烟叶霉变的快速识别
——基于近红外光谱与随机森林算法
2020-05-18赖燕华林云陶红王予
赖燕华,林云,陶红,王予
广东中烟工业有限责任公司技术中心,广州市荔湾区东沙环翠南路88号 510385
烟叶作为一种特殊的叶用植物,烟草仓储是极为重要的一个环节。田间生长的烟叶经过采收、烘烤、收购、运输、打叶复烤、醇化等环节,才能进入卷烟工厂制丝车间,卷制成卷烟。从烟叶采收到卷烟,至少需要1到2年时间。霉菌是自然界中分布最为广泛的真菌类微生物,只要碰到适宜它生长繁殖的温湿度条件,就会快速生长繁殖,造成烟叶霉变,导致烟叶的腐坏变质。因此,烟草防霉变的研究具有重要的经济价值和应用意义。导致烟草霉变的因素有很多,其中主要的影响因素是其存储环境的温度、湿度以及烟草的自身含水量[1-2]。但是由于在不同的地域、不同的烟草种类、所含菌类别及数量的不同等等,上述因素造就了烟草霉变过程的非线性和不确定性。目前,对烟草霉变监测的研究主要集中在霉菌种类的鉴定、霉菌毒素的检测以及通过几丁质、麦角甾醇的测定来评估霉菌生物量[3,4],对烟叶霉变的早期预测还缺少系统研究。
近红外光谱技术是近些年来发展较快的分析方法之一,它依据化学成分对近红外光谱的吸收特性而进行测定。近红外光谱分析技术无需复杂的样品前处理,具有快速、简便、高准确率、成本低、可用于无损检测等优点,已被国内外学者广泛应用于各种农产品品质的监测研究[5-9]。烟草行业在应用近红外光谱技术定性检测烟草霉变方面也取得了一些经验。周继月等[10]基于烟叶麦角甾醇含量变化,采用近红外光谱分析结合化学计量学方法建立了烟叶霉变过程的模式识别模型,该研究针对单个烟叶样品采用过程模式识别监测初烤烟叶霉变过程中麦角甾醇含量变化,能较好排除烟叶地区、部位和等级差异对模型的影响,但也正因为如此,模型的转移和应用势必存在局限性,对于不同产地、部位和等级的烟叶霉变预警,需要重新建立模型。杨蕾[11]运用近红外光谱仪在780 nm~2500 nm范围内对烟叶的近红外光谱进行采集,并建立了最小二乘-判别分析模型,将该模型应用于霉变烟叶的预测,但该模型仅对霉变烟叶样品和正常烟叶样品进行判定,未考虑临近霉变的烟叶预判。
本研究应用近红外光谱法对原料烟叶进行表征,通过采集不同霉变程度烟叶的近红外光谱,利用离散小波变换(DWT)对光谱进行前处理,并采用随机森林算法(RF)建立了正常烟叶样品、临近霉变烟叶样品和霉变烟叶样品的稳健分析模型。该方法无需对样品进行前处理,且监测速度快、操作方便,可有效地应用于库存烟叶的实时监测,在烟叶未出现明显损伤之间,对其霉变情况进行预判, 为烟叶贮藏过程中的品质控制提供一种新的思路。
