基于LFM的图书推荐服务研究
2020-05-22
随着信息爆炸时代的来临以及网络上大数据的不断增长,用户越来越难以将那些真正有价值的信息从无数无用的信息中筛选出来,越来越难以找到自己真正所需要的真正信息。因此,便产生了“信息过载”的问题。图书领域也面临着相同的问题,各大高校图书馆的纸质资源和电子资源,都不断以指数形式增长,在数以万计的图书面前找到自己喜欢和合适的图书,对于读者变得越来越困难。目前绝大多数高校图书馆都提供了图书检索功能,但是只能根据读者输入的关键字做简单排序检索,不能提供深层次的推荐功能,其效率低下、方式单一,无法提高服务的主动性,更无法提高图书的利用率[1]。因此,个性化图书推荐系统应运而生,它可以快速推荐合适的图书给读者,提高图书馆主动服务的效率,增加读者与图书馆之间的黏性。
1 研究现状
高校图书馆是高校的枢纽和心脏,是传播知识和文化的中心,是广大师生学习和科研的阵地。传统的图书馆都是以纸质资源为基础,随着大数据时代的来临,现在的高校图书馆越来越重视数字化资源的建设,也在不断更新服务模式,变被动服务为主动服务。读者来图书馆阅读,往往通过检索机来查询自己所要寻找的相应图书,但是这种方式太过单一和局限。许多读者并不知道自己所需要和感兴趣的图书,在数以万计的图书面前,往往无所适从。因此,个性化图书推荐服务应运而生。对于个性化图书推荐的研究,国内外的学者大多选择基于协同过滤的推荐、基于聚类的推荐、基于关联规则的推荐、基于数据挖掘的推荐以及混合推荐等[2]。除此以外,也有其他一些技术被用于图书推荐服务中,例如,基于Spark 的高校图书馆书目推荐系统、高校智慧图书馆智能推荐系统、基于标签的高校图书馆个性化推荐系统等。
2 协同过滤技术
2.1 概述
协同过滤算法是根据其他用户对物品的评分,从而产生对目标用户的推荐列表[3]。该算法主要是从用户的已知数据中出发,寻找目标用户的相似用户,然后从这些相似用户中,预测出当前用户对目标项目可能的评分。协同过滤主要依据用户对物品的历史评分来产生预测,在协同过滤算法中,最重要的就是计算目标与周围邻居之间的距离,找到目标的相似邻居进行排序,在排序列表中产生推荐。所以,相似度计算的准确性直接关系着推荐系统的效果。协同过滤技术因其高效、操作性强和准确率高等优点,正逐步成为广受欢迎的一种推荐技术。协同过滤常用推荐算法包括:基于用户的协同过滤,基于项目的协同过滤,基于模型的协同过滤。基于用户的协同过滤是利用用户对于物品评分的数据,根据不同用户对相同物品的评分,计算用户之间的相似度,对有相同偏好的用户进行物品推荐;基于项目的协同过滤是通过用户对不同物品的评分,计算物品之间的相似度,根据用户的历史记录,推荐给用户之前喜欢物品的相似物品。一般来说,基于用户和项目的协同过滤在数据信息简单以及数据内容完整的情况下,能够较好地完成快速准确的推荐;如果出现数据信息复杂并且存在许多数据缺失的情况,则不能很好地应对。而基于模型的协同过滤能够更好地解决大数据量情况下的数据稀疏性问题。
2.2 基于模型的协同过滤
与基于用户和项目的推荐方法不同的是,基于模型的协同过滤是使用用户的历史评分数据来学习预测模型,通过机器学习方法先建立一个推荐模型,然后通过训练数据来对完成对未评分项目的计算预测,并将预测值的前几项推荐给用户。模型的建立可以通过离线模式完成,当用户上线时能够产生实时推荐,这样提高了系统的响应度并增加了与用户之间的黏合度。同时,在用户评分矩阵稀疏的情况下,使用基于模型的推荐方法可以很好的计算用户未评分项目,填充稀疏项,增加了预测的精度。常用模型包括:聚类模型、贝叶斯模型、隐语义模型、图模型等。下面重点介绍本文用到的隐语义模型。
3 隐语义模型
3.1 LFM 概述
隐语义模型[4](Latent Factor Model,LFM)是属于机器学习算法的一种,其中包含了隐藏因子,相当于神经网络的隐藏层。从数据的方向,用户与物品之间通过中间隐含因子进行联系,从而更好地挖掘出用户特征,解决用户物品特征向量中的稀疏性问题,推荐系统和文本分类里面会经常用到此模型。
3.2 LFM 原理
LFM 原理矩阵表示如图1 所示:
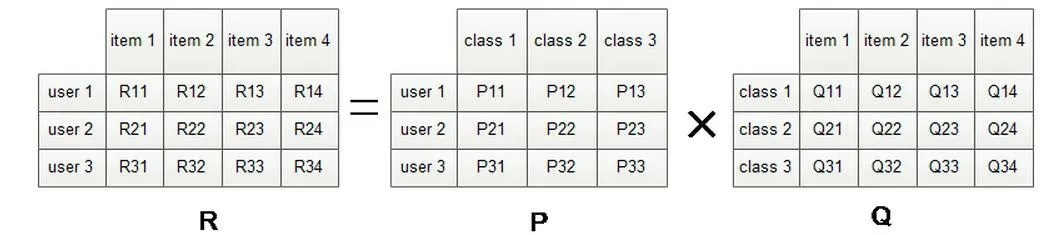
图1 LFM矩阵表示图
其中矩阵R 表示用户对物品的兴趣度,矩阵P表示用户对物品类别的偏好度,矩阵Q 表示物品属于哪个类别的概率。
隐语义模型就是通过将矩阵R 分解成P 和Q的乘积,通过P 矩阵物品类别将用户User 与物品Item 联系起来。从而得出用户对物品评分的公式:

