利用深度残差网络的遥感影像建筑物提取
2020-06-04刘亦凡张秋昭王光辉李益斌
刘亦凡,张秋昭,王光辉,李益斌
(1.中国矿业大学 环境与测绘学院,江苏 徐州 221116;2.自然资源部国土卫星遥感应用中心,北京 100048;3.江苏苏州地质工程勘察院,江苏 苏州 215129)
0 引言
利用遥感影像提取建筑物在建设用地规划、灾害评估、建设数字城市和GIS数据更新方面有重要的作用。虽然国内外众多学者已经探索出很多方法,但是由于高分辨率遥感影像中存在同物异谱、异物同谱、噪声阴影和地物遮挡等问题,很难实现高精度自动化提取[1-2]。
传统遥感影像提取建筑物的方法主要依赖于人工制作的特征,如局部特征(边缘角点等)[3-4]、纹理特征[5]、形态学特征[6]、多光谱属性特征[7]和阴影特征[8]等。同时支持向量机[9-10]、分水岭算法[11]和遗传算法[12]等也广泛应用于遥感影像建筑物提取。然而这些方法普适性稍差,分类性能取决于人工筛选的低级特征,表达能力也有限。因此,在图像分割中提取和使用具有代表性的高级特征,对建筑物的准确提取是十分重要的。
近年来,深度卷积神经网络在语义分割领域得到广泛应用[13]。如全卷积神经网络FCN[14]、SegNet[15]等神经网络都能够得到每一个像素在其类别最大的概率,最终完成像素级别的分类。然而FCN和SegNet对于物体的边缘信息不敏感,提取边界明显的建筑物时效果不佳。UNet网络是Ronneberger等[16]提出的一种处理医学影像的网络,它能够结合高层特征和低层特征,恢复边缘信息,成为众多语义分割比赛中的佼佼者。但是在遥感影像中,建筑物类别复杂,浅层的网络训练到一定程度会出现梯度消失的问题。文献[17]表明更深层次的网络会产生更好的性能,He等[18]提出深度残差网络(deep residual network,ResNet),利用恒等映射层拓展层数,为解决问题提供了新思路。
本文提出了一种以UNet为框架,以ResNet-34为前端编码器、转置卷积为后端解码器的Res-UNet结构。Res-UNet对比其他2种结构,能够有效结合2种结构的优势,可以融合上下文信息,提取多层级特征,同时解决了梯度消失的问题,从而提升了神经网络方法提取遥感影像中建筑物的精度。
1 Res-UNet方法
1.1 网络结构
