机器学习辅助的高通量实验加速硬质高熵合金CoxCryTizMouWv成分设计
2020-05-23王炯,肖斌,刘轶,
王 炯,肖 斌,刘 轶,
(1. 上海大学 材料基因组工程研究院,上海 200444)(2. 上海大学物理系 量子与分子结构国际中心,上海 200444)
1 前 言
研发具有特定目标性能的新材料时,传统的材料研究通常采用经验试错法,通过少量实验离散地调整样品成分与制备工艺来探索材料的最佳性能。然而,这种“炒菜式”研发手段耗时且成本高昂,同时由于实验数据量较少,对材料结构-性能关系考察不够全面深入。随着材料基因组工程的兴起[1],利用高通量实验、计算模拟和机器学习加速新材料研发,受到了越来越多的关注。早在1970年,Hanak[2]提出了包含高通量材料研发(high-throughput materials development,HTMD)在内的所有环节流程,该研究被认为是材料领域内最早提出高通量概念的工作。1980年,Moulijn等[3]发表了使用多相催化平行反应器的高通量材料制备研究。1997年,Danielson等[4]采用电子束蒸发法在一个直径为7.6 cm的衬底上合成了25 000种不同成分的材料。近年来,研究者们基于材料组合芯片思想,采用气相沉积、磁控溅射等工艺制备了每个成分连续变化的多组元薄膜样品或一批成分离散变化的块体样品[5-9]。总之,高通量材料制备方法具有多工位、自动化、并发式的特点,可以实现材料的快速、批量合成,比传统的单一样品生产模式在材料制备效率上有大幅度提升。随着实验数据的积累,材料数据库在新材料研发设计过程中也起到越来越重要的作用。Bligaard等[10]利用包含晶格尺寸、体积模量等物理量的有序化金属玻璃数据库,筛选出了具有低压缩性、高稳定性和低成本的备选材料。但通常情况下,针对某一类材料的单一或几个性能进行设计时,高质量、大批量的数据还很缺乏,甚至某些全新体系可能不存在已有实验数据,此时高通量实验成为获取大量优质、自洽实验数据的有力手段。
虽然高通量实验能够有效提升研究效率,但面对多元合金巨大的成分参数空间(数千至数万个成分组合)时,探索所有潜在合金成分在实验上是几乎不可能的,合金成分优化设计依然是一项艰巨的挑战。因此,将机器学习法引入到材料成分设计领域成为了加速新材料研发进程的重要手段。传统的机器学习法中,以神经元网络(ANN)、支持向量机(SVM)、随机森林(RF)、K近邻(KNN)等方法最具代表性[11-22]。2016年,Raccuglia等[23]利用失败实验数据结合SVM算法成功建立了无机-有机杂化材料结晶过程反应模型,并预测了新化合物的形成条件,准确率达89%。此外,机器学习法也被作为加速研究方法广泛应用于介电特性[24]、无机晶体带隙[25]、熔点[26]、抗压强度[27]、硬度[28]、相结构[29]等材料性质研究。