1 实验与方法
1.1 材料与仪器
选取116种2015—2017年采集的复烤片烟,来源于不同产地、不同部位和不同等级,以充分考虑到产地、部位、等级不同,烟叶中霉菌种类和数量不同,对烟叶霉变带来的不同影响。样品由广东中烟工业有限责任公司提供。
TRH-1250恒温恒湿箱(Thermoline Scientific公司,用于样品霉变实验); MPA傅立叶变换近红外光谱仪(德国Bruker公司);KBF恒温恒湿箱(Binder公司,用于微生物计数实验);Double Biocao RNA/DNA超净工作台(erlab公司);BA-2S拍打式无菌均质器(上海本昂科学仪器有限公司);MS204天平(mettler公司);Milli-Q Integral 10超纯水机(Merck公司)。
1.2 霉变样品的制备
将复烤烟叶样品置于温度(22±2)℃,湿度(60±5)%环境下平衡48 h。将平衡后的样品放入恒温恒湿箱,调节温、湿度分别为25℃和85%条件下进行烟叶霉变实验,以21天为周期,按照以下方式进行取样:
(1)第0天,即放入25℃和85%湿度条件的恒温恒湿箱之前,进行第1次采样;
(2)第3~9天,以3天为间隔,分别进行第2~4次采样;
(3)第11~21天,以2天为间隔,分别进行第5~10次采样。
该过程可完整采集到复烤烟叶从未发生霉变,到临近霉变,再到霉变的样品状态。
1.3 霉菌计数实验
按照YC/T 472-2013《烟草及烟草制品 微生物学检验 霉菌计数》方法对不同霉变程度的复烤烟叶样品进行霉菌计数检测。根据霉菌计数检测结果,将霉变程度分为:未霉变样品(霉菌计数<2×103CFU/g);临近霉变样品(2×103CFU/g≤霉菌计数<104CFU/g);霉变样品(霉菌计数≥104CFU/g)。
1.4 近红外光谱数据的采集
实验采用BRUKER公司的MPA型傅立叶变换近红外光谱仪,光谱采集范围为4000~12000 cm-1,分辨率为8 cm-1,扫描次数为64次。将不同霉变程度的烟叶样本装入样品杯,分别采集各个样本的近红外光谱,作为各烟叶样本的基础光谱信息。每个样品分别重复装样测定两次,然后计算其平均结果作为最终光谱。
1.5 光谱预处理