本文提出的Res-UNet网络结构如图1所示,主要分为左侧编码、右侧解码和中间金字塔式跳跃连接3个部分。

图1 本文提出的Res-UNet结构图
左侧编码部分的ResNet-34网络用于提取特征,将网络输入尺寸设计为256像素×256像素的三波段RGB影像。输入层后面跟着归一化层和最大池化层。网络中的激活函数为ELU(exponential linear unit),定义如式(1)所示。
(1)
ELU的输出均值接近于零,x>0的线性部分加速收敛速度,同时缓解梯度消失;x≤0的非线性部分使输入变化或噪声更鲁棒。4次2×2的最大池化层用于下采样,起到了降维和保持图像整体尺度不变的作用。在特征提取过程,共有4个阶段,每个阶段有若干残差模块,如图2所示,残差单元计算见式(2)、式(3)。
yl=h(xl)+F(xl,Wl)
(2)
xl+1=f(yl)
(3)
式中:xl和xl+1是第l个残差单元的输入和输出;F(xl,Wl)是残差函数;h(xl)是恒等映射函数;f(yl)是ELU激活函数,一般情况下,h(xl)=xl。同一阶段下特征图尺寸与数量相同,进入下一阶段时特征图尺寸变为原来的1/2,数目变为原来的2倍。
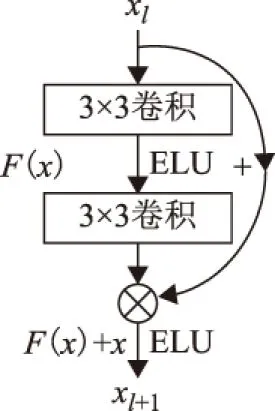
图2 残差计算单元
右侧解码部分也由4个阶段组成,每个阶段通过1×1卷积层、转置卷积层和1×1卷积层进行上采样,同阶段特征图尺寸和数量与左侧一致。中间跳跃连接部分受到FPN[19]的启发,设计为金字塔型层级结构,将左右两侧的特征图进行叠加再输入下一层级,实现上下文多尺度特征融合。在网络的最后,通过一个1×1卷积层和sigmoid激活函数输出特征向量概率图,将建筑物与背景分离。本文的网络结构解决了层数增加导致的梯度消失问题,金字塔结构融合了不同层级的多尺度特征,有助于恢复建筑物边缘信息。
全民学习共享平台呈现了全新的教学服务平台,给课程教学带来开阔的视野,提供强大的课程服务和学生管理能力,给教学传播带来新的契机。教研组可以申请、创建微信雨课堂教室,分享具体课程内容资源。教学团队可以自主制作视频和实验模板,让更多的人能够有所体验,而且雨课堂可以不用下载APP,占用空间很小,触手可及,用完就能退出。在内容设置安排上,要以直观且清晰的关键词来设计大数据信息,在线学员可以根据不同的需求和兴趣点到达不同的页面空间,开展学习活动。
1.2 数据预处理