其中公式(1)中,PU,K 和QK,I 是该模型的参数,Pu,k 代表用户U 的兴趣与第K 个隐含因子的关系,QK,I 表示第K 个隐含因子与物品I 之间的关系。
通过公式(2),采用最优化损失函数C 来求解P 和Q,得到最合适的P 和Q。

其中,λ||PU||2+λ||QI||2是用来防止过拟合的正则化项,λ 是需要根据模型算法训练数据反复实验得到。
4 图书推荐的实现
4.1 推荐方法
从图书馆借阅管理系统导出近一年的用户借阅历史记录,将数据进行预处理,用聚类方式先将同一专业的用户分在同一类里;然后对于每个类别,通过隐语义模型预测用户未评分图书的得分,将TOP-N 项推荐给用户。
4.2 建立模型
首先,建立用户对于图书的评分矩阵,其中,U={u1,u2,…,um}为用户向量,I={i1,i2,…,in}为图书向量,R 用来表示用户对图书的评分矩阵。利用公式(1)中的矩阵分解将矩阵R 分解为矩阵P 和Q,即R=P*Q。初始化用户对每个图书类别的偏好为矩阵P,每个图书所属图书类别为矩阵Q;将用户数据集进行训练,通过梯度下降算法,根据公式(2),不断更新矩阵P 和Q,以至损失函数达到最小,得出P 和Q,从而建立模型(LFM),用来预测矩阵R中的缺失值rui,即是用户对未评分图书的兴趣度。
4.3 推荐结果
随机抽取一名ID 为100 的用户,对没有评分过的图书通过建立好的模型进行兴趣度预测,选取兴趣度前5 位的图书推荐给该用户。结果如下:

图2
查询借阅历史,发现该用户看过机器学习的图书并且评分很高,故从推荐结果来看,兴趣度靠前的索书号都是跟机器学习和数据分析相关的图书。
5 结语
在如今信息不断增加和冗余的时代里,推荐系统已经成为如今信息时代人们获取关键信息的重要手段,可以帮助人们获取到真正感兴趣和有用的信息。本文采用协同过滤推荐技术的方法,提出了基于隐语义模型的推荐,选取了图书馆近一年的借阅历史记录,经过数据预处理,建立模型,通过计算预测用户对于图书的兴趣度来推荐给用户未评分过的图书,改善了用户评分的稀疏性问题,提高了推荐系统精度,方便用户更加快捷地找到合适的图书。
