基于动态策略的多源迁移学习数据流分类研究
2020-05-18刘三民
周 胜,刘三民
(安徽工程大学 计算机与信息学院,安徽 芜湖 241000)
0 概述
随着大数据技术的不断发展,数据流挖掘在天气预报、金融预测、电子商务等领域得到广泛应用。传统的数据流分类方法需要大量的标签样本来训练分类模型,而获取大量标签样本费时费力,且这类方法无法有效解决数据流中的概念漂移和噪声问题。
目前,将多源迁移学习[1-2]与集成学习[3-4]相结合并应用于数据流分类的研究得到广泛关注,该类方法通过将训练得到的多个源领域分类器进行集成来对目标领域新到样本进行分类,能够解决源领域和目标领域相似度较低以及目标领域标注样本不足的问题[5-7]。根据多源领域分类器的不同集成方式,可以将多源领域分类器集成分为多源领域分类器直接集成和多源领域分类器选择集成两类。
多源领域分类器直接集成的方法将所有源领域分类器进行集成。文献[8]建立一种多源迁移学习算法OMS-TL,该算法根据二部图实现对目标领域样本的预测,通过对数据样本进行重用来实现迁移学习。文献[9]设计OTLMS算法,该算法将源领域分类器和目标领域分类器进行组合以构建预测分类器,解决了与目标学习任务无关的噪声源数据影响分类精度的问题。文献[10]通过将目标特征空间分成源域的同构和异构2个部分,将基分类器进行加权组合获得多个源领域分类器,并将它们组合成一个集成模型来解决多源异构迁移学习问题。但是,每个源领域都可能不包含目标域的完整类别信息,当多个源领域之间存在较大差异时,将所有源领域分类器进行集成会导致分类性能降低。
针对多源领域分类器直接集成方法的不足,众多国内外学者提出使用多源领域分类器选择集成的方法来解决数据流分类问题。文献[11]基于局部分类精度提出一种多源迁移学习算法LC-MSOTL,该算法将局部分类精度最高的源领域分类器和目标领域分类器进行加权集成,实验结果显示,该方法具有较高的准确率。