基于改进YOLOv3的人脸实时检测方法
2020-05-16蒋纪威何明祥
蒋纪威 何明祥 孙 凯
(山东科技大学计算机科学与工程学院 山东 青岛 266590)
0 引 言
随着智慧城市的迅速发展,人脸检测在智能监控中具有重要的地位。如何准确快速地检测人脸,对人脸进行特征分析从而提取有用的信息,具有重要的研究价值。
传统的人脸检测方法有很多,Adaboost人脸检测方法通过无数次迭代来寻求最优分类器检测人脸[1]。SVM通过构造有效的学习机器来解决人脸的检测问题[2]。传统的人脸检测方法提取的特征单一,鲁棒性较差。随着深度学习的不断发展,人脸检测有了很大的提高。目前经常使用的目标检测方法分为两种,一种是基于分类的检测,一种是基于回归的检测。基于分类的目标检测方法有使用确定候选区域进行深层网络特征提取的FastR-CNN[3]和使用RPN网络进行深层网络特征提取的FasterR-CNN[4],分别将准确率提高至70%和73.2%,这种方法对目标物体的检测效果比较理想,但是检测速度为7帧/s,无法满足实时性。基于回归的目标检测方法主要使用单发多框检测器SSD[5]和统一实时对象检测YOLO[6],此类方法从端到端进行检测,因此检测速度更快,可以实现实时检测。
YOLOv3在YOLO基础上进行了改进,是如今实时性最好的检测方法之一。目前已经有学者对YOLOv3方法进行了相关研究,提出了不同的改进方法,在许多检测领域实现了应用。郑志强等[7]用密集网络模块替代YOLOv3网络中的残差网络模块,提高了遥感图像的检测准确率。鞠默然等[8]将YOLOv3网络的8倍下采样进行修改,并拼接第二个残差块特征图,能有效检测小目标。施辉等[9]通过获取不同尺度的特征图和改变输入图像的尺寸,实现了安全帽佩戴的实时检测。上述文献通过对YOLOv3网络结构改进,在不同的检测领域实现了应用,但是对人脸的实时性检测效果不是很理想。
如今随着智能监控的日益完善,需要对人脸进行准确并快速的检测,以提高实时性。为了兼顾人脸检测的准确性与实时性,本文使用改进的YOLOv3卷积神经网络。通过修改和测试YOLOv3的网络结构,提高了人脸检测的准确率。将本文改进的YOLOv3方法、FasterR-CNN方法、文献[9]的方法和YOLOv3方法在WIDERFACE和FDDB数据集上进行对比实验,结果表明本文改进的方法在人脸检测领域具有较好的实时性。
1 YOLOv3介绍
YOLO方法是Redmon等发表在CVPR2016上基于回归的经典目标识别方法,到2018年已经发展到YOLOv3,它采用多尺度从端到端进行训练,识别速度非常快。YOLOv3优化了R-CNN(区域卷积神经网络),成为一个更通用和更快的检测系统[10]。该模型将目标识别作为一个单一的回归问题来处理,同时在训练阶段对整个图像进行一次分析。
