基于DSP的无人机遥感影像SIFT算法设计与实现
2020-06-01赵海盟赵红颖
孙 鹏,肖 经,赵海盟,刘 帆,晏 磊,3,赵红颖
(1. 桂林电子科技大学机电工程学院,广西桂林541004;2. 空间信息集成与3S工程应用北京市重点实验室(北京大学),北京100871;3. 广西高校无人机遥测重点实验室(桂林航天工业学院),广西桂林541004)
(∗通信作者电子邮箱zhaohaimeng@guat.edu.cn)
0 引言
尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)算法[1]在无人机(Unmanned Aerial Vehicle,UAV)遥感影像特征点提取和匹配领域内扮演着重要角色,随着时间推移得到不断的发展和完善。
数字信号处理器(Digital Signal Processor,DSP)是一种适用于密集型数据运算与实时信号处理的微处理器[2]。现阶段,在高性能DSP 平台上实现部分复杂图像处理算法成为了DSP 应用研究的一个热点。在高性能DSP 平台上实现完整的SIFT 算法,可以减轻对主计算机中央处理器(Central Processing Unit,CPU)、图形处理器(Graphics Processing Unit,GPU)和高速缓存等资源的占用,特别是对图像算法处理过程中的定点、浮点迭代运算相比计算机平台处理速度更快。同时,DSP 平台具有体积小、功耗低和便于集成等优点[3],采用DSP 实现无人机遥感影像临场数据快速处理具有很大的优势。
前期,已经有一些人在DSP 上进行了SIFT 算法的部分研究。许飞等[4]在EVM6670L 平台上运行SIFT 算法时,基于进程间通信(Inter-Process Communication,IPC)模块实现4 核处理器协同处理;刘颜开等[5]在TMS320C6678 平台上实现8 核协同处理SIFT 算法。以上研究,既没有使用本文采用的DSP内核的硬件计算单元直接处理单精度浮点型像素数据的乘法计算,也没有充分发挥DSP的软件流水特长,对计算过程并未进行高质量的重新编排;此外,研究中处理的图像尺寸太小,远远小于本文实验采用的大尺寸无人机遥感图像,因此无法适应于无人机组网遥感影像的临场快速处理。
1 Rob-hess SIFT算法
SIFT算法是第一个通过稳健的描述子将一定程度的不变量与尺度、旋转、放射变换和光照联系起来描述局部特征的方法[6]。它被认为是计算机视觉研究的一个热点[7-8],也具有计算密集的特征[9-10]。
本文的参考对象为Rob-hess 基于OpenCV(Open source Computer Vision library)和C语言编译环境编写的通用SIFT算法程序。Rob-hess SIFT 算法实现特征点提取的主要过程如图1所示。

图1 Rob-hess SIFT算法的特征点提取流程Fig. 1 Feature point extraction flowchart by Rob-hess SIFT algorithm
2 SIFT算法在DSP平台上的实现
2.1 方案设计
德州仪器C66x系列DSP内核硬件的组成如图2所示。
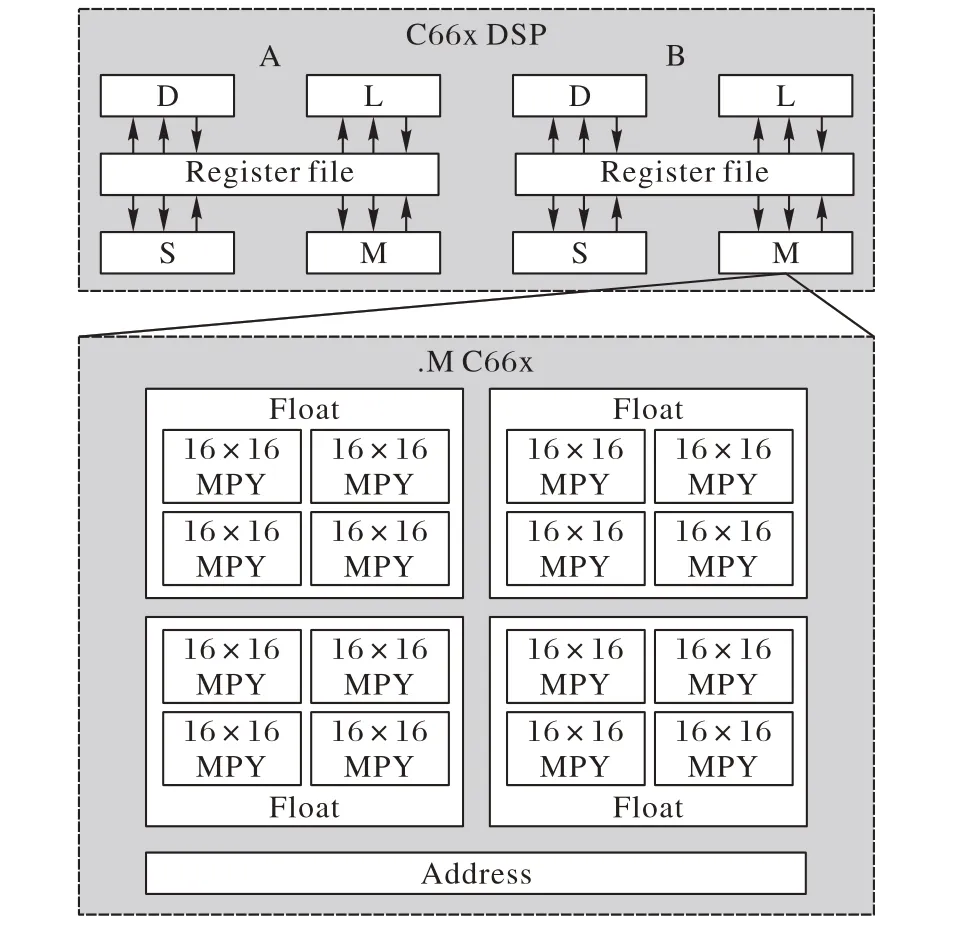
图2 C66x DSP内核Fig. 2 C66x DSP kernel
