Web Archive 工作收集策略中存在的问题及改进思考
2020-05-20崔鹏王曦波
崔鹏 王曦波


一、引言
在互联网上,每天都有无数新的信息的出现,同时也有无数旧的信息在消失。网络信息虽然增长速度飞快,其消失的速度也超出人们的想象。一些相关机构和学者的估计也能在某个程度上说明这个问题:据互联网档案馆(Internet Archive)估计,网页的平均寿命只有100天;亚马逊公司旗下的Alexa网站曾经估计,网页的平均寿命为75天;美国的NDIIPP项目人员则估计,网络信息的平均寿命只有44天。一些关于时事新闻的信息,其消失的速度更加惊人。表1是2018年1月中国互联网络信息中心发布的《第41次中国互联网统计报告》中对于我国网页更新情况的统计,从该表可以看出,超过3成的网页更新周期在三个月以内。
Web作为全球最大的信息资源库,其包含的信息对于对文化遗产保存、学术研究、社会经济的发展都具有十分重要的意义,但由于Web 信息的产生是自发的,而其消失又十分迅速,使网络信息资源既珍贵又脆弱。因此,对Web进行保存具有十分重要的意义,但是在我国,不论是与传统的信息资源保存相比,还是与国外的网络信息资源保存相比,Web Archive都没有引起足够的重视。
1996年,美国一个非营利性组织启动了Internet Archive项目,澳大利亚图书馆启动PANDORA项目;1997年,美国国会图书馆启动Minerva项目,丹麦、挪威、芬兰、冰岛和瑞典五个北欧国家的国家图书馆联合启动Nodic Web Archive项目;1999年,法国国家图书馆启动了BnF Web Archive项目,英国国家图书馆启动了UKWAC项目;日本、新加坡等国也在2005年以前启动了国家层面的Web Archive项目。
我国最早的Web Archive项目是2002年由北京大学启动的Informall项目;国家图书馆于2003年初启动了网络信息资源采集与保存试验项目(WICP),2009年国家图书馆互联网信息资源保存保护中心成立。中国人民大学也在2011年成立了“互联网数据信息海量存贮与智能服务中心”,其研究主要分为三个层面,第一个层面是互联网海量信息的组织、存储与管理技术,第二个层面是海量WEB数据的分析与挖掘,海量知识库管理等,第三个层面是面向社会科学用户的交互式分析决策平台。
國内对于Web Archive的研究,主要包括从宏观上介绍整个Web Archive工作的概念,从微观上介绍Web Archive工作的某一个环节,或者是介绍了国外的发展现状。在收集策略方面,国内的研究主要包括以下几个方面。第一,认为收集策略对于Web Archive工作具有基础性的重要作用。第二,不同的收集策略有不同优缺点。第三,收集策略必须要有科学的收集原则。
国外对于Web Archive的研究内容相对丰富,在很多方面对我国具有重要的借鉴作用。澳大利亚学者Edgar Crook认为,Web 2.0时代给Web Archive工作带来了新的技术上的挑战,图书馆必须学会适应并对未来做好计划,修改其收集的范围,并与其他保存机构进行合作,以保证这项重要工作的可持续发展。芬兰学者Juha Hakala主张对Web Archive工作收集的网络信息进行元数据标引,建立索引,以提供给终端用户使用。
Web Archive工作的责任体系、收集策略和资金支持三个方面是有机统一的,共同形成了Web Archive工作的运作机制,如图1所示。从图中可以看出,国家图书馆、各级图书馆和各级档案馆承担着网络信息资源长期保存的责任,在Web Archive工作中处于中心地位,是Web Archive工作的主力军。而长期保存的必要前提则是短期保存,短期保存的责任者主要包括网络信息资源的生产者和出版者。辅助保存是长期保存的重要补充,其责任者包括商业公司、各组织机构的网络技术部门和其他机构。而这些保存责任方都受到来自政府的统一规划和指导,政府处于Web Archive工作的领导者的地位,一方面为Web Archive工作提供必不可少的经费支持,另一方面也为Web Archive工作提供法律规范、政策支持和对公众的宣传教育等等。