针对概念漂移数据流分类中的概念重现问题,文献[12]提出一种重现概念漂移数据流分类算法RC-OTL,其根据领域相似度挑选最合适的源领域分类器,实验结果表明,RC-OTL算法能够有效克服“负迁移”问题。文献[13]构建一种多源迭代自适应算法MSIDA,该算法根据贪婪思想实现最佳源域的选择,同时通过创建额外的伪标记实例来解决样本标注问题。文献[14]通过求解每个源领域对应的权值向量,并用该权值向量表示源领域和目标领域之间的相似度,从而显著地提高了迁移学习的效率以及分类性能。文献[15]提出一种OHTWC算法,其通过计算异构域中同现数据的异构相似性,解决了异构域上的数据流分类问题。文献[16]通过调整每个源领域分类器对应的权重,同时用目标领域分类器更换权重最大的源领域分类器,在出现概念漂移后快速恢复集成分类器的分类准确率,最终使集成分类器的分类性能得到改善。
在数据流分类任务中,多源领域分类器选择集成技术具有明显优势,但在多源迁移学习过程中,从多个源领域分类器中如何挑选最合适的分类器进行迁移集成是急需解决的问题。本文提出一种基于样本确定性的动态分类器选择方法,以高效选择最合适的源领域分类器并解决数据流中的概念漂移和噪声问题。
1 基本概念
为便于分析和理解,对本文涉及的基本概念进行定义:
定义1数据流指按时间顺序依次到达的n个样本的集合,即:
S={(xt,yt)|t=1,2,…,n},(xt,yt)∈X×Y,X∈Rm,Y={-1,+1}
其中,X表示m维的特征空间,Y指样本类别。
定义2概念漂移指数据样本产生的联合概率分布函数随时间的推进发生无法预知的变化,即:
pt(x,y)≠pt+1(x,y)
其中,x表示样本特征信息,y表示样本所属类别。
定义3信息熵用来衡量某随机事件发生的不确定性,其计算如下:
(1)
其中,X为随机变量,k为随机变量X所有可能发生的事件数目,pi为对应事件发生的概率。
