基于文本加权词共现的跨语言文本相似度分析
2020-05-25张晓宇王永滨吴林
张晓宇 王永滨 吴林


摘 要:跨语言文本相似度计算在跨语言信息检索、数据挖掘、抄袭检测等领域有着重要应用,但是跨语言文本相似度计算因为不同语言文法、结构等问题,在空间映射、特征选择上与单语言文本相似度计算有很大差异。为解决上述问题,采用一种基于文本加权词共现关系的跨语言文本相似度计算方法,通过平行语料库构建跨语言词共现关系模型,使用该模型进行跨语言文本映射,对不同语言的文本进行相似度计算。该模型实际反映了某种语言中某些关键词共同出现时映射成另一种语言时的关键词概率分布。实验表明,该方法对跨语言文本排序的计算更接近人工评判标准。
关键词:词共现;文本相似度;跨语言;统计翻译模型
DOI:10. 11907/rjdk. 191233 开放科学(资源服务)标识码(OSID):
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2020)002-0092-04
英标:Cross-linguistic Text Similarity Analysis Based on Co-occurrence of Text Weighted Words
英作:ZHANG Xiao-yu,WANG Yong-bin,WU Lin
英单:(Key Laboratory of Convergent Media and Intelligent Technology, Communication University of China, Beijing 100024, China)
Abstract:Cross-language text similarity computation has important applications in cross-language information retrieval, data mining, plagiarism detection and other fields. However, cross-linguistic text similarity calculation differs greatly from single-language text similarity calculation in spatial mapping and feature selection due to the different grammar and structure of the languages. In order to solve the above problem, a cross-linguistic text similarity calculation method based on the co-occurrence relationship of text weighted words is adopted. This method constructs a cross-linguistic word co-occurrence relationship model by parallel corpus, and uses this model to map cross-linguistic texts, and calculates the similarity of texts in different languages. The model actually reflects the probability distribution of keywords in one language when some keywords appear together and map to another language. Experimental results show that the calculation of the cross language text sorting method is closer to the artificial evaluation standard.
Key Words:word co-occurrence; text similarity; cross-linguistic; statistical translation model
0 引言
隨着网络技术的发展,信息存储快速增长,如何从海量的互联网信息中获取需要的信息越来越困难,给信息处理技术带来新的挑战。文本相似度计算在各种信息处理应用中有着重要作用,例如搜索引擎、文本分类、文本聚类、信息检索等[1-3]。基于同一种语言的文本相似度算法主要分为基于字符串的方法[4-5]、基于语料库的方法[6-7]、基于世界知识的方法[8-9]和其它方法[10-11]。基于同语言的文本相似度研究趋于成熟,代表算法有向量空间模型[12]、基于文档结构方法[13]、基于本体知识[14]等。但是,相对于同语言的文本相似度研究,跨语言的文本相似度研究很少。跨语言文档相似度排序难点在于:首先,在跨语言信息检索过程中,不同语言的文档不属于同一特征空间,不能直接对不同空间的文档进行表示及进一步排序;其次,影响排序质量的因素十分复杂,即使同一算法对不同语言的文档也不能复制使用,尤其是针对现今带有众多复杂特征的互联网文档,不能很好地直接以符合用户需要的方式对文档进行排序。
