基于法向量和密度的点云特征点提取问题研究
2020-05-16马聪聪曹菁菁
马聪聪 李 松 曹菁菁 于 蒙
(武汉理工大学物流工程学院 湖北 武汉 430063)
0 引 言
随着三维扫描技术的飞速发展,三维点云数据的获取方式更加丰富且越来越便捷,精度越来越高。激光扫描是现阶段点云数据采集的主流方式,其速度快,获得的点云数据量相当庞大。点云数据的存储以及显示需要大量内存,同时需要较长的运算时间,这对后期模型重建的精度以及运算复杂度有重要影响。因此,在保证模型准确性的前提下提取特征点去除冗余点云数据,提高逆向工程各环节的运算效率是十分必要的。
针对点云特征点的提取,国内外研究人员做了大量研究。Woo等[1]基于八叉树进行三维网格划分,通过曲率与法向量对特征点进行提取,在考虑几何形状的同时对边缘点进行提取。Zhong等[2-3]提出内在形状特征(IntrinsicShapeSignature,ISS)算法,该算法具有较好的稳定性并取得了较好的特征点提取效果。Wang等[4]将三维点云数据与二维光学图像的优点相结合,提出一种基于结构信息的特征点提取方法,该方法能够准确、连续地提取点云特征。陶海跻等[5]对目标点及其K邻域内各点云数据对应的法向量夹角的算术平均值进行计算,并以此作为特征点的判别标准实现了对特征点的快速提取。陈龙等[6]通过采用多个判别参数并对其赋予不同的权重对特征点进行提取,该方法能够较好地对尖锐特征点进行检测提取,但是对于薄壁物体的特征点提取会出现误判的情况。张雨禾等[7]提出一种基于密度空间聚类的特征点提取算法,该算法具有较好的鲁棒性,但是需要对反K近邻进行计算,影响了算法的运行效率。陆帆等[8]提出反距离权重与密度相结合的算法,以边界点作为特征点进行提取,该方法运算速度较快但对特征变化不明显的点云进行特征点提取时效果稍差。
采用单一判别因素进行特征点提取容易导致特征点的漏判与错判,尤其对于特征变化不明显的点云,上述算法难以取得较好的特征点提取效果。针对该问题,本文提出一种基于点云法向量与点云密度相结合的特征点提取算法,有效改善点云特征点错判与漏判的情况,采用三组模型进行实验,获得了较好的特征点提取效果。
1 算法概述
设一点云数据集为X={xi|xi∈R3,i=1,2,…,n},首先对无序散乱点云通过建立KD树(K Dimension Tree)得到目标点的K邻域以提高点云数据的搜索速度。其次,通过主成分分析法(Principal Component Analysis,PCA)对点云法向量进行计算。然后,计算点云密度,并将其与点云法向量对应的特征度相结合组成特征点判别参数。最后,完成特征点的提取。算法流程如图1所示。

