基于神经网络的命名数据网学习型FIB研究
2020-06-04刘开华宫霄霖王彬志
刘开华,闫 柳,李 卓,宫霄霖,彭 鹏,王彬志
基于神经网络的命名数据网学习型FIB研究
刘开华,闫柳,李卓,宫霄霖,彭鹏,王彬志
(天津大学微电子学院,天津 300072)
针对命名数据网转发信息库快速检索差异化名称数据、高效存储转发信息和有效支持最长名称前缀匹配机制的需求和挑战,提出了基于神经网络的命名数据网学习型FIB整体方案,称L-FIB.首先,介绍了L-FIB的索引结构Learning Tree,通过使用塔式两级神经网络模型学习索引内容在存储器中的分布情况,实现更均匀的数据映射,降低映射冲突,提高存储效率.其次,研究了L-FIB的存储结构和名称数据检索算法,片内高速存储器部署多个与不同名称前缀组件数相对应的索引结构Learning Tree,片外低速存储器部署多个与索引结构Learning Tree对应的FIB存储池,并通过相应的名称数据检索算法实现对兴趣包的转发信息检索和转发信息更新操作,有效支持了命名数据网的最长名称前缀匹配机制,提高了名称数据检索速度.实验结果表明,L-FIB在误判概率、存储消耗和吞吐量方面的综合性能明显优于其他对比方案.在误判概率低于1%的条件下,L-FIB的索引结构存储消耗仅为58.258MB,能够部署于高速存储器SRAM上.L-FIB的实际吞吐量约为11.64×106数据包/s,可以满足当前命名数据网对数据包快速处理的要求.
命名数据网;转发信息库;神经网络;名称数据检索
互联网规模的不断扩大,虚拟现实、全息通信、高清视频传输[1]等全新应用在传统行业的不断呈现,加速了互联网由“通信信道”向“数据处理平台”的角色转变[2].为了应对互联网内容化、个性化等未来业务需求,国内外许多研究机构都在积极探索未来互联网架构的革新问题.作为未来互联网架构的一个典型范例,命名数据网(named data networking,NDN)[3]于2010年被提出,其不仅可以通过使用名称数据实现互联网面向内容的通信模式,而且可以通过在网络节点部署内容存储池,实现真正意义上的内容共享,极大地降低网络的负载[4].因此,命名数据网被认为是非常具有应用前景的未来互联网架构之一.
在命名数据网中,所有通信均由消费者驱动,通过交换包含名称标识的兴趣包和数据包实现[5].为了请求所需数据,消费者首先向网络发送一个兴趣包,路由器记录兴趣包的传入接口,并利用兴趣包的名称根据转发信息库(forwarding information base,FIB)[3]转发,直至到达含有相应数据包的网络节点,将该数据包发回给消费者[6].因此,FIB的设计直接关系到命名数据网转发平面的工作性能.然而,由于内容名称不同于IP地址的诸多特征,命名数据网的FIB研究面临着一系列亟待解决的问题和挑战.其一,FIB以名称字符串为索引主键,具有变长、无边界的基本特点[3],且内容名称在不同应用场景下极具个性化[5],如何支持差异化名称快速检索成为公认的难题.其二,FIB条目数可达百万级别[7],且需要更多的存储空间来记录远比IP地址复杂的内容名称及转发信息,如何高效地将转发信息存储在有限的内存中是一个极具挑战的问题.其三,命名数据网FIB具有不同于IP网络的最长名称前缀匹配(longest name prefix matching,LNPM)[6]机制,如何支持这种机制仍是有待解决的问题.
自2010年命名数据网被提出以来,转发平面FIB的研究和设计引起了国内外学术界的广泛关注.目前针对FIB的设计方案主要基于Trie、哈希表和Bloom filter 3种数据结构[6].例如,Ghasemi等[8]提出NameTrie方案,通过ASCII优化来高效存储转发信息;Dai等[9]提出CONSERT方案,通过删除冗余来减少名称前缀数量;Lee等[10]提出PC-NPT方案,通过路径压缩来优化查找速度;Song等[11]提出Binary Patricia Trie方案,通过使用比特级编码以支持变长名称数据检索和路由表增量更新;Yuan[12]提出FHT方案,利用指纹技术来压缩存储;Yuan等[13]提出Binary Search方案,通过二分查找来提高名称数据检索效率;Wang等[14]提出NameFilter方案,提出将Bloom filter部署于路由器每个端口;Dai等[15]提出BFAST方案,将Bloom filter与哈希表组合以映射数据地址;Li等[16-17]提出MaFIB和B-MaFIB方案,将Bloom filter与定位数组和Bitmap组合以实现数据映射.但是,目前提出的FIB设计方案难以很好地兼顾存储消耗和名称检索速度,且未充分考虑如何有效支持差异化名称检索和LNPM机制[6].因此,急需提出新的解决思路,设计新颖的FIB整体解决方案,以充分应对上述问题和挑战.