目前,跨语言文本相似度主要有以下几种方法:
(1)基于全文机器翻译方法[15-16]。该方法使用机器翻译工具,将待检索的源语言翻译成目标语言,再使用单语言的文本相似度算法进行相似度计算。或者将源语言和目标语言都翻译成同一种中间语言,再进行文本相似度计算。无论是否借助中间语言计算,基于机器翻译的方法都极其依赖机器翻译的质量,并且很难应用到多种语言。
(2)基于统计翻译模型方法[17-18]。该方法需要在两种语言之间生成翻译概念词典,建立翻译概念词典需要大规模对齐语料。本文使用的方法是基于统计翻译模型的文本加权词共现的跨语言文本相似度算法。
(3)CL-ESA算法(Cross-Language Explicit Semantic Analysis)。是基于平行语料库的跨语言相似度算法,是ESA算法的扩展[19-20]。该类算法以两种语言的平行语料库为基础计算相似度,其算法准确度主要依赖语料库的规模和质量。要获得较高的准确度需要大规模高质量的平行语料,而大规模的索引语料会增加算法的计算量。因此, CL-ESA算法的准确性和效率很难兼顾。
本文提出的方法属于基于统计翻译模型方法,不同的是,本文对翻译概念词典的建立基于语义思想,即认为同一关键字在不同的语义中有不同含义,结合上下文语义才能得到该关键词的最佳翻译结果。
1 文本相似度计算过程
1.1 算法总体流程
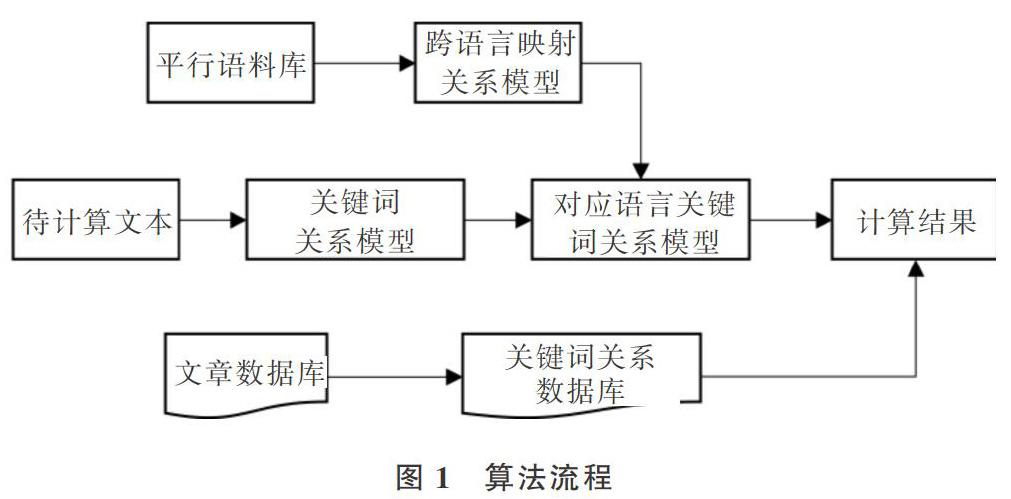
本文根据平行语料库计算好关键词的共现映射模型,并对待检测文章和新加入的文章提取关键词关联关系存入数据库,这样可提高计算效率。算法应用过程分为映射阶段和匹配阶段,对目标文本进行关键词映射,再通过跨语言的映射模型映射其它语言的关系矩阵,基于该矩阵对待匹配文本进行计算匹配,流程如图1所示。
1.2 跨语言映射关系模型构建
本文基于语义思想构建跨语言映射关系,并且认为语义的确定基于语境。语境这一概念是英国民俗学家马林诺斯基首先提出的,他认为语境对于理解语言必不可少。同一个词在不同语境中可能代表不同的意思,例如英语中的hang就有“吊死、悬挂”的意思。因此,本文使用句子作为确定语境的最小单位,并使用一个句子中实词的加权共现关系作为跨语言关键词映射关系模型构建的依据。因此,对于语料库选择,必须选择句子对齐的平行语料,具体方法如下:
(1)统计[L1]中词[w1]出现过的所有句子,组成集合[S1]。[S1=s1,s2,s3,?,sn,其中si]是含有[w1]的一个句子。
(2)统计[S1]中每个词出现的频率[fi],过滤掉频率太低的词,对筛选得到的词进行排序,得到新的集合:[F1=w1,f1,w2,f2,w3,f3,?,wn,fn]。其中:
(3)找到[L2]中所有与[S1]对应的句子,组成集合[S1'],[S1'=s1',s2',s3',?,sn']。
(4)对[S1']作与第(2)步相同的处理,得到[F1'。F1'=][w1',f1',w2',f2',w3',f3',?,wn',fn']。
(5)将第(2)步和第(4)步结果生成的[F1,F1']映射关系保存。
(6)对[L1]中的所有词进行第(1)~第(5)步操作,生成[L1]对[L2]的映射模型。
其中[L1]、[L2]代表不同的两种语言,[S1]、[S1']分别代表[L1]、[L2]中不同语言对齐的句子。如上述过程对平行语料库处理完成后,得到[L1]对[L2]的跨语言映射关系模型。如需要[L2]对[L1]的映射关系模型,则对[L2]进行相同处理。该模型实际反映了某种语言中某些关键词共同出现时映射成另一种语言的关键词概率分布,能有效解决双关键词共现算法中某一句子同时出现“A B C”时,选用“AB”、“AC”还是“BC”作为共现词对进行映射的问题。跨语言文本相似度计算基于本文所提出的跨语言映射关系模型实现。
1.3 文本相似度计算
本文使用的相似度计算基于前述构建的跨语言映射关系模型。不同于传统的文本相似度计算方法,使用本文算法进行计算之前,要对待检索的文档数据库进行预处理,将每篇文档用关键词分布频率表示出来,形成检索匹配向量,具体方法如下:
(1)对待检索的[L1]语言[T1]进行句子拆分,把[T1]拆分成句子集合表示的形式,即[T1=s1,s2,s3,?,sn]。
(2)去停用词后对[T]中的每个词按句子统计共现词内容和频率。
得[F=w1,w2,fw1,w2,?,wm,wn,fwm,wn]。
(3)设定频率阈值[θ],过滤掉[fwx,wy]<[θ]的共现词对,计作向量[N],其中[N]的长度为n。
