基于群智数据的情境关联旅游路线推荐
2020-05-25李智敏於志文
郭 斌, 李智敏, 张 靖, 於志文
(西北工业大学 计算机科学系 陕西 西安 710129)
0 引言
随着大众旅游时代的到来与互联网的普及,旅游爱好者们热衷于在互联网旅游平台通过游记的形式记录自己旅途中的感受、经历,游记中包含着丰富的图像、文字等多媒体信息,用户所贡献的旅游相关内容可视为群体智慧信息,可以给其他旅游爱好者提供重要的参考信息。然而,由于用户量日益增大,马蜂窝网站(http:∥www.mafengwo.cn)游记数量日益庞大,且内容各异、千人千言,给用户在获取知识和整理知识时造成了负担,用户即使耗费大量时间进行阅读仍难以从中获取最适合自己的信息。据统计[1],在马蜂窝自由行问答系统中,景点类问题(如何在景点内游玩、景点内哪些景观是受欢迎的、景点概况等)热度排行为第三名,景点内的安排等问题是旅游爱好者们非常关注的领域,“如何玩转景区”成为用户迫切的知识需求[2]。用户十分需要一种智能推荐方法来从海量信息中根据个性化需求快速准确地为其推荐景区内的游玩路径。
游记成为旅游领域群智知识的一个重要载体,并得到学术界越来越多的重视。目前,大多工作研究群体智能数据[3-4]的主要目的在于对大量用户在网络社区贡献的多模态、富内容的数据进行挖掘与理解,从而获得各种智能信息并将其运用到各种创新型服务中。在旅游推荐领域,Yuan等[5]使用Flickr上的数据对景区内的热门景点进行推荐;Ji等[6]也运用群智数据对城市进行了地标挖掘;孙焕良等[7]通过转移图模型实现了时间敏感的最佳路线推荐。然而这些推荐系统只能给用户以单维度的推荐,无法将路径以可视化、多元化方式呈现给用户。
在本文的研究工作中,如何联合使用丰富的文本信息与图片信息是一大挑战。首先,游客视角多,拍摄角度各不相同,造成同一景区内的不同景观类内差异大、类间差异小;其次,过于多样化的图片难以进行筛选和保留;最后,游客们的旅游路径各不相同,不能以一种统一的方法来评估每一种路径的好坏。
基于此,本文提出一种基于群智数据的跨模态分析与情境关联旅游路线推荐方法。首先使用跨模态分析方法将互补的图像与文本相结合,再进行分类识别,然后基于图模型使用PhotoRank算法优选出具有多样性、代表性的图片,最后采用关联规则挖掘,得到针对不同出行人群的特定需求情境的推荐路线,使推荐结果更加个性化,更符合用户的需求。通过从马蜂窝上采集的游记多媒体数据进行实验,结果表明本文工作具有较好的用户反馈,在路径的合理性、图片的多样性和代表性上都取得了良好的效果。
1 系统框架
系统输入为游记数据与用户个性化情境,其中游记数据包括文本、图像、发布时间等内容;系统输出为基于用户输入情境的路线推荐,并配以多角度、具有代表性的图片。
系统处理包括3个步骤:首先对多模态的游记内容进行分析,将游记中图片与文字按照对应景观进行分类识别;然后根据每组数据中文本和图像的联系建立景观图模型,在此模型基础上提出了满足多样性和代表性的图片优选方法;最后进行智能路线推荐,即从景区所有游记文本中进行游览路线挖掘后根据用户输入的不同情境进行关联路线挖掘,并配以上一步优选图片进行可视化呈现。
1.1 基于跨模态分析的景观图像分类识别