针对上述挑战和研究现状,本文提出了基于神经网络的命名数据网学习型FIB整体方案,称L-FIB.首先,对L-FIB的索引结构Learning Tree展开介绍,通过使用塔式两级神经网络模型学习索引内容在存储器中的分布情况,实现更均匀的数据映射,降低映射冲突,提高存储效率.其次,对L-FIB的存储结构和名称数据检索算法进行设计,通过采用多个Learning Tree和多级存储器的部署模式,有效支持命名数据网的LNPM机制,并提高名称数据的检索速度.实验结果表明,L-FIB在误判概率、存储消耗和吞吐量方面的综合性能明显优于其他对比方案.
1 FIB的设计要素
与IP网络不同,命名数据网FIB中每个条目的内容为:<name prefix,stale time,interface ID,routing preference,RTT,status,rate limit>[7].每次转发兴趣包,都需要根据兴趣包的内容名称在FIB中检索相应的转发信息.因此,FIB的设计要素包含3点:索引结构、存储结构和数据检索算法[18].
1.1 索引结构
命名数据网FIB索引的主键是变长、无边界的名称字符串,比固定长度的IP地址更加复杂[3].应用驱动的数据命名规则,不但使内容名称在不同应用场景下极具个性化[5],更使转发平面FIB条目数可达超百万级别[7].此外,每次转发兴趣包或FIB更新时,都需要使用相应的名称以实用的高速在FIB中执行检索操作.因此,如何设计可支持差异化名称检索,且内存消耗小、检索速度快的索引结构,是FIB设计的要素之一.
1.2 存储结构
目前存储器技术中,可快速访问的存储器芯片通常存储空间较小(如SRAM),而提供较大存储空间的芯片通常访问速度较低(如DRAM)[11].如果只能将FIB部署在具有较大存储空间的低速存储器上,那么路由器将很难完成快速转发操作.因此,如何设计适合于当前存储器硬件水平的高效存储结构,是FIB设计的要素之二.
1.3 数据检索算法
不同于IP地址最长匹配原则,命名数据网FIB的数据检索基于LNPM机制,通过名称前缀匹配进行,以兴趣包名称的每个分隔符为断点,按名称组件粒度找到最长匹配的名称前缀[6].因此,如何设计可支持LNPM机制的名称数据快速检索算法,是FIB设计的要素之三.
2 L-FIB的索引结构Learning Tree
根据命名数据网FIB的研究挑战和设计要素,本文首次提出了基于神经网络的学习型FIB整体方案,称为L-FIB.本节介绍了L-FIB的索引结构Learning Tree,阐述其具体结构以及其中神经网络模型的参数选择.
2.1 Learning Tree基本结构
传统哈希表因操作速度上的明显优势而被广泛使用,然而,它的不足在于数据映射的不均匀性和大量的哈希冲突,这大大降低了存储效率[6].鉴于此,Learning Tree通过使用神经网络来学习索引内容在存储器中的分布情况,实现更均匀的数据映射,降低映射冲突,提高存储效率.具体效果如图1所示.

图1 哈希表与Learning Tree映射对比
Learning Tree实现均匀映射的原理阐述如下.首先,利用大量内容名称构建神经网络模型的训练数据集,按照字符串值对其进行排序,并将排序后的序号作为标签与内容名称一一标定.其次,利用该训练集训练神经网络,学习出能反映索引内容在存储器中分布情况的累积分布函数(cumulative distribution function,CDF).训练完成后,对于输入的数据,通过神经网络预测CDF值,将该值乘以映射表的大小即可得到该数据在映射表中的具体位置.CDF的均匀分布特性使得数据在映射表上的位置必将服从均匀分布.
基于上述思想,Learning Tree的结构设计如图2所示.该结构共包含3个单元:输入单元、模型单元和输出单元.

图2 Learning Tree基本结构
输入单元用于将变长的内容名称转变为固定维数的输入向量.假设输入向量的维数是,且一个长度为的内容名称可以视为一个维向量.对于长度的名称,令y=x(0<),y=0(<);对于>的名称,将每个元素拆分为一个子向量,然后令y等于所有子向量中第个元素执行按位异或运算的结果(0<).因此得到维输入向量.
