基于协同过滤的改进课程推荐算法
2020-06-02尚立
尚 立
近年来,高校开始广泛采用选课制,选修课的开设本身也是为了培养多元化、个性化的人才,目前高校的选课系统中存放着大量的、多方面的选修课,面对这些课程,学生需要在段时间内找到符合自身兴趣偏好的课程。根据高校教务选课平台所提供的课程信息,学生难以第一时间找到符合要求的课程,同时因为多数学生盲目选课,使得一些优秀课程长期被忽视或是无人选修。与此同时,个性化推荐系统在电子商务、电影平台和音乐平台的技术应用越来越成熟,网站可以根据用户的历史浏览记录、用户的购买(观看)记录、用户收藏记录等,推荐类似的产品,降低用户查找和选择难度,例如亚马逊、网易云音乐等。
目前,国内大部分高校仍然采用的传统的搜索配合试听让学生选择选修课程,少部分采用了比较弱化的推荐,即根据学生专业推荐相近课程,或者逆向推荐,即向文科学生推荐理工科课程,以上方式并不能根据学生自身的需求为他们得到想要学习的课程。有鉴于此,本文将推荐算法应用于选课系统中,在使用学生历史选课行为记录进行协同过滤推荐的基础上,增加了对课程简介的文本内容挖掘,通过用户行为和文本向量共同计算课程之间的余弦相似度,提高推荐的准确性,满足用户的需求。
1 一种改进相似度计算的协同过滤推荐算法
1.1 协同过滤算法
基于协同过滤思想的推荐系统是基于一个思想,即相似的用户可能会有相似的偏好或者相似的物品可能会被相似的用户所偏好[1]。协同过滤有两类:
1)基于用户[2]。根据用户行为记录,找到和目标用户兴趣偏好相似的用户集合,进而找到相似用户集合中每个用户所喜欢的物品,过滤掉目标用户已经产生过行为的物品,最后推荐给目标用户。表示用户所喜欢的物品集合,是用户所喜欢的物品集合,和的用户相似度通过公式1 所示的余弦相似度计算。
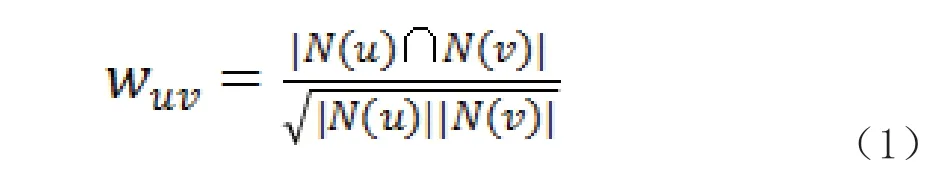
利用相似度公式计算得到的用户相似度矩阵,预测目标用户对相似用户所喜欢的物品的评分。用户对物品的预测评分计算公式为式2[3]。
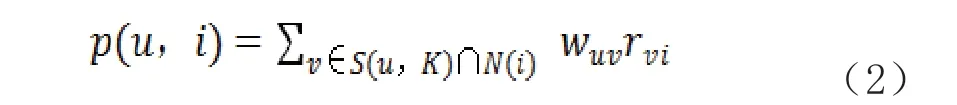
其中表示与用户最相似的个用户,即近邻,为喜欢物品的用户集合,为用户和用户的用户相似度,为用户对物品的真实评分。
2)基于物品[4]。根据用户行为记录,计算物品之间的相似度,过滤出目标用户所产生过行为的物品集合中该用户评分高的物品集合,根据物品相似度矩阵,分别找出集合中每个物品最相似的个物品,通过排序同时过滤目标用户已经产生过行为的物品,最后向目标用户推荐物品。表示喜欢物品的用户数,表示喜欢物品的用户数,物品和的相似度通过公式3 所示的余弦相似度计算。

然后根据式4 计算用户对物品的兴趣偏好程度[3]。
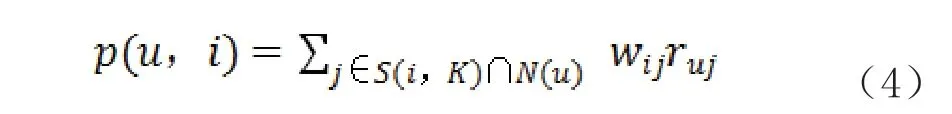
1.2 基于TF-IDF 的文本相似度计算
本文为了增加课程特征对课程相似度的影响,使用TF-IDF 理论从课程简介的文本中提取文本向量,进而计算课程相似度,TF-IDF 模型的核心思想是,将一段文本看作是词汇的集合,通过TF-IDF 模型为每个词赋予一个权重值,最终将原来的文本表示为向量的形式,即将文本相似度的计算问题转化为计算向量相似度。该模型主要包含了两个因素[6]:
1)词频(Term Frequency,TF),即词在文本中出现的频率,频率越大意味该词对该文本的贡献越大,通过公式5 计算

其中是词在文档中出现的次数,分母表示文本中所有词汇出现的次数总和。
2)逆文档频率(Inverse Document Frequency,IDF),即词在其它文本中出现的频率,频率越大,表示该词被使用的更广泛,代表性越低,也更难以代表文本,通过公式6 计算
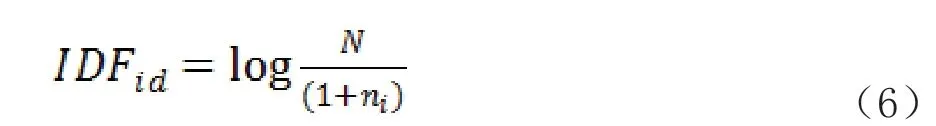
其中是语料库中的文本总数,即文本集合,表示文本集合中包含词的文本数量,如果不在文本集合中,就会导致分母为零,因此一般情况下使用。
最终通过公式7 得到词在某文本中的TF-IDF 值。