1.1 YOLOv3思想
YOLO输入图像被分为S×S均匀网格,每个网格由(x,y,w,h)和置信度C(Object)组成。其中坐标(x,y)表示检测边界框中心相对于网格的位置,(w,h)是检测边界框的宽度和高度[11]。
置信度Pr(Object)表示是否包含物体,置信度C(Object)表示包含物体情况下位置的准确性,定义为:
C(Object)=Pr(Object)×IOU(box,centroid)
(1)
如果检测网格不包含目标对象,则C(Object)=0。
IOU是预测值与真实值的重叠率,即它们的交集与并集之比,如下式所示:
(2)
1.2 网络结构
YOLOv3网络结构没有池化层,在前向传播过程中,通过改变卷积核的步长代替池化层,特征提取模型采用很多3×3和1×1的卷积层,再加上全连接层共有53个卷积层,因此YOLOv3通常也称作Darknet-53[7]。YOLOv3首先通过特征提取网络对输入图像进行特征提取得到特征映射,采用3个尺度进行预测,如图1所示,每个尺度有3个界限值(bounding box),最后由与ground truth的交并比(IOU)最大的界限值预测物体。
(1)电磁吸附工装的应用 目前电磁吸附工装在工件搬运及机械加工行业有着广泛的应用,采用磁力吸盘对铁磁性材料进行吸合固定,如机械加工车削、铣削、磨削、镗削、锻件模具加工的紧固工作。
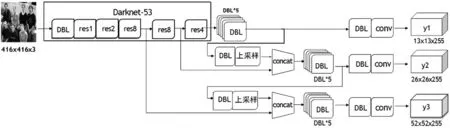
图1 YOLOv3网络结构
2 基于改进YOLOv3的人脸检测方法
本文主要利用YOLOv3研究人脸的检测,通过修改YOLOv3的网络结构,将YOLOv3结构较好地应用在人脸检测领域。
2.1 聚类方法
虽然YOLOv3在目标检测方面获得了很好的结果,但是它不完全适合人脸图像定位任务。因此,本文对YOLOv3进行了相应的改进。
YOLOv3训练网络时,初始规范先验边界框并确定其数量。随着网络迭代次数的增加,YOLOv3学习人脸特征,通过调整先验边界框的参数不断接近真实的检测框。YOLOv3的anchor由VOC2007和VOC2012数据集确定,这两个数据集的类别丰富,确定的anchor参数是通用的,但是不适用于特定的检测任务,因此需要在检测数据集中重新确定先验边界框。为了加快收敛速度,提高人脸检测精度,采用K-means法进行聚类,得到图像中最接近人脸边界框的先验边界框。
通常来说,K-means聚类使用欧几里得距离测量两点之间的距离。在本文中,IOU用来代替K-means中的欧式距离,聚类使用文献[12]定义的距离公式:
d(box,centroid)=1-IOU(box,centroid)
