基于DB-CF算法的音乐平台个性化推荐研究
2020-05-28窦维萌郑秋爽孙宗锟
窦维萌 郑秋爽 孙宗锟


摘 要:娛乐方式日益丰富,产生巨量数据,利用这些数据通过推荐系统可以让用户获得更好的体验,为此提出了DB-CF(DBSCAN-Collaborative Filtering)算法。首先,使用DBSCAN聚类算法对音乐平台的线下用户进行聚类;然后,通过协同过滤算法计算对象用户与各聚类中心的相似度,再通过对比相似度度量矩阵,遍历离对象用户最近的邻居,通过邻居作出评分预测。实验表明,采用DB-CF算法比传统算法准确率提高8%左右,可以产生更准确的推荐结果,为用户带来更好的体验。
关键词:音乐电台;信息超载;个性化推荐;协同过滤;聚类
DOI:10. 11907/rjdk. 192582 开放科学(资源服务)标识码(OSID):
中图分类号:TP301 文献标识码:A 文章编号:1672-7800(2020)003-0057-03
Research on Personalized Recommendation of Music Platform
Based on DB-CF Algorithm
DOU Wei-meng1,ZHENG Qiu-shuang2,SUN Zong-kun1
(1. College of Computer Science and Engineering, Shandong University of Science and Technology;
2. College of Mining Safety and Engineering, Shandong University of Science and Technology, Qingdao 266590, China)
Abstract: With the increasing enrichment of entertainment methods and the influx of huge amounts of data, peoples lives are more convenient through the effective use of data. In terms of music platforms, excellent recommendation systems are used to provide better experience to platform users. In order to obtain more accurate recommendation results than the traditional recommendation techniques in a large number of tracks, a DBSCAN-collaborative filtering(DB-CF) algorithm is proposed. Firstly, when processing the offline data, we use the DBSCAN clustering algorithm to cluster the users of the music platform. Secondly, when processing the online data, we calculate the similarity between the user and each cluster center by a collaborative filtering algorithm. And then through the comparison of the similarity measurement matrix, we traverse the nearest neighbor of the object user,and make prediction of the object users score. Experiments show that under different recommendation algorithms, the DB-CF algorithm improves the accuracy by about 8% compared with the traditional algorithm, which proves the algorithm can produce more accurate recommendation results and bring better experience to users.
Key Words: music platform; information overload; personalized recommendation; collaborative filtering; clustering
0 引言
网络发展和娱乐方式多样化产生更多的信息,而巨量不相关的信息让用户选择过程变得繁琐。传统的社会化推荐系统在不明确需求的情况下不能提高用户的满意度[1]。
网络正全面深入到人们的日常生活中[22],推荐平台充满机遇更充满挑战,但因冷启动问题[2]以及行为数据快速更新等矛盾,平台尚无法满足客户的精确需求。个性化推荐技术能够解决信息超载 [3],通过上传用户一系列操作,为每一个用户创建独立模型,并推荐用户偏爱的内容,如各音乐平台的“推荐歌单”,就是利用此技术挖掘出客户喜欢的歌曲予以推荐,这种方式大大节约了用户的时间[4]。
赵亮等[24]针对协同过滤算法效能低的缺点进行了改进,提出一种高效的个性化推荐算法,以解决推荐系统稀疏问题,但是它存在测试集作为分析样本的方法优化问题;周军锋等[25]提出优化的协同过滤算法,采用修正的条件概率方法计算项目相似性,提高了计算结果的准确性,提高了推荐质量,但此方法增加了时间损耗;刘佳璐等[26]结合协同过滤和用户特征标签增加用户的黏度,在Hadoop平台上实现分布式的离线计算,克服推荐单一性,提高了推荐质量,但对噪声点没有进行对应的处理。本文提出DB-CF算法,在保证推荐效率的同时注重对噪声点的处理,提高了推荐质量。
1 相关理论
1.1 个性化推荐系统
个性化推荐系统能让平台用户在大规模数据中找到自己所需的信息。出色的音乐平台推荐系统能够提高用户的满意度,音乐平台能因此获得巨大的收益[13]。