将影像数据输入到网络之前需要对数据进行预处理,主要有两个目的:一是数据增广,当数据集较少时,可以通过旋转、翻转或随机裁剪等方式扩大数据量;二是数据增强,使数据变得更加多样,避免模型偏向某一特定方位的特征。由于建筑物尺寸大小存在差异,为了使网络能够学习到不同尺度的特征,首先利用双线性插值法,将影像分别放大和缩小至原尺寸的0.5倍、0.75倍和1.5倍;其次用256像素×256像素的滑动窗口裁剪,其中对一些房屋密集区以一定的步长进行过采样;然后利用随机旋转、随机翻转和随机添加噪声处理裁剪后影像;最后对所有数据进行归一化。
利用滑动窗口对影像数据进行裁剪时,如果裁剪尺寸为128像素×128像素,下采样至16倍时,8像素×8像素的特征图不足以表达复杂的空间信息,恢复至原尺寸时细节较差;如果裁剪尺寸为512像素×512像素时,将超出计算机的内存占用,导致计算资源不足。因此本文的滑动窗口尺寸为256像素×256像素,以128的步长进行裁剪。
1.3 模型集成
神经网络基于梯度下降的原理更新权重,随着迭代次数增加,模型逐步趋于收敛,但是不同迭代次数也会导致模型参数变化。因此本文提出一种集成多模型得到最终预测结果的方法,在训练进入平缓区后,保存最后几轮模型结果做集成,可以防止迭代次数过多导致的过拟合现象,降低随机误差。
第一步预测阶段采用TTA(test time augmentation)策略,将原始预测图送入网络前旋转0°、90°、180°和270°,上下翻转和水平翻转得到6张每个像素点数值在(0,1)之间的预测图,将6张概率图中相对应的每个像素点用直接平均法得到新的概率图。第二步用训练好的4个模型同时预测,得到的预测结果进一步取平均值,准备下一步后处理工作。
1.4 后处理
通常利用深度学习训练获得模型得到的预测结果都不够齐整,有些建筑物存在椒盐噪声、孔洞和边界不平滑等现象,因此需要阈值过滤和后处理来优化结果。首先利用选择好的阈值,对概率图进行二值化,用于区分建筑物与背景,然后对有空缺的建筑物孔洞填充,再选择合适的像素值用于去除较大图斑,最后进行高斯滤波和形态学运算对边界进行平滑,以上运算由OpenCV处理。整体的工作流程如图3所示。
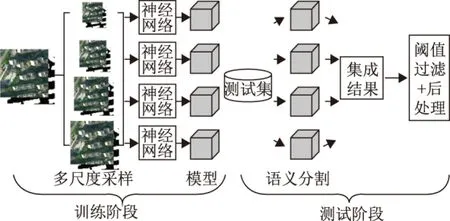
图3 本文方法的工作流程
选取合适阈值的策略是通过对训练集和验证集进行预测,预测结果阈值以5为步长,从50取至160,计算每个阈值下的F1值,选取最大的F1值作为测试集的二值化阈值。
