基于最大决策邻域粗糙集的不确定性度量方法
2020-06-05史国川鲁磊纪赵小帆
徐 洋,徐 怡,史国川,鲁磊纪,赵小帆
1(安徽大学计算机科学与技术学院,合肥230601)
2(安徽大学计算机智能与信号处理教育部重点实验室,合肥230039)
3(中国人民解放军陆军炮兵防空兵学院信息工程系,合肥230031)
1 引 言
波兰学者Pawlak 提出的粗糙集理论是一种处理知识不确定性的有效分析方法[1],由于它能够从给定问题的描述集合出发,通过不可分辨关系确定问题的近似域,且不需要数据之外的任何先验信息,目前已在模式识别、机器学习、医疗诊断等领域[2-4,7,8]广泛应用.
近年来,许多粒计算模型与方法在特定的应用背景下被相继提出[7,8,12,13,16],其中粗糙集对粒计算研究的推动和发展起着重要作用.经典粗糙集通过确立上、下近似集和边界域,并利用近似粗糙度来度量信息系统的不确定性.随着研究的深入,人们意识到粗糙集不确定性度量在粗糙集理论中的重要性.不少学者对于粗糙集不确定性度量进行了大量研究[5-6,14,15,17],许多学者从不同角度研究了系统的不确定性方法,比如信息熵[18]、粗糙熵[11]、知识粒度[10,15]等,以上方法都能够有效地度量信息系统的不确定性.
经典粗糙集模型是建立在等价关系基础上,对离散型数据系统有较好的应用效果,但不能有效应用于邻域系统,而对数值型数据进行离散化处理,可能会导致知识的分类能力下降.当前,邻域粗糙集模型是处理数值型数据的一种有效模型,其最大优势在于能够直接处理数值型的数据,对比经典粗糙集模型,邻域粗糙集模型有着更加广泛的应用范围.在邻域信息系统中,不少学者对邻域粗糙集模型的不确定性度量从不同的角度进行了研究.姚晟[21]等人提出了一种基于邻域混合熵的不确定性度量方法,构造了邻域粗糙集属性约简算法.Hu[19]等人提出了邻域软间隔度量方法.黄国顺[20]等人提出了基于条件概率的不确定性度量方法.然而,在以上模型中的正域只关注相似类完全包含在某些决策类中的一致性样本.基于正域的依赖度度量忽略了决策类中的边界样本包含在相似类的可能性.实际上,边界样本在样本空间中占有很大的比例.Xiaodong Fan[9]提出了最大决策邻域粗糙集模型,能够更好地处理数值型数据.
为了提高分类能力,本文引入最大决策邻域粗糙集模型,该邻域粗糙集模型密切关注边界样本,通过增加与某些决策类有最大交集的相似类样本来扩大正域,能够更加精确的刻画同一邻域中各个对象之间的关系.在邻域信息系统下,本文利用这一特点,提出了基于最大决策邻域粗糙集的混合型不确定性度量方法.首先在最大决策邻域粗糙集模型下,分别定义了最大决策邻域精确度和最大决策邻域粗糙度,并基于边界域提出一种改进的粗糙度;在粒计算视角下,研究了该模型的粒结构,同时定义了最大决策邻域粒;在此基础上,本文将边界域产生的不确定性与知识粒度产生的不确定性结合起来,提出了新的邻域系统下的不确定性度量方法.该方法结合了两种度量方式的优越性,能够在不同的视角对邻域信息系统进行不确定性度量,最后通过实验证明了新的不确定性度量方法的有效性和高效性.
2 相关基本概念
设 S=(U,A,D)为一个决策信息系统,其中 U={x1,x2,…,xn}是一个非空有限对象集,A={a1,a2,…,am}是一个非空有限属性集,对于任意a∈A,都存在映射aj:U→Vj,Vj称为属性a 的值域,j=1,…,m;任意B≤A 都对应不可辨识关系 IND(B)={(x,y)∈U×U|aj(x)=aj(y),aj∈B},易见IND(B)为U 上的一个等价关系,所有等价类的集合记为U/IND(B),简记为U/B;决策属性D 导出的划分为U/D={D1,D2,…,Dr}.另外,当条件属性Vj均为数值型时,此时信息系统又称为邻域信息系统.