对信息熵计算公式分析可知,当概率为1时,信息熵最小为0,相当于确定性事件。对于只有2种事件的随机变量,当概率为0.5时,信息熵取得最大值,表明无法对当前事件进行有意义的判断。随机事件的信息熵与概率之间的关系如图1所示。
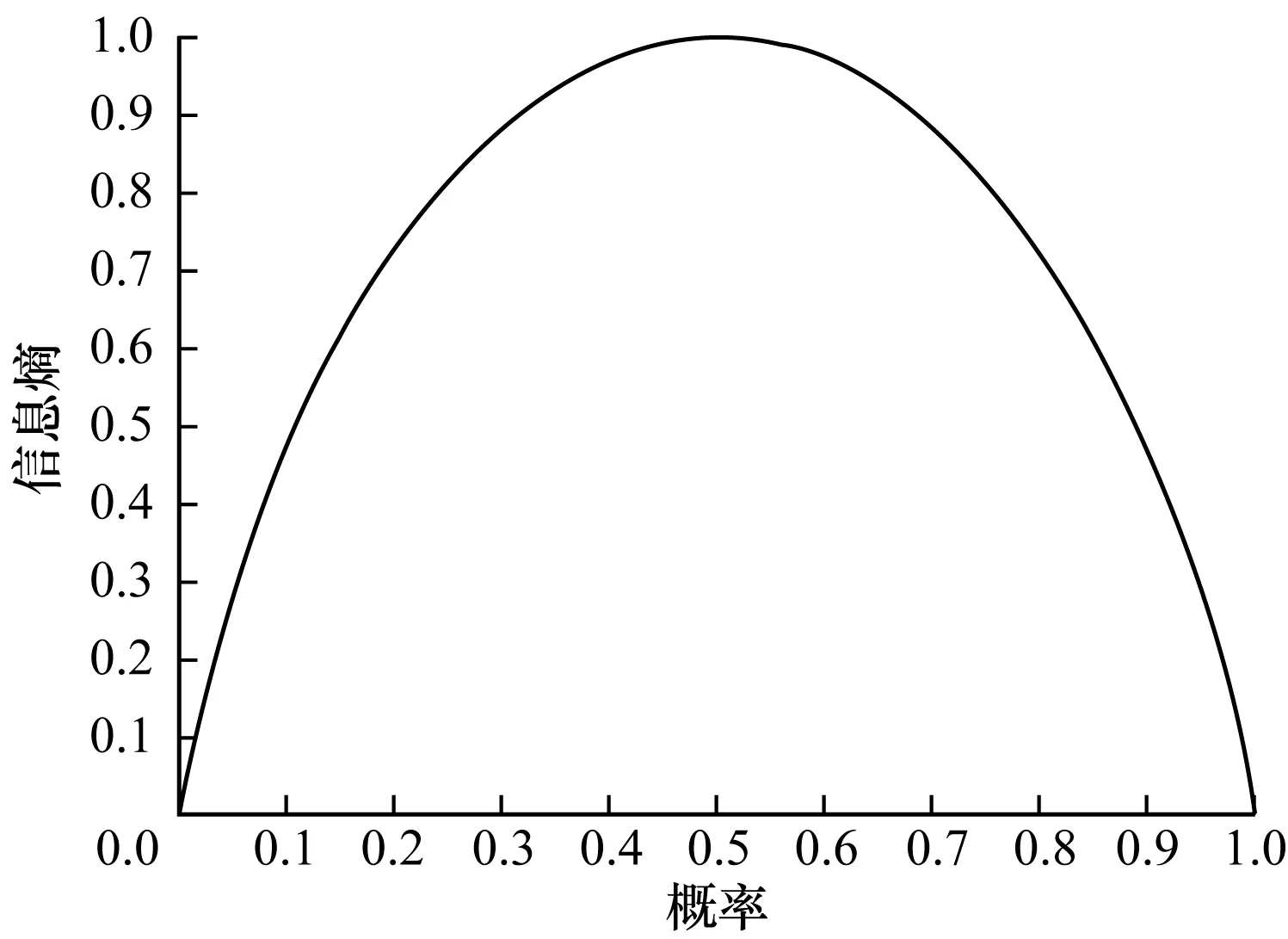
图1 信息熵与概率之间的关系
定义4样本确定性指分类器对待分类样本x预测结果的确定性程度。本文讨论的是二分类问题,结合信息熵的定义可得样本确定性计算公式如下:
(2)
其中,pi为样本x对应的类别后验概率。
通过样本确定性进行数据流分类,可以有效避免不确定分类器对噪声数据流带来的不利影响,同时提高分类准确率。
2 弃权分类器
针对概念漂移数据流分类问题,文献[17-19]提出基于弃权分类器的数据流分类方法,以挑选最合适的基分类器。弃权是指未能达到特定规则要求的基分类器不参与决策,当发生概念漂移时,该方法通过允许基分类器对新实例丢失信心时放弃预测,同时允许选择的基分类器参与决策,从而探索集成的多样性,弃权分类器的结构如图2所示。首先计算多个基分类器对新到样本的确定性值,然后强制未能达到阈值限制的基分类器放弃预测,最后采用多数投票的方法对新到样本进行集成决策。该方法强制不确定分类器(未能达到特定规则要求的分类器)不进行预测,即不确定分类器可以放弃参与最终决策,并将所选择的基分类器的输出结果作为分类器集合的输出。
弃权分类器的优点在于能够挑选出达到特定规则要求的分类器,更快适应概念漂移现象,有利于消除噪声数据的影响。本文基于弃权分类器,将多个源领域分类器对目标领域数据块中每个样本的确定性值与给定的阈值进行比较,对于未能达到阈值限制的源领域分类器,强制其不参与投票。若所选择的源领域分类器集合能够正确地预测标签,则意味着已经选择了有能力的源领域分类器,可以通过降低阈值来探索其他类似能力的源领域分类器。如果所选择的源领域分类器集合做出不正确的决定,则表示可能发生了概念漂移现象,在这种情况下,需要增加阈值来排除不太合格的源领域分类器,以挑选出最适合当前流状态的源领域分类器。