主要数据计算模块包括支持单精度浮点型数据运算的硬件乘法器(Hardware Multiplier,MPY)、累加器和双数据通道[11]。
为了充分发挥DSP 内核计算性能,本文重新设计了SIFT算法的图像数据结构、软件流水和动态数据存储。首先,重构图像数据结构和图像函数使得硬件乘法器可以直接参与单精度浮点型像素数据的乘法计算;其次,采用软件流水技术重新编排算法的循环计算,以增强算法计算的并行能力;最后,迁移算法产生的动态数据至片外第三代双倍速率同步动态随机存储器(Double Data Rate 3 synchronous dynamic random access memory,DDR3),以提升动态数据的存储空间。具体实现流程如图3所示。
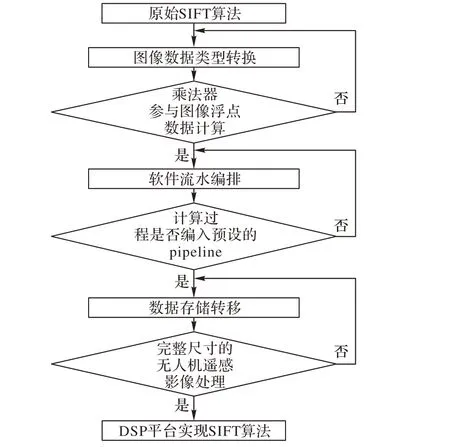
图3 DSP平台上SIFT算法的总体设计Fig. 3 Overall design of SIFT algorithm on DSP platform
2.2 图像数据类型转换
硬件计算单元直接参与数学计算可以提升计算的速度。但是,原始SIFT 算法使用char 型地址空间存储图像像素数据,使得DSP 内核的单精度浮点型硬件乘法器不能够直接计算算法单精度浮点型像素数据的乘法。
为了使DSP内核的硬件乘法器能够直接参与单精度浮点型像素数据的乘法计算,需要根据硬件乘法器的输入、输出特性对图像数据结构和图像函数进行重构,具体实现流程如图4所示。
1)IplImage图像数据结构的重构。
在SIFT 算法原始IplImage 图像数据结构中,char 型、float型像素数据都存储于char*型指针imageData 指定的地址空间。一个char 型图像像素数据存储于一个char 型存储空间内,一个float 型像素数据需要存储于4 个char 型存储空间内。由于,DSP 内核单精度浮点型硬件乘法器不能够参与char 型存储空间内数据的计算,无法发挥DSP 优良的单精度浮点型数据计算能力。
为了使单精度浮点型硬件乘法器可以直接计算SIFT 算法float 型像素数据的乘法,本文对算法的IplImage 图像数据结构进行重构。
首先,在IplImage结构中新增float*型指针imageData1,并使用该指针为float型像素数据分配存储空间;其次,在算法浮点运算段启用imageData1指针直接存储像素点的float型像素数据,实现float 型像素数据的存储空间类型由char 型转变为float 型;最后,对图像浮点型像素数据的计算过程进行调整,并在编译软件中启用硬件乘法器处理该型像素数据的乘法计算。新IplImage 结构中图像单精度浮点型像素数据访问形式如下。
新IplImage 结构中图像gray32 第row 行、第col 列像素点的浮点型像素数据访问形式如式(1)所示:
float_val=*(gray32->imageData1+
gray32->widthstep∗row+col) (1)
新IplImage 结构中图像gray32 第n 个浮点型像素数据的访问形式如式(2)所示:
float_val=*(gray32->imageData1+n) (2)其中:gray32 为一个IplImage 型结构体图像的起始地址;row、col 和n 为被定义的int 型变量;gray32->widthstep 为gray32 图像中每一行像素数据存储时占用的存储空间;gray32->imageData1为新数据结构中图像单精度浮点型像素数据的起始地址。