自Senkov等[30, 31]制备了具有优异高温性能的W-Nb-Mo-Ta-V系列bcc相难熔高熵合金后,关于难熔高熵合金的研究受到了极大关注。研究者们广泛研究了含W,Mo,Ti,Nb,Ta,Zr的高熵合金体系[32-37]。除纯相高熵合金外,还广泛研究了高熵合金中第二相对合金性能的影响[38-40]。本工作将高通量实验与机器学习法相结合,应用于开发新型非等摩尔比的硬质高熵合金。在元素组成上,考虑到高熔点的W和Mo以及Co,Cr,Ti等在高温结构材料中广泛应用的金属元素,以CoCrTiMoW体系为基础设计了新型非等摩尔比的硬质高熵合金。
2 实 验
2.1 高通量实验
本工作首次提出了以制备离散成分块体合金为特色的全流程高通量材料制备概念,涵盖合金样品配料、混合、压块、电弧熔炼、镶嵌、切割、磨抛的合金熔炼和金相样品制备环节。基于此思想,上海大学材料基因组工程研究院与合肥/沈阳科晶材料技术有限公司联合设计研发了全流程高通量合金制备系统,具体包括36工位粉料分配器、16工位球磨混料机、16工位压力机、32工位自动电弧熔炼炉、16工位冷镶嵌机、8工位线切割机以及16工位自动磨抛机(图1)。本实验的合金熔炼和样品制备均由高通量合金制备系统完成,对材料制备流程各环节实现了多工位、自动化加速,缩减了单个样品的平均实验准备和运行时间,例如省略了传统电弧熔炼的多次抽真空过程,克服了材料制备过程中耗时的瓶颈。该高通量合金制备系统的整体效率比传统单一或少样品制备方法提升了至少10倍。
本工作以粒径均约为50 μm的Co,Cr,Ti,Mo,W纯金属粉为原材料,其纯度均大于99.5%(质量分数),共制备了138个合金样品,其成分分布在CoxCryTizMouWv空间内。初始的合金成分设计采用以下两种策略:① CoCrTiMouWv,重点调整难熔金属W和Mo的含量;② CoxCryTizMouWv,首先将成分映射到与合金相稳定性有关的描述因子价电子浓度-原子半径差(VEC-δ)空间[41],然后选取VEG-δ空间内均匀分布的点转换回成分。