网络信息资源的收集是Web Archive工作的第一步,也是十分重要的一步。在网络信息资源的收集过程中,可以采用多种收集策略。收集策略的不同,会直接影响到Web Archive信息的质量和价值,以及Web Archive工作的成本。按照不同的分类标准,收集策略的分类也不相同。按照信息的收集方式,网络信息资源的收集模型可以分为推送模型和拉取模型。按照信息的收集范围,网络信息资源的收集策略可以分为全面性收集策略和选择性收集策略。
二、Web Archive收集策略存在的问题
1.全面性收集策略存在的问题
(1)更新周期长,不能做到真正意义上的全面性收集
对于印刷型出版物来说,主要是那些连续出版物,比如期刊、报纸存在着连续收集的问题,由于连续出版物的更新周期比较固定,比如,期刊的更新周期可能是一个月、半个月等等,而报纸的更新周期一般是一天,因此收集周期就很容易确定。而网络信息的收集周期则很难确定。理论上讲,收集周期应该同网络信息的变化更新周期相一致,只要网络信息进行了更新,就应该对该次更新进行收集。但实际上,网络信息的更新变化规律十分复杂,难以找寻,有的六个月甚至更久都不更新一次,有的一两个月更新一次,更有的一星期甚至一天更新一次。对于全面性收集策略来说,由于收集的范围宽,对象多,一次收集所需的时间长,因此收集的周期一般设置得比较长。
世界上主要的Web Archive项目都以年作为网络信息资源的收集周期,每年对网络信息资源进行n次收集(n<=10)。比如,瑞典的网络信息资源保存项目Kulturarw3将其收集的更新周期设置为每年2次。在这个收集频率下,两次收集的间隔时间平均为6个月,这6个月时间内发生的信息更新和信息消失就无法收集到,而这6个月的信息更新和信息消失所产生的信息量是十分巨大的。可见,采用完整性收集策略,由于更新周期长,无法收集在两个更新时间点之间的信息更新和信息消失,而产生大量的信息遗漏,实际上不能做到真正意义上的全面性收集。
(2)只能收集静态信息资源,不能处理深层网络资源
靜态信息资源主要是指静态网页。静态网页是一种浅层网络资源,是纯粹的HTML格式的网页,它们是实实在在保存在服务器上的文件。静态网页的内容不会因为浏览时间或浏览者IP的变化而变化。也正是因为静态网页的这些特点,使得静态网页很容易被搜索引擎发现,从而大大提高了被Web Archive工作收集到的可能性。
尽管完整性收集工作能对静态信息资源进行有效的收集,但是由于技术上的原因,对于深层网络信息资源(数据库资源)的收集却显得力不从心,而更为遗憾的是,相对于静态信息资源来说,这些无法收集到的深层网络信息资源数量更大、质量更高、增长速度更快、重复率也更低。调查表明:深层网络信息资源的规模是浅层网络信息资源的500倍以上,而其质量是浅层网络信息资源质量的大约3倍。另外,深层网络信息资源的增长速度也明显高于浅层网络信息资源的增长速度。而就重复率而言,浅层网络中有很多镜像站点,提供的信息本来就不是一手的信息,另外很多网络信息被大量复制粘贴(如百度知道中有很多回答都是从别处复制粘贴过来的),造成重复率不断提高,而深层网络信息资源的重复现象则要少得多。
综上所述,完整性收集策略虽然能对浅层网络信息资源进行有效的收集,但是由于技术上的障碍,对于数量更大、质量更高、增长速度更快、重复率更低的深层网络信息资源无能为力。
(3)不能对收集的信息进行有效的质量控制
全面性收集是对一个广泛的范围内的站点(如以国家为范围)的信息进行收集,这个范围十分巨大。而我们都知道,网络上存在的信息污染大,噪音多,质量千差万别,参差不齐,有很多重复信息、虚假信息和垃圾信息,加上在收集过程中,收集的范围宽,收集的对象众多,较少地采取了人工干预,大多数是利用网络爬虫对网络信息资源进行自动收集,很容易造成收集质量的低劣。具体表现在,一方面,由于缺少了人工的干预,没有人对这些信息进行人为的信息主题的选择、重复信息的排除、虚假信息的鉴定、垃圾信息的识别等等,从而导致产生许多无关信息、重复信息、虚假信息和垃圾信息。另一方面,缺少了人工的干预,任由网络爬虫独自工作,使得许多的收集失败得不到及时发现,许多的收集错误得不到及时纠正,从而导致一些信息的遗漏,甚至有可能造成重要信息的缺失。
