基于传播和时间权重的协同过滤新书推荐算法*
2020-05-29杨迎方邓长寿
彭 虎 杨迎方 邓长寿
(九江学院信息科学与技术学院 江西九江 332005)
1 概述
随着互联网及硬件的发展,数据量呈现出几何式增长的趋势[1],从而加速了大数据人工智能时代的到来。其中,“数字化图书馆个性化服务”的概念逐渐被提出,读者对新书推荐等个性化服务产生了更大的需求[2-3]。目前热门的在线图书网站中,亚马逊能针对特定用户提供不同的新书籍推荐明细[4],而豆瓣图书利用挖掘算法向读者提供Top250类的图书推荐榜单[5]。毫无疑问,个性化推荐技术在当前的图书推荐领域仍有着广阔的研究前景。
当前的个性化推荐领域中,协同过滤是其中发展较为成熟的一种推荐算法,但也不可避免地存在冷启动、稀疏性及可扩展性等一系列关键性问题[6]。对于稀疏性问题,由于协同过滤主要依据为用户对项目的偏好信息,而用户仅仅评价少量项目就会导致用户-项目偏好矩阵成为高维稀疏矩阵,从而导致推荐精度下降。对于可扩展性问题,随着用户和项目的基数不断扩大,用户-项目偏好矩阵规模庞大,算法进行相似度计算和预测评分的工作量急剧增加,导致实时性下降。而当用户数据的时间跨度较大时仍对所有用户偏好信息等同对待,显然不是合理的推荐方式,忽视了新书推荐的时效性[7]。毫无疑问,对用户偏好数据的正确使用,有助于提高协同过滤在新书推荐场景中的推荐质量。
因此,文章提出了一种基于相似度传播和时间综合权重的协同过滤新书推荐算法,依据数据量划分三个数据阶段,不同阶段动态选择适合的推荐方案,在相似度计算中采用传播思想以解决稀疏性问题,引入时间综合权重以应对可扩展性问题并提高推荐的时效性,具有重要的理论与实践意义。
2 协同过滤
2.1 协同过滤算法
协同过滤(collaborative filtering,CF)是一种利用集体智慧的经典方法,即在用户群中找到与目标用户有着相似兴趣和偏好的用户,综合相似用户的偏好信息对目标用户进行喜好程度预测,并进一步为目标用户提供推荐。协同过滤一般可分为两大类:
(1)基于内存的协同过滤。数据量较小的应用场景下,采取直接在线使用的实时推荐方法。一般又分为基于用户的协同过滤和基于项目的协同过滤,这两种推荐算法目前在实际应用中得到了最广泛的使用。
(2)基于模型的协同过滤。依据历史数据得到模型,并依据模型进行预测评分。一般又分为聚类、关联规则、贝叶斯网络和机器学习分类等。
2.2 协同过滤原理
协同过滤能为不同对象进行推荐,且不受数据格式的影响,例如图书、音乐、电影等难以处理的复杂数据都可以进行推荐,并且能够挖掘出用户的潜在兴趣,生成的推荐具有较高价值。基本原理如下:
(1)收集用户偏好。用户的偏好分为显性和隐性收集,显性如评分、评论、投票,隐性如购买、查看等。在收集用户行为数据后,需要对数据进行处理,得到一个反映用户偏好的二维矩阵,一维是用户列表,另一维是项目列表,值为用户对项目的偏好信息。
(2)寻找相似邻居。相似度计算是协同过滤的核心,传统的测算距离方法主要有:基于相关系数的相似度、基于余弦相似度以及基于调整的余弦相似度等。
(3)生成推荐集,具体表现形式为预测推荐或TOP-N推荐。其中,预测推荐为产生一个预测评分值Rui,表示目标用户u对目标项目i的预测评分值。而TOP-N推荐为产生一个目标用户最喜欢的N个项目集合,表示目标用户未访问的项目中值得推荐的项目列表。
2.3 基于用户的协同过滤
尽管协同过滤种类繁多,但目前应用最广泛的仍然是基于内存的协同过滤,以下介绍具体的基于用户和基于项目的协同过滤算法原理。
基于用户的协同过滤算法的基本原理是:根据用户偏好信息,寻找与目标用户兴趣相似的最近邻居用户,依据相似邻居用户的偏好信息,为目标用户提供个性化推荐。
算法步骤如下:
输入 目标用户u、用户-项目偏好矩阵R。
输出 目标用户u的Top-N推荐集。
Step1 使用用户-项目偏好矩阵R以及选定的相似度计算方法,计算用户u和其他用户之间的相似度矩阵S。
Step2 根据得到的相似度矩阵S,为用户u选择k个最相近的相似近邻,建立相似近邻集合N={u1,u2,u3,……,uk},及相应的相似度Sim={s1,s2,…,sk}。
Step3 对目标用户u和所有相似近邻ui∈N,找出u的已评分项目集Iu和相似邻居的项目集Ii,将所有Ii取并集;然后去掉Ii中在Iu已存在的项目,生成候选推荐集C。
Step4 对候选推荐集∀j∈C,使用加权平均算法预测用户u的评分Ruj。
Step5 采用Top_N形式推荐,按预测评分降序排列,选择前N个项目作为推荐。
2.4 基于项目的协同过滤
基于项目的协同过滤的基本原理是:综合用户对项目的偏好信息,得到项目之间的相似性,进一步依据目标用户的历史偏好信息,将类似的项目推荐给用户。
算法步骤如下:
输入 目标用户u、用户-项目偏好矩阵R。
输出 目标用户u的Top-N推荐集。
Step1 使用用户-项目偏好矩阵R以及选定的相似度计算方法,计算项目间的相似度矩阵S。
Step2 找出用户u的已评分项目集Iu,对所有已评分项目i∈Iu读取S得到该项目的K最近邻居集Ni={i1,i2,……,ik},合并所有Ni并从中删除Iu中已经存在的项目,得到候选推荐集C。
Step3 对所有项目j∈C,在Iu中为该项目选择相似近邻,然后预测用户u对该项目的评分。
Step4 采用Top_N形式推荐,按预测评分降序排列,选择前N个项目作为推荐。
3 基于传播和时间权重的协同过滤算法
研究表明,协同过滤相比其它推荐算法在新书推荐中有较大优势,但还是存在稀疏性和可扩展性等问题,并且单一的协同过滤推荐难以适用于复杂的图书推荐应用场景。因此,对协同过滤的改进,有助于提高新书推荐算法的推荐质量。
文章提出一种基于相似度传播和时间综合权重的协同过滤(collaborative filtering based on similarity propagation and time comprehensive weight,PTCF),算法根据读者的偏好数据量划分三个数据阶段,不同阶段可动态选择适合的推荐方案,将传播的思想应用于相似度计算以解决稀疏性问题,并引入时间综合权重以应对可扩展性问题并提高新书推荐的时效性[8]。改进算法的核心原理如下:
3.1 初始阶段
初始阶段是指读者作为新用户刚刚进入推荐系统的阶段,在这一阶段读者的访问记录为零或接近于零,因而新书推荐受到冷启动问题的影响[9]。显然,这一阶段使用传统的基于内存协同过滤并不合适,由于用户偏好信息的匮乏,新书推荐结果的可靠性较低。
因此,初始推荐采用评分最优的推荐方案,由读者尚未阅读的图书生成候选推荐集,再汇总每本图书的平均评分作为该图书的预测评分值,最终以Top_N形式推荐给目标读者[10]。
3.2 稀疏阶段
稀疏阶段是指读者的偏好信息数据已初具规模,但用户-项目评分矩阵仍具有较大的稀疏性,使用一般性的基于内存协同过滤推荐效率有限,新书推荐结果的可信度难以保证[11]。目前,对于稀疏性问题的解决方法主要是填充用户-项目偏好矩阵,该种方法尽管有效,但是在实际应用中的效率一般[12-14]。
因此,稀疏推荐将传播的思想应用到相似度计算中,即充分利用目标用户的近邻以及近邻的相似邻居的偏好信息为用户进行新书推荐[15]。核心的相似度传播技术具体如下:
表1是稀疏的二维矩阵,若采用基于用户的协同过滤为用户u1推荐,则先找到u1相似邻居u3,然后根据u3的评分计算u1对i5的预测评分,显然,由于邻居个数及数据稀少会导致推荐精度较低。引入的传播思想是,进一步找到u3的相似邻居u1和u5,再同时把u3和u5的数据用到对u1的评分预测和推荐上,能够有效提高推荐效率[16]。
