基于遗传算法优化BP神经网络的玉米遥感估产方法
2020-05-20于海洋陈圣波杨北萍安秦
于海洋,陈圣波,杨北萍,安秦
1.吉林大学 地球探测科学与技术学院,长春 130026;2.山西能源学院 地质测绘工程系, 山西 晋中 030600
0 引言
农作物产量的监测对于中国粮食政策的制定和农业种植决策方案的安排有着重要的作用[1]。遥感数据具有数据范围大、数据时相多的特点,能够反映农作物在整个生育期一定区域上的生长状况。目前应用广泛的估产模型主要是经验回归模型,通常选择与农作物生长关系密切的植被指数建模[2]。玉米单产可以通过归一化差值植被指数(normalized difference vegetation index, NDVI)进行模拟[3--4],也可以构建比值植被指数(ratio vegetation index, RVI)和叶面积指数(leaf area index, LAI)与产量之间的关系模型[5]。通过时间序列NDVI与作物产量建立回归模型,可以预测江苏省的水稻产量[6],将多种植被指数进行组合成功建立了河北省冬小麦的估产模型[7]。经验回归模型是一种线性模型,而人工神经网络是一种非线性模型[8],具有通过学习逼近任意非线性映射的能力,可以使产量的预测减少所需要的同时期的采样数量,使得产量估算过程更加高效并减少人力物力资源的消耗。
BP神经网络是一种流行的机器学习模型,通过训练给出最接近期望输出值的结果[9],利用BP神经网络结合遥感数据进行产量估算的研究相对较少。遗传算法可以优化BP神经网络的权重和阈值,改善BP神经网络在学习过程中遇到的陷入局部最小值的问题。以BP神经网络可以建立山东省禹城市的冬小麦产量的估算模型[10],平均相对误差为13.1%。以BP神经网络建立吴桥实验站的冬小麦估产模型[11],最大相对误差为3.42%。对于BP神经网络的应用比较广泛,但是对于利用植被指数进行大面积的产量估算研究较少,因此采用遥感数据可以提高估产效率,应用于较大面积。本文利用高分一号全色多光谱影像提取的内蒙古开鲁县4种植被指数为训练数据,通过遗传算法优化BP神经网络,得到预测玉米产量,以期使该地区的估产更加准确、高效、宏观。
1 研究区概况与数据
1.1 研究区概况
开鲁县位于内蒙古自治区东部,通辽市西部,属于大陆性温带半干旱季风气候,年平均气温5.9℃,平均降雨量338.3 mm。开鲁县种植的主要农作物为玉米,研究区玉米普遍在5月下旬播种,9月进入收获期。
1.2 数据及预处理
1.2.1 遥感数据
高分一号卫星是中国于2013年发射的高分辨率对地观测卫星,其搭载了两台2 m分辨率全色/8 m分辨率多光谱相机,重访周期为4 d;以及4台16 m分辨率多光谱相机,重访周期为2 d。采用高分一号卫星16 m分辨率的数据,数据来源于中国资源卫星应用中心(http://www.cresda.com/CN/)。在选取影像时,为使植被指数的运算更加准确并且覆盖整个研究区,选择2018年8月2日一幅影像和2018年9月12日两幅影像。