通过分词对文本集合中的每个文本中得到各自的一系列词串,对词串中的每个词求解其TF-IDF 值,得到该文本的文本向量,如,第p 个文本的文本向量可以表示为式8 的形式。
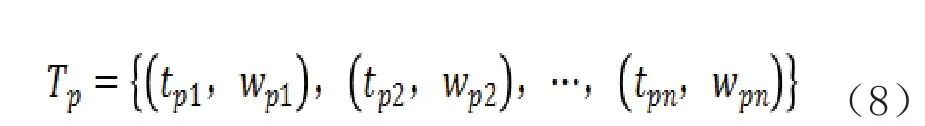
如前文1.1 节所述,基于用户(UserCF)和基于物品(ItemCF)的协同过滤都是推荐系统中常用的算法,UserCF 需要不断更新用户的相似度,ItemCF 更偏向于挖掘物品之间的相似性,课程推荐的应用场景特点决定了课程集合不会出现较大的变化,同时考虑到学生人数较多,因此本文采用ItemCF 作为课程推荐算法的改进基础。
利用余弦相似度式9 计算文本集合中每对文本的文本相似度作为课程相似度的补充。

所以改进的基于课程的协同过滤相似度为式10所示:
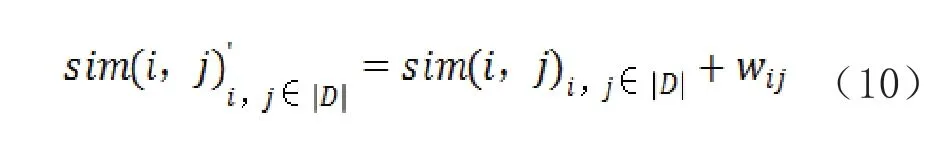
2 实验结果及分析
本节对提出的基于改进的协同过滤课程推荐算法进行评估,实验平台的配置如下:操作系统:Win10x64 位;CPU 为i7 处理器;开发语言及平台:Python+Microsoft VScode。实验数据选取中国传媒大学共2 000 名学生对400 门选修课的18 000 条选课记录和选修课各自的课程简介文本信息。
离线实验则采用4 折交叉验证的方式,即测试集占整个训练集的比例为25%,取4 次试验的均值作为每组参数的最终实验结果,分别在邻域K 为5,10,20,40,80,160 时,对ItemCF、UserCF,以及本文的相似度修正推荐算法进行对比,评估指标采用准确率precision 和召回率recall,按照以下式11 和12 分别计算[7]:
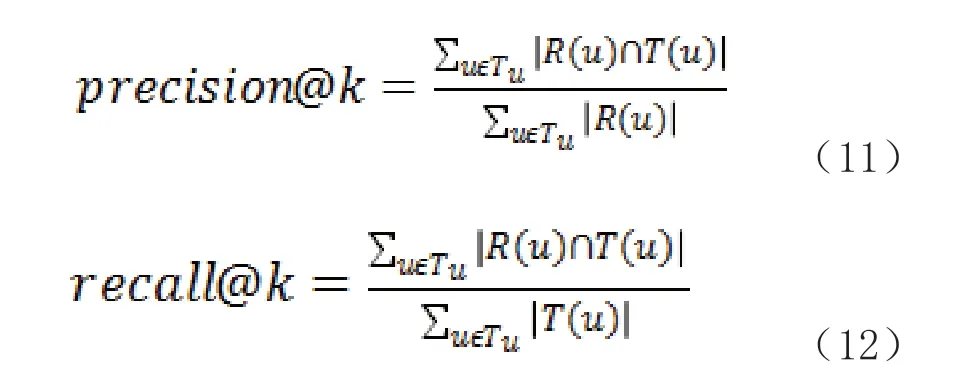
其中,表示邻域值,表示测试集中的用户集合,表示推荐给目标用户的推荐课程列表,表示测试集中目标用户的真实评价课程,准确率precision 反映的是查准率,即推荐列表中确实会被用户查看的课程所占比例,召回率recall 反映的是查全率,即会被用户查看的课程占用户所有查看课程的比例。
准确率、召回率实验结果分别如图1、图2 所示:
可以看到,对比UserCF、ItemCF,经过TF-IDF文本相似度优化后的协同过滤算法在准确率和召回率上均取得了提高。

图1 不同邻域K下precision对比结果
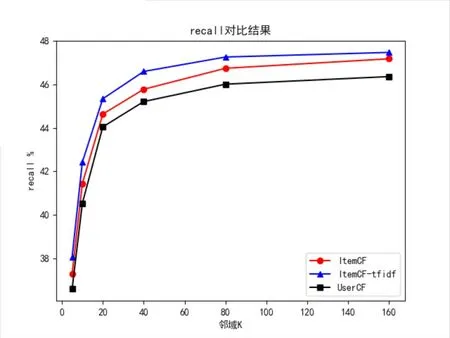
图2 不同邻域K下recall对比结果
3 结语
本文提出了一种基于文本相似度计算的协同过滤优化算法,实验结果表明了该模型的可行性,与基于用户和物品的协同过滤推荐相比,大大提高了推荐结果的准确率。对于未来的研究,将探索不同的融合策略对结果的影响,以尽可能地提升推荐的效果。