用户贡献的游记知识包含丰富的图像与文本数据,与景区官方提供的信息相比,这些群智信息更加真实、多样。但游记作为一种自由化文本,具有内容和结构的双重随意性,并包含大量噪声。若构建结构化的景观信息库,需要对游记的知识进行筛选与分类识别。同时,大多景区内建筑风格统一且较为相似,景观的外观颜色、轮廓相差较小。此外,游记中的图片大多数为游客从多角度拍摄的,造成图片类内差距大、类间差距小,给图片的分类识别增加了难度。考虑到文本与图像之间存在着互补关系,本文将两种数据的分类模型结合,分别使用卷积神经网络(convolutional neural network,CNN)与循环-卷积神经网络(CNN-recurrent nueral network,CNN-RNN)学习图像与文本的深度表达,通过联合预测来提升分类的准确率。
本文采用ResNet-50[8]处理模型对图像进行处理。网络的第一层定义输入图像尺寸为224×224×3。第一层对数据进行预处理,接下来的卷积层、激活函数和池化层等中间层构成了整个神经网络的主要部分,之后为3个全连接层,最后为分类层,类的个数等于景区内主要景观的个数。
在此之后,采用深度结构化联合嵌入[9]的方法把图像和文本共同用向量表示出来。本文用深度神经编码器生成的特征内积把图像和文本之间的联系最大化,与其他图片之间的兼容度最小化。
给定一组数据D=(vn,tn,yn),n=1,2,…,N,其中:v∈V代表图片数据;t∈T代表图片对应的文本;y∈Y代表数据的标签。定义图像分类识别函数为fv:V→Y,文本分类函数为ft:T→Y。而后计算图像和文本特征的内积,定义兼容函数F:V·Y,其中特征向量是通过图像的编码器函数θ(v)及文本的编码器函数φ(t)学习得到,
F(v,t)=θ(v)Tφ(t)。
(1)
然后用CNN-RNN来学习视觉描述。参考文献[10]的方法,CNN的隐藏层置于模型的底部,RNN被放置于CNN之上,隐藏单元激活量被提取作为文本特征,如公式(2)所示,
(2)
其中:hi是隐藏层的第i个框架的隐藏层激活向量;L代表序列长度。图像与文字分别经过CNN、CNN-RNN处理后,图像可以根据图像特征向量得到分类预测,文本通过计算图像和文本之间的兼容函数来给出预测。最终,两个模型的预测结果通过公式(3)相结合,
f(I)=fv(v)+βft(t),
(3)
其中:fv(v)和ft(t)分别是图像和文本的分类函数,是通过交叉验证得到的参数。此外,本文通过CNN实现了昼夜情境识别,将白天、夜晚所拍摄照片进行分类识别并运用到图片推荐中。
1.2 基于图模型的景观图片优选方法
对于一个给定的景观,由于不同游客的偏好与游览线路不同,所以通常会在游记中呈现出不同角度拍摄的同一景观的图片,也会用不同的语言对其进行描述。为了使挑选出的图片既有代表性,又有多样性,本文提出了一种基于图模型的景观图片优选算法,可以将每个景观的优选图片展示给用户。
1.2.1图像及文本特征提取 本文从CNN以及CNN-RNN中分别输出图像及文本特征。
1.2.2图像优选算法 本文根据图片间文本和图像数据的联系建立景观图模型,基于此模型提出了景观图片优选算法,如算法1所示。
算法1基于图模型的景观图像优选算法
输入:Vi的文本特征向量集合X以及图像特征向量集合Y
输出:优选推荐图像集合O
1. C=K-means(X,Y,r)
2. for every ci∈C
3.if Wp(i,k)>median Wp
4.Lik=1
5.else Lik=0
6.if Link(ci)=∅ && Wp(i,j)=max
7.Lij=1
8.end if
9.TopPhoto=PhotoRank(N)
10.O.add(TopPhoto)
11. end for
12. return O
其中:Vi表示第i个景观所有图像及其文本描述;N表示无向图结点的集合;r表示聚类的簇数;Lik表示第i个节点和第k个结点之间的连线。