1.2.2 产量数据
本文产量数据均来源于实地采样。2018年9月至10月,在开鲁县实地采样46个点。根据实地采样点采集的玉米棒,经过脱粒、烘干、测水和称重等一系列操作,计算出采样点处玉米产量值,单位为斤/亩。产量采样点位于开鲁县12个镇,开鲁县地理位置及采样点分布如图1所示。
2 研究方法
2.1 植被指数提取
监测作物长势的有效方法是利用多光谱数据的多个通道反射率值得到植被指数。绿色植被的叶绿素a和叶绿素b对于各个波段的光谱吸收不同,因为植被指数可以反映植被的生长状况,典型的植被指数有4种。归一化差值植被指数NDVI表示为植被近红外波段发射率与红波段反射率的差值与两者加和的比值,对于模拟地表作物的生长状态有着重要作用。计算公式如下:
NDVI=(ρNIR-ρR/(ρNIR+ρR)
(1)
式中:ρNIR、ρR分别为近红波段和红光波段反射率。
比值植被指数RVI(red vegetation index)表示为植被近红外波段反射率与红波段反射率的比值,与植物叶绿素含量相关性较高。计算公式如下:
RVI=ρNIR/ρR
(2)
增强植被指数EVI(enhanced vegetation index)具有较强的识别作物的能力,计算公式如下:
EVI=2.5×(ρNIR-ρR)/(ρNIR+6.0×ρR-7.5×ρB+1)
(3)
式中:ρNIR、ρR、ρB分别为近红、红和蓝波段反射率。EVI可以矫正土壤背景对植被反射率的影响。

图1 开鲁县地理位置与采样点分布图Fig.1 Position of Kailu County and distribution of samples
另外,将近红波段与绿波段反射率比值定为植被指数G(green),计算公式如下:
G=ρNIR/ρG
(4)
式中:ρNIR、ρG分别为近红和绿波段反射率,反映植物的绿色程度。
NDVI、RVI、EVI和G为4种指数增强植被光谱信息并反映植被生长状况,故选择4种指数作为玉米产量模拟的训练数据。
2.2 遗传算法优化BP神经网络
BP(back propagation)神经网络是一种反向误差传播的神经网络[12],一般分为3层,即输入层、隐藏层和输出层,BP神经网络的结构示意如图2所示。
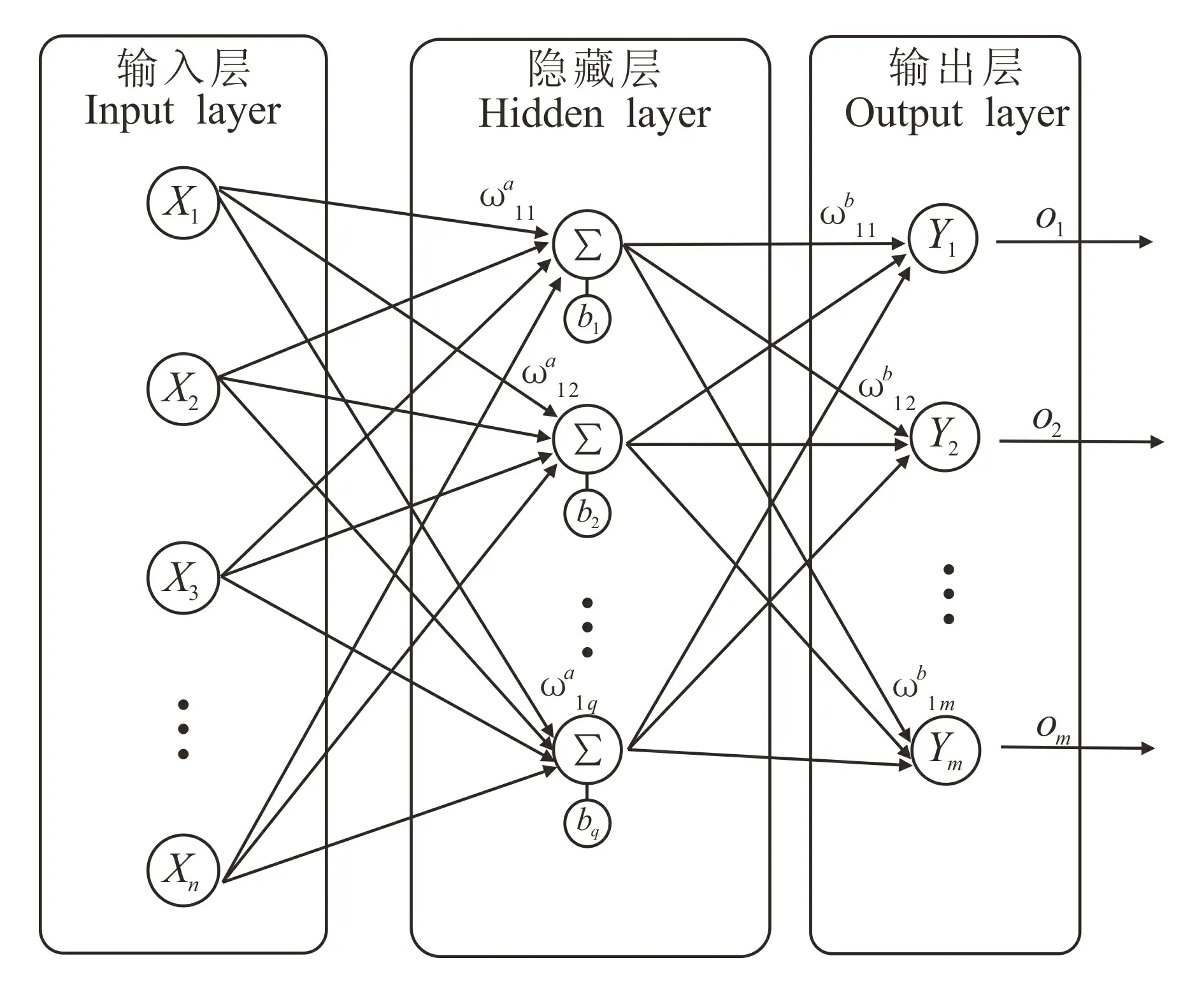
图2 BP神经网络结构示意图Fig.2 Schematic diagram of BP neural network structure