3 算法描述
在样本确定性和弃权分类器的基础上,本文提出一种基于动态策略的多源迁移学习算法DSMTL。该算法求得源领域分类器对目标领域数据块中每个样本的类别后验概率,然后根据样本确定性计算方法求得各源领域分类器对目标领域数据块中每个样本的确定性值,最后将样本确定性值满足当前阈值限制的源领域分类器与目标领域分类器进行在线集成,以对目标领域数据块进行分类,其中,使用多数投票的方式进行有关预测标签的最终决策,并根据集成决策的正确性修改阈值。DSMTL算法的详细描述如下:
算法1DSMTL算法
输入目标域数据流DS,源领域分类器集合CS,弃权阈值θ,调整因子S
输出集成分类模型对目标领域数据块的分类准确率
1.参数初始化θ、S,缓存10个规模大小相等的数据块,并分别在数据块上训练源领域分类器
2.For j=1,2,…,对后续数据块Dj依次循环处理
3.基于目标领域数据块Dj构建目标领域分类器ftj
4.计算各源领域分类器对目标领域数据块中每个样本x的类别后验概率pi
5.计算各源领域分类器对目标领域数据块中每个样本x的样本确定性值sc:
6.将样本确定性值满足阈值限制的源领域分类器fs与目标领域分类器ftj进行在线集成,以对目标领域数据块Dj进行分类
7.根据集成决策的正确性修改弃权阈值θ,如果集成分类器对目标领域数据块Dj的分类准确率大于弃权阈值θ,则:
θ=θ·(1-S)
否则:
θ=θ·(1+S)
8.End For
在算法1中,步骤1表示初始化,步骤3表示基于目标领域数据块构建目标领域分类器,步骤4~步骤5表示求各源领域分类器对目标领域数据块中每个样本的确定性值,步骤6表示选取样本确定性值满足阈值限制的源领域分类器,并与目标领域分类器在线集成以对目标领域数据块进行分类,步骤7表示弃权阈值修改。