为了准确刻画出集合X 的不确定程度,Pawlak 引入了精度和粗糙度的概念,分别给出了由等价关系P 定义的集合X的精度及对应粗糙度的计算公式

2.1 最大决策邻域粗糙集
定义 1.[9]设 B 为属性子集,B≤A,是B在U上诱导一个二元关系,那么可以定义为:
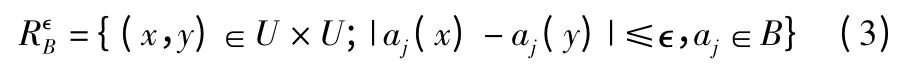

邻域粗糙集中包含两种相似类,第一种是完全包含在决策类Dj中的样本x,第二种是来自多个决策类的样本x',其最大部分包含在Dj中,如图1 所示.在邻域粗糙集模型和最大决策邻域粗糙集模型中,第1 类样本可以明确地分类,不存在任何不确定性.
在邻域粗糙集模型中忽略了第2 类样本,其正域不包括这些样本.然而,在实践中,这类样本被划分为决策类Dj是合理的.
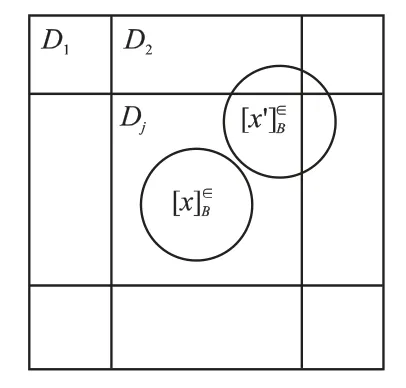
图1 下近似的构成Fig.1 Composition of lower approximation
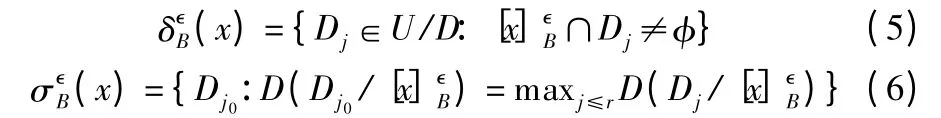
定义3.对于邻域决策信息系统(U,A,D),B≤A,X≤U且邻域半径为是由 B 诱导的二元关系,Dj∈U/D 为 U 上的决策类,那么Dj关于B 的上近似集和下近似集分别定义为:
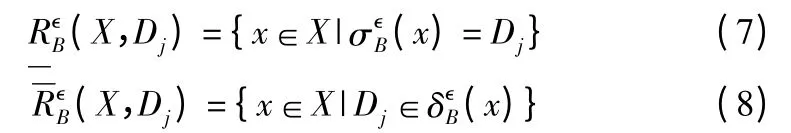
例1.对于邻域决策信息系统(U,A,D),B≤A,设 U={x1,x2,x3,x4,x5,x6,x7,x8,x9,x10},U/B={{x2},{x1,x5},{x3,x4},{x6,x7},{x8,x9,x10}},U/D={D1,D2,D3},D1={x2,x5,x8,x9},D2={x1,x3,x4},D3={x6,x7,x10},设邻域半径为∈,根据定义3,D1关于B 的下近似集和上近似集分别为:

3 邻域信息系统的不确定性度量
Pawlak 提出的经典粗糙集理论中,精度和粗糙度是最基本的概念,二者从边界域的角度去分析样本的不确定程度,成为了一种重要的不确定性度量方法.本节,在完备决策信息系统的基础上,给出基于最大决策邻域粗糙集模型下精度和粗糙度的定义,并研究了相关性质,提出改进后的精度和粗糙度.
定义4.对于邻域决策信息系统(U,A,D),B≤A,X≤U且邻域半径为是由 B 诱导的二元关系,Dj∈U/D 为 U上的决策类,那么D 关于B 的最大决策邻域精度和最大决策邻域粗糙度分别定义为:
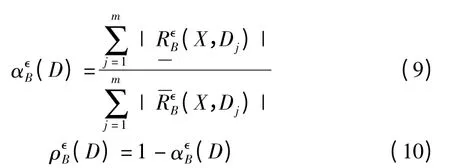
对于邻域决策信息系统(U,A,D),随着知识划分的变细,邻域精度不一定会严格变小,同时邻域粗糙度是由边界域与上近似集基数的比值,不能刻画负域的变化的过程,特别是负域或正域中知识被细分时,粗糙集的粗糙度可能并不发生改变,具体反例如例2 所示.