由图2可知,Xi(i=1,2,…,n)为输入层元素;Yj(j=1,2,…,m)为输出层元素;ω、b分别为输入层与隐藏层、隐藏层与输出层之间的权重和阈值;Oj(j=1,2,…,m)为输出层的期望输出值。
遗传算法(genetic algorithm,GA)来源于“优胜劣汰、适者生存”理论,是一种通过模拟自然界当中生物的遗传和进化过程,求解全局优化概率最佳解的算法[12]。其中,适应度函数是确定所求解是否为最佳解的依据,也是遗传算法的核心部分。初始化后种群中的个体,经过交叉、变异操作,对其进行筛选,最终得到满足条件的新个体。新的个体相比于原始个体,更加接近于期望输出。经历反复的循环和筛选,得到满足条件的新种群,即输出值。
由于传统的BP神经网络,其初始的权重和阈值是几组0到1之间的随机数,网络达到收敛需要较多的迭代次数,而遗传算法可以通过全局的解算得到最佳解,因而采用遗传算法将BP网络的初始权重和阈值进行优化,可提高BP神经网络的运算速度并减少训练网络所需时间。将遗传算法运用到BP神经网络的技术路线如图3所示。

图3 遗传算法优化BP神经网络Fig.3 Genetic algorithm optimized BP neural network
由图3可知,遗传算法首先对初始输入数据进行编码,以BP神经网络训练的误差作为适应度函数,适应度函数F的表达式如公式(5)所示。
(5)
式中:yj是网络第j个节点的期望输出;Oj是网络第j个节点的预测输出;n为节点的个数;k是调节系数。将完成上述操作的个体进行适应度值判断,满足条件的个体作为BP神经网络的优化权重和优化阈值。BP神经网络的误差值计算公式如(6)所示。
(6)
式中:yj是节点j的输出值;Oj是节点j的期望输出值,二者差值平方和的一半为整个网络的误差E(ω,b)。当网络达到设定的循环次数或达到精度时,停止训练并生成输出结果。利用sim函数对结果进行仿真,得到最终的输出数据,即采样点的产量值。
3 结果分析与精度验证
3.1 模型结果
本文构建BP神经网络(BP)和遗传算法优化BP神经网络(GA--BP)两种估产模型。BP神经网络设置输入层、隐藏层和输出层节点数分别为8个、9个、1个。选择tansig函数作为隐藏层训练函数,purelin函数作为输出层训练函数,训练精度0.000 1,网络学习速率设为0.1,同时设置训练最大循环次数为2 000,利用sim函数对结果进行仿真。4种植被指数作为输入,实测产量作为期望输出。选取41个点为训练点,5个点为验证点。BP神经网络结果与GA--BP神经网络结果如图4所示。
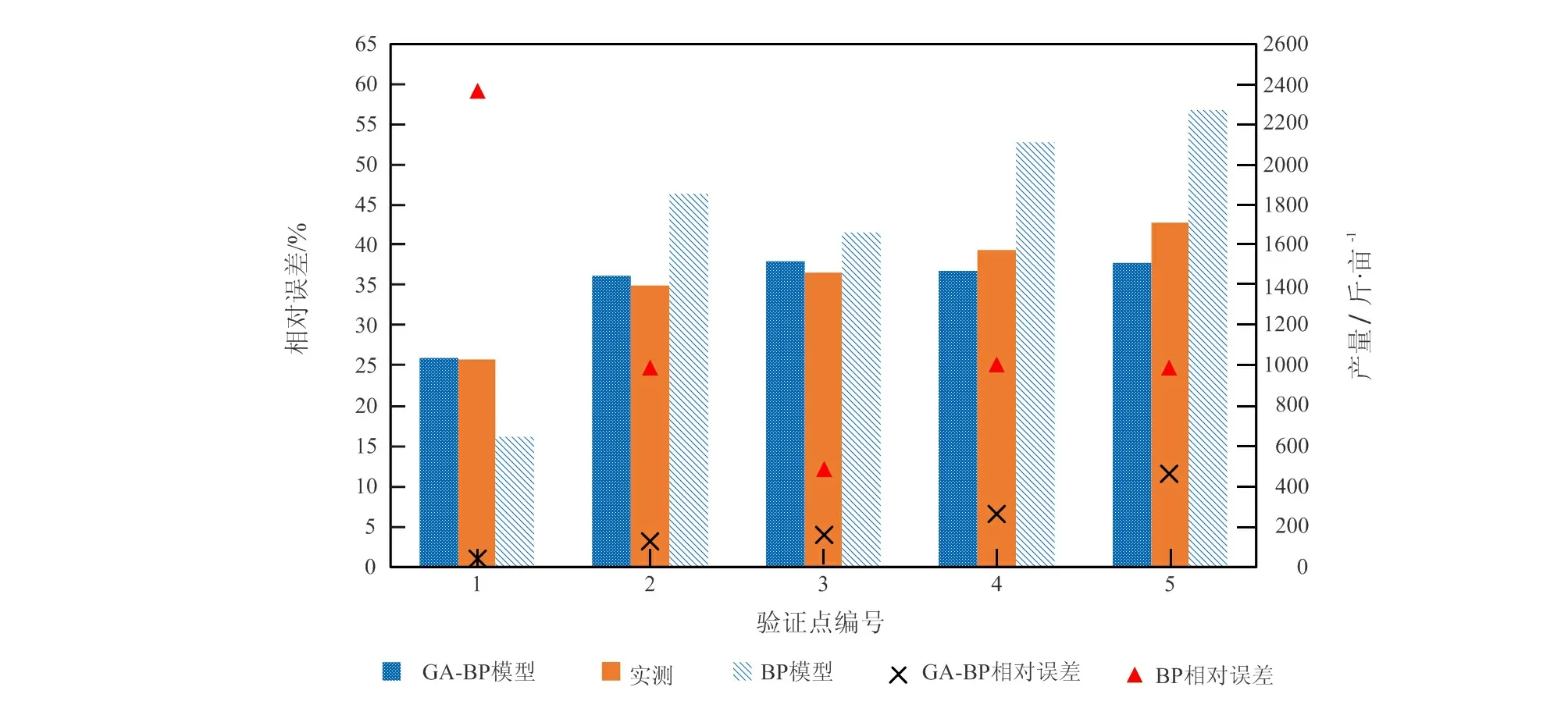
图4 GA--BP和BP神经网络结果Fig.4 GA--BP and BP neural network results

图5 开鲁县预测产量分布图Fig.5 Forecasted yield map of Kailu County