2)图像函数的重构。
原始SIFT 算法程序调用cvCreateImage 函数创建图像结构的首地址并根据图像头信息为结构体的像素数据分配适当存储空间。在图像创建过程中,调用的子函数主要包括创建图像头信息的函数cvCreateImageHeader 和为像素数据分配存储空间的函数cvCreateData。
原始图像像素数据存储空间的首地址由像素数据空间分配函数cvCreateData 提供。为了使新增加的imageData1 指针能够指向合法的存储空间,需要对函数cvCreateData 进行重构。当输入的图像像素数据类型为32 位float 型时,函数cvCreateData 的子函数ialloc 开始分配存储空间并将返回的地址强制转换为float*型;然后,将得到的float*型地址传递到指针imageData1。具体实现方式如式(3)所示:
img->imageData1=(float*)ialloc
((size_t)img->imageSize) (3)
其中:img->imageSize 为图像像素数据需要占据空间的大小(单位:字节),由图像的行、列和像素点数据类型决定;img->imageData1 为图像img 的单精度浮点型像素数据在新IplImage 结构中存储后返回的起始地址;iallco 为空间分配函数,在完成空间分配后会返回void*型起始地址(该地址可以被强制转换为其他类型)。
2.3 软件流水编排
2.3.1 编排设计
德州仪器C66x DSP 内核具有8 路超长指令字(Very Long Instruction Word,VLIW)、浮点数据路径[12]和8 组单精度浮点型硬件乘法器,内核主频高达1.25 GHz(Giga Hertz),浮点性能高达20 GFLOP(Giga Floating-point Operations per Second)。由于,其指令集架构(Instruction Set Architecture,ISA)是基于VLIW 架构,每个指令加载包的长度为256 位[13]。因此,在C66x 内核DSP 平台上使用的单指令多数据流(Single Instruction Multiple Data,SIMD)指令可以同时执行最多8 条32位指令。
使用软件流水技术对算法程序重新进行编排,使得编译器可以更加均衡地使用芯片内核的硬件资源;同时,部分无关联性指令的不同执行阶段可以被同时执行,缩短各指令执行时的等待间隔,可以更充分地发挥系统的并行计算能力。
软件流水编排的实质是:降低函数指针之间的关联性以增强计算的并行性能;将算法的子函数内嵌入主程序;对多层循环体进行简化与展开;使用软件流水技术将数据计算段编排到预设的pipeline 中;同时,结合CCS(Code Composer Studio)5.5 集成开发环境的DSP 软件流水优化功能,优化流水编排的层级,最大化使用硬件资源。采用四级流水编排前后的指令执行情况如图5所示。

图5 指令执行对比Fig. 5 Comparison of instruction execution