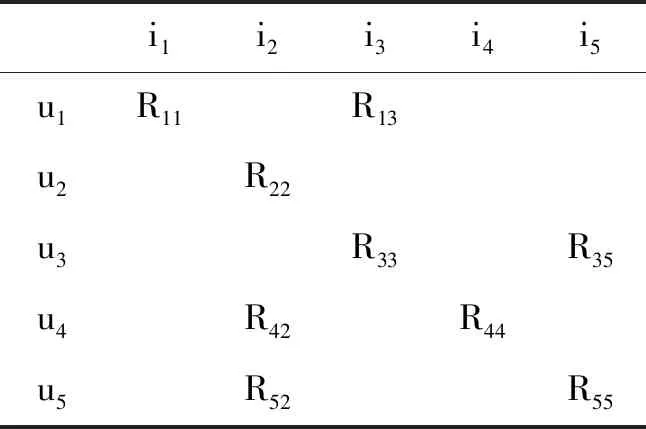
表1 用户-项目偏好稀疏矩阵
根据上述的相似度传播思想,文章在相似度计算上,分别给出了用户u和用户v的相似度计算以及项目i和项目j的相似度计算的公式。
Sims(u,v)(h+1)=
(1)
Sims(i,j)(h+1)=
(2)
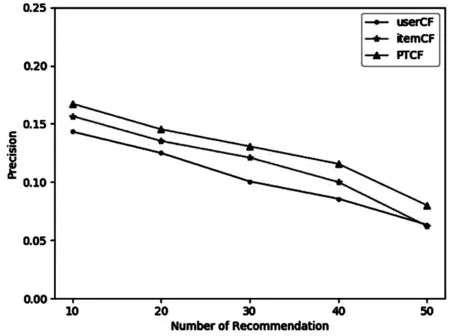
其中,C(0 对于推荐过程,稀疏推荐从基于用户和基于项目两方面进行考虑,以下为用户u对项目i的预测评分Pre_Rui的计算公式。 Pre_Rui(h)= (3) 丰富阶段即在一定的时间跨度下,读者的偏好信息数据较为丰富,能够支持推荐运算的用户-项目偏好矩阵规模庞大。一方面,大量的偏好信息有助于提高新书推荐的效率,但过量的读者及图书基数必然带来可扩展性问题。另一方面,当时间跨度较大时,用户的实际兴趣可能发生动态地变化,不同时间段的偏好数据对于预测读者兴趣的价值不一致,等同对待所有偏好数据在推荐中的作用会忽视了推荐的时效性。因此,充分考虑时间特征,有助于应对可扩展性问题,提高新书推荐的时效性[17]。 基于以上,丰富推荐引入了一个基于时间和基于项目相似度的综合权重TS(u,i),表示用户u对已访问项目i的的兴趣相关度[18]。 定义1 基于时间的数据权重。近期的用户数据更能反映用户的近期兴趣,而早期的用户数据对于推荐的价值相对较低。显然,应该重点突出近期用户数据在推荐中的作用。时间权重函数T(u,i),表示用户u对于项目i的近期相关程度。 (4) 其中,Lu表示为用户使用推荐系统的时间间距;Dui为用户u最早访问项目与访问项目i的时间间距;a∈(0,1)为权重增长系数,a越大则权重增长速度越快,通过改变参数a的值可以进一步优化算法性能,当a=0.5时,算法的推荐效果较优。 定义2 基于项目相似度的数据权重。如果仅仅考虑用户的近期数据,就会忽视掉早期的能够反映用户兴趣的数据的推荐价值。基于项目相似度的权重函数S(u,i),表示用户u和项目i的当前兴趣的关联程度。 (5) 其中,设Iu为用户u的已访问项目集合,T为时间窗,则IuT为在时间跨度T下用户u的已访问项目集合,其在一定程度上反映了用户的近期兴趣;size(IuT)为IuT中的物品数目;sim函数采用传统的相似度度量函数。时间窗T是该权重值的核心参数,通过调整T的时间跨度可以改变推荐算法的平均性能。 定义3 基于时间和基于项目相似度的时间综合权重。为了有效结合以上两种权重的各自优势,给出了一个时间综合权重函数TS(u,i),表示用户u对已访问项目i的兴趣相关度[19]。 TS(u,i)=β×WT(u,j)+(1-β)×WS(u,i) (6) 其中,系数β∈[0,1],通过改变β值的大小可以调整两种权重值的比重,从而实现优势互补,提高算法的性能。 下面将时间综合权重TS(u,i)引入到基于项目的协同过滤。 改进的算法步骤如下: 输入用户-项目时间矩阵、目标用户u。 输出 Top_N形式的推荐集Rankings。 Step1 计算每个项目的相似邻居得到相似邻居集S,即每个物品的最近邻居集合,存储其相似邻居及对应相似度,每个物品的相似邻居个数设定在20个。 Step2 设Iu为用户u的已评分物品集合,对i∈Iu,读取其在离线字典S中的最近邻居,汇总所有的最近邻居并删除Iu中已存在的项目,得到候选推荐集Rankings。 Step3 对j∈Rankings,计算用户u对物品j的预测评分值。 (7) Step4 采用Top_N形式推荐,按预测评分值降序排列,前N个作为指定推荐。 实验在 Windows 10环境下进行,以 Python实现。