近红外光谱受样品的一系列化学和物理因素影响,有必要采取数学前处理方法减少系统噪音,如基线变化和光散射等。本研究在对比了一阶导数(1-Der),二阶导数(2-Der),多元散射校正(MSC),标准正态变量校正(SNV)等多种预处理方法后,采用了离散小波变换(DWT)对近红外光谱数据进行预处理。
小波变换的实质是把信号分解为不同尺度和频率的小波子空间。根据波形或长度选择各种母小波使小波变换比其他信号预处理方法能够有效灵活地提取信号中的特征。通过小波变换,把信号分解成低频信号和高频信号,即近似系数和细节系数[12]。用小波变换对近红外光谱进行预处理时,在独立变量和近红外信号之间建立关联模型有两种途径[13-14]:一是用去噪或数据压缩后的近似系数和细节系数重构光谱,在重构光谱和独立变量之间建立模型; 二是直接用小波分解得到的小波系数作为变量来建立模型。很显然,后一种方法方便省时得多,也应用得较多[15-17]。本研究采用小波系数作为变量建立复烤烟叶霉变程度预测模型。
1.6 随机森林算法
随机森林(Random forest,RF)是一个包含许多决策树和投票策略的融合分类算法[18]。RF的基本思想是通过自助法随机选择(不是全部)向量生长成分类树,并且在生成树的时候,每个节点的变量都仅仅在随机选出的少数几个变量中产生。即变量和样本的使用都进行随机化,通过这种随机方式生成的大量的数被用于分类或回归分析,因此称为随机森林。最终的决策树是通过潜在的随机向量树进行投票表决产生,即选择具有最多投票的“类”为对应样本的类别。
随机森林模型具有两个非常重要的自定义参数:分类树的数量(k)和分割节点的随机变量的数量(m)。包含了k 个分类树的随机森林模型的建模过程如下:
1) 当i 从1变到k时:建立一个包含原始数据集X 中三分之二数据量的自助法子集Xi;以上述子集Xi为基础,在每个节点上随机选择m个预测变量,并在这些随机变量中选择一个最好的进行节点分割分类,建立一个不需修剪的深度最大的分类树。
2) 通过k个分类树的反馈信息预测新数据。如果是分类,利用k个分类树组合中的多数选票,如果是回归计算平均值。由于随机森林只采用了三分之二的数据进行建模,因此不会产生模型过度拟合。
2 结果与讨论
2.1 霉变烟叶的分类