2.选择性收集策略存在的问题
(1)各个网络信息资源之间的割裂性强
我们现在网络中各个站点、各个地域的网络信息资源相互之间存在着千丝万缕的联系,通过错综复杂、无处不在的各种链接形成了一个整体。我们把与某一个站点相链接的所有网页形成的整体叫做“语境”。而通过选择性收集策略,把某些我们认为有价值的站点或主题的网络信息资源从这个完整的、相互联系的整体中抽离出来的时候,与这些信息资源链接的其他信息资源如果不符合收集的标准就会被舍弃掉,从而不可避免地割裂了这些网络信息资源之间原本存在的联系,使抽离出来的网络信息资源失去了原来的“语境”。而这种割裂性会给未来研究人员的研究带来很大的隐患,因为被割裂了的网络信息资源无法反映出当时整个网络信息资源的全貌,同时也有可能使未来的研究人员断章取义,在对某些信息理解不全而需要与之相链接的信息作为辅助理解的时候却找不到这些原来的链接了。
(2)选择标准主观性强
选择性收集策略是根据网络信息资源的价值的不同来判断是否应该对某个或某些站点的网络信息资源进行保存。而这些选择的标准具有很强的主观性,全凭收集人员(如图书馆员、档案工作人员)根据自身的知识结构和个人意愿来进行判断。一方面,用现在的标准来判断某一些信息在未来是否具有价值是一个很困难的工作,因为某些信息也许现在具有价值,但是在若干年后的将来也许一文不值,这样就会造成资源的浪费;而更坏的情况是,某些信息现在可能一文不值,却有可能在若干年后的将来有很重要的意义,这就不可避免地会导致一些重要信息的遗漏。另一方面,收集人员的知识结构的不同,个人意愿的不同都会在很大程度上影响选择标准的形成,有可能造成选择标准的混乱,甚至遭受后人的非议。就像劳埃德·索克文纳(Lloyd Sokvitne)曾经总结的那样:“我们不知道未来的人们需要哪些信息,我们现在的判断标准也不一定科学,尽管我们已经很尽力,但我们仍旧会失去许多有价值的信息”。
(3)人力、财力成本高
全面性收集策略虽然收集的范围广,但是因为绝大部分工作都交给了网络爬虫,所以人工成本很低,节省了大量的费用。而选择性收集策略则不然,从选择标准的确定,到收集站点的选择,到网络信息的编目,再到网络信息的质量审核,都需要人力的介入。特别是在网络信息的编目和质量审核阶段,面对的对象是数量巨大的网络信息资源,需要巨大的人力成本。而且,由于Web Archive工作对于人员的专业素质要求较高,需要对Web Archive工作的工作人员进行一定的培训,这也需要一笔不小的费用。如,澳大利亚国家图书馆的网络信息保存的单位成本多达178. 68澳元,其中94%为人力成本。
三、Web Archive收集策略的改进思考及其选择
1.根据不同的需要制定不同的收集级别
上文中指出,全面性收集策略容易遗漏一些重要的网页更新,而选择性收集策略又会割裂收集到的信息与其他信息之间的联系,使其丧失“语境”。针对这种状况,有必要根据不同的需要,制定不同的收集级别。
在这个方面,国外已经有数个网络信息保存项目做出了有益的尝试。比如,澳大利亚马尼亚州立图书馆实施的网络信息资源保存项目——“我们的数字岛屿”制定了比较详细的选择策略,该项目规定了四个级别,即完全级、选择级、代表性收集、快照。完全级对收集深度最深,不仅包括网站内部所有网页,还包括与之相链接的其他一级、二级、三级网页。这种收集级别有效地保证了收集的信息同与其相链接的信息的联系,为其保存了一个相对完整的“语境”。选择级对选定网站的关键更新进行收集,收集深度包括所有的内部网页和重要的外部一级网页和二级网页。这种收集级别既保证了不遗漏更新的网页,也照顾到了“语境”的完整性,是二者之间的一个折中选择。代表性收集对选定网站进行不定期的收集,或者对网站内的网页进行收集,收集深度为网站内的重要网页和外部网页。这种收集级别在收集频率和保持“语境”完整性上都降低了标准。快照只收集网站的某些网页,足够提供该网站的示例即可,是最低级别的收集。这四种收集级别灵活多变,可以在实际操作中根据需要适时调整。