本工作使用自动粉料分配器根据给定合金成分进行配粉。将配置好的合金粉末经过自动球磨机充分混合均匀后,利用自动压力机压制成圆柱状块体(直径约为2.05 cm,高度约为1.50 cm)。然后在Ar气氛保护下的手套箱内利用自动电弧熔炼炉中的水冷铜模具自动连续熔炼制备铸态金属锭。每个工作流程最多可熔炼32个金属锭,单个金属锭的重量约为10 g,需反复熔炼5次以上以保证其组织均匀性。然后,经冷镶嵌和磨抛后(依次用颗粒粒度为70,37,15,12,7和5 μm的砂纸打磨、抛光)制成金相样品。最后,采用HBRV(D)-187.5A1型手动布洛维三用硬度计测试合金的宏观维氏硬度(HV),测试条件为:压力为30 kg,预加载时间为3 s,加载时间为10 s。对每个样品进行多次宏观硬度测量,至少获得五次以上有效值并取其平均值。138个不同成分的合金的HV测量结果如图2所示,其中36个合金的HV低于600 MPa,70个合金的HV在600~800 MPa之间,32个合金的HV高于800 MPa。

图1 全流程高通量合金制备系统Fig.1 All-process high-throughput synthesis system of alloy

图2 138个高熵合金CoxCryTizMouWv样品的硬度实验测量值Fig.2 Experimental HV values of 138 high-entropy alloy CoxCryTizMouWvsamples
2.2 机器学习
机器学习数据集为通过高通量实验获得的138个合金的硬度数据。由于全流程高通量合金制备系统尽可能提供了相同的实验环境和过程,减少了因工艺参数不同造成的数据不确定性。对于不同的机器学习预测模型,本工作采用决定系数R2、平均绝对误差MAE与均方根误差RMSE来综合评判模型优劣。考虑到小数据样本和数据本身的误差,在最终模型选用上,采用评判拟合效果的相关系数R2作为第一判据,并结合考虑MAE和RMSE。R2,MAE和RMSE由式(1)~式(3)计算得到:
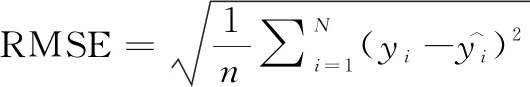

2.2.1 机器学习算法与特征
本工作测试了RF[42]和SVM[43]机器学习算法,其中SVM法选择了高斯径向基核函数(rbf)与线性核函数(linear),将上述算法分别记为RF、SVM_rbf和SVM_linear。所有机器学习算法由Python语言实现,主要使用Scikit-learn算法包[44]以及Pandas和Numpy计算扩展库实现数据的读入与处理。
本工作的机器学习共使用了29个基础特征描述因子(表1)[45-48]和1个目标变量——HV。机器学习模型的输入特征是基于合金体系中不同元素的基本属性,以各组元成分的摩尔比为权重的算术平均值构建生成。因此,将29个基础元素或单质体相材料的描述因子分为4组:
(1)AD:编号1~29的所有描述因子。