在图5 中,指令甲、乙与指令1、2、3、4、5 为处理器的相同执行指令。没有进行软件流水编排时,指令乙只能在指令甲完成写回操作后才可以得到执行。对算法程序运行重新编排后,程序中指令1 的写回、指令2 的执行、指令3 的译码和指令4 的预取操作可以被同时执行,缩短了指令的执行间隔。该处为流水编排后循环核的开始;指令2的写回、指令3的执行、指令4 的译码、指令5 的预取也会同时执行,为循环核的一部分;循环核左侧部分为流水循环填充(pipeline loop prolog);循环核右侧部分为流水循环排空(pipeline loop epilog)。图5中,同样的时钟周期内,原始程序仅可以执行甲、乙两条完整指令,而流水编排后的程序可以执行5 条完整指令,算法程序的计算速度得以提升。
流水编排的具体实现流程如图6所示。

图6 软件流水编排流程Fig. 6 Flowchart of software pipeline arrangement
2.3.2 具体实现
为了减少计算过程中输入、输出数据指针的关联性,在函数中使用restrict 和const 关键字以声明函数非关联性指针指向不同内存块。当函数输入、输出指针存在关联性且在计算独立时,需要对程序的输出指针进行调整;建立过渡内存块,并将输出指针指向过渡区块;完成计算后,再将过渡区块的内容拷贝到原始程序指定的内存块中。邻近插值函数变化如下。
原始源代码:
void resizeImg(IplImage*gray,IplImage*Big)
插入关键字后源代码:
void resizeImg(const IplImage*gray,IplImage*Big)
以上源代码中,gray 为输入指针,Big 为输出指针。在源代码中使用const关键字以声明输入、输出指针为非关联性指针且指向不同的内存块。
由于含有子函数的循环体无法通过优化器编排为一个pipeline。因此,需要将迭代计算调用的子函数内嵌入主程序循环体内。
此外,DSP 集成开发环境的编译器优化循环计算时,只在循环计算的内层中形成一个pipeline。因此,需要对多重循环计算进行简化和展开,使得计算可以更加充分地被编排入预设的pipeline。图像归一化的计算变化如下。
原始源代码:

以上源代码中,row3 和col3 是被定义的int 型变量;height1 和width1 为图像的每列、行像素点数目;alpha 为一浮点数;gray8->imageData 为归一化前图像像素数据起始地址;gray->imageData1 为归一化后图像像素数据起始地址。原始的算法计算程序只能将图像每一行像素数据的计算纳入pipeline,而简化后的计算程序可以将图像所有像素数据的计算都纳入pipeline,从而缩短了指令间等待时间。
软件编译器优化设置可以改善软件流水性能[14]。编译器优化选项使用如下:
1)启用Assume no irregular alias or loop be-havior,以声明程序中没有使用alasing技术。
2)设置Optimization level 为3,即选择-o3以进行文件级别的优化。
3)启用Program mode compilation,即使能-pm 以配合-o3使算法实现程序级别优化。
4)设置Specify call assumptions when opti-mizing 为3,选择-op3以控制程序的优化级。
