出21个离群点,LDOF算法检测出11个离群点,CBOF算法检测出15个离群点,LOF算法检测出15个离群点,如图3所示。三组合成数据集中BGRW算法的平均检测率为0.913,LDOF算法的平均检测率为0.478,CBOF算法的平均检测率为0.652,LOF算法的平均检测率为0.652,实验结果证明BGRW算法是有效可行的。
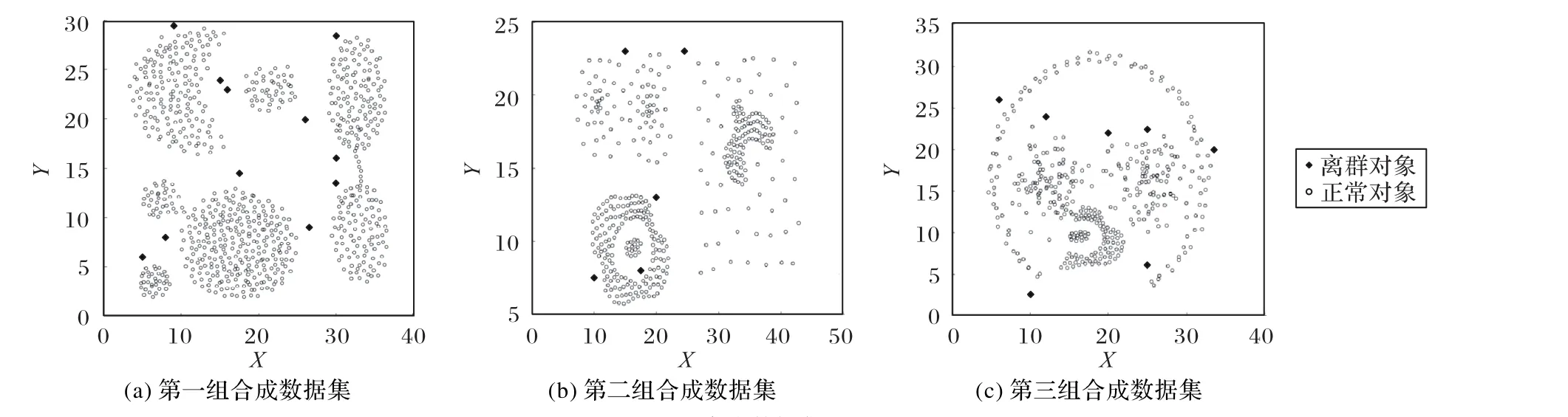
图2 合成数据集Fig.2 Synthetic dataset
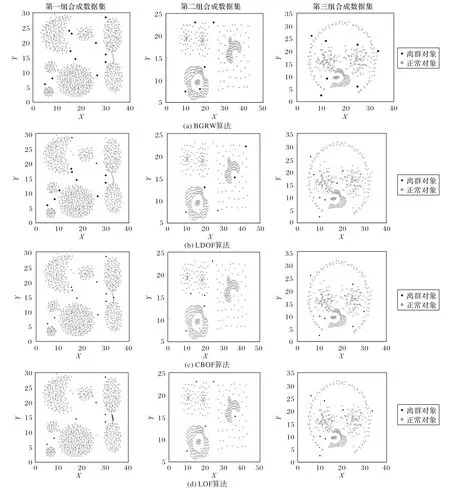
图3 4种算法在三组合成数据集中的检测结果Fig.3 Detection resultsof four algorithmsin three synthetic datasets
4 结语
针对基于距离的LDOF、CBOF与基于密度的LOF离群点检测算法检测率低且执行时间长的问题,提出了基于图上随机游走的BGRW离群点检测算法。BGRW算法构建了数据集中对象之间的转移概率矩阵,通过迭代运算,求得对象的离群值,将离群值最高的对象判定为数据集中的离群点。通过在UCI真实数据集与合成数据集的对比实验证明,BGRW算法相较于对比算法,降低了执行时间和误报率、提高了离群点检测准确率。未来的工作中,将进一步研究如何利用更少的迭代次数尽快地分离出数据集当中的离群点,以及研究如何在受损数据集中使BGRW算法更具鲁棒性。
