基于RBM的语音特征提取方法研究
2020-05-25赵从健雷菊阳李明明
赵从健 雷菊阳 李明明

摘 要:针对传统语音识别在多目标情况下识别率较低的问题,从特征参数提取角度,提出一种基于受限玻尔茨曼机(RBM)的特征提取方法。依据不同个体语音信号之间的特征差异提取特征参数,通过梯度上升算法调整网络参数以拟合给定训练样本,通过对比散度算法降低采样达标所需状态转移次数以提高算法效率,再利用重构误差曲线评价受限玻尔茨曼机对训练样本的似然度。实验表明,当隐含层节点个数为30时,参数提取的重构误差低于20%。此时使用改进的BP网络训练,与传统算法相比,综合识别率提高到86.9%,对提升多目标语音识别率具有重要意义。
关键词:语音识别;受限玻尔茨曼机;特征提取;梯度上升;对比散度
DOI:10. 11907/rjdk. 191462 开放科学(资源服务)标识码(OSID):
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2020)002-0114-04
英标:Research on Speech Feature Extraction Method Based on Restricted Boltzmann Machine
英作:ZHAO Cong-jian,LEI Ju-yang,LI Ming-ming
英单:(College of Mechanical and Automotive Engineering,Shanghai University of Engineering Science,Shanghai 201620,China)
Abstract: In order to solve the problem that the rate of traditional speech recognition was low in the case of multiple targets, from the point view of feature parameter extraction, a feature extraction method based on restricted Boltzmann machine was proposed. It extracted the characteristic parameters mainly based on the characteristic differences between different individual speech signals, adjusted the parameters of the network by the gradient rise algorithm to fit the given training sample, reduced the number of state transitions required for sampling to reach the standard by the contrast divergence algorithm to improve the efficiency of the algorithm, used the reconstruction error curve to evaluate the likelihood of the restricted Boltzmann machine to the training samples. Experiments showed that when the number of hidden layer nodes is 30, the reconstruction error is less than 20%. Compared with traditional algorithm, the comprehensive recognition rate obtained form the improved BP network training was raised to 86.9%, which was of great significance for improving the speech recognition rate of multiple targets.
Key Words: speech recognition; restricted Boltzmann machine; feature extraction; gradient rising; contrast divergence
0 引言