5)设置Optimize for code size 为2,选择-ms2 以缩小代码的部分尺寸。
6)设置Generate optimizer information file at level 为2,选择-on2以生成优化信息文件。
2.4 数据存储迁移
SIFT 算法具有占用存储空间大的特征,处理1 000×750彩色正射影像时,主要内存占用情况如图7所示。分析图7可知:SIFT 算法处理1000 × 750 彩色影像时,构建高斯差分金字塔过程中需要的存储空间最大,约为168 MB;考虑到SIFT算法计算过程中的其他变量和特征点情况,处理1000 × 750彩色影像所需要的实际存储空间应大于168 MB。芯片内部的SHRAM(shared memory)存储空间为64 MB,不能够满足算法运行过程中的存储需求。
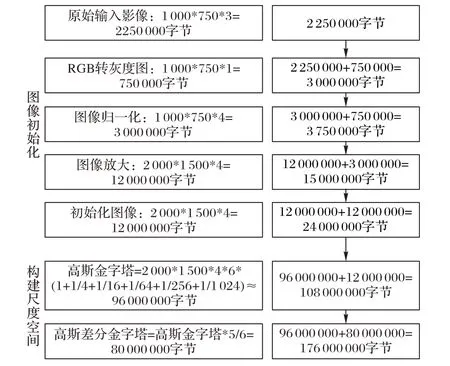
图7 主要内存分布Fig. 7 Main memory distribution
为了使DSP 平台SIFT 算法可以处理1 000×750 彩色正射影像,需要将算法的动态数据从芯片内部的SHRAM 转移至片外DDR3存储器。由于原始DDR3存储器内各子存储空间,也无法支持SIFT 算法的数据存储,因此需要将DDR3 存储器中不连续的原始子存储空间进行合并,以拓展存储器中的连续存储空间。
为了完成上述的存储迁移,需要调整存放链接器的配置信息CMD(算法工程中后缀为.cmd)文件。具体调整细节为:根据平台板载存储空间重新编写CMD 文件中的SECTIONS(目标存储器模型段)和MEMORY(硬件资源描述段)。
1)CMD文件的SECTIONS编写。
德州仪器C66x DSP 内核的片内内存与CPU 保持相同的时钟频率。但是,片内存储空间过小,不适应大量数据的存放。在本文研究的过程中,使用DSP 平台搭载的DDR3 存储器存储SIFT 算法计算产生的动态数据,改变动态数据存储空间的具体方式如下。
在新创建图像结构体分配内存时,直接采用了ialloc 函数,同时,需要调整CMD 文件中SECTIONS(目标存储器模型段)的描述代码,详细源代码变化如下。
原始CMD文件中动态内存的存储器模型描述源代码:
.sysmem >SHRAM
重新编写CMD 文件中动态内存的存储器模型描述源代码:
.sysmem >DDR3
2)CMD文件的MEMORY编写。
CMD 文件的MEMORY 代码段用于描述系统实际硬件资源配置。为了充分使用DDR3 存储器的存储空间,需要将存储器内不连续的硬件描述区域合并为一个以DDR3 为名称的连续存储空间,具体的硬件描述源代码变换如下。
原始DDR3存储器地址空间的硬件描述源代码:
DDR3:origin=0x80000000 length=0x10000000
DDR3A:origin=0x90000000 length=0x10000000
DDR3B:origin=0xA0000000 length=0x10000000
合并后DDR3存储器地址空间的硬件描述源代码:
DDR3:origin=0x80000000 length=0x7FFFFFFF
在以上代码中,DDR3、DDR3A、DDR3B 分别为DDR3 存储器内子存储空间的名称;origin 表示该子存储空间的起始地址;length 表示该子存储空间的有效长度;DSP 平台实际搭载的DDR3 存储器起始地址为0x80000000,有效长度为0x7FFFFFFF(容量为2 GB),该容量远大于SHRAM 内64 MB存储空间。