个性化推荐系统依据用户收藏,通过相关操作推送给用户喜好的歌曲[14]。由于音乐平台规模日益扩大,音乐数量与类别快速增长,用户欲找到自己喜好的音乐要花费很长时间,这种现象大大降低了体验感[12]。
个性化推荐算法主要有:①基于用户的协同过滤[5]。计算对象用户和已有用户的相似度,挖掘相似用户感兴趣的物品,估测出对象用户对物品的评分,将高评分的音乐介绍给对象用户;②矩阵分解:矩阵分解推荐算法能够解决近邻模型不能解决的难题,例如矩阵稀疏问题,对运算的结果有很大影响,增加了不稳定性,导致结果差异很大[6];③混合推荐算法:混合以上推荐算法,融入深度学习或数据挖掘算法[7],混合算法推荐的音乐与对象用户相关性最高。
1.2 DB-CF算法
DBSCAN聚类算法是一类具有噪声的以密度为基准的空间聚类方法。DBSCAN将算法密度较高的区域划分为簇[8]。现今数据量越来越庞大,从大规模的数据之中挖掘出用户所需求的信息、清除掉无关的数据是聚類的一个重大应用[15]。当今推荐系统中,聚类算法处理大规模数据非常有价值[16-17]。DBSCAN算法优点如下:①能够有效处理噪声点,挖掘出任意形状的聚类,聚类速度很快[18];②和K-MEANS算法相比,DBSCAN对划分的聚类个数不需要预先输入[9];③能够在实验必要时输入过滤噪声参数。
协同过滤(Collaborative Filtering)算法计算对象用户和已有用户的相似性,挖掘出相似用户感兴趣的物品,预测出对象用户对物品的评分,将高评分的音乐推荐给对象用户,主要通过余弦相似度计算用户行为的相似度[10]。
1.2.1 用户相似度中的距离度量
余弦计算相似度,用来衡量平台用户之间的差异程度,用户之间的相似度和相似度度量值相关。余弦相似度数值越小,用户之间的差异越大,余弦相似度的数值越大则表明用户之间越相似[23]。
余弦相似数学公式如下:
式(1)中,通过用S(u,v)表示对象用户u与用户v的相似度,用Aui表示对象用户u对音乐i的评分值,通过Avi表示用户v对音乐i的评分,用Iuv表示对象用户u和v共同评过分的音乐集合[21]。
1.2.2 DB-CF算法设计
首先对线下数据进行处理,使用DBSCAN聚类算法对音乐平台的用户进行聚类,生成线下用户的聚类中心点;将每一位平台用户与各个聚类的中心点进行相似度计算,得出各个用户与各个聚类中心点的相似度度量矩阵。在处理线上数据时,通过协同过滤算法计算对象用户与各个聚类中心的相似度,再通过对比相似度度量矩阵,遍历离对象用户最近的邻居,通过离对象用户最近的邻居得到对象用户评分的预测,由此产生更准确的推荐效果。
算法描述:
算法: DB-CF
输入: db(数据集),eps(给定半径),MinPts(指定点在半径邻域内可以成为核心对象的最小邻域点数)。
输出: 目标类簇集合
方法步骤:①Repeat;②判断输入点是否为核心对象;③ 若该点是核心点,找到全部从该点出发的直接密度可达点,形成簇;④若该点不是核心点,跳出循环,查看下一个点;⑤Until 所有输入点都判断完毕。
在对线下数据进行处理的基础之上,先运算出对象用户与各个聚类中心点的相似度,得到对象用户所属各个聚类程度的向量,再通过搜索类所属的程度矩阵,得到离对象用户最近的邻居。
输入:类所属程度矩阵U (p,q),对象用户评分向量。
输出:离对象用户最近的K个邻居。
方法:
a= 0.0
b = 0.0
c = 0.0
for p in user.items():
for q in user.items():
a += float(q[0]) * float(q[0])
b += float(q[1]) * float(q[1])
c += float(q[0]) * float(q[1])
if(c == 0.0):
return 0
return c / sqrt(a * b)
//运算出对象用户与m个聚类的中心相似度,获得1*k的向量(q1,q2,…,qm)。
计算向量(q1,q2,…,qm)与类别所属程度矩阵U (p,q)各行之间的余弦值;
离对象用户最近的K个邻居就是以上余弦值最小的前K个基本用户。
利用DB-CF算法获得离对象用户最近的邻居,根據公式(1)得到推荐数据。
2 实验结果与分析
2.1 实验环境
本实验操作系统为Windows10,系统类型为64位操作系统,处理器为I7 7700HQ 2.80GHz,安装内存(RAM)为8GB,集成开发环境为PyCharm、Python 3.6 (64-bit)。
2.2 数据集介绍
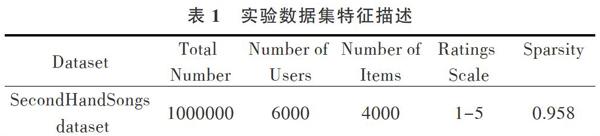
采用的数据集来自http://millionsongdataset.com/上的SecondHandSongs dataset?,经过处理后包含6000名用户对4000首曲目的100万条评分数据,如表1所示。
2.3 实验方法
统计精度度量方法和决策支持精度度量方法是客观衡量音乐平台推荐系统质量的主要方法。本文将统计精度度量方法中的平均绝对误差(MAE)作为评价指标衡量推荐精确度,使用MAE能直接地显现推荐质量的优劣,是最为常用的一种推荐质量的度量方法[11]。
式(2)中,MAE越小说明推荐算法的精确度越好,推荐质量越高。[x(i)]表示预测值,[y(i)]表示真实值。
2.4 结果分析
对以上数据集分别用DB-CF算法、CF(Collaborative Filtering)算法、CB(Content Based)算法进行实验,求取F-measure。为了避免实验结果的偶然性,分别进行20次实验,求出结果的平均值作为实验的最终结果[20]。
如图1所示,选数据稀疏度为0.958时进行DB-CF、CF和CB算法推荐效果比较[19],根据平均绝对误差(MAE)值越小结果越精准的标准,DB-CF的推荐效果比CF以及CB推荐算法的精确度高。
图2为DB-CF、CF和CB算法的推荐效率比较,可以看出DB-CF算法的效率要比传统的CF算法和CB算法效率高。DB-CF推荐算法先对线下数据进行聚类,在线上推荐时可以通过聚类完成的结果更快捷地进行推荐。
3 结语
音乐曲目浩如烟海,音乐曲目推荐对用户来说具有重大意义。本文介绍了基于DB-CF算法的音乐平台个性化推荐系统。与传统推荐算法相比较,本方案能够更快更准确地推荐给用户感兴趣的曲目。未来研究内容是如何强化学习解决高维数据问题,更进一步优化推荐结果。
参考文献:
[1]刘进,胡大权, 陈家佳. 面向海量数据的推荐系统研究[J]. 现代电子技术, 2016, 39(12):59-61.