(2)EMF:只包含编号1~5表示元素摩尔比的描述因子。
(3)VDSHOT:VEC,△Hmix,△Smix,Tm,Ω,δ与高熵合金相结构关联的特征[41, 49-52]。
(4)SD:选择特征集合,由经RF算法评估后排名前9位的描述因子组成(δ,DC,NC,RC,△Smix,EI,W,EN,Cr)。

表1 机器学习模型的描述因子[45-48]
2.2.2 机器学习策略
将3种机器学习算法与4种描述因子集合进行组合,构建了12个机器学习方法,如表2所示。使用五折交叉验证法分别对12个机器学习方法的超参数进行优化,即80%的数据用于建模,20%的数据用于评估算法的精度。对12个机器学习方法分别进行10次随机数据集划分(8∶2)建模,共获得120个机器学习模型,记为ML(120)。

表2 由3种机器学习算法与4种描述因子集合组合而成的12个机器学习方法
2.2.3 模型选择
图3为按照描述因子集合划分的120个机器学习模型评估结果。RF、SVM_rbf和SVM_linear 3种机器学习算法使用4种描述因子集合构建的模型的预测能力定性基本相似,其中以AD构建的模型的预测结果定量最优,后续针对该系列模型的预测结果进一步讨论。不同机器学习算法的预测精度排序为RF>SVM_rbf>SVM_linear。虽然RF算法的模型预测能力最好,但SVM算法在随数据集划分变化时的波动性显著小于RF算法,这说明SVM算法相较于RF算法对小样本数据集合具有更强的鲁棒性。考虑到机器学习建模过程中小样本数据集划分对模型的影响,在最终模型的选择上除了以R2作为判据,也结合较低的MAE和RMSE进行综合评判,因此挑选出的最佳模型为RF/AD_4。此外,还从鲁棒性强的SVM_rbf算法生成的模型中依据R2选出一个最优模型SVM_rbf/AD-5,进而比较这两种模型在合金硬度预测趋势上的异同。
预测精度最好的RF/AD_4和SVM_rbf/AD-5模型的评估结果如表3所示,138个合金样品硬度的实验测量值(H138e)和机器学习模型预测值(H138m)如图4所示。两个模型的预测结果在趋势上表现出一致性,但RF/AD_4模型在数据相关性和预测误差方面明显要优于SVM_rdf/AD-5模型。RF/AD_4模型在低(HV<600 MPa)、中(600
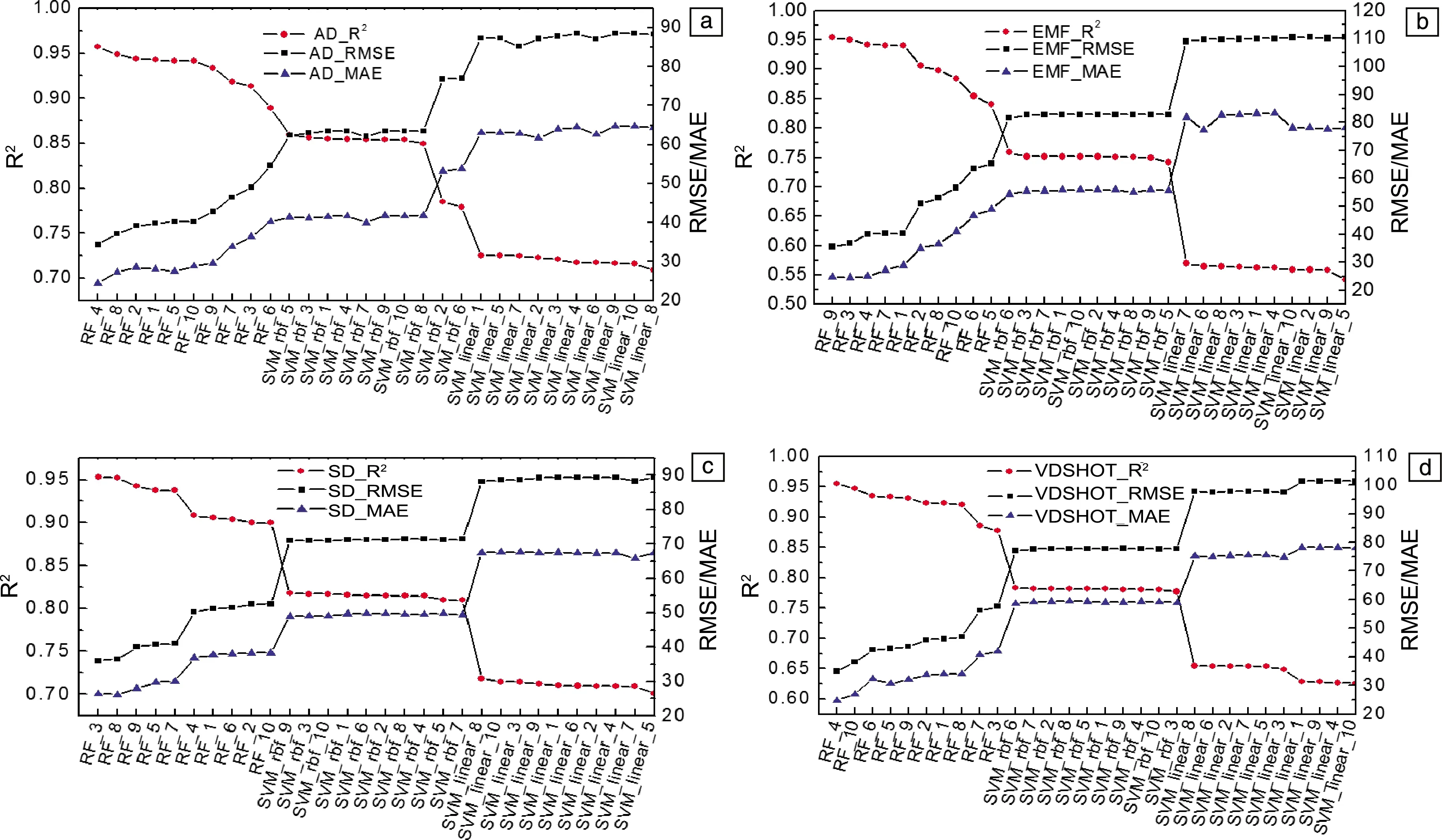
图3 按照描述因子集合划分的120个机器学习模型的评估结果:(a)AD,(b)EMF,(c)SD,(d)VDSHOTFig.3 The evaluation results of 120 machine learning models divided by different descriptor sets: (a) AD, (b) EMF, (c) SD, (d) VDSHOT