随着大数据、人工智能、物联网等领域的快速发展,个人信息安全问题随之而来,个人身份认证成为热门研究领域。和传统的身份识别方法相比,声纹识别拥有不易丢失、遗忘和被盗的特性[1-2]。目前,声纹识别技术已经应用于国家安全、金融认证、个性化语音交互等众多领域,随着技术的商业化运用,解决标准和技术等方面的问题迫在眉睫[3]。
语音特征参数的选取直接影响识别效果,当前最常用的特征参数提取方法是梅尔倒谱系数(MFCC)和线性预测倒谱系数(LPCC)[4-5]。為解决复杂环境下的识别差异问题,研究者从提高特征鲁棒性[6-9]、加入语音情感识别[10-11]等方面作了尝试和改进,但依然未达到商业应用的程度。
近年来,随着深度置信网络(DBN)的发展,人们开始重视深度学习在语音识别领域的应用[12-13],国内外对受限玻尔兹曼机(RBM)作了大量研究[14-17]。文献[18]结合高斯受限玻尔茨曼机和概率线性判别分析(PLDA),解决了说话人因子和通道因子难以分解的问题;文献[19]将总体差异模型(TVM)中的差异矢量替换为受限玻尔茨曼机,结合i-vector模型构建可视层和隐含层服从高斯分布的超向量提取器。
上述提取方法关注的是个体语音信号的共性,忽略了不同个体语音信号的差异性。鉴于RBM具有很强的自适应性和无监督学习能力[20-21],可以学习和发现多识别目标之间的个体差异分布,本文提出一种基于RBM的语音特征提取方法。该方法通过梯度上升算法拟合训练样本、对比散度算法提高效率,一方面提高了特征参数的鲁棒性,另一方面也可有效利用标签缺失的数据,在保持识别精度的基础上加快网络训练效率。
1 模型简介
利用受限波尔茨曼机提取语音信号的特征参数,重构误差评价受限玻尔茨曼机对训练样本的似然度。根据所提取的特征参数构建语音识别神经网络,训练集调整网络参数,识别多目标语音信号集。
1.1 受限玻尔茨曼机
受限玻尔茨曼机是深度概率模型中常用的一种研究方法,其本质上是一种基于能量模型的二分无向图模型,如图1所示。
该模型主要由n个隐藏节点组成的隐藏层(Hidden Layer,简记为h)和m个可视节点的可视层(Visible Layer,简记为v)组成。不同层的节点互相关联,但没有方向,同层的节点之间互相独立。可视层一般表示数据的一个特征或类型,隐藏层的表征含义不明确,但隐含了可视层和输入变量之间的关系,因此也称为特征提取层。
RBM是基于能量的模型,其联合概率密度函数为:
其中,v表示可视层的状态向量,h表示隐藏层的状态向量,b表示可视层的偏置向量,c表示隐藏层的偏置向量,W表示可视层和隐藏层之间的权值矩阵。
1.2 语音识别
语音识别属于模式识别的一种,主要提取语音信号里的重要特征信息,并与语音库里的样本信号模型库进行对比分析,从而判断说话人的身份。
图2为语音识别系统流程。语音信号预处理有以下几种方法:预加重、分帧、加窗、端点检测等。经过预处理的语音信号再提取特征用于后期训练和识别。
不同个体语音信号的特征向量包含不同的特征参数,不同特征参数的选择直接影响模型的识别率。选择合适的、可以表征说话人身份的特征参数,可以降低与语音识别无关的输入(通常是噪音)影响,减少后续识别、匹配和判决阶段的数据计算量,最终提高语音识别准确率。
2 模型建立与实现
在预处理好语音数据前提下, RBM网络的训练目标就是通过调整参数值去拟合该样本数据,使得调整后的RBM模型反映的概率分布与样本数据尽可能一致。
假定训练数据集:S={s1,s2,s3,…,sns};
其中ns表示训练的样本数,每个样本包括多维数据(记为j维数据),可表示为:si={x1i,x2i,x3i,…,xji},i=1,2,…,ns;
上述的训练数据是独立分布的, RBM的目标就是最大化其似然函数。为计算方便,对函数两边取对数后得:
2.1 梯度上升算法
利用梯度上升方法,通过迭代逼近最大值,迭代公式为:
其中,η>0为学习率,θ指各参数变量。
對于梯度?lnLS/?θ的计算,实际上是lnLS对各个参数的偏导数计算。
由式(4)可得多训练样本如下:
利用梯度上升算法计算和化简后,对于多个训练样本(即S={s1,s2,s3,…,sns})情形有如下公式:
其中,ζ表示特定的单个训练样本,P(h|ζ)表示可见单元为特定训练样本y时对应的隐藏层概率分布。
2.2 对比散度算法
上述计算复杂度较高,为O(2nv+nh),与可视层和隐藏层神经元个数呈正相关。
对于大数据集来说,难以保证采样后小样本可以保留原数据的目标分布。每次进行MCMC采样时,为了使原目标分布以精确状态转移到小样本数据中,需要大量采集样本,加大了RBM的训练复杂度。