[2]刘畅,王玉龙. 推荐系统冷启动问题分析[J]. 电信网技术,2017(1):65-68.
[3]王国霞, 刘贺平. 个性化推荐系统综述[J]. 计算机工程与应用, 2012, 48(7):66-76.
[4]侯烨炜. 个性化新闻推荐算法比较研究[J]. 科技视界,2014(32):362-366.
[5]TSAI C F,HUNG C. Cluster ensembles in collaborative filtering recommendation[J]. Applied Soft Computing,2012,12(4):1417-1425.
[6]GAI L I, LEI L I, POLYTECHNIC S, et al. Collaborative filtering algorithm based on matrix decomposition[J]. Computer Engineering & Applications, 2011(9):2001-2012.
[7]黄立威,江碧涛,吕守业,等. 基于深度学习的推荐系统研究综述[J]. 计算机学报,2018,427(7):1619-1647.
[8]王红. 面向数据发布的差分隐私保护研究[D].北京:中国人民大学,2012.
[9]冯超. K-means聚类算法的研究[D]. 大连:大连理工大学, 2007.
[10]尹晓丽,李济洪,LI Y X,等. 一种访问者行为的相似度度量方法[J]. 太原科技大学学报,2007,28(5):371-373.
[11]TERMSTRC. Average absolute mean error[EB/OL]. https://en.so.com/s?q=average+absolute+mean+erro
[12]JONES S L,KELLY R. Dealing with information overload in multifaceted personal informatics systems[J]. Human-Computer Interaction, 2017(1): 73-130.
[13]粱伟萍. 浅谈电子商务中的个性化推荐系统[J]. 网络与信息, 2011, 25(8):38-39.
[14]刘辉,郭梦梦,潘伟强. 个性化推荐系统综述[J]. 常州大学学报(自然科学版),2017, 29(3):51-59.
[15]宋杰, 孙宗哲, 毛克明,等. MapReduce大数据处理平台与算法研究进展[J]. 软件学报, 2017, 28(3):514-543.
[16]孙吉贵,刘杰,赵连宇. 聚类算法研究[J]. 软件学报,2008,19(1):48-61.
[17]杨启仁. 数据挖掘中聚类算法的研究[J]. 牡丹江大学学报, 2010(6):107-109.
[18]张毅, 刘旭敏, 关永. 基于密度的离群噪声点检测[J]. 计算机应用, 2010, 30(3):802-805.
[19]吴颜, 沈洁, 顾天竺,等. 协同过滤推荐系统中数据稀疏问题的解决[J]. 计算机应用研究, 2007, 24(6):94-97.
[20]刘明昌. 基于内容的推荐技术研究[J]. 现代营销(下旬刊), 2016(6):243-245.
[21]焦东俊. 基于用户人口统计与专家信任的协同过滤算法[J]. 计算机工程与科学, 2015, 37(1):158-164.
[22]阿布力孜·布力布力, 邓楠, 薛冠华. 电子商务在小微企业发展中的作用研究——以新疆少数民族小微企业为例[J]. 民族论坛, 2018, 395(1):47-50,67.
[23]李慧敏. 基于社交网络的垃圾用户检测方法分析与实现[D].北京:北京交通大学, 2017.
[24]赵亮, 胡乃静, 张守志. 个性化推荐算法设计[J]. 计算机研究与发展, 2002(8):91-97.
[25]周军锋, 汤显, 郭景峰. 一种优化的协同过滤推荐算法[J]. 计算机研究与发展, 2004, 41(10):1842-1847.
[26]刘佳璐, 周传生. 基于Hadoop分布式个性化推荐算法的设計与实现[J]. 科学技术创新, 2017(1):170-171.
(责任编辑:杜能钢)
收稿日期:2019-11-11
作者简介:窦维萌(1993-),男,山东科技大学计算机科学与工程学院硕士研究生,研究方向为云计算与大数据处理;郑秋爽(1995-),女,山东科技大学矿业安全与工程学院硕士研究生,研究方向为矿井突水防治安全;孙宗锟(1995-),男,山东科技大学计算机科学与工程学院硕士研究生,研究方向为数据安全。本文通讯作者:郑秋爽。