图像聚类:为了保证图片的多样性,对每一个景点的数据集合Vi,首先将图片进行聚类,聚类的方法经过比对实验选定为K-means聚类,将每个景点的数据聚为r个簇,r的大小即为最终输出结果,即每个景观所优选的图片的数目。
图模型生成:把每个簇中的图片联系起来建立一个无向图。假设聚类后的簇中含有n张图片及其配文,那么这个簇的无向图含有n个结点,每个结点代表一张图片和它的配文。在建立节点之间的边时,节点与结点之间的相似度similarity首先被计算,
Wp(i,k)=Wc(i,k)×Wt(i,k),
(4)
其中:Wc代表的是第i和j个结点对应的文本余弦相似度;Wt代表的是第i张图片和第j个结点对应的图片的余弦相似度。两组图文间相似度为其文本向量余弦相似度与图像向量余弦相似度的乘积。本文取相似度值在前50%的每组图文进行连接,同时规定每个结点至少与其他一个节点进行连接,即每个孤立节点与其相似值最高的节点相连接,最终得到一张每个节点都有至少一条连线的无向图。
PhotoRank:受PageRank[11]的启发,本文使用一种名为PhotoRank[6]的算法来判断每张照片的代表性的高低,如果一张图片和簇内其他图片及配文相似度非常高,则它具有较高的代表性,并将其命名为代表度。
首先进行初始化,每一个节点的代表度为1/n,n为无向图节点总数。每次无向图内的迭代和PageRank的原理相同,每个节点的流行度通过公式(5)计算得到,
(5)
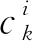
1.3 情境关联的景观路线推荐
情境关联在本文中指将游客的游览路线与其出行人群、时间等相联系。景观路线则是从游记中提取出游客从进入景区到离开景区的旅行路线,是一个包含该景区若干个景观的有序序列。本文基于关联规则挖掘提出了一套挖掘有序路径序列的方法,流程如算法2所示。算法可分为3个步骤进行,分别为建立路线库、情境关联、序列挖掘。
算法2情境关联的景观路线推荐算法
输入:人群crowd 0, 月份month 0, 昼夜dayornight 0, 景观集合S={si,s2,…,si}, 含标签的游记文本集合T={t1,t2,…,tk}
输出:情景关联的推荐游览路径
1. for every tiin T
2. ci=ti∩N
这场讨论受到了租界当局、军警和卫道士们的围攻,《民国日报·觉悟》的主编邵力子先生受到处罚,魏金枝寄去的文章忽然不登出来了,他写信去追问,邵力子回信中表示很尴尬,劝他不要再讨论这个问题,免得他受罚。这场恋爱的争论就此终结。魏金枝很不满意,就写了一篇新诗《大风歌》,“想将一股大风,把一切阻碍人世间的障碍一气吹得精光。”可惜这诗篇目前还没有找到。
3. if len(ci)≥num(S)/4
4. R.append(ci)
5. end if
6. end for
7. R_rec=R.contain(input)
8. Popular_si=ni.occurance
9. k=1
10. for k in range(num(ni))
12. M.append(sk)
13. if len(M)=num(S)‖sk.next=∅
14. break
15. print M
16. end if
17. end for
1.3.1建立路线库 通常情况下游记均是以时间的先后顺序来展开叙述,故默认游记中景点的出现顺序即为游览顺序,可提取成为一条路线。将游记与官方景点取交集并进行去重处理即可得到游记中的游览路线,同时获取游记发布时间与游记文本中提及出行人群作为该路径的tag。在所有路线中,考虑到质量因素,景点数少于该景区景点总数1/4的路线会被剔除,剩余路线放入路线库R。