4 实验结果与分析
4.1 实验数据集
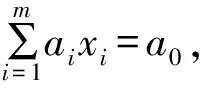
4.2 结果分析
本文将所提方法与基于准确率选择集成的多源迁移学习方法ASIMTL[4]进行对比。实验采用Bayes分类器作为基分类器,通过批处理模式生成数据块以及训练基分类器,其中,源领域数据块大小为2 000,源领域数据块个数为10,训练10个源领域分类器,同时基于目标域数据流形成20个数据块,数据块大小设为500,求得各源领域分类器对目标领域数据块中每个样本的确定性值,将样本确定性值满足阈值限制的源领域分类器与目标领域分类器进行在线集成,从而对目标领域数据块进行分类。
实验1验证弃权阈值参数的影响。为验证弃权阈值对算法的影响,本文选择3个不同的阈值,将平均准确率和标准差统计量作为评价指标,固定调整因子的值为0.01,实验结果如表1所示。
表1 弃权阈值对DSMTL算法性能的影响
Table 1 Effect of waiver threshold on performance of DSMTL algorithm
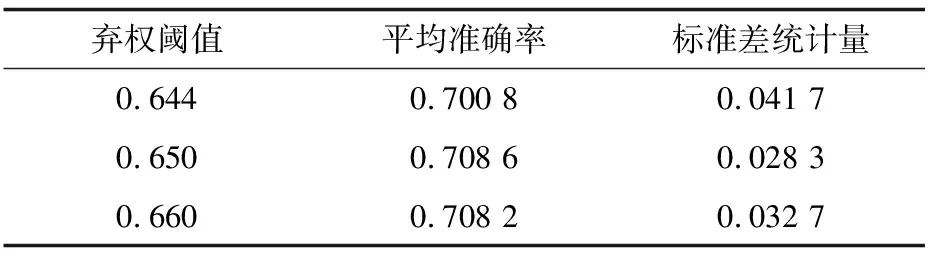
弃权阈值平均准确率标准差统计量0.6440.70080.04170.6500.70860.02830.6600.70820.0327
从表1可以看出,当弃权阈值为0.650时,算法平均准确率和标准差统计量较优。当弃权阈值较大时,每次迭代选择的源领域投票分类器数量不够,而阈值较小时选择的源领域投票分类器可能并不适合当前流状态,弃权阈值较大或较小都会导致无法挑选出最合适的源领域分类器,从而影响算法的分类性能。