制定了收集级别的Web Archive项目还有不少,如加拿大国家图书馆的Web Archive项目、伯克利数字图书馆的Web Archive项目等等。这些项目的收集级别的制定对于我国的Web Archive工作是很好的借鉴。
2.为选择性收集策略制定选择标准
结合众多项目的选择标准,笔者认为对于网络信息资源保存系统来说,制定收集标准时,应该主要考虑以下几个方面:
第一,网络信息内容方面的价值。网络信息资源的价值很大程度上体现在内容上,主要是从网络信息资源的原创性、权威性、可靠性几个方面进行考虑。
第二,网络信息媒体方面的价值。网络作为一种新的交流信息、传递信息的媒体,具有某种意义的文献价值。因此除了考虑内容方面的价值,还要考查某网络信息是否具备反映网络这一新型媒体的特征。对网络媒体发展中具有里程碑性质的网站应进行保存,比如说第一个博客,第一个进行电子商务的网站,第一个微博,等等,主要将网络作为一种媒体的价值进行记录和保存。
第三,网络信息凭证方面的价值。很多网络信息资源,特别是一些政府网站,还有一些机构网站内部网的资源,是机构行为的一种记录,具备档案的特点,可备查考之用。因此在制定选择标准时还要充分考虑哪些网络信息资源具备这种特质。
第四,保存机构自身的特性。对站点进行选择时,还要充分考虑保存机构的属性。比如说国家级的机构在制定标准时就应该侧重具备国家重要意义的网络信息资源,而地方机构(如地方图书馆)则应该侧重反映本地文化、经济等方面的网络信息资源的收集。再比如,档案机构就应该侧重网络信息的记录档案价值。
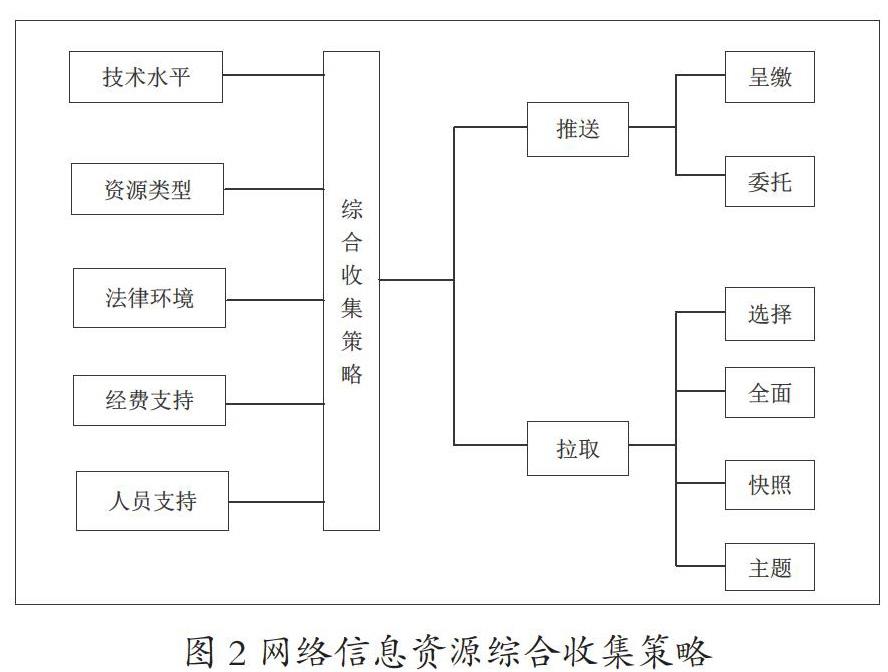
3.采用综合的策略
由于全面性收集策略和选择性收集策略都有其固有的问题和不足,不能很好地适应各种条件下的网络信息资源的收集,而我们也很难在短期内对这两种收集策略的问题和不足提出具有针对性的改进措施,因此,笔者认为应该根据网络信息资源自身的特点,保存机构所处的法律技术环境,保存机构自身的经费、人员支持情况综合采用两种收集策略,而不是采用单一的收集策略。笔者认为综合的收集策略就是对两种收集策略的有效改进,可以起到扬长避短、取长补短的作用,如图2所示。
比如,可以根据网络信息资源变化更新的不同频率采用不同的收集策略。上文已有提到,全面性收集策略由于收集的频率较低,容易遗漏在两次收集的间隔中更新的信息,而选择性收集策略因为收集频率要高很多,因此遗漏的信息会比较少。既然两种收集策略各有利弊,我们就应该将两种收集策略结合起来使用。有一些网站更新变化的频率很低,比如个人网站,基层政府网站等中小型网站,这些网站可能好几个月甚至一年都没有多少内容的更新。显然,针对这类网站,频繁地对其进行抓取只会造成人力物力资源的浪费,采用全面性收集策略中网络爬虫收集的方法就足够了。而有一些大型网站更新变化的频率则很高,比如新华网、人民网等网络报纸,腾讯新闻、新浪新闻、百度新闻等新闻网页,省级以上政府的门户网站等等,这些网站的更新频率大都为每天更新或几天更新一次。针对这些网站则更适合采用选择性收集策略,用较高频率的收集来保证不遗漏一些更新的重要信息。
另外,如果有呈繳法的支持,则以网络信息生产者呈缴为主,辅之以其他方法;如果著作权法没有赋予保存机构对网络信息资源保存的权力,则需要在选择的基础上和出版者协商;如果某些深层网络信息资源不能被自动收集,就需要出版者将信息发送到保存机构;如果收集的信息质量低劣,则需要适当对其质量进行控制。对于重要网站用选择性收集策略,对于一般网站用全面性收集策略。芬兰同时采用推送和拉取两种模式,对于公开的资源采取拉取模式,对于非公开的采用呈缴模式。澳大利亚国家图书馆的Web Archive项目采用选择性收集策略,但也委托互联网档案馆(Internet Archive)全面收集澳大利亚国内的网络信息。