(4)对第(3)步中的每个共现词对,根据跨语言关系映射模型映射成对应语言[L2]的向量,并截取排名前n的结果,将所有向量组合成矩阵[M]。
(5)计算矩阵乘积结果[N?MT],其中[MT]是[M]的转置矩阵。
(6)将乘积结果相同的关键词频率合并,统计所有[关键词,频率],计作[r,f]并按照频率从大到小排序,得到[T]的对应[L2]语言共现词分布概率向量[R]。
(7)计算数据库中每篇文章的共现词分布概率[R'],计算[R]与每篇文章[R']的欧式距离[d],对结果从大到小排序即为相似度计算结果。其中:
上述计算过程的中心思想是根据关键词共现映射模型,将[L1]语言的文本[T]映射成[L2]语言的共现词分布概率,再通过计算[L2]的每篇文本共现词分布概率的相似程度,完成文檔间相似度计算。其中[L2]语言的待检索文本库可以进行共现词分布计算,将所有文档用共现词分布概率表示并存入另一个共现词数据库。当进行检索时,可以直接从该数据库中获得数据,从而提升计算效率。对于新入库的文本,也可直接对齐进行共现词概率表示,同时存入两个数据库。
2 实验
2.1 平行语料库构建
平行语料库是构建跨语言关键词映射模型的基础。根据本文的模型构建方法,要求平行语料库是以句子为对齐单位的双语语料库。本文实验采用中文和英文两种语言,对齐语料来源于大量的电影字幕文件。由于电影字幕文件有精确的时间轴和准确的双语语义信息,所以用其构建句子级对齐的平行语料库事半功倍。
实验使用爬虫工具从字幕网站下载字幕文件,筛选文件格式为.srt的文件下载到本地,在本地对.srt文件进行解析,根据其时间戳进行双语对齐,.srt文件格式如图2所示。
将得到的中英文句子存入数据库用作对齐语料库,最终得到语料库规模为120 994条对齐语料。
根据跨语言关键词共现关系模型构建方法,对平行语料库中的数据进行处理,构建出词共现关系模型,存入另一个数据表中。该表保存了词之间的共现关系及映射关系,用来对检索文章进行映射。
2.2 跨语言文本相似度计算
本文所使用的文本相似度计算测试数据与实验设备由智能融媒体教育部重点实验室(中国传媒大学)提供。其中,中文新闻文档1 000篇,英文新闻文档1 000篇。测评方法采用先进行机器计算,再对结果打乱进行人工打分。
(1)对每篇中文文章使用本文提出的方法进行跨语言文本相似度计算排序,即计算出和该篇中文文本相似的所有英文文章的相似程度并排序,截取其结果的前30篇作为人工打分备选。
(2)打乱这30篇文章顺序,交给人工进行标注,人工标注为:人工认为和待检索文章(即中文文章)相似或相关的英文文章打1分,认为不相似或不相关的打0分。
(3)定义相似准确率为[P1=tT],其中[t]表示算法计算排序为前[T]的文章中,人工标注结果为1的文章数,[T]表示选择标准,本文选用排序的前10位作为标准。同理,不相似准确率为[P2=fF],其中[f]为排序倒数[F]的文章中,人工标注为0的文章数。本文依然选择10作为[F]的具体参数,即认为相似度排序的计算结果中,排序21-30为不相似文章。
(4)对[P1]和[P2]进行加权调和平均处理,得出综合指标[F=2P1P2(P1+P2)]。
该评估方法参考了机器学习中常用的准确率/召回率评估方法,不同的是本文并不同于文本分类问题,无法计算常规的准确率或召回率,转而采用上述方法对排序结果进行评估,并且采用先使用算法计算再进行人工打分的方法,减少了人工标注时间。
为了对实验结果进行对比分析,本文使用基于全文翻译的文本相似度算法作为对照实验,并采用上述方法对结果进行评估。对300篇中英文文档分别进行相似度排序计算,取平均值作为最终实验结果。
实验结果如表1所示。
从表1可以看出,本文提出的基于文本加权词共现的跨语言文本相似度算法优于基于全文翻译的文本相似度算法,其对跨语言文本相似度的排序结果更接近人工排序结果。
3 结语
本文提出了一种新的跨语言文本相似度计算方法,该方法依据语义思想,基于文本加权词共现关系进行跨语言文本相似度计算。通过使用平行语料库实现跨语言的加权词共现关系模型,通过模型间不同语言共现词的映射关系进行跨语言文本相似度计算。本文详细阐述了根据平行语料库构建词共现映射模型的过程,以及根据词共现映射模型进行文本相似度计算的过程和实验流程。实验结果表明,本文提出的方法相对于基于机器翻译的跨语言文本相似度计算,更接近于人工判断标准。但是本文所提出的算法仍然存在改进空间:首先,语料库的来源没有针对性,本文所使用的句子级对齐语料库来源于电影字幕文件,但是字幕文件往往偏口语化,专业性较差,没有话题针对性;其次,词共现关系研究还有待深入,需要挖掘词之间更紧密的联系与关联。
参考文献:
[1] LI H,XU J. Semantic matching in search[J]. Foundations & Trends in Information Retrieval,2014,7(5):343-469.