模型单元设计为由小型BP神经网络(back propagation neural network,BPNN)[19]搭建的塔式两级结构,用于分类训练、预测CDF值.该塔式结构包括第1级1个BPNN、第2级1000个BPNN.其中,第1级BPNN输出1000个分类值,第2级BPNN输出预测的CDF值,以支持转发平面百万级别的数据分类索引需求.模型单元的训练过程简述如下.假设BPNN代表模型单元中第级的第个BPNN.首先,将训练集分类标定为编号从小到大的若干区域,对BPNN1.0进行训练.BPNN1.0分类训练结果的每个区域值对应一个BPNN2.k.随后,继续分别训练第2级的每个BPNN2.k,学习得到CDF函数的一个部分.最终训练完成后,所有BPNN2.k的预测范围将可以覆盖整个CDF.即,训练后的塔式神经网络将是一个CDF的预测函数.
输出单元部署一个Bitmap结构,用于获得实际存储器索引地址.其中,Bitmap被均分为若干个部分,其中每个槽记录名称数据插入该部分的顺序,以实现实际存储单元的动态内存分配.通过将模型单元已预测的CDF值乘以Bitmap中槽的总个数,即可得到Bitmap中的映射槽位置.最后,根据该槽所在部分对应的基地址和该槽中数字序号所代表的地址偏移量,即可求得实际存储器索引地址.
图2给出了一个训练完成后通过Learning Tree进行索引的实例.对于一个输入的NDN内容名称/NDN/TJU/maps,首先将其拆分并执行按位异或运算,以获得输入向量(26,116,98,97,66).随后,将该向量输入到模型单元.假设BPNN1.0计算得到的区域编号为2,则选择BPNN2.2进行CDF计算.假设BPNN2.2计算得到的CDF值为0.2,则该内容名称在Bitmap中的映射位置为0.2×15(槽个数)=3.由于位置3处在Bitmap分块的第一部分,且其中记录的数字序号为2,所以最终索引内容的实际地址等于第一部分对应的实际存储基地址加地址偏移量2.
2.2 模型单元参数选择
在Learning Tree的模型单元中,一个BPNN输入向量的维数和隐藏层神经元的个数会直接决定神经网络模型的分类准确率和输入冲突率,并影响索引结构的存储消耗和检索速度.本节通过分析不同参数设置下BPNN的性能,确定Learning Tree中最佳的BPNN参数.
参数分析结果如图3所示.图3(a)表明,当输入向量维数大于等于5时,系统的输入冲突率可远远低于1%,满足当前互联网对丢包率小于1%的要求[20];当输入向量维数小于等于6时,BPNN的分类准确率可达到80%以上.图3(b)表明,当隐藏层神经元数大于等于20时,分类准确率可稳定在85%左右.此外,考虑到模型的存储消耗和执行速度,参数选择应使模型尽可能小巧.因此,输入向量维数和隐藏层神经元个数分别确定为5和20,以实现满足分类准确率和输入冲突率要求的、简单可靠的BPNN.

图3 1个BPNN在不同参数设置下的性能分析
3 L-FIB的存储结构和数据检索算法
本节介绍了L-FIB的存储结构和名称数据检索算法.首先阐述其多级存储器的部署模式,然后展示其对兴趣包的转发信息检索和转发信息更新的操作流程.
3.1 L-FIB的存储结构
考虑到当前存储器硬件水平和名称数据检索速度的需求,L-FIB的存储结构采用多级存储器的部署模式.如图4所示,该存储结构由片内和片外两个存储单元构成.其中,片内存储单元使用高速存储器,部署多个与不同名称前缀组件数相对应的索引结构Learning Tree,以实现基于LNPM机制的名称数据快速索引;片外使用存储空间较大的低速存储器,部署多个与Learning Tree输出单元对应的FIB存储池,以存储实际转发信息.此外,对于片内索引结构Learning Tree可能产生的误判,在片外FIB存储池中使用链地址法来处理冲突,即映射到相同地址的数据以链表的形式连接.