由图4可知,GA--BP模型对于相对低产(800斤/亩±)和相对高产(1 200斤/亩)的模拟效果都比BP模型效果好。对比BP模型与GA--BP模型之间验证点相对误差,BP模型的最大相对误差为-59.16%,最小相对误差为12.20%,平均相对误差为29.23%。GA--BP模型的最大相对误差为11.59%,最小相对误差为-0.86%,平均相对误差为5.27%。BP模型对于低产量的模拟结果与实际值之差较大,GA--BP模型对于高产量和低产量的模拟情况误差较小。
将生成的神经网络保存,利用开鲁地区全部玉米地4种植被指数影像作为输入,生成开鲁县2018年玉米预测产量分布图(图5)。
由图5可知,开鲁2018年预测产量最大值为1 986.12斤/亩,预测产量最小值为812.27斤/亩。利用神经网络可以生成区域性的产量图(图5),可以看出,开鲁县东南部产量集中在1 500斤/亩以下,高产地区集中在开鲁县中部。
3.2 精度验证
相关系数(R2)和均方根误差(RMSE)是用来判断模型结果的参数,R2的计算公式如下:
(7)

均方根误差RMSE是将误差平方和做平均,再开平方,是表示样本离散程度的数值,计算公式如下:
(8)
BP神经网络模型和GA--BP神经网络模型的R2值与RMSE值如表1所示:

表1 BP模型与GA--BP模型的R2与RMSE
由表1可知,利用BP神经网络构建的玉米估产模型R2达到0.845 2,具有较好的产量估算能力,RMSE(%)为28.37,表明模型的预测值与真实值之间存在差异。利用遗传算法优化BP神经网络构建的玉米估产模型R2达到0.985 0,RMSE(%)为6.70,表明模型的预测能力较强,且预测值与真实值之间的差值很小,起到了良好的产量估算作用,并且对于较大产量和较小产量的模拟均具有较强的学习能力。
4 结论
(1)相对于BP神经网络,经过遗传算法优化后的BP神经网络(GA--BP)对于研究区内玉米产量的估算具有更高的精度和更好的效果,表明GA--BP神经网络对于数值的预测因其结构的更加复杂而具有更好的预测效果。估产相对误差由BP神经网络的最大59.16%,缩小到GA--BP神经网络的最大11.59%;RMSE(%)由BP神经网络的28.37,缩小到GA--BP神经网络的6.70。
(2)利用训练后的GA--BP神经网络,生成了开鲁地区2018年玉米产量分布图,准确反应了开鲁县玉米相对高产与低产分布情况,为大范围的估产提供了方法。
(3)玉米产量由多种因素决定,本文仅选取乳熟期和成熟期的植被指数建立产量之间的联系,没有加入诸如温度、降水和土壤条件等因素对于玉米产量的影响因子,对于多种因素的联合作用没有深入研究。这也成为建立更准确、高效、宏观的遥感估产模型要思考的重点问题。