图1 特征点提取流程图
其具体步骤如下:
1) 构建点云拓扑结构。点云数据庞大且不具规律性,需要对其建立适当的拓扑关系,通过建立KD树以获得各个数据点的K邻域。
2) 采用PCA算法计算点云X中各点的法向量,并求得数据点与其K邻域中各个点的法向量之间的数量积。
3) 计算点云X的密度,并与法向量间数量积对应的特征度组成特征点判别参数。
4) 设定阈值,对符合条件的点进行保留,将不满足阈值要求的点剔除。
5) 根据点的K邻域内各点的特征,进一步对提取到的点进行筛选,得到最终的特征点集。
2 算法描述
2.1 点云拓扑关系构建
通过三维扫描仪获得的点云数据相当密集且数量庞大,同时点云数据在分布上呈现出杂乱、无规律的特性,在对其进行遍历时将严重影响算法的运行效率。K邻域是最常用的索引方式,其中心思想是选取与目标点最近的K个点构成一个集合,而K邻域的构造主要通过构建KD树的方式来实现。
KD树的构建是一个递归的过程,本文以x、y、z三个坐标轴所在的方向依次作为分区面,以欧式距离为标准进行点云数据的划分。首先,以x轴作为划分平面将点云数据x轴对应的坐标值按从小到大的顺序进行排序,取中值点作为根节点,将小于中值点的点云数据划分到左子树,则右子树中对应的点云数据的坐标值大于中值点。然后,以y轴作为分割坐标轴,同样将之前分割的子树中的点云数据按y值大小排序,以中位数作为切割点,最后,在z轴按同样的方式进行左右子树的划分。循环上述过程,直至按照某个节点划分结束后不能再划分出子节点为止。
KD树的搜索作为KD树算法不可或缺的环节,主要包含查询与回溯两个过程[9]。给定目标点,首先与根节点进行比较,若该点的坐标值小于根节点的值则进入左子树进行搜索,反之在右子树中进行搜索,循环该过程,直到搜索到最后一个叶节点为止。将该节点作为当前的最近点并进行回溯,与该节点相比,如果在点云数据中存在更符合要求的点,则将该点进行替换;否则寻找该节点对应的父节点,然后对父节点对应的其他子树进行校验。当搜索进行到根节点时,回溯停止,循环上述过程,直至获得K个最近邻点。
2.2 点云法向量计算
法向量是点云数据的一个重要的几何特征,可以在一定程度上反映曲面的变化情况,当曲面变化剧烈时,点云法向量的波动也会更加频繁,反之当曲面变化平缓时,点云的法向量变化也随之减小。采用PCA算法[10]对点云法向量进行计算,具体流程如下:
Step 1 建立K邻域后,计算各邻域中心点的坐标:
(1)
Step 2 构造点云数据的协方差矩阵Σ:
(2)
Step 3 计算协方差矩阵Σ的特征值以及对应的特征向量,点云的法向量为最小的特征值对应的特征向量。
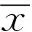
ni·nxi≥0
(3)
对所有点云数据对应的法向量计算完成后,对点云数据的特征度ti进行计算,特征度以某点的法向量与其K邻域内各点法向量的点积的平均数进行表示。
(4)
式中:ti表示点xi的特征度。
2.3 点云密度计算
点云密度对特征点的提取有重要影响,对于几何特征变化较大的点云模型,将点云密度作为特征点检测参数,会根据点云数据分布获得更多的特征点。而对于几何特征变化较小的点云模型,若仅以几何特征作为特征点提取的判别标准,提取到的特征点较少,难以表述点云模型的特征,引入点云密度将会提升特征点提取效果。
点云密度主要有两种表现形式,即基于分块的点云密度提取以及基于距离的点云密度计算。基于分块的点云密度提取方法将点云数据划分成若干块,统计各块内点的数量并以此对点云密度进行表示。基于距离的点云密度计算则以点云数据间的距离为依据,本文以此作为点云密度的表示方法[7]:
(5)
式中:ρi为点的密度;dij表示K邻域内点xj与xi之间的距离。可以看出,当点间距离较大,即点云分布较稀疏时,ρi的值较小;而当点间距离较小时,点的分布相对密集,ρi的值随之增大。
2.4 特征点提取
以点云法向量作为特征点提取的依据,当点云数据间距离较大时,法向量的变化可能随之变大,从而容易出现非特征点误判的情况;而当点云数据间距离较小时,法向量的变化程度也随之减小,可能导致特征点漏判。针对上述问题,本文将点云法向量对应的特征度与点云密度相结合组成特征点判别参数,计算如下:
(6)
式中:Hi表示特征点判别参数;ρi对应xi的点云密度;ρmin表示所有点云数据对应的点云密度中的最小值;ρmax则为点云密度中的最大值。
当完成所有点云数据的特征点判别参数计算后,与阈值进行比较。将特征点判别参数小于阈值的点作为特征点,特征点参数大于阈值的点则为非特征点。当点云密度较大时,特征点判别参数会随之增大,从而使得更多的点大于阈值,因此特征点的概率随之下降,减少了冗余点的存在。当点云几何特征变化强烈时,特征度的值也会随之变大,该点作为特征点的可能性也随之提高,将其与点云密度相结合,使得点间距离与几何特征取得了更好的平衡,提升了特征点的判断准确性,使得特征点提取效果更好。
3 实验验证与分析
为验证本文算法的有效性,选择三组点云模型进行实验验证。实验环境为Win10 64位系统,i5-8300H CPU,8 GB内存的计算机,通过MATLAB 2017b实现。为体现本文算法的优越性,与ISS算法、文献[5]的算法以及文献[11]的算法进行对比实验。ISS算法在刚性变换中对特征点进行提取时具有较好的稳定性和效果,应用较为广泛。点云几何特性主要包括法向量与曲率,文献[5]的算法以点云几何特性中的法向量作为特征点判断标准,而文献[11]以曲率特性为依据对特征点进行提取。因此,选择上述三种算法与本文算法进行对比验证更具代表性与说服力。
(1) Bunny点云模型特征点提取效果。Bunny点云模型数据来源于斯坦福大学,该模型含有的点云数据量为40 097,各算法运行所需的时间以及提取到的特征点数量如表1所示。本文算法所需的时间相对较少,提取到的数据量适中。
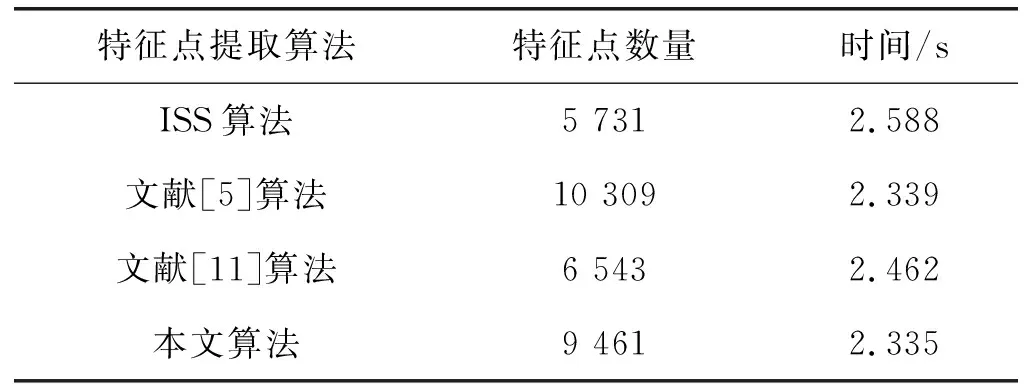
表1 Bunny模型特征点提取算法结果
三种算法得到的特征点提取效果如图2所示。图2(a)为Bunny模型的原始图像,该模型的轮廓特征清晰,点云模型的边界变化明显,在耳朵、背部以及腿部等区域,点云模型的几何特征变化强烈,法向量变化较大,点云密度也相对较大。图2(b)为经ISS算法运行后得到的特征点提取结果,可以看出ISS算法提取到的特征点基本能够反映模型的几何形状与变化特点,但是在耳朵以及尾巴部分得到的特征点有所欠缺。采用文献[5]的算法得到的特征点提取效果如图2(c)所示,该算法提取到了较多的特征点,但是包含了一些杂乱的冗余点,而轮廓作为该模型变化最丰富的区域,采用该算法获得的轮廓效果稍差。采用文献[11]的算法得到的特征点数量较少,其提取效果如图2(d)所示,该算法在几何特性变换明显处得到的特征点效果不明显,包含了一些非关键点,其运行效率相对来说也并不是最优。采用本文算法得到的效果如图2(e)所示,可以看出本文算法相对于ISS算法提取到了更多的特征点,尤其是在几何特征变化明显的区域获得了更多的特征点,而与文献[5]以及文献[11]的算法进行对比,可以看到本文算法提取到的特征点更能反映Bunny模型的轮廓特征,特征点提取效果更优。