通过重新编写CMD 文件SECTIONS 和MEMORY,将DSP硬件平台DDR3 存储器内不连续的存储空间转变为连续的存储空间,并将SIFT 算法的动态数据迁移至该段连续的存储空间内,为算法处理较大尺寸的图像打下了基础。
3 实验与结果分析
3.1 硬件平台设计
根据上述方案,选择德州仪器66AKH12 处理器作为DSP硬件平台主处理器,平台如图8 所示。66AKH12 是基于KeyStone Ⅱ架构的高性能处理器,主处理器内部集成了8 核的C66x 内核组和4 核的ARM(Advanced RISC Machine)A15内核组[15]。XDS(Extended Debugging Simulator)200mini 模块为仿真器;MiniUSB(Universal Serial Bus)接口固定在仿真器上,用于与外部连接。
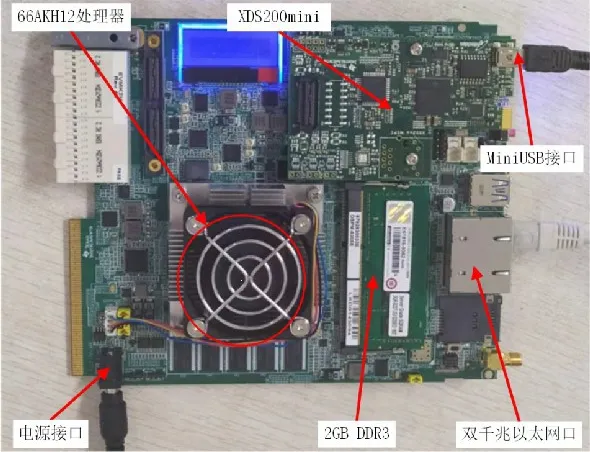
图8 DSP测试平台Fig. 8 DSP test platform
在实验中,设置C66x 内核组的0 核作为处理器核,配置DSP 的时钟频率为1.2 GHz。测试平台通过硬件Board to Board 连接器连接至XDS200mini 模块,并使用MiniUSB 电缆将XDS200mini 连接至PC。PC 平台的CCS 5.5 软件集成开发环境用于程序的调试、加载和中断等。运行设计如图9 所示。测试图像为一无人机遥感任务采集的正射彩色影像,原始影像尺寸为1 000 × 750,如图10所示。

图9 硬件运行设计Fig. 9 Hardware running design

图10 测试图像Fig. 10 Test image
3.2 结果分析
1)算法精度分析。
DSP为32位处理器,原始SIFT算法程序的处理平台为64位处理器。由于,32位处理器与64位处理器数据总线位数的不同,在数据长度为64 位double 型数据的计算过程中会产生相应的计算误差;而且,在不修改计算数据的数据类型时,该部分的计算误差会一直存在。由于在构建高斯尺度空间的计算过程中进行了大量的double 型数据的乘法、加法和减法迭代计算,因此DSP 平台SIFT 算法程序与原始SIFT 程序所提取特征点坐标、尺度、方向的小数部分和128 维特征描述子也会存在相应的差异。不同平台SIFT 算法的实际处理情况如图11所示。
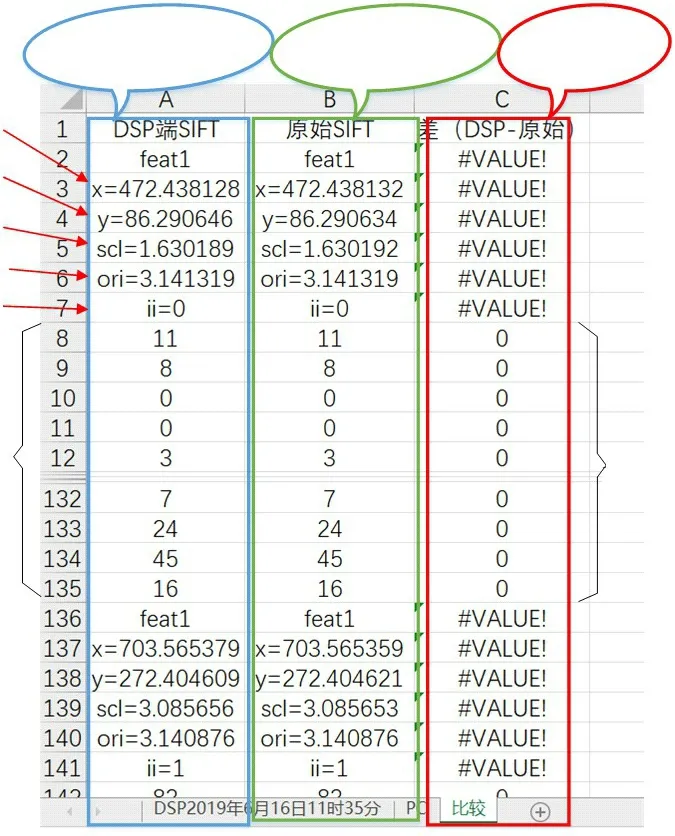
图11 不同平台的特征点处理结果Fig. 11 Processing results of feature points on different platforms