例 2.假设 U={x1,x2,x3,x4,x5,x6},X={x1,x6},U/A={{x1,x2},{x3,x4},{x5,x6}},U/B={{x1,x2,x3,x4},{x5,x6}}.
显然,有U/A<U/B,且|BNDA(A)|<|BNDB(X)|,但ρA(X)=ρB(X)=1,与U/B 相比,U/A 未能将正域中的颗粒做进一步分离,但仍能确定{x3,x4}不在X 中.因此,可以考虑提出一种基于边界域的能够刻画正域、负域变化的不确定性度量方法.
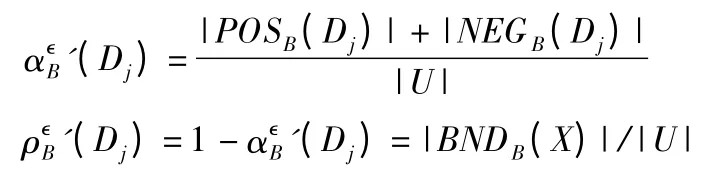
定理1.对于邻域决策信息系统(U,A,D),P≤Q≤A,X≤U,则
证明:根据P≤Q,可得知U/Q<U/P,且|BNDQ(X)|≤|BNDP(X)|,则有).
此外,知识粒度对论域有较强的区分度,知识粒度越小,其区分度越强,反之则越弱.
在粒计算模型中,每一个信息粒由若干对象粒化而成,所有信息粒共同构成粒结构.本文在此基础上,构造基于最大决策邻域关系的粒结构,并提出基于该粒结构的粒度度量方法.
定义5.对于邻域决策信息系统(U,A,D),B≤A 且邻域半径为∈,由B 决定的最大决策邻域粒结构为:

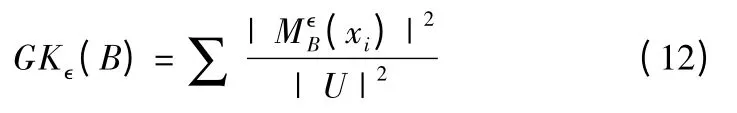
当B 的分类能力越强时,划分粒度越小,每个最大决策邻域粒中元素个数就越少,能区分开的对象就越多.相反,分类能力越弱,划分粒度就越大,最大决策邻域粒中的元素个数就越多,能区分的对象就越少.当B的粒度达到最小时,当B的粒度达到最大值时,GK∈(B)=.
定理2.对于邻域决策信息系统(U,A,D),P≤Q≤A,X≤U,则 GK(P)≥GK(Q).
证明:令Ax ∈U 在 P,Q 的划分中的粒结构分别是MP(X),MQ(X),由于 P≤Q,根据定义5 可以得到 MP(X)≥MQ(X),所以显然有KG(P)≥GK(Q).
定义6.对于邻域决策信息系统(U,A,D),B≤A,设邻域半径为∈,由B 推导出的最大决策邻域粒度为GK∈(B),那基于最大决策邻域粗糙集的混合型度量定义为:
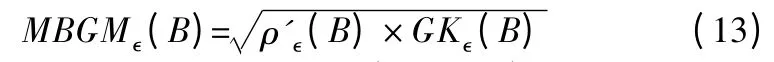
定理3.对于邻域决策信息系统(U,A,D),B≤A,设邻域半径为∈,那么混合度量满足0≤MBGM∈(B)≤1
证明:根据定义4 可直接得到.
定理4.对于邻域决策信息系统(U,A,D),P≤Q≤A,设邻域半径为∈,那么混合边界粒度度量满足MBGM∈(P)≥MBGM∈(Q)
证明:根据定理1 和定理2 可直接得到.
定理 5.对于邻域决策信息系统(U,A,D),B≤A,∈1,∈2为两个邻域半径且满足∈1≥∈2,那么混合边界粒度不确定性度量满足 MBGM∈1(P)≥MBGM∈2(B).
4 实验结果与分析
为进一步验证本文提出的不确定性度量方法在邻域信息系统的有效性,选取 UCI 标准集中 Wine、Glass、Cancer 等 6个数据集,具体信息如表1 所示.