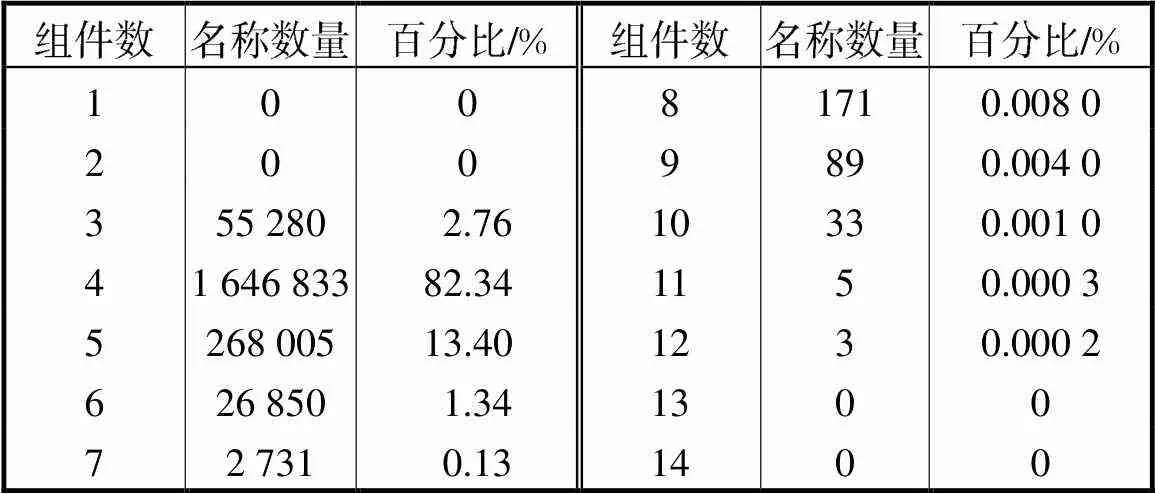
为了确定片内存储单元中所需部署的索引结构Learning Tree的数量,需要统计名称前缀组件数的分布特点.统计结果如表1所示,对于200万条名称数据,名称前缀组件数的分布非常集中,组件数为4的内容名称占总数的82.34%,组件数为其他的所有内容名称只占总数的17.66%.因此,L-FIB的片内存储单元部署两个索引结构Learning Tree即可满足设计要求,其中,第1个Learning Tree对应组件数为4的内容名称,第2个Learning Tree对应组件数为其他的内容名称.
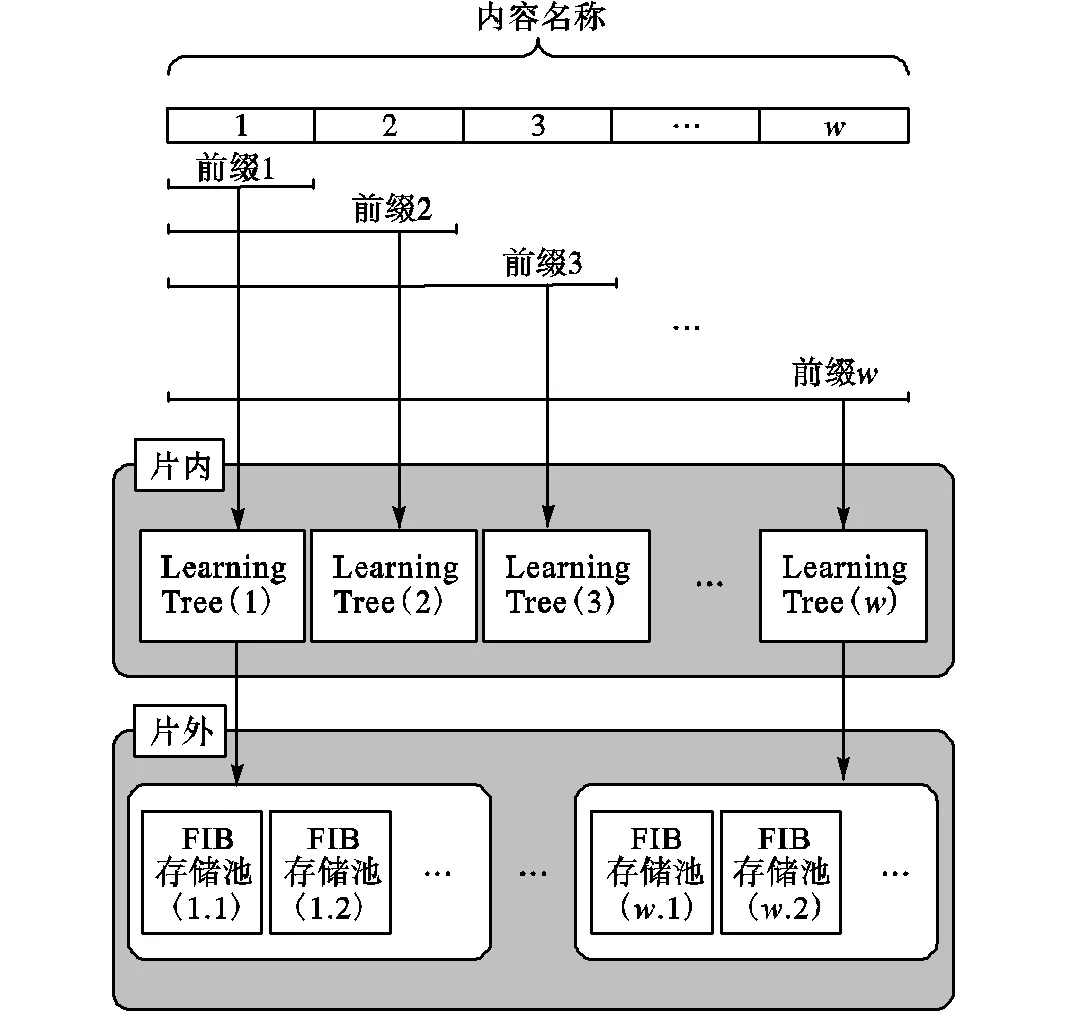
图4 L-FIB的存储结构
表1 名称前缀组件数统计
Tab.1 Number of names under different numbers of components
3.2 L-FIB的数据检索算法
命名数据网FIB工作机制包括对兴趣包的转发信息检索操作和转发信息更新操作.因此,本小节描述了L-FIB的上述操作算法.