按照1.2所述方法进行霉变实验后,116种单料烟分别在不同阶段进行了10次采样,获得了不同霉变程度的1160份烟叶样本。按照YC/T 472-2013《烟草及烟草制品 微生物学检验 霉菌计数》方法对1160份样本进行微生物学检验。杨蕾[11]的研究结果表明,霉菌数达到一定量(104CFU/g左右)时,会开始快速增长。为了能够对烟叶霉变提前预警,需要对临近霉变的样品进行预判,因此以104CFU/g为临界点,判定“临近霉变”样品(详见1.3所述)。根据烟叶霉变程度的判定方法,最终将烟叶霉变情况分为未霉变、临近霉变和霉变三个类别。霉变实验获得的三类样本情况如表1所示。第一类:548个,未霉变的正常样品(图1(a));第二类:102个,临近霉变样品(图1(b)),眼观和鼻嗅无法辨出其与正常样品的区别;第三类:510个,霉变样品(图1(c~d)为例),实验周期中获得的霉变烟叶样品霉菌菌丝体分布范围较大,从104CFU/g~105CFU/g不等,外观差异也较大。在本研究的实验周期中,未获得已经碳化变黑的霉变样品。
2.2 近红外光谱预处理
图2为1160份不同霉变程度的复烤烟叶样品的原始近红外光谱图。根据近红外光谱的原理,样品的近红外光谱吸收带是有机分子中含氢基团(O-H、N-H、C-H)在中红外光谱区基频吸收的倍频、合频和差频吸收带叠加而成的。当烟草发生霉变时,样品内部的C源、N源等有机物质因被霉菌分解代谢而发生变化,同时会产生一些麦角甾醇、几丁质等与霉菌细胞壁组成有关的化学成分。因此,从理论上来看,不同霉变程度的烟叶,其近红外光谱吸收带会随着样品内部化学成分的变化而产生变化。然而,一方面由于近红外光谱的严重重叠性,另一方面烟草霉变是一个复杂的过程,化学成分的变化也极其复杂,烟叶近红外光谱中与霉变程度相关的信息很难直接提取出来并给予合理的光谱解析。从图2可以看到,烟叶样品的近红外光谱中与霉变相关的吸收带很难从图谱上直观判断。
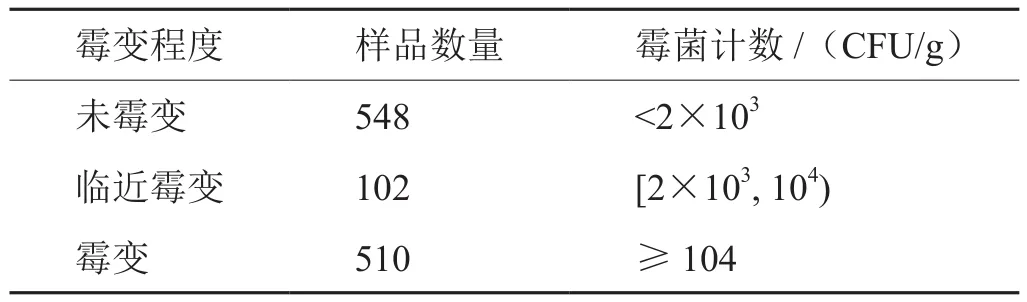
表1 烟叶样品霉变程度分类Tab.1 Classification of mildew degree of tobacco leaf samples

图1 不同霉变程度的复烤烟叶外观.Fig.1 Typical pictures of redried tobacco leaf with different degrees of mildew
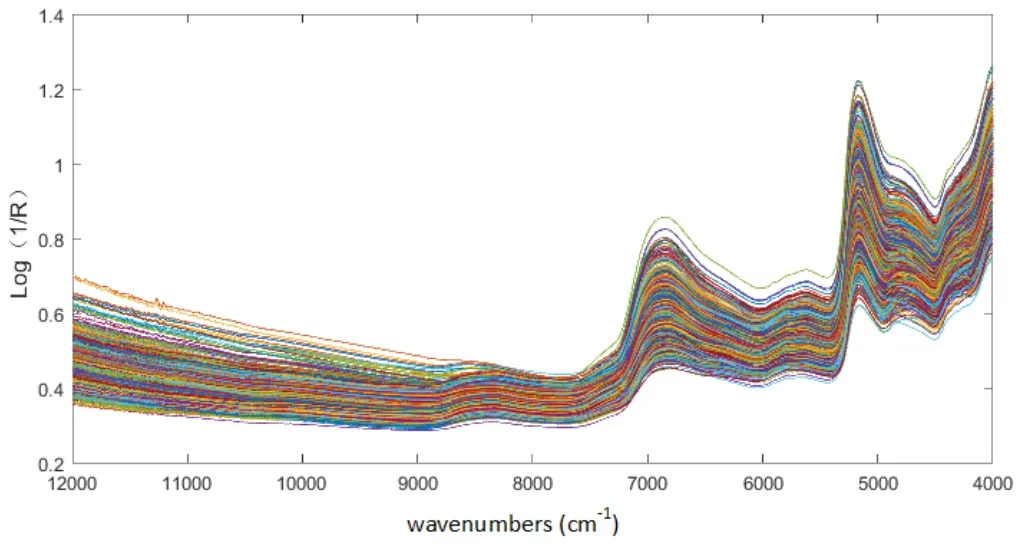