表3 RF/AD_4与SVM_rbf/AD-5模型的评估结果
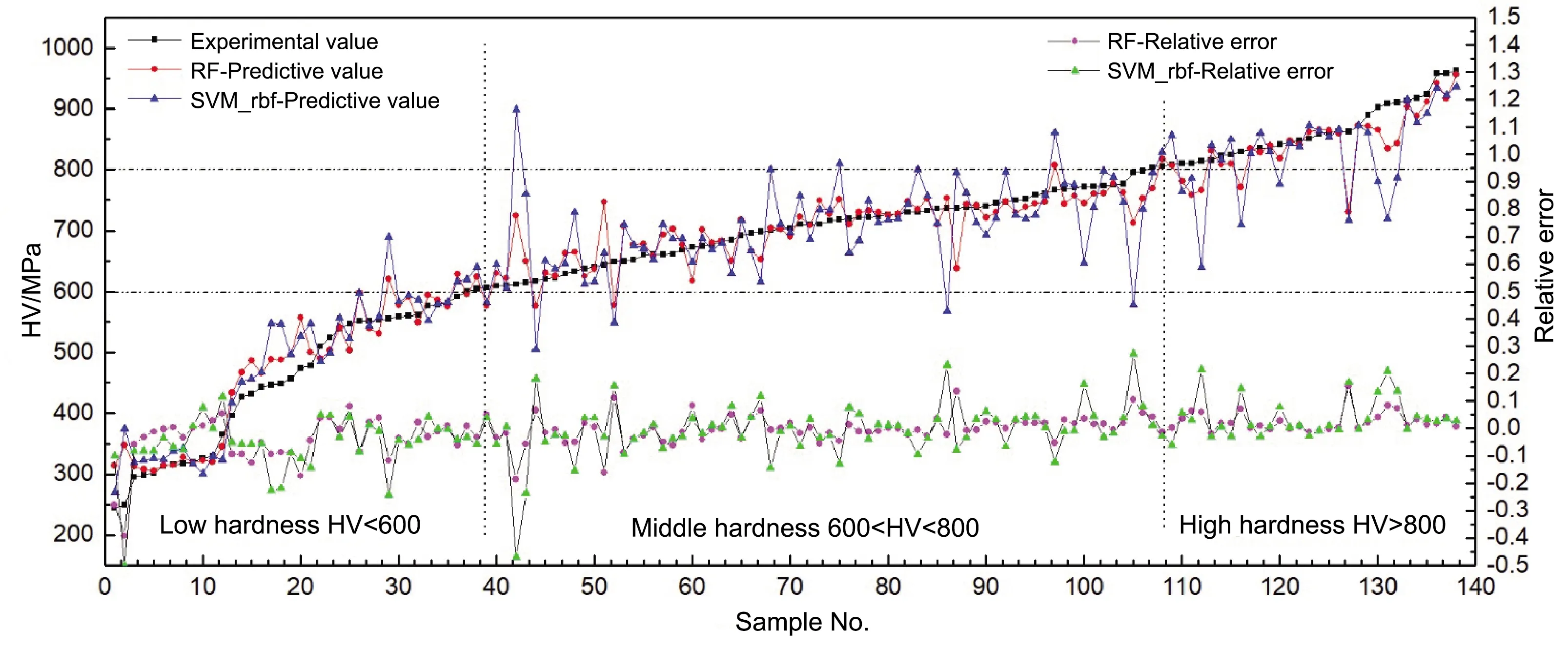
图4 138个合金样品硬度的实验测量值、模型预测值以及预测值的相对误差Fig.4 Experimental values,predictive values and relative errors of predictive values to the hardness of 138 alloy samples
3 结果分析
3.1 描述因子的选择
使用RF算法对29个描述因子的重要性进行排序(图5),其中RF算法的回归树采用最小均方差原则计算、评估描述因子的重要性,其重要性由高到低排名前9的分别为:δ,DC,NC,RC,△Smix,EI,W,EN和Cr。根据重要性排序,其中最重要的描述因子为δ,表明δ在29个描述因子中对合金硬度的影响最大,相关文献也证明了δ对合金硬度有显著影响[53, 54]。从合金组元角度分析,各元素按其对合金硬度影响的大小排序为:W>Cr>Mo>Ti>Co。因此,将排名前9的描述因子作为SD用于机器学习建模,由其构建的模型预测结果如图3c所示。

图5 机器学习中29个描述因子的重要性排序Fig.5 Importance order of 29 descriptors in machine learning
3.2 “成分-硬度”图谱
图6分别为根据RF/AD_4与SVM_rbf/AD-5模型预测结果绘制的合金全成分空间的“成分-硬度”图谱(composition-hardnessmap, CH map)。两个模型在对CoxCryTizMouWv合金体系全成分空间的硬度预测结果上显示出相似的趋势。对于五组元成分体系,有4个独立成分变量。两个模型在CH图谱上都具有4条与成分变量相对应的硬度包络曲线,且各硬度峰值对应出现在相同的成分区间内。以合金元素的摩尔比作为变量,硬度随成分改变呈现有规律的变化趋势。
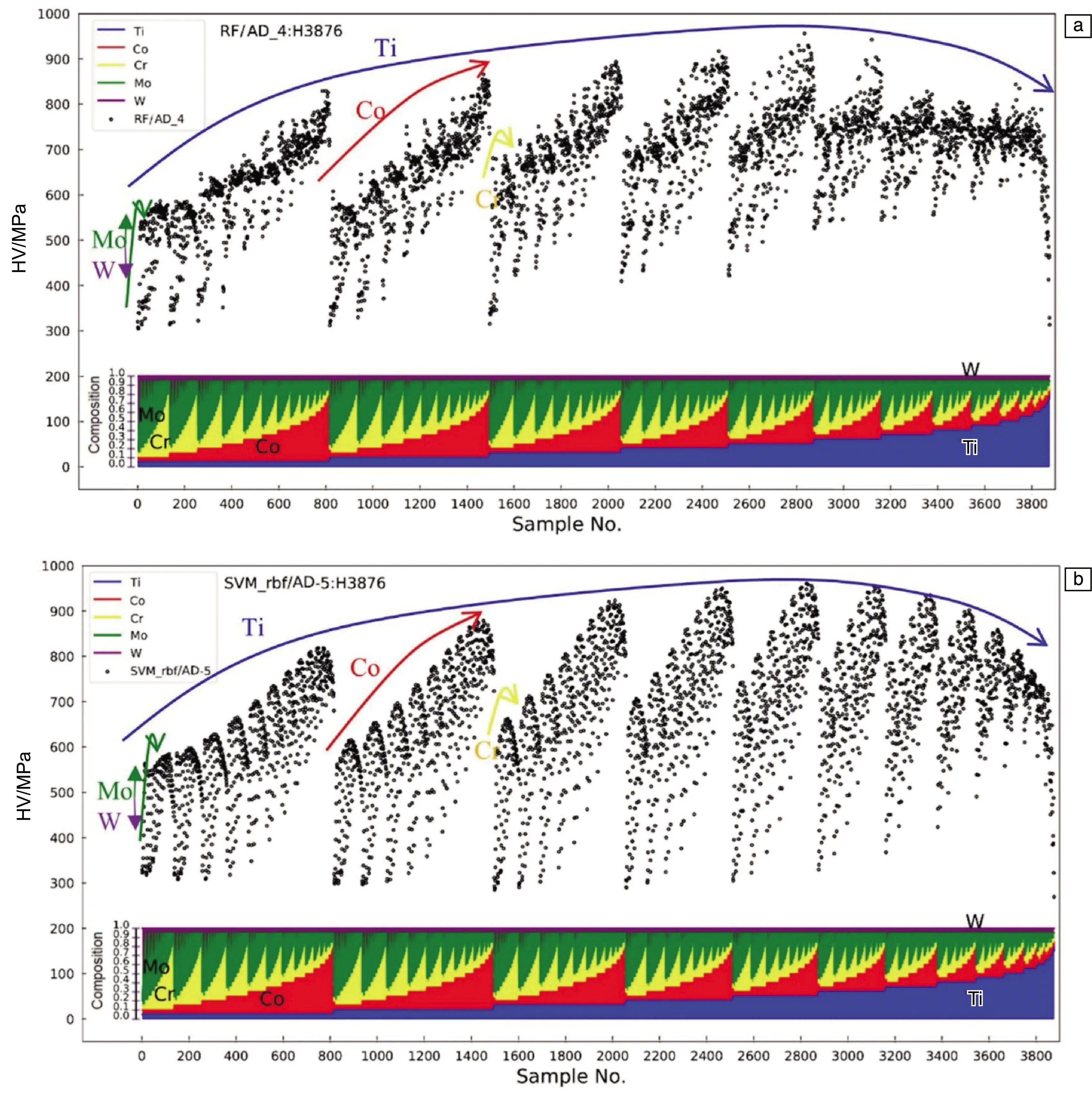
图6 根据两种机器学习模型预测结果绘制的高熵合金“成分-硬度”图谱:(a)RF/AD_4,(b)SVM_rbf/AD-5Fig.6 “Composition-hardness” maps of high-entropy alloy constructed by the two kinds of machine learning models: (a) RF/AD_4, (b) SVM_rbf/AD-5