(a) Bunny模型 (b) ISS算法

(c) 文献[5]算法 (d) 文献[11]算法

(e) 本文算法图2 Bunny点云模型不同算法特征点提取效果
(2) Dragon点云模型特征点提取效果。Dragon点云模型经三种算法进行特征点提取得到的结果如表2和图3所示。Dragon模型的原始图像如图3(a)所示,Dragon模型的点云数据量为25 141,该模型几何形状更加复杂,细节更加丰富,因此,需要提取到更多的特征点才能尽可能表示模型的变化特点。图3(b)为ISS算法提取到的特征点,可以看出,该算法提取到的特征点能够较好地反映点云模型的变化特点,模型边界相对完整,在变化较大的头部以及细节丰富的主干部分获得了较好的数据点。文献[5]的算法获得的特征点如图3(c)所示,该算法得到的特征点提取效果较差,出现了特征点漏判的情况,且边界不够完整,细节不够清晰。图3(d)为文献[11]得到的提取效果,该算法得到的特征点数量大大减少,但不能较好地反映模型的几何变化特征。采用本文算法得到的结果如图3(e)所示,可以看到本文算法提取到的特征点数量大于ISS算法,在细节丰富的主体部分获得的点云数据能够更好地反映模型特点,本文算法的效果同样优于文献[5]与文献[11]的算法,且相对于ISS算法以及文献[11]的算法,本文算法的运行效率更好。
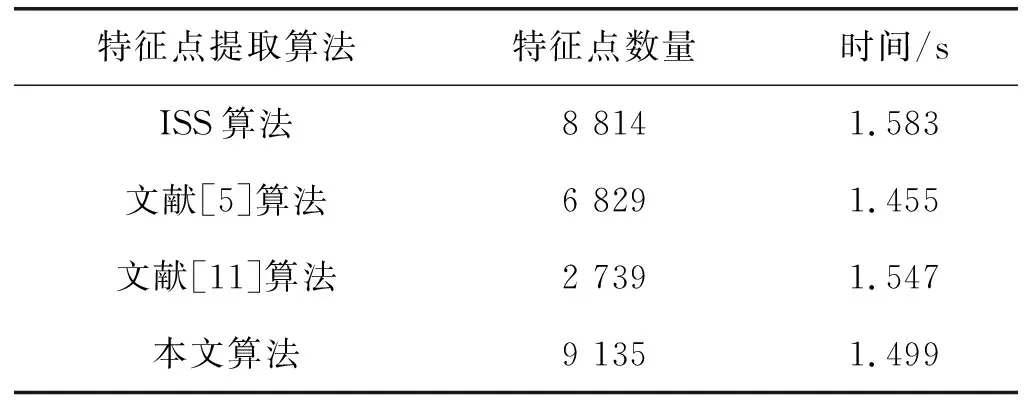
表2 Dragon模型特征点提取算法结果

(c) 文献[5]算法 (d) 文献[11]算法

(e) 本文算法图3 Dragon点云模型不同算法特征点提取效果
(3) Panda点云模型特征点提取效果。Panda点云模型的数据量为155 868,该模型的特征点提取效果如表3和图4所示。图4(a)为Panda模型的原始图像,可以看出,该点云模型数据量大,而且模型中存在破损的孔洞以及连接处缺失等情况,因此,该模型的形状特征较为丰富。经ISS算法得到的特征点提取效果如图4(b)所示,该算法得到的特征点分布与原型分布大体一致,虽然在三种算法中提取到最多的特征点,但是在一些细节处的特征点提取不够完整。图4(c)为文献[5]的算法得到的特征点提取结果,该算法相较ISS算法得到的点云数据较少,且提取到的特征点质量不高,在轮廓特征方面表示不清晰,且细节特征也不够突出。采用文献[11]的算法得到的结果如图4(d)所示,该算法极大地降低了特征点数量,其中包含了一些非特征点,从而导致提取效果不佳。本文算法得到的特征点提取结果如图4(e)所示,可以清晰地看到本文算法在变化较大的边界处提取到了更多的特征点,在点云分布均匀的部分,提取到了较少的点云数据,减少了冗余点的数量且能够更好地反映Panda模型的轮廓特征,取得了较好的特征点提取效果,且算法运行效率较稳定。

表3 Panda模型特征点提取算法结果

(a) Panda模型 (b)ISS算法

(c) 文献[5]算法(d) 文献[11]算法

(e) 本文算法图4 Panda点云模型不同算法特征点提取效果
4 结 语
本文针对现有特征点提取算法存在的错判以及漏判等问题,提出了一种基于点云法向量与密度相结合的特征点提取算法。特征点判别参数由特征度与点云密度共同组成,兼顾了几何特征变化与点云间距离以及密度对特征点提取的影响。采用三组不同的点云模型对本文算法进行了实验验证,结果表明本文算法相对于传统算法提取到的特征点能够更加清晰地表征模型几何形状变化,在细节丰富的区域提取到的特征点更加合理有效。