图2 复烤烟叶霉变过程中的原始近红外光谱图Fig.2 Typical near infrared spectroscopy of redried tobacco leaf during mildew process
为此,本研究采用离散小波变换(DWT)对霉变过程中的复烤烟叶原始近红外光谱进行分解。运用DWT处理近红外光谱时,有两个因素需要考察:母小波的选择和分解水平的确定。对于母小波的选择目前还没有理论可循,研究考察了15种母小波:5个 Daubechies系 列小 波(db2,db4,db6,db8,db10),5个 Symlets 系 列 小 波(sym2,sym4,sym6,sym8,sym10)以及5个Coiflets 系列小波(coif1,coif2,coif3,coif4,coif5)对霉变烟叶识别正确率的影响。Daubechies系列小波得到的结果基本一样,但总体上要比其他两个类型的小波得到的预报结果更好。最终确定db6为母小波。在确定分解水平时,通常应考虑输入数据的维数N,一般不超过log2(N);对于有用信息的提取,要求分解水平尽可能大。本研究中,近红外光谱有2074个数据点,因此本文选择11作为小波变换的分解水平。经每一水平的分解之后,会得到一个细节系数向量和一个近似系数向量;近似系数继续分解得到细节系数和近似系数,直到第11分解水平。最后用小波变换处理得到的向量包括每个样品的光谱信号在最后一个分解水平的近似系数(ca)和在所有分解水平的细节系数(cd),得到ca11,cd11,cd10,...,cd1共12组小波系数。
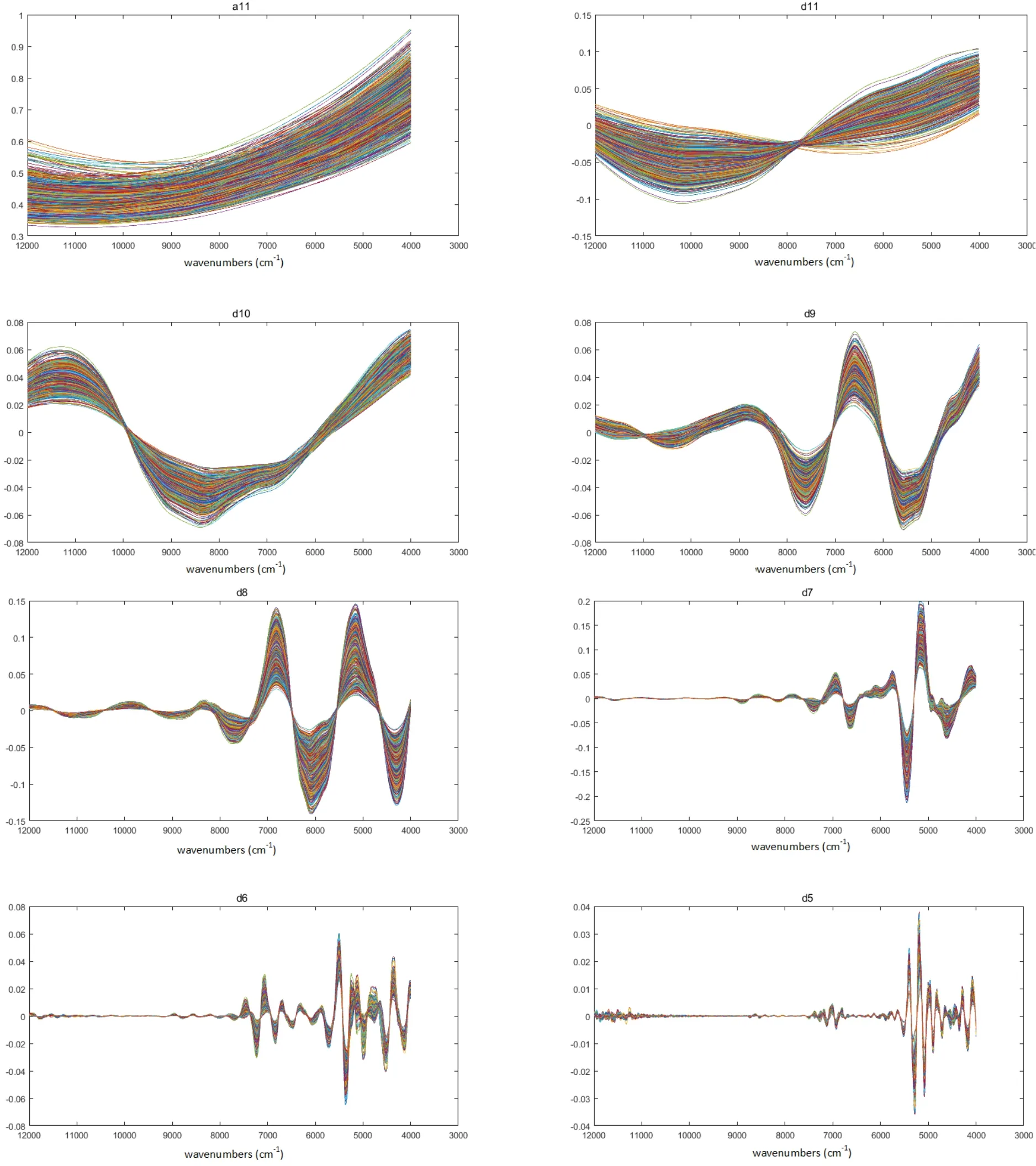
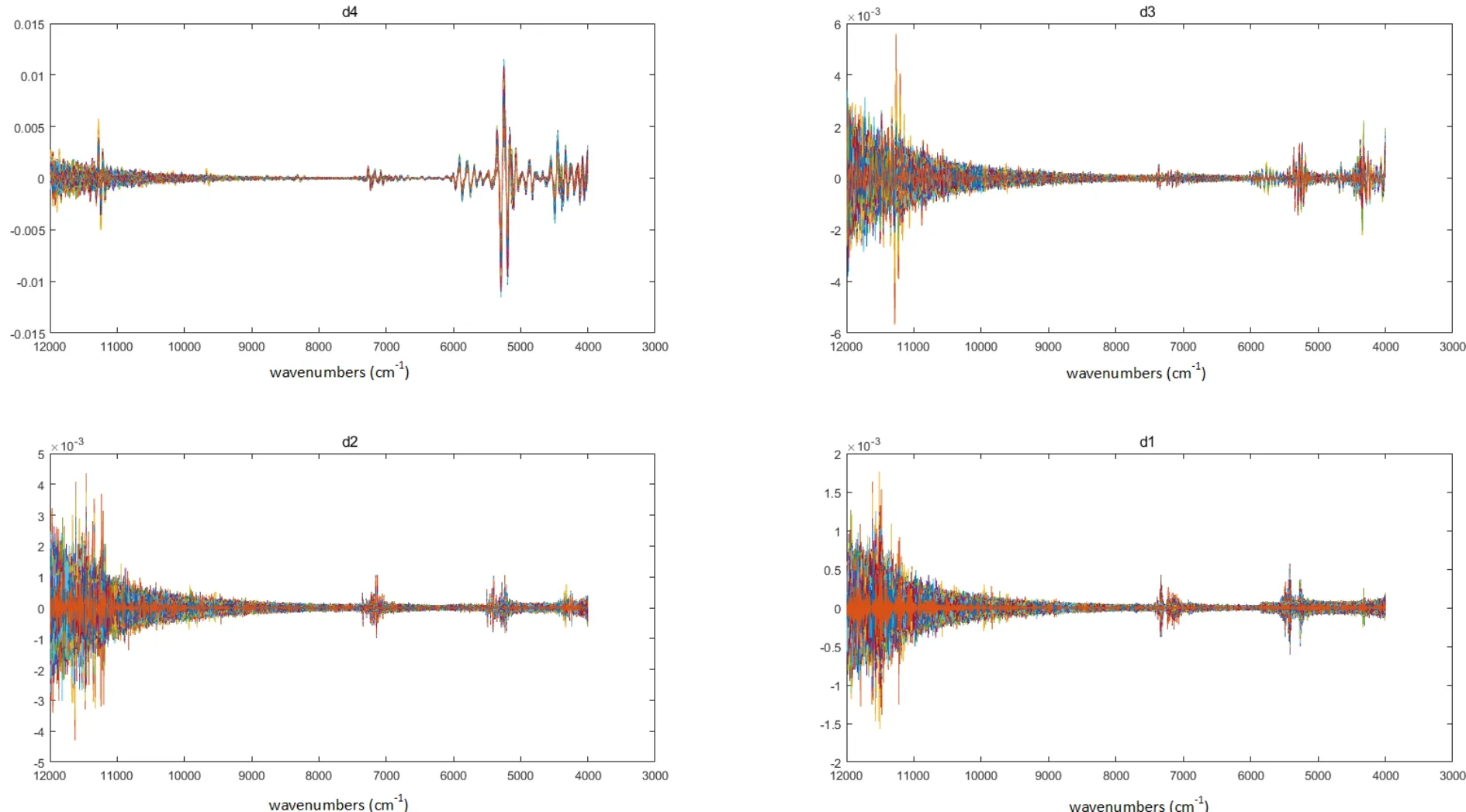
图3 不同霉变程度烟叶样品的小波系数重构光谱Fig.3 Reconstructed spectra of WT coefficient of redried tobacco leaf with different degrees of mildew
图3为基于12组小波系数(ca11,cd11,cd10,...,cd1)的1160份不同霉变程度的复烤烟叶样品的重构光谱a11,d11,d10,...,d1。从图3可以看出,a11、d11 等高阶信号主要反映了近红外光谱的低频(基线)信息,即光谱的骨架信息;d1、d2 等低阶信号主要反映了近红外光谱的细节(噪声)信息。