以Ti作为第一层变化元素,可以看到合金体系的硬度包络曲线随着Ti含量的升高先升高再下降,而且后半段曲线有加速下降的趋势。结合一般二元固溶体合金的经验,在一种元素的含量由0增加到1的过程中,合金一般会经历“单相-固溶相-金属间相-固溶相-单相”的转变过程。在单相区间内,随着元素含量的变化,晶格畸变也将发生显著变化,从而影响位错在晶粒内部的运动,产生位错钉扎等效应,对合金的力学性能产生影响。当合金内产生金属间相,或单相结构产生较大的晶格畸变时,合金会表现出较高的硬度;而当合金成分接近单一组元(即固溶组元含量少)、晶格畸变较小时,合金一般表现出较低的硬度。由图6中的4条硬度包络曲线可以看出,在某一元素的含量达到最高值时,其对应的合金硬度出现跳变,由于x轴的成分变量按照Ti,Co,Cr,Mo,W的顺序进行排序组合,因此Ti,Co,Cr对应的3条硬度包络曲线变化更为显著。这两种模型的预测结果与传统经验有类似的变化规律,这也证明了模型预测结果的可靠性。
3.3 “描述因子-硬度”图谱
除了建立CH图谱,还根据RF/AD_4模型预测结果,将硬度投影到二维机器学习描述因子平面中构建“描述因子-硬度”图谱(descriptor-hardness map,DH map),如图7所示。由于部分描述因子具有特定的物理含义,这种表示材料性质的描述因子投影图有助于理解合金成分之外的描述因子对合金硬度的影响规律。这种不含特定合金成分的图谱可能具有更广泛的适用性,不仅可应用于CoxCryTizMouWv特定合金体系,还可能扩展到其他多元合金体系的硬度预测。另外,将多组元成分空间投影到二维描述因子空间内,还将有效降低合金初始成分选择的维度,实现快速简便的合金成分反向设计。
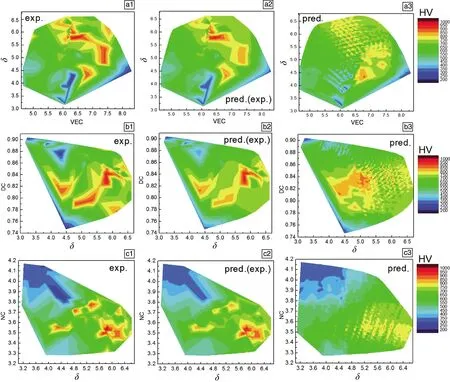
图7 138个合金硬度的实验测量值(H138e)(1)、机器学习模型预测(H138m)(2)和全局成分空间内3876个合金硬度的模型预测值(H3876m)(3)的“描述因子-硬度”图谱(图中的彩色标尺代表硬度,从蓝到红表示硬度增加):(a)VEG-δ,(b)δ-DC和(c)δ-NCFig.7 “Descriptor-Hardness” maps of H138e (1), H138m (2) and H3876m (3) (The color scales represent the hardness value increased from blue to red): (a) VEG-δ, (b) δ-DC and (c) δ-NC