实验2验证DSMTL算法的分类性能。图3所示为DSMTL和ASIMTL 2种算法在数据集D1上采用先测试后训练策略所得的分类准确率情况。从图3可以看出,在无噪声的情况下,相对于ASIMTL算法,DSMTL算法的分类准确率有明显提高,其能够及时发现概念漂移并且挑选出最合适的源领域分类器以处理新出现的概念,如在数据块2和数据块5之间出现了分类准确率持续下降的情况,数据块12和数据块14之间出现了曲线低峰,但算法能够快速地恢复其识别准确率,说明DSMTL算法能够很好地适应概念漂移情况,即通过样本确定性值选择源领域分类器的策略能够有效改善迁移效果。
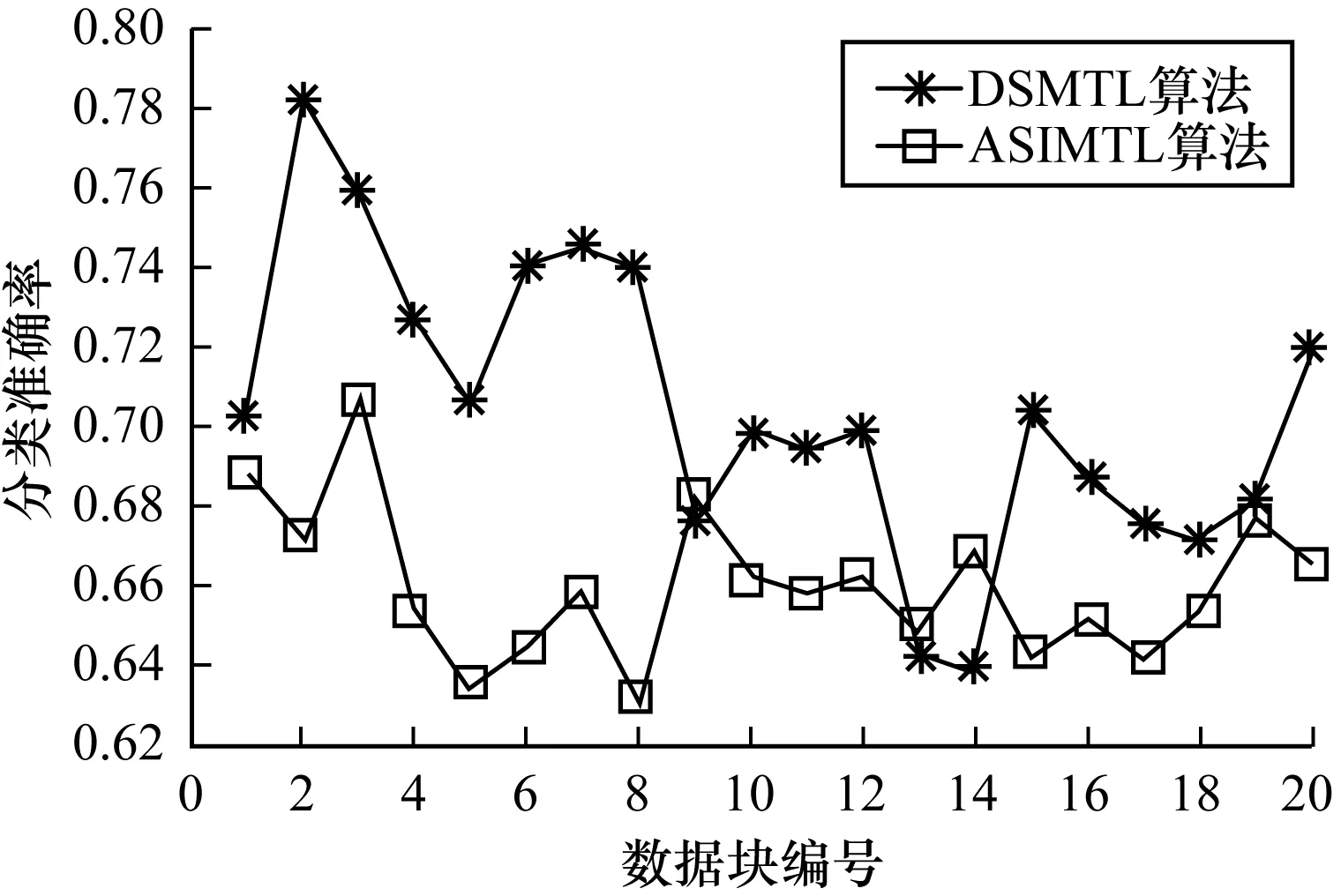
图3 数据集D1上的实验结果
图4、图5是噪声环境下2个数据集中的实验结果,从图4、图5可以看出,在有噪声的情况下,DSMTL算法仍然具有较高的分类准确率,优于ASIMTL算法,说明其具备一定的抗噪性能,这是由于DSMTL算法使用了信息熵求样本确定性值,其消除了噪声数据的影响。但随着噪声数据的增加,DSMTL算法分类准确率出现较大波动,这是由于噪声样本被误认为是概念漂移样本用以构建目标领域分类器,导致集成分类器对新概念无法收敛。
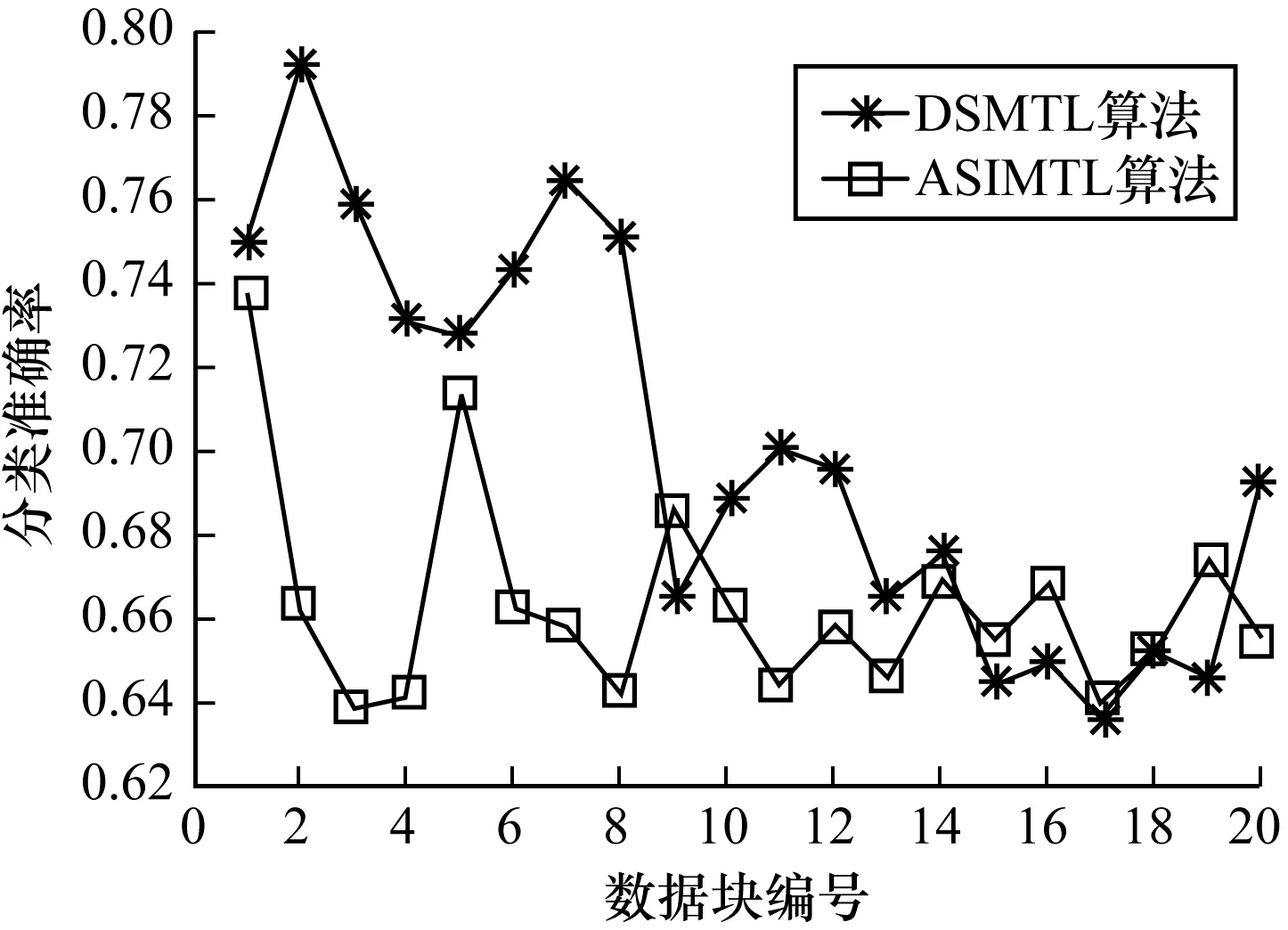
图4 数据集D2上的实验结果
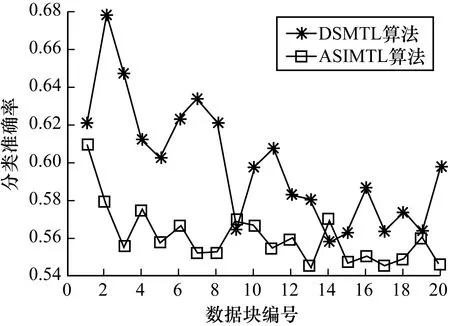
图5 数据集D3上的实验结果
综上可知,DSMTL数据流分类算法可行,分类准确率优于ASIMTL算法,原因是DSMTL算法将求得的各源领域分类器对目标领域数据块中每个样本的确定性值与一个给定的阈值进行比较,只选择满足当前阈值限制的源领域投票分类器,即强制不确定的分类器不参与投票,目的是为投票步骤选择最不可能受噪声数据影响的源领域分类器。因此,该算法能够通过设置弃权阈值的方式挑选出最合适的源领域分类器,且其策略可以消除噪声数据的影响,更快地适应概念漂移现象,使分类模型面对概念漂移问题时具有更好的泛化能力。