从图中可以观察到,去除噪音和背景后的d4、d5、d6、d7等中间频率信号,不同霉变程度样品的光谱特征变得更加明显,利用这些隐藏的光谱差异,就有可能实现不同霉变程度的烟叶样品区分。将不同霉变程度的烟叶样品近红外光谱一一分解为包含不同光谱信息的12组小波系数,为建立烟叶霉变程度识别模型时减少系统噪音、去除背景干扰提供了方向。分别以各个频率区的小波系数作为输入变量,建立烟叶霉变程度鉴别模型,将其中给出最高预报正确率的小波系数,作为最后的输入变量。
2.3 烟叶霉变程度识别模型的建立
为了比较不同模型的识别效果,首先把1160份样本分成训练集和测试集,约2/3样本作为训练集,1/3样本作为测试集。最终随机选择773个样本作为训练集,其中包括365个未霉变的正常样品、68个临近霉变样品和340个霉变样品;剩余的387个样品作为测试集。本文将未霉变的正常样品、临近霉变样品和霉变样品分别记为“1”类、“2”类和“3”类。对训练集和测试集的识别正确率分别以识别率和预报率表示。
在本研究中,采用随机森林算法从烟叶近红外光谱的小波系数中识别烟叶的霉变程度。基于训练集,对识别模型进行了构建。在该算法中,设置森林中决策树的数目为200、每一个节点随机选择特征的数目为默认值(即,所有特征数目的平方根)。采用10折交叉验证方法考察模型的识别正确率,结果列于表2(表中识别率、识别率_1、识别率_2和识别率_3分别代表模型对训练集中所有样本的识别正确率、未霉变样品的识别正确率、临近霉变样品的识别正确率和霉变样品的识别正确率)。
从表2可以看出,从cd1~cd11,ca11,变量数从1051~29依次减少,其中具有较少变量数(92)的小波系数cd4构建的随机森林模型得到了最高的识别率:总识别率90.04%、未霉变样品的识别正确率90.68%、临近霉变样品的识别正确率80.88%、霉变样品的识别正确率93.24%,均高于其他小波系数的辨别能力。处于高频的系数,如cd1,cd2和cd3,变量数较多,识别率也较低,这可能是由于高频区的细节系数包含了大量的噪声信息(图3)。而处于低频的系数,包括高水平的细节系数和最后一个水平的近似系数,由于背景干扰或基线漂移比较严重,导致cd5,cd6,cd7,cd8,cd9和ca9构建的模型具有相对较低的识别率(59.51~84.22%)。此外还考察了不同系数组合构建识别模型的效果,结果发现以[cd4,cd5]为输入变量构建的随机森林模型识别率最高:总识别率93.40%、未霉变样品的识别正确率93.42%、临近霉变样品的识别正确率91.17%、霉变样品的识别正确率93.82%.相比之下,以原始光谱为输入变量构建的识别模型,识别率最差:总识别率69.73%、未霉变样品的识别正确率73.15%、临近霉变样品的识别正确率30.88%、霉变样品的识别正确率73.82%.