实验数据集为GoodBook,原始数据来源于BookCrossing官方网站上278 858个用户对271 379本书的评分记录,通过数据清洗及预处理最终得到了实验数据。 其处理步骤如下:首先,去除评分值为0的评分记录并随机生成评分时间;其次,筛选出500个评分记录在10条以上的用户,由他们的评分信息构成GoodBook,包含了500个用户对17 696本书共计27 300条图书评分记录,每条记录格式为(用户,图书,评分,访问时间);最后,采用五折交叉验证的方式,划分出了测试集和训练集,其中每个用户20%的评分数据作为测试集,剩余部分的数据作为训练集。 实验的评价指标采用准确率(Precision),即推荐结果中正确的个数与总推荐个数的比重,若由训练集数据计算所得的推荐结果能在测试集中找到,则视为产生了一条正确推荐。 (8) 其中,N为总的推荐个数;Right为正确的推荐个数。 实验目的为对比改进的PTCF算法与传统的基于用户(UserCF)和基于物品(ItemCF)的协同过滤之间的性能差异,从而验证PTCF在新书推荐中的推荐效率。 文章设计了两组实验,实验一是采取五折交叉验证的方式,考察不同算法的推荐效果;实验二是观察不同推荐个数时各算法的准确率情况。其中,实验指标precision的值为用户的平均值加权汇总。 实验参数设定如表2 所示。 表2 实验参数设定 参数解读:Ra及Rb:数据阶段的划分指标;n:返回推荐结果的个数;h:稀疏推荐方案中,寻找相似邻居的迭代次数;c:稀疏推荐方案中,表示相似度随迭代次数增加的传播衰减率;a:丰富推荐方案中,调整权重随访问时间变化的速度的权重增长指数;T:丰富推荐方案中,表示近期数据的时间跨度;β:丰富推荐方案中,调整两种权重的比例因子;sim:表示传统的相似度度量函数,sim_distance为欧几里得距离计算方法。 (1)实验一的具体情况如图1所示。 图1 GoodBook上5折交叉验证实验情况 从图1可以看出,三种算法的precision值集中于0.15~0.20之间,K不同取值情况下值波动较小;PTCF的值普遍接近于0.20,对比UserCF和ItemCF值更大;而ItemCF较userCF推荐精度更高,反映出对于新书推荐,当项目总数大于用户总数时,采取基于项目的协同过滤有着更高的推荐效率。 (2)实验二的具体情况如图2所示。 图2 GoodBook上不同推荐个数实验情况 从图2可以看出,三种算法的precision值集中于0.18到0.5之间,并且随着推荐个数的增加,各算法的preciosion值出现较大幅度地递减;PTCF整体递减速度平缓,且平均值大于UserCF和ItemCF,反映出相对较高的推荐效率;而ItemCF和UserCF的值距离较小,随着推荐个数的增加precision值逐渐接近。 实验表明,不同的数据情况下对协同过滤算法的性能影响很大,采取传统的协同过滤的效率有限,无法克服稀疏性和可扩展性问题,单一推荐算法在实际推荐过程中不能满足个性化推荐的复杂需求。PTCF的提出能够考虑到多样化的推荐需求,且算法的准确率(precision)情况良好,使推荐性能得到保障。故改进的PTCF算法完全适用于新书推荐这一具体应用场景,且推荐质量较优。 文章提出了一种改进的PTCF算法,将其应用于新书推荐的具体场景中,具有重要的理论与实践意义。今后,将对数据阶段的划分将采用更精确的方法,对初始阶段着手挖掘读者的基本信息提出更加个性化的推荐,对稀疏阶段可以尝试降低相似度计算的时空开销,对于丰富阶段需要考虑比例因子β的最优值情况。
3.3 丰富阶段
4 实验结果及分析
4.1 实验环境及数据集
4.2 评价标准
4.3 实验方案及参数设定

4.4 实验结果及分析

5 结语