1.3.2情境关联 不同的人群有时会因为季节、节日、昼夜的差异而产生不同的游览序列,而这些知识恰恰是可以通过旅游爱好者们在平台上发布的群智数据呈现的。为了能够给游客提供更加有针对性的路线推荐方案,本文给每一条路径添加上人群(crowd)与时间(month)标签。
关于人群(crowd)标签,本文通过游记的文本挖掘获取,主要包括以下类别:独自出行、陪老人出行、带孩子出行、家人出行、情侣出行、朋友出行、夫妻出行。根据本文建立的词库,如在游记中若出现老人、长辈等字词,便视该游记为陪老人出行,其余以此类推。
关于时间标签,即month,在爬取游记时本文一同爬取游记发布时间,将游记发布的月份视为旅行时间,标注为该游记所提取路径的时间标签。
1.3.3路径序列挖掘 用户通过选择人群(crowd)、月份(month)与昼夜(dayornight),可获取路径。 通过crowd与month对推荐路径进行筛选,通过dayornight对推荐图片进行筛选。若游客没有设置输入值,则对所有提取的路径进行筛选。推荐路径的挖掘方法根据关联规则挖掘而改进。在所有路径中的第一个景观的集合中找到出现次数最多的景观作为推荐路径的第一个景观,而后依次找出当前景点的下一个数目最多的景点作为推荐路径的下一个景点,当且仅当下一景点不与之前路径M中景点重复。按照此方法依次找到接下来的景点,直到推荐路径包含景区所有景点,或当所有路径中对应的下一个景观都在M中,便将此时的M作为推荐路径推荐给游客。
2 实验验证
2.1 实验数据
本文以大唐芙蓉园、故宫、颐和园、鼓浪屿、黄山、西湖、承德避暑山庄共7个景点为例进行实验,获取景点游记数量、总图文数据数量、训练集数量、测试集数量分别如表1所示。
2.2 基于跨模态分析的图像分类识别
经过实验得到公式(3)中的β值为3。本文将跨模态分析方法与传统机器学习方法中支持向量机(support vector machine,SVM)、朴素贝叶斯、随机森林分别对图像、文本、图像与文本结合进行了测试。其中,SVM、朴素贝叶斯、随机森林分类方法使用通过bag-of-visual-words提取的图片特征与词频-逆文本频率(term frequency-inverse document frequency,TF-IDF)文本特征。

表1 七个景点的实验数据Table 1 Experimental data of seven scenic spots
由于景观图片集的特殊性,传统的机器学习方法对游记中图像的分类效果比较差,无法解决景观之间较为相似的问题,实验结果如表2所示。尽管本文所采取的对比实验方法是目前较为流行且较为简便的分类方法,由实验得出,传统机器学习方法准确率都在72%以下。

表2 传统机器学习方法与本文方法结果对比Table 2 Comparison of traditional machine learning method and our method 单位:%
通过结果对比分析,使用CNN-RNN跨模态分析图像与文本的方法得到的效果较其他几种有着明显的提升。在深度学习方法的对比中,本文的方法比传统CNN图像分类方法提升了4%的准确率,由此可见在类内差距大、类间差异小的景观数据中,文本与图像互相补充,将两者结合起来能得到更好的结果。
2.3 图像聚类评估及图像优选结果