综合比较,以[cd4,cd5]小波系数组合作为光谱变量建立的随机森林模型,对不同霉变程度烟叶的识别准确率高,说明中间频率系数[cd4,cd5]中包含了绝大部分与烟草霉变相关的信息,同时随机森林算法有效地利用了烟草发生霉变时小波系数[cd4,cd5]中蕴含的变化,在霉变程度与小波系数间建立了有效关联。与原始光谱相比,基于[cd4,cd5]小波系数的随机森林模型变量数目少,运行速度最快,无需进一步去噪或平滑等优点,能够同时解决近红外光谱分析中背景干扰强,光谱数据维数高,运行速度慢等问题。因此,最终选择具有较少背景和噪音干扰的中间频率系数,[cd4,cd5]组合,作为输入变量,构建烟叶霉变程度识别模型。
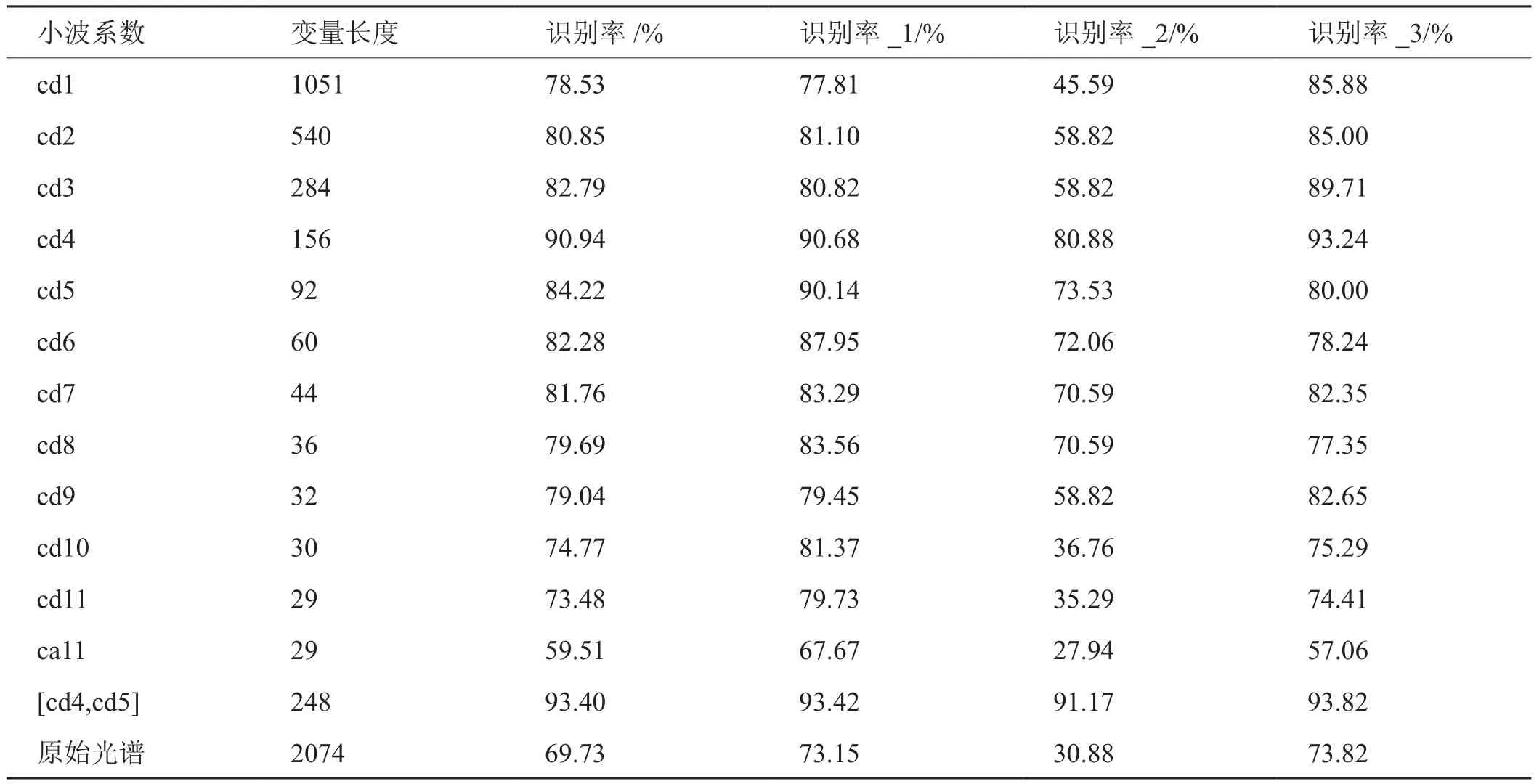
表2 基于不同小波系数的随机森林模型训练结果Tab.2 Training results of random forest model based on different wavelet coefficients
2.4 不同制样方式的对比研究
考虑到霉菌在烟叶上生长位置的随机性,以及样品装填的均匀性,可能会导致不同的样品处理方式对模型结果产生影响。但另一方面,从模型应用的便利性角度,希望样品处理方式约简单越好。因此本文基于片烟(无须制样)、烟丝(切丝)和烟末(磨粉)三种制样方式,分别建立了片烟、烟丝、烟末和综合模型,并对模型性能进行了评价和对比。其中,综合模型为综合三种样品建立的模型。模型结果见表3。
从表3可以看出,从模型准确率来看,烟末模型>烟丝模型>片烟模型>综合模型模型,总体上烟末模型、烟丝模型和片烟模型的预测准确率相差不大,对未霉变样品、临近霉变样品和霉变样品的识别准确率均超高了90%。将三种不同制样方式的样品综合在一起建立的模型,预测准确度大大降低,总精度仅为80.60%,对三类样品的预测都没有获得令人满意的准确度。由此可见,对烟叶霉变程度的判断,用片烟、烟丝和烟末样品建模均可获得较为满意的识别准确率,烟末和烟丝模型略优于片烟模型。考虑到样品制备的便利性,本研究选择片烟模型作为烟叶霉变情况预判的方法,可大大减少工作量。