2 实验结果处理与分析
2.1 数据介绍
实验数据为CCF卫星影像识别比赛中南方某地亚米级高分辨率遥感影像集,光谱为RGB可见光波段。选取建筑物类别作为样本。影像中建筑物种类较多,有小区、工厂和平房等,将建筑物标记为前景,其他地物标记为背景,数据预处理后整个数据集共10 598张。在训练时以8∶2的比例随机分为8 478张训练集和2 120张验证集。
2.2 实验过程与结果
在训练阶段,将预处理过的数据集输入网络,经过大量测试,为了得到效果最好的模型,选用BCE+Dice_loss作为损失函数,选择Adam算法作为优化器,进行权值更新。训练一共迭代106 000次,批处理图像个数为8张,学习率设置为0.000 1,每迭代10 600次,对验证集loss监视,如果不再继续减小,则下一次迭代次数减小为原来的1/10。
为了对模型的性能做定量评价,本文选择精确率、召回率和F1值作为像素级语义分割的评价指标。F1值代表了精确率与召回率的加权平均值,通常选取F1值最高的作为最佳模型,计算公式如式(4)~式(6)所示。
(4)
(5)
(6)
式中:TP表示预测为正样本,实际预测正确(正确提取的建筑物);FP表示预测为正样本,实际预测错误(错误提取的建筑物);FN表示预测为负样本,实际预测错误(预测为背景,实际为建筑物)。
本文实验使用Tensorflow+Keras深度学习框架,在Linux系统下,通过一块12 GB显存的NVIDIA TITAN V显卡完成训练,实验过程中的准确率和损失曲线如图4所示。
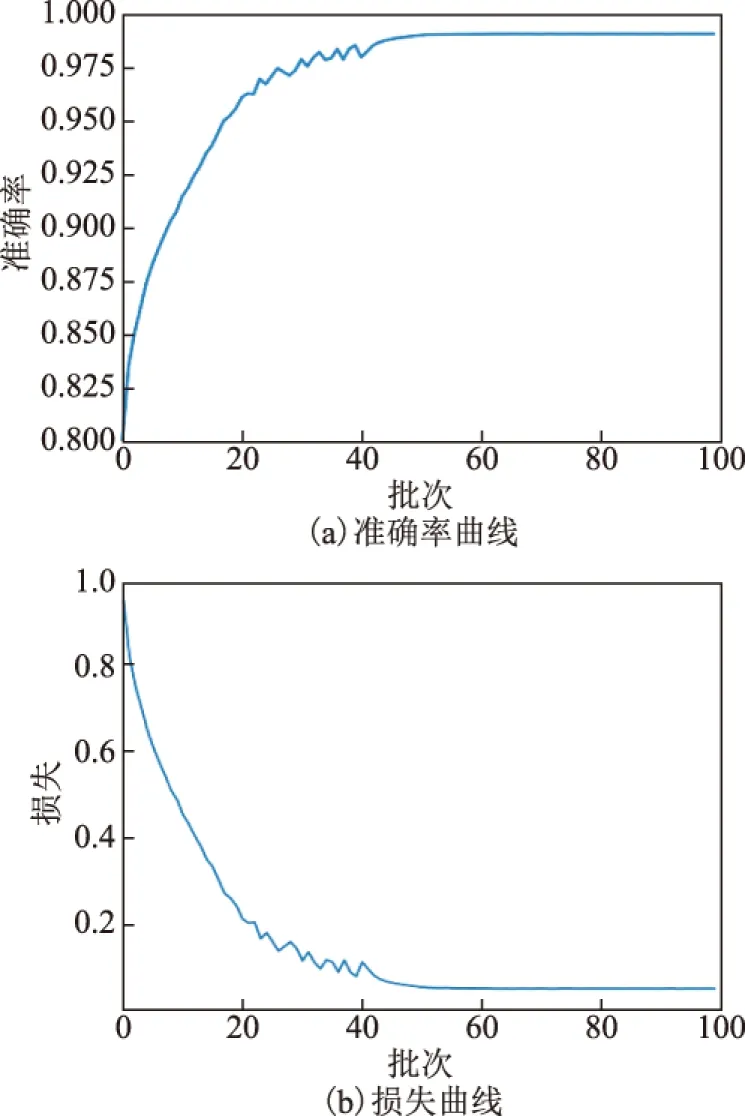
图4 模型训练过程中准确率和损失值变化
2.3 结果分析
1)不同网络结构对比。首先对SegNet、UNet和Res-UNet的提取效果进行对比,图5(c)至图5(e)是同一区域不同模型的预测结果,一些重要区别用圆圈标记。图5中红圈处的建筑物较为密集,SegNet和UNet提取的建筑物之间有黏连,Res-UNet提取分离度较好;图5中蓝圈和黄圈处Res-UNet提取边界也更加完整。表1给出了测试集不同模型的评价指标对比,可以看出,Res-UNet的精确率与召回率均优于SegNet和UNet,F1值分别提升了0.8%和1%。