本文使用3种聚类方法K-means、mean shift、BIRCH进行聚类,并基于轮廓系数评判聚类结果,经过试验得到3种聚类方法的平均轮廓系数分别为0.36、0.19、0.27,因此本文选用得到轮廓系数值最大的K-means方法。
本文对聚类后50个景观内的每个簇构建了无向图,其中点的位置由图像特征向量经过映射而成。以“十七孔桥”为例,此景观聚类得到5个簇,得到的无向图如图1所示。

图1 景观“十七孔桥”每簇构建的无向图Figure 1 Undirected graphs of clusters in the landscape “Seventeen-arch Bridge”
2.4 路径推荐结果呈现
本文将crowd、month、dayornight分别设置为<带老人,七月, day>、<带小孩,五月, night>以此为例生成的大唐芙蓉园推荐路径如图2、图3所示。

图2 <带老人,七月,day>大唐芙蓉园可视化推荐路径Figure 2 Visual path recommendation route of Datang Paradize with the tag
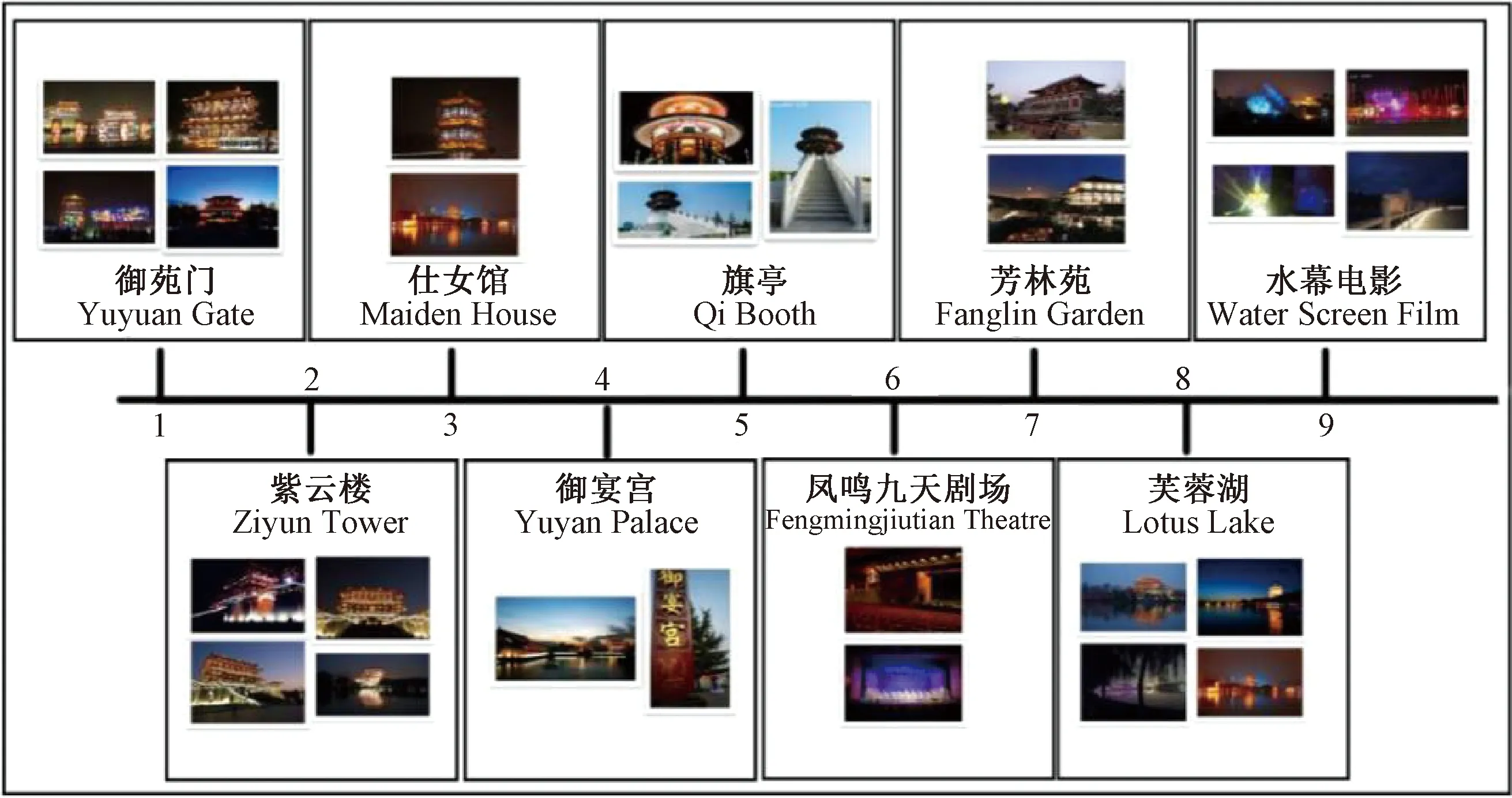
图3 <带小孩,五月, night>大唐芙蓉园可视化推荐路径Figure 3 Visual path recommendation route of Datang Paradize with the tag
从推荐路径中可以看出,由于不同的出行人群在不同的出行时间有不同的偏好,最终所呈现结果是具有年龄和时间特色的。经过优选的图片也可以对景观进行不同角度的展示,从而让用户更好地了解景观的各个角度。在筛选标签中加入的昼夜情境的选项也可以帮助用户了解相同景观在不同时间的景象,可帮助其更好地规划路径与出行时间。
2.5 用户体验
20名年龄从20到54岁不等的用户受邀参与到使用者研究中,将路径推荐的结果呈现给他们,并且让他们从4个方面进行打分,分别为路线推荐的合理程度(1分表示不合理,5分表示非常合理)、图片与景观的一致性(1分表示不一致,5分表示非常一致)、图片的多样性(1分表示不具备多样性,5分表示多样性极强)、推荐图片的质量(1分表示图片质量很低,5分表示质量很高),并对打分结果进行统计。用户对路线设计的合理性达到4.58分,对图片文字的一致性为4.1分,对描述景点图片的多样性和质量打分分别为4.16分和4.34分。由此可以看出本文的工作收到了使用者积极的反响,图片在多样性、代表性上都取得了一定的效果,证明了该研究在旅游领域的价值。
3 总结与展望
本文提出基于群智数据的跨模态分析与情境关联旅游路线推荐方法,通过挖掘群体智慧信息可以很好地满足不同用户不同情境的需求。在基于跨模态分析的图像分类识别中,运用CNN-RNN克服了同一景区图片类内差距大、类间差距小的现状,实现了较传统机器学习方法更好的分类识别效果。基于图模型的景观图片优选算法通过聚类、建立无向图、使用PhotoRank对类内节点重要性进行排序,实现了具有多样性、代表性的景观图片优选;情景关联的路径推荐通过游记中群智知识为不同人群在不同时间出行进行了智能推荐,为用户的出行提供了重要参考。
当前的研究中仍然存在着不足和可以改进的方向。在未来的工作中本文可以考虑实现智能化跨媒体关联,实现游记中图片与对应文本的自动关联,来达到更好的效果;在图片多样性方面,本文目前已经完成了基于聚类的图片多样化排序,但目前的评价方式较为单一,只通过使用者研究的方式进行评价。如何构建标准答案或者测评集以及通过与其他方式对比证实是否真实有效,还需要进一步研究。