L-FIB对兴趣包的转发信息检索过程包括以下步骤.
(1) 片内输入处理:输入名称前缀,拆分为若干子向量,然后对所有子向量中相同位置的元素执行按位异或运算,得到定长输入向量.
(2) 片内模型运算:将定长输入向量输入模型单元,计算预测的CDF值.
(3) 片内位置映射:将已预测的CDF值乘以Bitmap中槽的总数,得到Bitmap中的映射槽位置.
(4) 片内数据存在性判断:如果该槽的值不为0,则继续;如果为0,则说明不在该FIB中,输出检索结果“无法匹配”,结束.
(5) 片内索引地址计算:根据该槽所在部分对应的基地址和该槽中数字序号所代表的地址偏移量求得索引地址.
(6) 片外转发信息输出:根据索引地址访问片外FIB存储池,输出下一跳路由转发信息,结束.
L-FIB对转发信息更新的过程包括以下步骤.
(1) 片内输入处理:输入名称前缀,拆分为若干子向量,然后对所有子向量中相同位置的元素执行按位异或运算,得到定长输入向量.
(2) 片内模型运算:将定长输入向量输入模型单元,计算预测的CDF值.
(3) 片内位置映射:将已预测的CDF值乘以Bitmap中槽的总数,得到Bitmap中的映射槽位置,并计算该槽所在的部分.
(4) 片内更新类型判断:如果更新类型为“添加”,则继续;如果为“修改”,则转到(7);如果为“删除”,则转到(8).
(5) 片内添加操作:将插入与其前缀长度对应的Learning Tree中,并计算索引地址.
(6) 片外添加操作:根据索引地址访问片外FIB存储池,插入相应的路由转发信息,结束.
(7) 片外修改操作:计算索引地址,访问片外FIB存储池,修改相应的路由转发信息,结束.
(8) 片外删除操作:计算索引地址,访问片外FIB存储池,删除相应的路由转发信息.
(9) 片内删除操作:Bitmap中该槽清零,结束.
4 L-FIB性能评价
本节从误判概率、存储消耗和吞吐量3方面,通过与Binary Patricia Trie-FIB[11]、哈希表(Hash Table,HT)-FIB[21]以及B-MaFIB[17]进行比较,来评估L-FIB的性能.
4.1 实验设置
所有实验均在一台配置为Intel Xeon E5-1650 v2 3.50GHz、DDR3 24GB SDRAM的小型工作站上进行.对神经网络模型的训练利用MATLAB神经网络工具箱实现.训练完成后,提取模型的权重和偏置参数,然后利用C++语言实现L-FIB.考虑到实验对比的公平性,Binary Patricia Trie-FIB、HT-FIB和B-MaFIB同样使用C++语言实现.
L-FIB中,每个BPNN设置为5个输入神经元、20个隐藏神经元和1个输出神经元;Bitmap每个槽的大小设置为2bytes.Binary Patricia Trie-FIB中,每个地址指针为4bytes.HT-FIB分别采用MD5[21]、SHA1[21]和CityHash256[17]作为哈希函数实现,每个地址指针同样为4bytes.B-MaFIB中,Bloom filter大小设为224bit,定位数组大小设为24bit,Bitmap每个槽的大小设为2bytes.
实验名称数据使用当前互联网域名,因为命名数据网内容名称由结构化的变长字符串构成,与域名类似[3].考虑到转发平面FIB条目数可达超百万级 别[7],实验训练集包含1亿个不同的域名,4个测试集分别包含50×104、100×104、150×104和200×104个不同的域名,具体信息如表2所示.