采用k步对比散度算法,步骤为:①对?si∈S(i=1,2,…,ns),取初始值s(0)=s,然后进行k次Gibbs采样。依次循环执行步骤②、步骤③、步骤④k次;②第t次循环,利用P(h|s(t-1))采样h(t-1);③第t次循环,利用P(s|h(t-1))采样s(t);④每次采样得到的值实际上是一次梯度上升迭代过程中偏导数的近似值,简记为Δwi,j、Δaj、Δbi。利用式(4)、式(7)、式(8)、式(9),结合采样得到的数据分别更新参数Δwi,j、Δaj、Δbi。
其中,3个参数更新公式为:
2.3 初始参数值选取
为保证RBM训练的高效与准确,要有严格的参数选取要求。
(1)样本预处理。将原样本分割成多个小样本数据,每个样本所含数据集数目大致相等,且互相没有交集。这样做可以利用并行处理数据的一些方法(如GPU),提高算法的运行处理效率。
(2)确定学习率η。神经网络训练过程中需要适当增大学习率,加快算法的收敛速度,但静态设置过大的学习率会使结果变得不稳定。现引入学习率动量项ρ,利用类似式(5)的参数更新式:
动态学习率更新方式和训练中的特征参数保持一致,可以降低代码复杂度,也可避免算法过早陷入局部最优。
(3)初始化参数矩阵W、a、b。权值矩阵W的参数来自正态分布N(0,0.01)的随机数,隐藏层偏置矩阵b初始化为零,而可见层偏执矩阵a采用如下公式计算:
其中,Pi表示训练集的第i个特征处于激活状态的样本占所有样本的比例。
2.4 特征参数提取
结合上述对比散度和梯度上升算法,可保证RBM训练的正常进行,详细步骤如下:
(1)RBM网络的初始化。①指定训练样本S;②确定训练网络的周期J,学习率η,对比散度的采样参数k;③选取可见和隐藏层对应单元数目nv和nh;④初始化偏置向量a、b和权值矩阵W。
(2)RBM网络训练。①重复学习训练J次;②利用CD-K,生成Δwi,j、Δaj、Δbi;③利用式(10)、式(11)、式(12)更新特征参数表。
3 实验结果
3.1 实验设计
利用倒谱系数法所提取4个不同类型的语音特征信号,分析采用RBM提取特征参数后对语音识别模型性能的影响,如图3所示。从2 000组24维的数据集中随机选择1 500组作为训练数据,其余500组作为检测数据验证模型的识别率。
为验证多目标情况下各算法性能,分别利用PCA、MFCC、RBM特征提取后的参数,利用同样的语音识别方法(这里采用改进后的BP神经网络)对最终结果进行对比并分析。
3.2 实验分析
重构误差曲线反映了RBM对训练样本的似然度,分别在网络隐藏层节点数nh=10、20、30、40、50时绘制训练集的重构误差曲线如图4所示。
由图4可以看出,适当增加节点数可以降低重构误差。当隐藏层节点数设置为30时效果较好,此时再增加隐藏层节点数反而会增大重构误差。
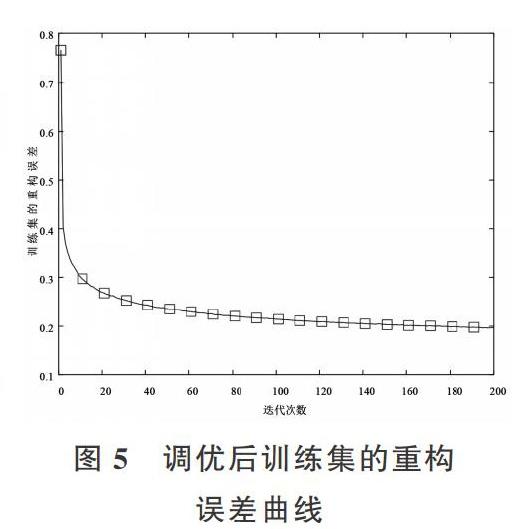
RBM预训练完成后,利用共轭梯度算法对网络调优训练,对比调优后重构信号与原信号,训练集的重构误差变化如图5所示。
由图5可知,重构误差随著迭代次数增加而减少,200次迭代后重构误差变化不大。
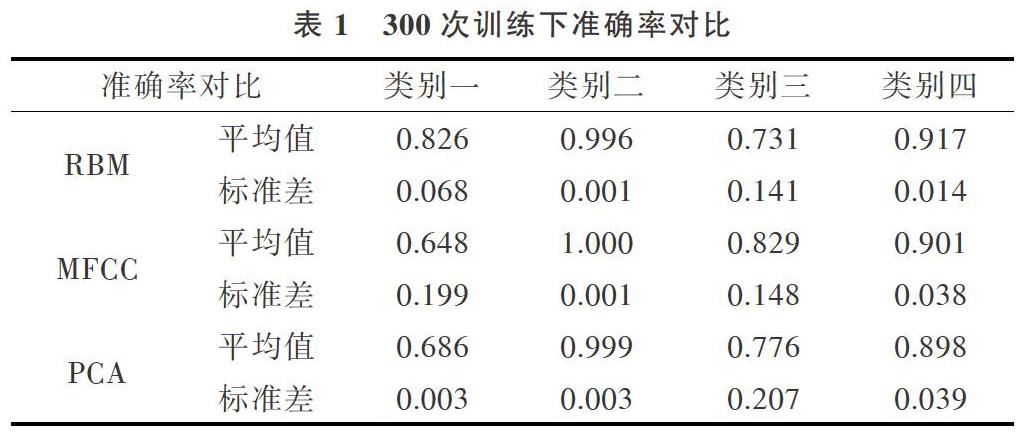
利用RBM提取特征参数后,采用改进型BP神经网络搭建语音识别网络,对随机待测语音信号进行识别,记录300次训练结果数据如表1所示。
由表1可知,类别2和4,用3种方法识别率差异不大,但RBM结果更稳定。类别1和3,RBM的识别准确率高且更为稳定。选取其中的前8次训练结果绘制成图6。
由图6可以看出,对于单个类型的语音信号,采用RBM方法的准确率更高也更稳定。
作为测试集的500组数据属于未知的随机数据,4类信号的数量占比不一致。多目标语音识别对于整体识别率有很高要求,记录测试集在3种方法下的总识别率如表2所示。
从表2可以看出,对于多目标语音识别,RBM依然有着良好表现,结果优于其它两种方法。
4 结语
相较于传统的语音特征提取算法,RBM拥有很强的数据特征适应性,可以准确表征出不同数据的本征特征,这在多目标数据训练中的优势尤其明显,具体表现为算法更稳定及多目标的综合误差更低。此外,RBM的训练采用无监督学习,可使用大量存在缺失标签的数据,增强了算法对数据类型的适应性。
本文也存在一些不足之处:由于语音信号的种类和数量有限,需要收集和处理现实环境下的语音信号,并将其数据化标签化。在今后的研究中,还要考虑噪声、方言、不同语义等环境因素,因此还需进一步改进特征提取方法。
参考文献:
[1] 郑方,李蓝天, 张慧, 等. 声纹识别技术及其应用现状[J]. 信息安全研究,2016,2(1): 44-57.