表1 UCI 标准集Table 1 UCI data sets
首先对6 个数据集条件属性值进行归一化处理,使得所有条件属性值都处于[0,1]区间,设置邻域半径 ∈=0.3.对于表1 中数据集,分别计算最大决策邻域粗糙度、最大决策邻域粒度和最大决策邻域混合度量随属性数目变化的结果,具体结果如图2-图7 所示.通过观察可以发现,随着属性数目的增加,实验结果的度量值均逐渐减小,表明三种度量方法均能对系统的不确定性进行度量.在图3 中,Glass 数据集当属性从2 增加到4 时,最大决策邻域粗糙度和最大决策邻域粒度的度量结果变化不大,说明尽管知识空间发生了改变,邻域系统的不确定性没有发生变化,而最大决策邻域混合度量的值变化也较小,与另外两种度量结果相吻合,类似的情形也出现在Wine、Zoo、Sonar 和 Wdbc 数据集中.在图5 中,Zoo 数据集属性数量从1 增加到4,最大决策邻域粗糙度并未发生较大变化,而最大决策邻域粒度和最大决策邻域混合度量的值下降较快,说明粒度的变化对混合度量有一定影响,类似的情况出现在Wine 和Glass 数据集中.在图2-图7 中,最大决策邻域粗糙度和最大决策邻域粒度随着属性数目的变化均出现过不同程度大幅下降,而最大决策邻域混合度量的值表现较平稳,这是由于两种度量方法从不同的度量视角导致的,但是最大决策邻域混合度量同时考虑了两种不确定性度量的视角,结合了二者的优越性,是两者的折中.因此提出的不确定性度量方法能够较好地度量邻域系统的不确定性.