表2 实验数据集

Tab.2 Experimental dataset
4.2 误判概率
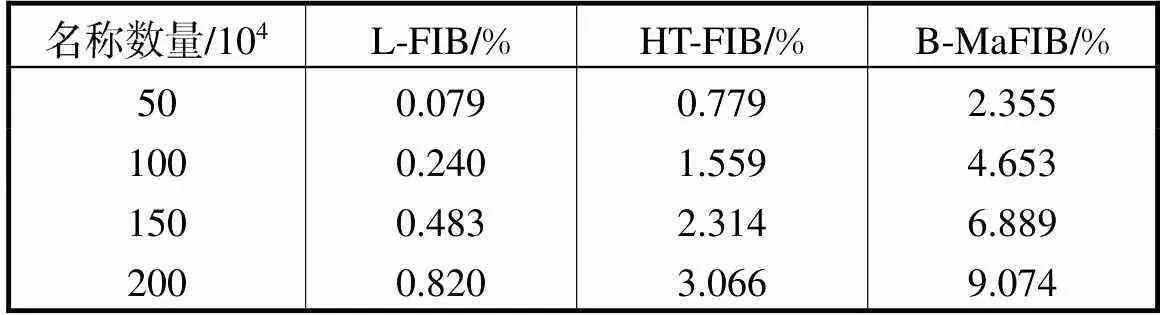
本小节针对L-FIB、HT-FIB和B-MaFIB的误判概率进行比较和分析.实验中,Bitmap和哈希表的槽个数均暂定为3200×104个,依次向L-FIB、HT-FIB和B-MaFIB中插入50×104、100×104、150×104和200×104个不同名称,记录误判概率.结果如图5和表3所示,L-FIB的误判概率分别为0.079%、0.240%、0.483%和0.820%,已满足当前互联网对丢包率低于1%的要求[20].相比之下,HT-FIB和B-MaFIB的误判概率远远高于L-FIB,B-MaFIB最高达到了9.074%,原因即在于其映射的不均匀性和大量的冲突.
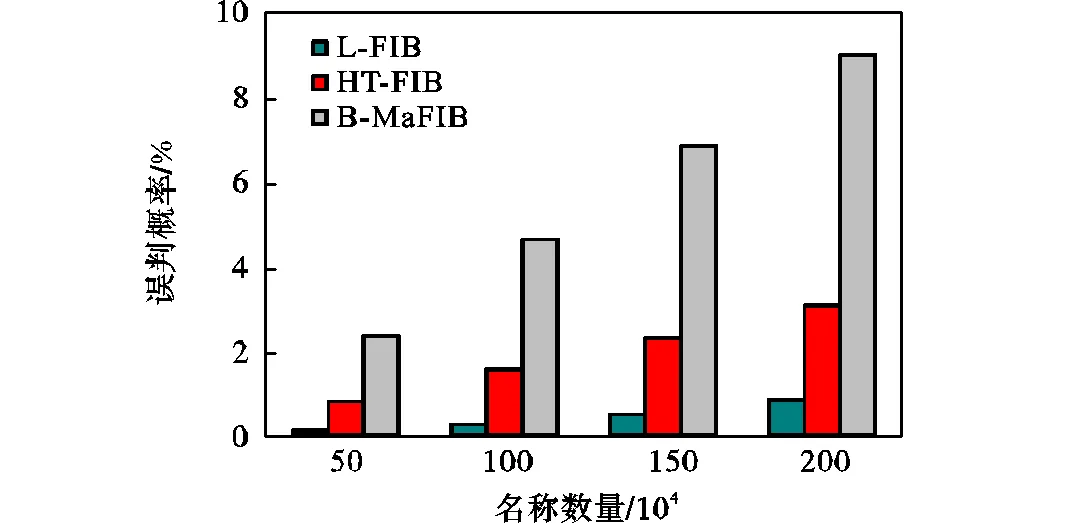
图5 L-FIB的误判概率性能分析
表3 L-FIB的误判概率性能分析
Tab.3 False positive probability of the L-FIB
4.3 存储消耗
对于相同的测试数据集,L-FIB、Binary Patricia Trie-FIB、HT-FIB和B-MaFIB存储转发信息所需的存储空间大小是相同的.因此,本小节将只对比分析各方案中索引结构的存储消耗.
对于L-FIB、HT-FIB和B-MaFIB,其索引结构的存储消耗主要由映射表的大小决定.因此,实验中首先测试了在误判概率低于1%[20]的条件下,L-FIB、HT-FIB和B-MaFIB索引结构的映射表所需槽总数.实验结果如表4所示,名称数量达到200×104个时,L-FIB的映射表需要2800×104个槽,而HT-FIB和B-MaFIB的映射表所需槽总数比L-FIB高约1~ 2个数量级.原因在于L-FIB通过学习数据的分布情况实现了更均匀的映射,提高了存储效率;而HT-FIB和B-MaFIB的地址映射都含有大量冲突,需要极大地增加映射表的大小才可将误判概率降到1%以下.
表4 不同名称数量下映射表所需槽总数

Tab.4 Number of slots required under different numbers of names 104
对于50×104、100×104、150×104和200×104个名称,由表4所示映射表的大小,得出L-FIB中Bitmap的存储消耗分别为8MB、20MB、34MB和56MB.对于L-FIB中的神经网络模型,每个BPNN由5个输入神经元、20个隐藏神经元和1个输出神经元组成,且两个Learning Tree共包含2002个BPNN,得出神经网络模型的存储消耗为(20×5+20×1+1×20+1×1)×8B×2002≈2.258MB.因此,对于4组不同数量的名称数据,L-FIB中索引结构的存储消耗总计分别为10.258MB、22.258MB、36.258MB和58.258MB.