[2] 裴鑫. 声纹识别系统关键技术研究[D]. 哈尔滨: 哈尔滨理工大学,2014.
[3] 郑方,程星亮. 声纹识别:走出实验室,迈向产业化[J]. 中国信息安全,2019(2): 86-89.
[4] HU Z,ZENG Y,ZONG Y, et al. Improvement of MFCC parameters extraction in speaker recognition[J]. Computer Engineering & Applications, 2014, 50(7): 217-220.
[5] BARUA P, AHMAD K, KHAN A, et al. Neural network based recognition of speech using MFCC features[C]. 2014 International Conference on Informatics, Electronics & Vision (ICIEV). IEEE, 2014.
[6] 黄羿博, 张秋余, 袁占亭,等. 融合MFCC和LPCC的语音感知哈希算法[J]. 华中科技大学学报:自然科学版,2015, 43(2): 124-128.
[7] 徐照松, 元建. 基于BP神经网络的语音情感识别研究[J]. 软件导刊, 2014, 13(4): 11-13.
[8] 高家宝. 支持向量机在语音识别中的应用[J]. 软件导刊, 2015, 14(1): 39-40.
[9] 于娴, 贺松, 彭亚雄,等. 基于GMM模型的声纹识别模式匹配研究[J]. 通信技术, 2015, 48(1): 97-101.
[10] MILTON A, ROY S, SELVI S. SVM scheme for speech emotion recognition using MFCC feature[J]. International Journal of Computer Applications, 2014, 69(9): 34-39.
[11] 徐照松, 元建. 基于BP神经网络的语音情感识别研究[J]. 软件导刊, 2014, 13(4): 11-13.
[12] 侯一民, 周慧琼, 王政一. 深度学习在语音识别中的研究进展综述[J]. 计算机应用研究, 2017, 34(8): 2241-2246.
[13] 李晓坤, 郑永亮, 袁娘, 等. 基于深度学习的声纹识别方法研究[J]. 黑龙江大学工程学报, 2018, 9(1):64-70.
[14] 张春霞,姬楠楠,王冠伟. 受限波尔兹曼机[J]. 工程数学学报, 2015(2): 159-173.
[15] TRAN T,PHUNG D,VENKATESH S. Mixed-variate restricted boltzmann machines[J]. Computer Science,2014, 5(6): 213-229.
[16] BERGLUND M,RAIKO T,CHO K. Measuring the usefulness of hidden units in Boltzmann machines with mutual information[M]. Berlin: Springer,2013.
[17] MA X,WANG X. Average contrastive divergence for training restricted boltzmann machines[J]. Entropy, 2016,18(2):35-39.
[18] TAFYLAKIS T, KENNY P, SENOUSSAOUI M, et al. PLDA using gaussian restricted boltzmann machines with application to speaker verification[C]. Proceedings of the 13th Annual Conference of the International Speech Communication Association,2012.
[19] 酆勇,熊庆宇,石为人,等. 一种基于受限玻尔兹曼机的说话人特征提取算法[J]. 仪器仪表学报, 2016, 37(2): 256-262.
[20] 杨杰,孙亚东,张良俊,等. 基于弱监督学习的去噪受限玻尔兹曼机特征提取算法[J]. 电子学报, 2014, 42(12): 2365-2370.
[21] 张立民,刘凯. 基于深度玻尔兹曼机的文本特征提取研究[J]. 微电子学与计算机, 2015, 32(2): 142-147.
(责任编辑:杜能钢)