图2 数据集CT 的不确定性度量结果Fig.2 Uncertainty measurement of data set CT
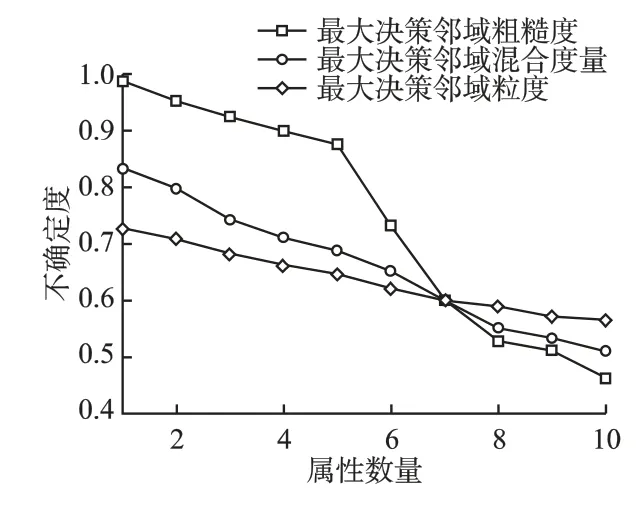
图3 数据集Glass 的不确定性度量Fig.3 Uncertainty measurement of data set Glass
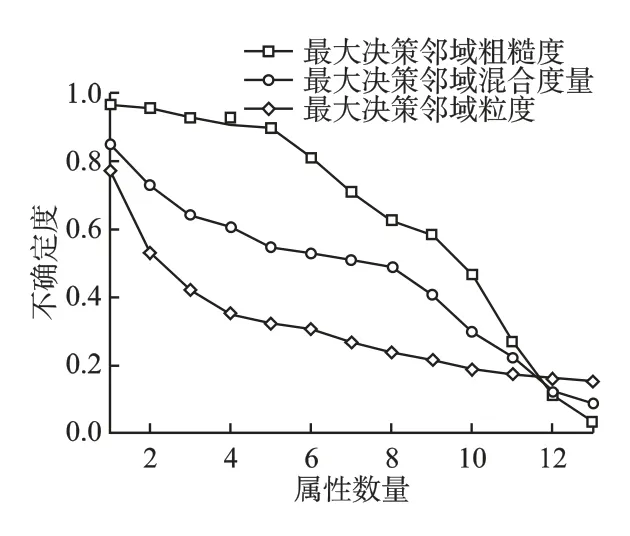
图4 数据集Wine 的不确定性度量Fig.4 Uncertainty measurement of data set Wine
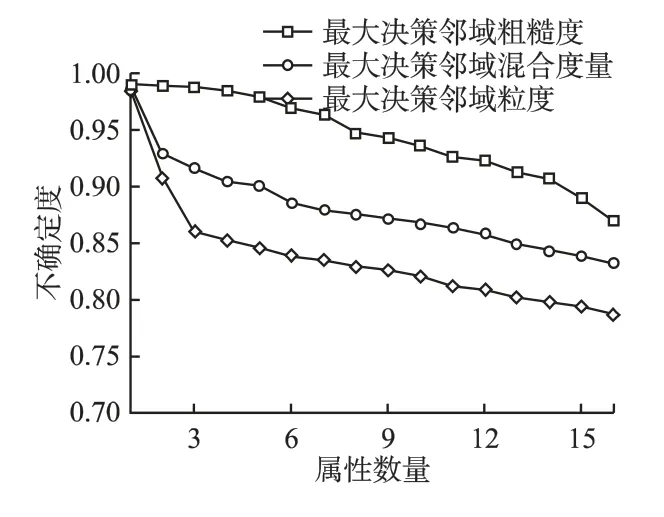
图5 数据集Zoo 的不确定性度量Fig.5 Uncertainty measurement of data set Zoo
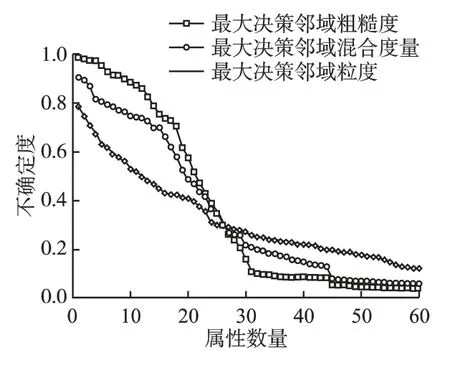
图6 数据集Sonar 的不确定性度量Fig.6 Uncertainty measurement of data set Sonar
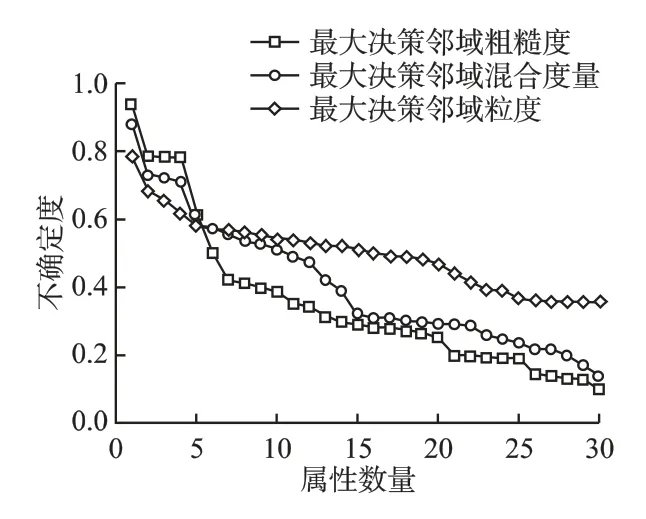
图7 数据集Wdbc 的不确定性度量Fig.7 Uncertainty measurement of data set Wdbc
为了更进一步验证最大决策邻域混合度量的有效性,采用支持向量机(SVM)分类器进行分类实验,对应的分类精度如图8-图13 所示.本实验中分类精度的表示,即:

其中 T,Simples 分别表示分类正确的样本数量以及样本总数.