图6显示了L-FIB和其他方案中的索引结构存储消耗性能对比.相比之下,L-FIB和Binary Patricia Trie-FIB的索引结构存储消耗更低,因为L-FIB通过相对均匀的映射提高了存储效率,Binary Patricia Trie-FIB通过相同前缀的比特级集成降低了存储消耗.表5给出了更详细的结果.一个4SRAM线卡的最大存储空间可达128.746MB[11],如表6所示,因此L-FIB的片内存储单元能够使用高速存储器SRAM,部署其索引结构.而HT-FIB和B-MaFIB的索引 结构都需要较大的存储空间,难以完全部署在SRAM上.

图6 L-FIB的存储消耗性能分析
表5 L-FIB的存储消耗性能分析

Tab.5 Memory consumption of the L-FIB
表6 当前线卡存储器技术指标

Tab.6 Memory devices in a line card
4.4 吞吐量
图7给出了L-FIB和其他对比方案的吞吐量性能,更详细的结果如表7所示.由于L-FIB和Binary Patricia Trie-FIB可以完全将索引结构部署在SRAM上,因此它们的吞吐量远远大于其他方案.在这两者之间,L-FIB的性能更优,吞吐量可以达到大约11.64×106数据包/s,因为L-FIB中的神经网络模型足够小巧,能够在命名数据网转发平面中快速运行.Binary Patricia Trie-FIB的吞吐量比L-FIB稍低,原因在于Binary Patricia Trie较高的深度影响了名称数据检索的速度.而HT-FIB和B-MaFIB的索引结构需要较大的存储空间,必须完全部署或部分部署在DRAM上,因此它们的吞吐量大大降低,难以满足当前互联网对数据包快速处理的要求.

图7 L-FIB的吞吐量性能分析
表7 L-FIB的吞吐量性能分析

Tab.7 Throughput of the L-FIB
5 结 语
本文提出了基于神经网络的命名数据网学习型FIB整体方案,L-FIB.具体地,首先介绍了L-FIB的索引结构Learning Tree,然后在此基础上设计了L-FIB的存储结构和数据检索算法,以提高存储效率,有效支持LNPM机制,并提高名称数据检索速度.实验结果表明,在误判概率为1%的条件下L-FIB的索引结构存储消耗为58.258MB,L-FIB的实际吞吐量约为11.64×106数据包/s,综合性能明显优于对比方案.未来的工作是将L-FIB以多线程实现,并测试其在实际通信环境下的误判概率、存储消耗和吞吐量等性能指标,验证其在命名数据网中的实际工作性能.
[1] 卫津津,金志刚,张瑞. 面向网络传输的立体视频QoE评价模型[J]. 天津大学学报:自然科学与工程技术版,2016,49(12):1248-1254.
Wei Jinjin,Jin Zhigang,Zhang Rui. QoE evaluation model for stereoscopic video network business[J]. Journal of Tianjin University:Science and Technology,2016,49(12):1248-1254(in Chinese).
[2] 孙立军,刘艺伟. 流量计校准网络监控管理系统[J]. 天津大学学报:自然科学与工程技术版,2018,51(8):825-831.
Sun Lijun,Liu Yiwei. Monitoring and management system for flowmeter calibration network[J]. Journal of Tianjin University:Science and Technology,2018,51(8):825-831(in Chinese).
[3] Zhang L,Estrin D,Burke J,et al. Named Data Networking(NDN)Project[EB/OL]. http://named-data.net/,2010-10-31.
[4] 石建,李卓,刘开华,等. 基于内容中心网络的高速铁路通信系统架构研究[J]. 天津大学学报:自然科学与工程技术版,2016,49(12):1236-1242.
Shi Jian,Li Zhuo,Liu Kaihua,et al. Research on high speed railway communication system based on named data networking[J]. Journal of Tianjin University:Science and Technology,2016,49(12):1236-1242(in Chinese).
[5] Zhang L,Afanasyev A,Burke J,et al. Named data networking[J]. ACM SIGCOMM Computer Communication Review,2014,44(3):66-73.
[6] Li Z,Xu Y,Zhang B,et al. Packet forwarding in named data networking requirements and survey of solutions[J]. IEEE Communications Surveys & Tutorials,2018,21(2):1950-1987.
[7] Yi C,Afanasyev A,Wang L,et al. Adaptive forwarding in named data networking[J]. ACM SIGCOMM Computer Communication Review,2012,42(3):62-67.
[8] Ghasemi C,Yousefi H,Shin K G,et al. A fast and memory-efficient trie structure for name-based packet forwarding[C]//2018 IEEE 26th International Conference on Network Protocols. Cambridge,UK,2018:302-312.