[2] HALL P,DOWLING G. Approximates string matching[J]. Computing Survey,1980,12(4):381-402.
[3] 吴多坚. 基于 Word2Vec 的中文文本相似度研究与实现[D]. 西安:西安电子科技大学,2016.
[4] 秦春秀,赵捧未,刘怀亮. 词语相似度计算研究[J]. 情报 理 论 与 实 践,2007,30(1):105-108.
[5] 劉萍,陈烨. 词汇相似度研究进展综述[J]. 现代图书情报技术, 2012(7-8):82-89.
[6] LANDAUER T K,DUMAIS S T. A solution to Plato's problem: the latent semantic analysis theory of acquisition, induction, and representation of knowledge[J]. Psychological Review,1997,104(2): 211-240.
[7] BLEI D M,NG A Y,JORDAN M I. Latent Dirichlet allocation[J]. Journal of Machine Learning Research,2003(3):993-1022.
[8] 刘群,李素建. 基于《知网》的词汇语义相似度计算[J]. 中文计算语言学,2002,7(2):59-76.
[9] 孙琛琛,申德荣,单菁,等. WSR:一种基于维基百科结构信息的语义关联度计算算法[J]. 计算机学报,2012,35(11):2361-2370.
[10] 李彬,刘挺,秦兵,等. 基于语义依存的汉语句子相似度计算 [J]. 计算机应用研究,2003,20(12): 5-17.
[11] JIANG J J,CONRATH D W. Semantic similarity based on corpus statistics and lexical taxonomy[C]. Taiwan:Proceedings of the International Conference on Research in Computational Linguistics,1997.
[12] 胡吉明,肖璐. 向量空间模型文本建模的语义增量化改进研究[J]. 现代图书情报技术,2014(10):49-55.
[13] ZHANG X L,YANG T,FAN B Q,et al. Novel method for measuring structure and semantic similarity of xml documents based on extended adjacency matrix[J]. Physics Procedia,2012(24):1452-1461.
[14] WACHE H,VOGELE T,VISSER U,et al. Ontology based integration of information a survey of existing approaches[C]. Seattle Proceedings of the IJCAI01 Workshop on Ontologies and Information Sharing,2001:108-117.
[15] OARD D W,HACKETT P. Document translation for cross-language text retrival at the university of Maryland[J]. Journal of Computer Science & Technology,1998,30(2):259-272.
[16] MAIKE ERDMANN,ANDREW FINCH. Calculating Wikipedia article similarity using machine translation evaluation metrics[C]. Procedings of the 2011 IEEE Workshops of International Conference on Advanced Information Networking and Applications,2011:620-625.
[17] WESSEL KRAAIJ,NIE J Y,MICHEL SIMARD. Embedding web- based statistical translation model in cross-language information retrieval[J]. Computational Linguistics,Sep,2003,29(3):381-491.
[18] ALBERTO BARRON-CEDENO, PAOLO ROSSO, DAVID PINTO,et al. On cross-lingual plagiarism analysis using a statistical model[C]. ECAI 2008 Workshop on Uncovering Plagiarism, Authorship, and Social Software Misuse,2008:9-13.
[19] MARTIN POTTHAST,BENNO STEIN,MAIK ANDERKA. A Wikipedia-based multilingual retrieval model[C]. Proceedings of 30th European Conference on IR Research,ECIR 2008, Glasgow, LNCS, Berlin Heidelberg, New York, 2008: 522-530.
[20] YANG Y M,JAIME G,CARBONELL, et al. Translingual information retrieval: learning from bilingual corpora[J]. Artificial Intelligence,1998,103(1-2):323-345.
(責任编辑:杜能钢)