图7a1~7c1为H138e分别在VEG-δ,δ-DC和δ-NC空间的DH图谱;图7a2~7c2为H138m分别在VEG-δ,δ-DC和δ-NC空间的DH图谱;图7a3~7c3为全成分空间内3876个合金硬度的模型预测值(H3876m)分别在VEG-δ,δ-DC和δ-NC空间的DH图谱。与H3876m的DH图谱相比,H138m与H138e的DH图谱更吻合,这是因为后两者是点对点对应,而前者在相同范围内布点更密集,其高硬度与低硬度可能非常接近。尽管预测结果在绝对数值上可能存在差异,但在二维描述因子空间下,硬度分布呈现出定性相似模式。在DH图谱中,VEG-δ映射中的高硬度区和低硬度区间的分离距离最大,表明VEG-δ空间在分离和预测硬度上具有优势。实际硬度预测可以由多个DH映射同时确定,进一步增加预测的可靠性。
4 结 论
本文利用高通量实验结合机器学习的方法加速非等摩尔比的硬质高熵合金CoxCryTizMouWv的成分优化设计,使综合设计效率提高了200倍以上。利用本团队自主研发的一系列新型全流程高通量合金制备实验设备,多工位、大批量、自动化制备具有离散成分的块体合金,较传统单/少样品制备过程至少加速10倍。该套高通量材料制备系统包括合金熔炼和金相样品制备流程,具体涵盖配料、混合、压块、电弧熔炼、镶嵌、切割和磨抛。利用高通量实验合成了138个不同成分的合金样品,根据其硬度数据使用3种机器学习算法(随机森林和两种支持向量机法)和4种描述因子集合构建了120个机器学习模型。研究结果表明,随机森林比支持向量机精度更高,其预测结果与实验测量值接近。通过机器学习建模设计合金成分,与在全成分空间内排列组合式的穷尽搜索相比至少加速了20倍。利用机器学习模型构建全成分空间内的“成分-性质”和“描述因子-性质”关系,“从数据驱动设计再返回到知识驱动设计”,从而实现认知的螺旋式上升。本工作证明了材料基因组计划提出的低成本加倍材料研发速度不仅可能,而且效率会比最初提议的两倍更高。机器学习指导下的高通量实验方法可成为加速多组元材料成分优化设计的有效通用策略。未来材料研究需要在“机器学习”的基础上聚焦“向机器学习”,从而获得新的专业领域知识。
致谢:感谢上海大学高水平大学建设项目对高通量实验设备研制的支持;感谢中铝材料应用研究院、鞍山钢铁公司、云南锡业集团、福建南平铝业公司和上海紫燕合金公司对高通量材料研发的支持;同时感谢科晶(MTI)集团的江晓平博士在共同研发高通量合金制备系统方面的帮助。