[9] Dai H,Liu B. CONSERT:Constructing optimal name-based routing tables[J]. Computer Networks,2016,94(1):62-79.
[10] Lee J,Lim H. A new name prefix trie with path compression[C]//2016 IEEE International Conference on Consumer Electronics-Asia. Seoul,Korea,2016:1-4.
[11] Song T,Yuan H,Crowley P,et al. Scalable name-based packet forwarding:From millions to billions[C]//Proceedings of the 2nd ACM Conference on Information-Centric Networking. San Francisco,USA,2015:19-28.
[12] Yuan H. Data Structures and Algorithms for Scalable NDN Forwarding[D]. St Louis:School of Engineering & Applied Science,Washington University in St. Louis,2015.
[13] Yuan H,Crowley P. Reliably scalable name prefix lookup[C]//Proceedings of the 11th ACM/IEEE Symposium on Architectures for Networking and Communications Systems. Oakland,USA,2015:111-121.
[14] Wang Y,Pan T,Mi Z,et al. Namefilter:Achieving fast name lookup with low memory cost via applying two-stage Bloom filters[C]//2013 Proceedings IEEE INFOCOM. Turin,Italy,2013:95-99.
[15] Dai H,Lu J,Wang Y,et al. BFAST:High-speed and memory-efficient approach for NDN forwarding engine[J]. IEEE/ACM Transactions on Networking,2017,25(2):1235-1248.
[16] Li Z,Liu K,Liu D,et al. Hybrid wireless networks with FIB-based named data networking[J]. EURASIP Journal on Wireless Communications and Networking,2017,2017(1):54-60.
[17] Li Z,Xu Y,Liu K,et al. 5G with B-MaFIB based named data networking[J]. IEEE Access,2018,6(1):30501-30507.
[18] Yuan H,Song T,Crowley P. Scalable NDN forwarding:Concepts,issues and principles[C]//2012 21st International Conference on Computer Communications and Networks. Munich,Germany,2012:1-9.
[19] Rumelhart D E,Hinton G E,Williams R J. Learning representations by back-propagating errors[J]. Nature,1986,323(6088):533-536.
[20] You W,Mathieu B,Truong P,et al. DiPIT:A distributed bloom-filter based PIT table for CCN nodes[C]//2012 21st International Conference on Computer Communications and Networks. Munich,Germany,2012:1-7.
[21] Kirsch A,Mitzenmacher M,Varghese G. Hash-based techniques for high-speed packet processing[G]//Algori-thms for Next Generation Networks. London,UK:Springer,2010:181-218.
A Learning Forwarding Information Base for Named Data Networking with Neural Networks
Liu Kaihua,Yan Liu,Li Zhuo,Gong Xiaolin,Peng Peng,Wang Binzhi
(School of Microelectronics,Tianjin University,Tianjin 300072,China)
Designing an effective forwarding information base(FIB)for named data networking(NDN)is a major challenge within the overall NDN research area,since an FIB has to perform fast lookups for complex names,provide high capacity,and accurately support the mechanism of longest name prefix matching (LNPM). Therefore,a learning FIB based on neural networks,called L-FIB,was proposed. First,the index of L-FIB,named Learning Tree,used a two-level neural network model to learn the distribution characteristic of data indexed in static memory,which achieved more uniform mapping,reduced the false positive probability and improved memory utili-zation. Second,the storage structure and name lookup algorithms of L-FIB were put forward. The on-chip memory using SRAMs deployed multiple Learning Trees corresponding to the name prefixes with different numbers of compo-nents,while the off-chip memory using DRAMs deployed multiple FIB stores corresponding to the Learning Trees. The name lookup algorithms were also described to implement the retrieval of forwarding information for the Interest packets and the update of forwarding information. This well supported the LNPM mechanism and realized fast name lookups. Experimental results showed that the overall performance of L-FIB was superior to the compared schemes in terms of false positive probability,memory consumption,and the throughput. The index of L-FIB significantly re-duced memory consumption to 58.258MB with the probability of false positive<1%,which meant it was deployable on SRAMs in commercial line cards. The throughput of L-FIB was about 11.64 million packets per second,which met current network requirements for fast packet processing.
named data networking(NDN);forwarding information base(FIB);neural network;name lookup
the National Natural Science Foundation of China(No.61602346).
TP393.0
A
0493-2137(2020)08-0825-08
10.11784/tdxbz201905032
2019-05-09;
2019-08-29.
刘开华(1956— ),男,博士,教授,liukaihua@tju.edu.cn.Email:m_bigm@tju.edu.cn
李卓,zli@tju.edu.cn.
国家自然科学基金资助项目(61602346).
(责任编辑:王晓燕)