图11 中A、B 列分别为DSP 平台SIFT 算法程序和原始SIFT 算法程序提取的特征点信息,C 列为DSP 平台SIFT 算法程序提取的特征点数据与原始算法提取数据之差。在A、B列中feat1 为1 000×750 测试图像(如图10 所示)的名字。x、y 为提取特征点的坐标信息,scl 为特征点的尺度,ori 为特征点的方向角,ii 为特征点的编号;从第8 行到第135 行数据为特征点0 的128 维特征描述子;分析C 列可以发现,算法在不同平台上提取特征点0 的描述子信息误差为0,特征点0 坐标、尺度的小数部分存在细小的误差(此误差由处理器之间硬件差异造成)。由于EXCLE 表格中第2 行到第7 行的特征信息数据不是单一数值,因此,在进行不同平台特征点信息逐差计算的过程中,此处系统自动使用“#VALUE!”以表示“引用单元格错误”。由于图11 无法展示全体特征点的特征信息,因此使用表1对该信息进行统计。

表1 特征点信息(1000 × 750)Tab. 1 Information of feature points(1000 × 750)
分析表1 可以发现,处理测试的1000 × 750 图像时,本研究的DSP 平台SIFT 算法程序与原始算法程序的处理结果保持高度一致:两个平台提取的特征点数量和特征点坐标信息保持一致,在3 324 个相同坐标特征点所对应的特征描述子中,相同描述子比例的高达99.97%;可见DSP 平台SIFT 算法程序对图像特征点的识别、描述能力与原始算法程序基本保持一致。由于使用特征点信息进行图像匹配时,处理过程对图像特征点的坐标、尺度、方向角和128 维特征描述子的误差要求远大于本研究算法程序的提取误差,因此,该算法程序完全满足临场实时快速处理无人机组网遥感影像的精度需求。
2)耗时分析。
DSP 平台SIFT 算法的运行时间由CCS 5.5 软件自带Count Event模块统计。详细实验结果如图12所示。
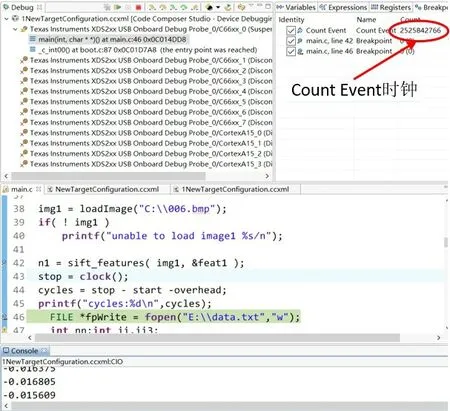
图12 DSP平台运行的SIFT算法Fig. 12 SIFT algorithm running on DSP platform
实验中,处理器为C66x 内核组的0 核,主频为1.2 GHz。当程序运行至图12 第42 行时,受到间断点的限制,板载仿真在此处暂停;此时,Count Event模块统计的时钟显示图像预处理耗时,此处耗时不计入SIFT 算法的总耗时。点击继续运行后,Count Event 模块自动清零并开始重新统计CPU 运行时钟数据,SIFT 算法程序开始被执行;当程序运行至第46行时,板载仿真进入暂停,此时Count Event 模块统计的时钟显示SIFT算法处理1000 × 750 影像所消耗的CPU 时钟数据。由图12分析可得,在特征点提取过程中,DSP平台SIFT算法程序共消耗2 525 842 766 个CPU 时钟周期,约为2.53 GHz。结合DSP主频配置和表1 分析可得:在确保提取到高质量特征点坐标、尺度、方向和特征描述子前提下,DSP 平台的0 核运行本文的SIFT 算法程序处理测试的1000 × 750图像需要运行2.108 s,满足在单核处理器平台上临场实时快速处理无人机组网遥感影像的时间要求。
4 结语
本文基于DSP平台的软硬件资源实现了具有完整功能的Rob-hess SIFT算法。通过对图像数据结构、图像函数的重构、软件流水的重新编排和动态数据存储空间的迁移,实现了对大尺寸无人机遥感图像的高精度快速处理。实验结果表明,本文算法的精度、运行耗时和处理图像的尺寸满足临场处理需求。
下一步,可以对数据的输入输出接口进行深入设计,实现无人机遥感影像数据在PC 和DSP 间的快速交互。同时,在DSP 开发的过程中,进行多任务调度实现可以进一步提升处理速度。