从表2可以看出,DSMTL算法性能明显优于ASIMTL算法,平均准确率约高出5个百分点,在噪声环境下仍然具有较高的准确率,说明DSMTL算法能够有效地处理数据流中的噪声,更快地适应概念漂移现象。当数据集由不含噪声的数据变为含有噪声的数据时,DSMTL算法的分类准确率下降程度小于ASIMTL算法,说明DSMTL算法面对噪声数据流时具有更好的稳定性和更强的抗噪性。原因是DSMTL算法利用信息熵求得各源领域分类器对目标领域数据块中每个样本的确定性值,有效消除了噪声数据的影响,使分类模型保持较高的分类精度以及较好的稳定性。
表2 2种算法平均准确率和标准差统计量对比
Table 2 Comparison of average accuracy and standard deviation statistics of two algorithms
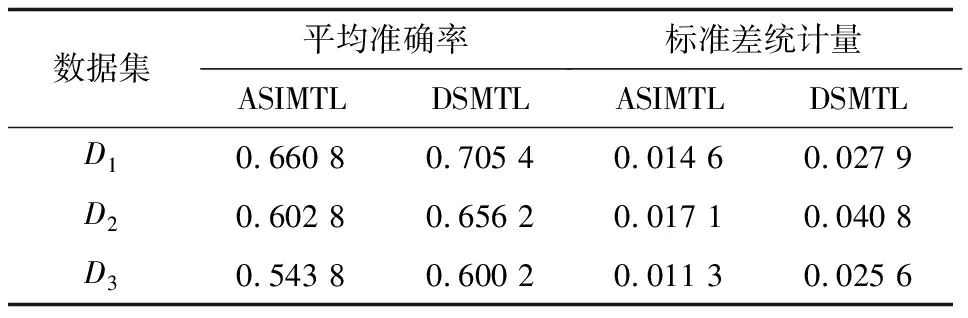
数据集平均准确率标准差统计量ASIMTLDSMTLASIMTLDSMTLD10.66080.70540.01460.0279D20.60280.65620.01710.0408D30.54380.60020.01130.0256
5 结束语
本文结合弃权分类器和样本确定性计算方法,提出一种多源迁移数据流分类学习算法DSMTL。该算法能够有效利用弃权分类器思想强制不确定分类器不进行预测,同时计算样本确定性值以从源领域分类器集合中挑选最合适的分类器,并与目标领域分类器进行在线集成。实验结果表明,DSMTL算法能够对集成的多样性进行选择性控制,消除噪声数据的影响,并解决数据流中概念变化和样本标注问题。下一步将对源领域与目标领域数据的共有特征进行识别,根据新到达样本对分类模型进行更准确的权重设置,并探究对源领域和目标领域之间的区分性进行建模的方法。