2)阈值过滤与后处理对比。为了进一步优化预测结果,进行阈值过滤和后处理操作。在前文具体介绍了选取阈值的方法,图6为F1值随着阈值增加的变化曲线。可以看出F1值有先增加后减少的趋势,通过计算,最大F1值的阈值为105。本文对不同阈值过滤结果进行了对比,如图7(c)至图7(e)所示,阈值导致的变化用圆圈标记。图7中蓝圈处,如果选取的阈值太大,一些模糊的建筑物边界就会被剔除掉,提取建筑物的尺寸就会缩小;图7中黄圈处,如果设置的阈值太小,会有与建筑物边缘纹理特征相似的像素点存在,导致建筑物比实际大,有些建筑物之间有黏连;图7中红圈处,会有一些不属于建筑物的噪声存在。表2为测试集预测结果的精度评定,阈值较小时,存在大量不属于建筑物的像素点,导致精确率较低;阈值较大时,属于建筑物的概率较低的像素点被过滤,导致召回率较低。综上所述,所选阈值必须处在二者的平衡位置,才能得到最佳效果。
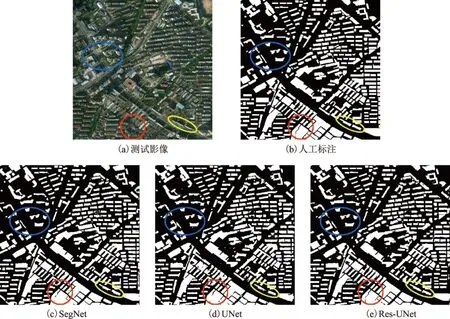
图5 不同网络结构建筑物提取结果
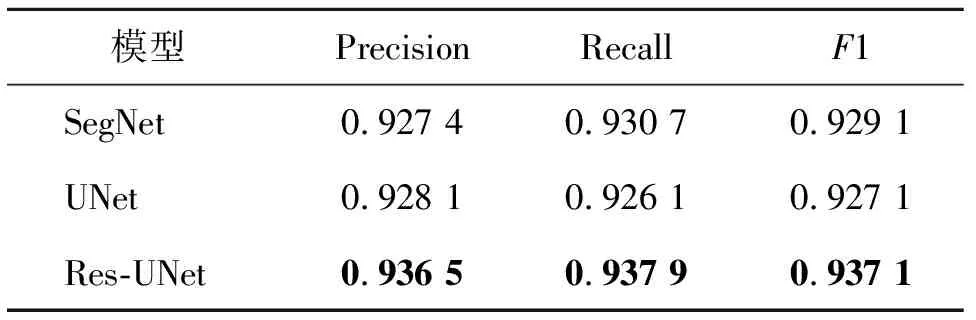
表1 测试集不同网络结构的F1值对比
后处理过程中,首先对上一步得到的预测结果进行多模型集成,然后选择合适的像素值去除较大图斑,最后利用高斯滤波和形态学运算使建筑物边界平滑,进行孔洞填充使建筑物更加完整,最终效果图如图7(f)所示。由表2分析表明F1值的提升主要为精确率的提升,说明经过后处理的建筑物更加完整。
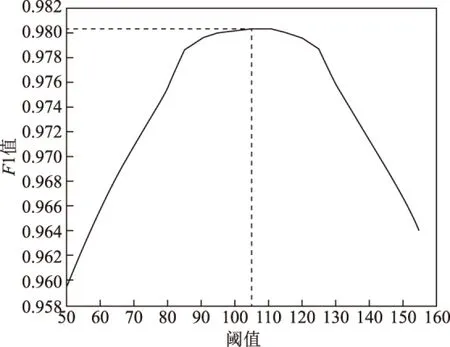
图6 阈值增加导致的F1值变化

图7 不同阈值下建筑物提取结果和后处理结果
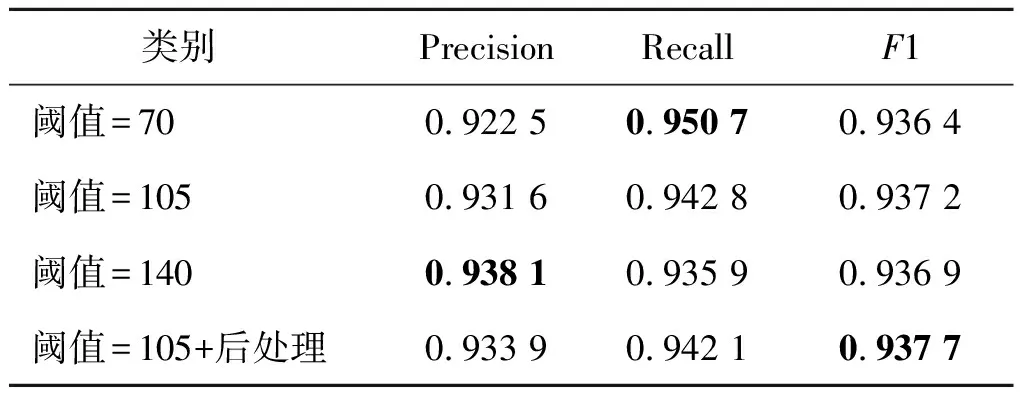
表2 测试集不同阈值和后处理结果对比
3 结束语
本文提出了一种Res-UNet深度神经网络进行高分辨率遥感影像建筑物的提取方法,解决了梯度消失的问题,有助于恢复高级边缘特征信息。实验表明,本文算法与SegNet和UNet相比,能有效提高建筑物提取精度,并且通过模型集成、阈值过滤和后处理,有效剔除了噪声,使建筑物边界更加平滑,预测结果得到进一步优化。利用深度学习进行分割任务虽然比传统方法精度高,但是它主要有两个缺点:一是需要大量的样本数据;二是训练需要经验设置参数。在后续工作中,将参考弱监督方法并结合先验知识,提高适用能力。