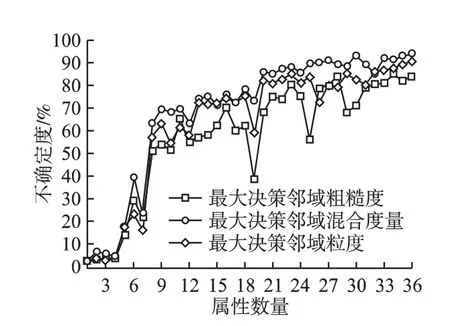
图8 数据集CT 分类精度对比Fig.8 Comparsion of classification accuracy(CT)
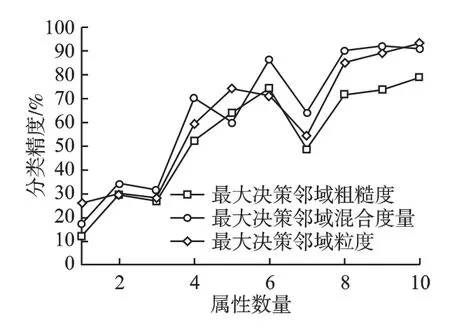
图9 数据集Glass 分类精度对比Fig.9 Comparsion of classification accuracy(Glass)
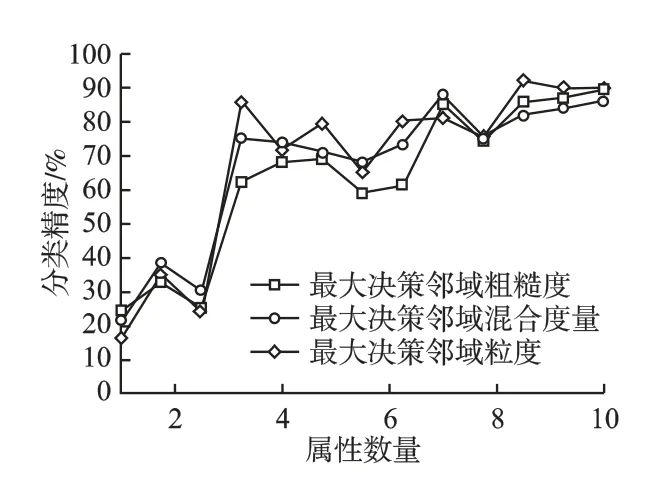
图10 数据集Wine 的分类精度对比Fig.10 Comparsion of classification accuracy(Wine)
实验通过增加属性数目来评估3 种度量的分类效果.具体结果如图8-图13 所示.可以看出,随着属性数量的增加,3 种不同度量的分类精度都呈现出增长趋势.当属性数量增加到一定程度时,分类精度基本达到最大值,当属性数量再增加时,因冗余属性加入,对实验产生一定干扰,分类精度有不同程度的下降,如图8-图13 所示.当属性数量最大时,分类精度也趋于最大.综合实验结果分析得出,本文的基于最大决策邻域粗糙 集模型的混合度量方法具有有效且合理的不确定性度量效果.
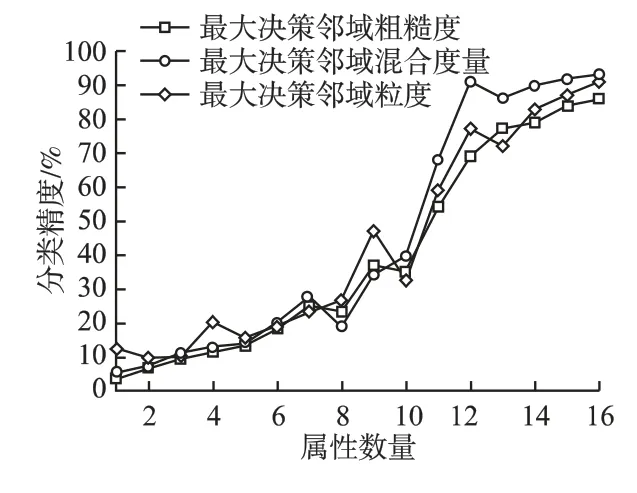
图11 数据集Zoo 分类精度对比Fig.11 Comparsion of classification accuracy(Zoo)
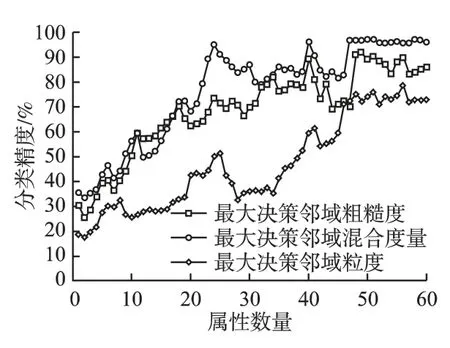
图12 数据集Sonar 的分类精度对比Fig.12 Comparsion of classification accuracy(Sonar)

图13 数据集Wdbc 分类精度对比Fig.13 Comparsion of classification accuracy(Wdbc)
5 结束语
粗糙集理论与方法作为处理复杂系统的一种较为有效的方法,其不确定性的度量已成为最为活跃的研究领域之一[13].本文通过引入最大决策邻域粗糙集模型,定义了基于该模型的最大决策邻域粗糙度和最大决策邻域粒度,从不同的粗糙集的角度出发,结合两种度量方式的特点,提出一种混合型不确定性度量方法.研究结果发现,提出的混合型不确定性度量方法能够结合两种不确定性度量方法的优越性,对邻域信息系统的不确定性有更好的度量效果.