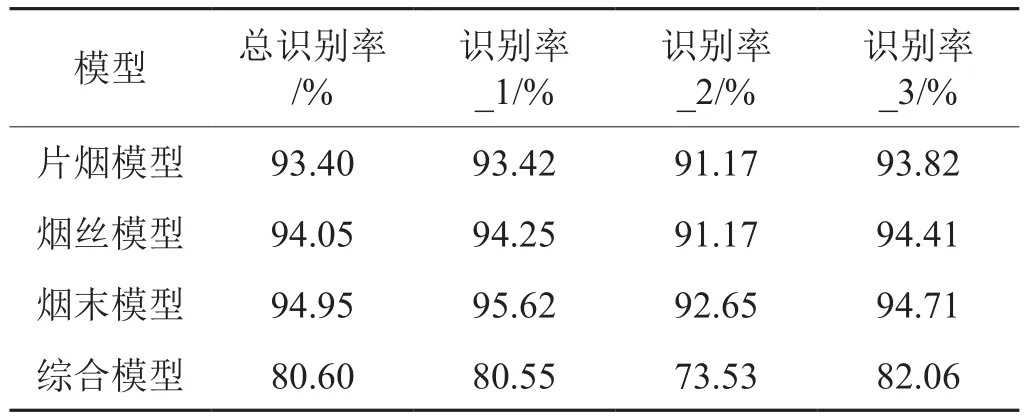
表3 片烟模型、烟丝模型、烟末模型和综合模型训练结果对比Tab.3 Comparison of training results of tobacco strip model, cut tobacco model, tobacco dust model and integrated model
2.5 片烟模型的验证
将片烟模型用来对测试集样品的归属进行预报,预报结果列于表4。从表4可以看到:183个未霉变样品中,175个被正确预报,正确率95.63%;34个临近霉变样品中,31个被正确预报,正确率91.18%;170个霉变样品中,161个被正确预报,正确率94.71%;测试集总预报正确率94.84%。结果表明,本方法建立的模型可以有效识别不同霉变程度的烟叶样品。
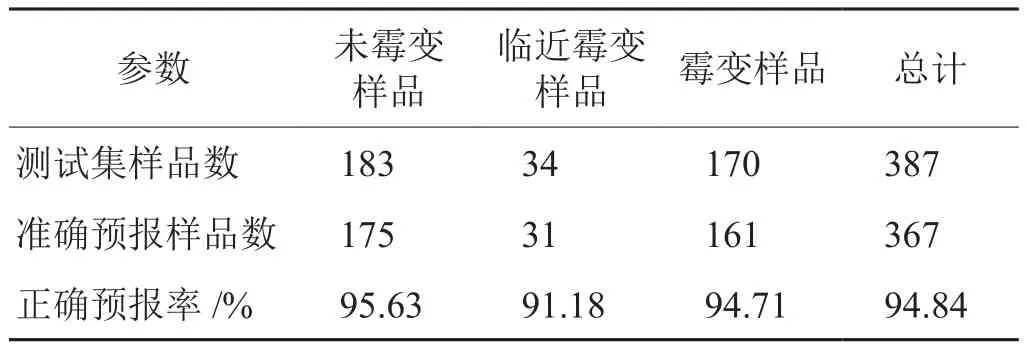
表4 基于[cd4, cd5]的随机森林模型对测试集的预测结果Tab.4 Predication results of the test set based on random forest model using [cd4, cd5]as WT input variables
关于实际应用,本研究随机抽取了一些库存片烟样品,应用本文方法对其霉变情况进行判别,结果均显示为“未霉变样品”;同时,通过霉菌计数及麦角甾醇含量的测定[4]考察抽取样品的霉变情况,结果与本文方法预判结果一致,所抽取的库存烟叶样品均未发生霉变。作为一种快速简便的方法,本方法正在逐步应用于公司烟叶质量监控的日常检测中。在实际应用中,应根据实际库存原料烟叶的情况,考虑采收年份、产地、部位、等级等因素的变化,尽量选择具有代表性的烟叶样品构建模型,及时进行模型维护,以确保基于近红外光谱的烟叶霉变预判模型的准确性。
3 结论
用近红外光谱法建立了不同霉变程度烟叶样品的快速识别方法,为烟叶霉变的预警提供依据。采用小波变换处理光谱数据,选择[cd4,cd5]作为光谱变量建立了不同霉变程度烟叶的随机森林识别模型,模型识别率和预报率分别达93.82%和94.84%,对未霉变的正常烟叶、临近霉变烟叶和霉变烟叶均达到了满意的识别率。由此可见,近红外光谱法结合小波变换和随机森林算法能有效识别不同霉变程度的烟叶样品。该方法可作为快速预测烟叶霉变程度的可行性方法。