(3)
YOLOv3使用K-means聚类来确定先验边界框,在COCO数据集上通过计算确定的先验边界框尺寸分别是:(10,13),(16,30),(33,23),(30,61),(62,45),(59,119),(116,90),(156,198),(373,326)。在进行人脸检测实验时,待检测人脸边界框的尺寸如图2所示,采用原始先验边界框会影响人脸检测的准确率和实时性,因此需要重新确定YOLOv3先验边界框尺寸。

图2 人脸边界框尺寸
通过本文改进的聚类方法对数据集进行聚类分析,得到先验边界框尺寸分别为:(58,24),(64,30),(70,34),(78,38),(84,40),(88,43),(96,47),(100,50),(106,58)。
2.2 改进的网络结构
Darknet-53网络的最后一层采用1×1卷积层输出预测结果,其卷积核数量是根据所需识别的类的数量计算的,如下式所示:
filters=(classes+5)×3
(4)
在原网络中,第一层中有32个卷积核,如图3所示。本文改变了第一层卷积核的数量,第一层卷积层卷积核的数量分别设置为8、16、32。通过这种方式,生成了3个不同的网络,每层网络输入图像为416×416像素[13],提出的网络结构如表1所示。
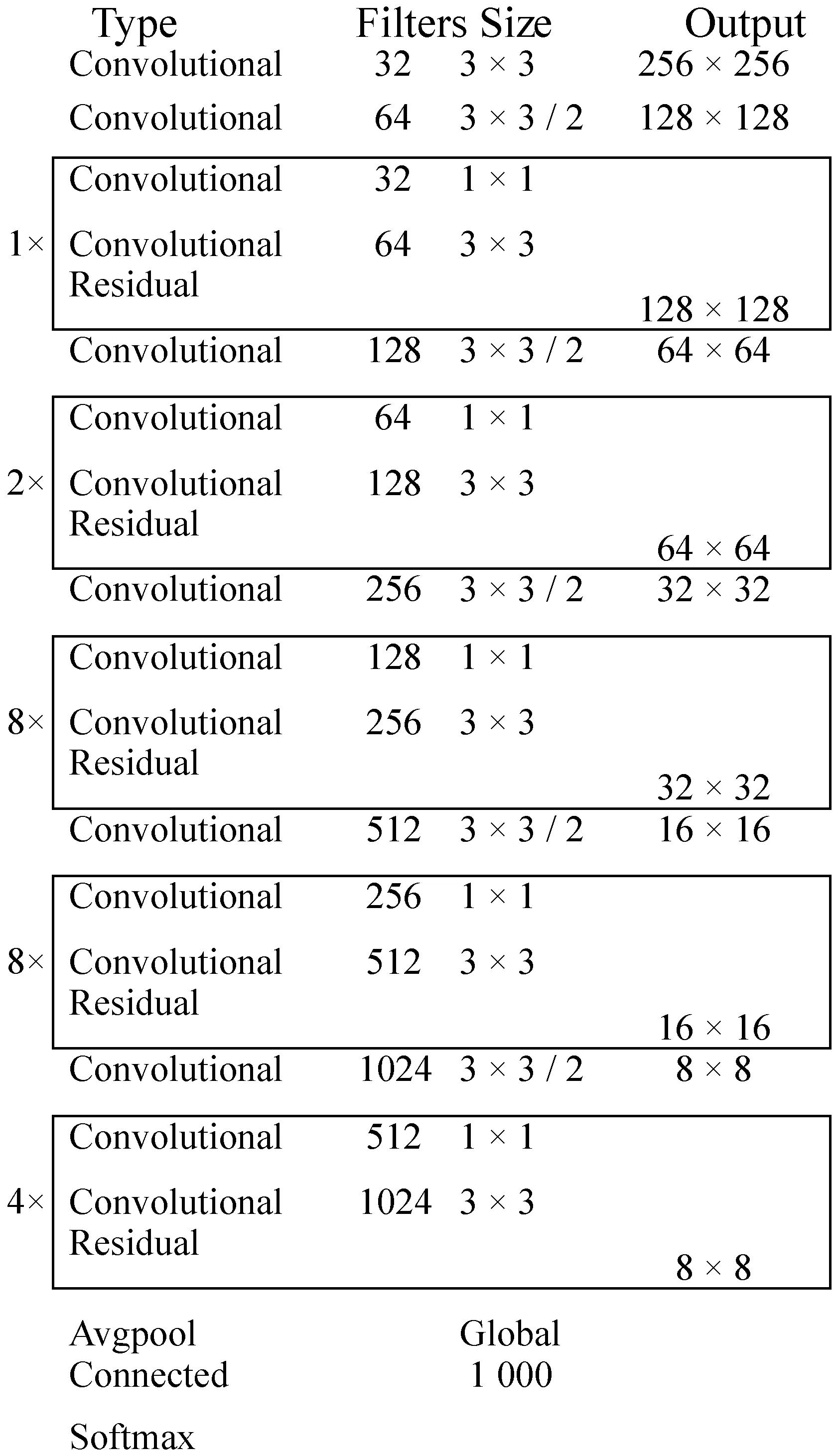
图3 Darknet-53模型结构
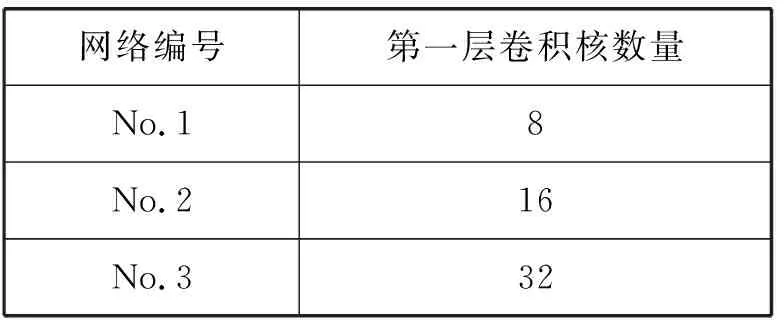
表1 改进Darknet-53网络结构
采用表1的思想,改变Residual×1中第一层卷积核的数量,得到改进的YOLOv3结构如图4所示。

图4 改进YOLOv3结构
3 实验结果与分析
本文的仿真实验环境:处理器为Inter corei7-7770,CPU为3.60 GHz×8,7.7 GB内存,GPU为GTX1080。操作系统为Ubuntu16.04,深度学习框架采用Darknet。
本实验的目的是确认具有最佳人脸检测效果的改进的Darknet-53网络结构,通过与Faster R-CNN、文献[9]和YOLOv3对比,验证本文方法具有较好的实时性。
3.1 网络对比实验
本文采用香港中文大学公开的人脸数据集WIDER FACE,其包括了在角度、光照、姿势等方面不同的人脸图像。训练集选取其中1 500幅图片,对所有Darknet-53网络进行了300 000次迭代训练。为了加快训练速度并防止过拟合,初始学习率设置为0.001,学习率衰减系数设置为0.000 1,权值衰减系数设置为0.000 5[14]。
为了测试网络人脸检测的准确度,本文分别对三种网络进行测试实验,并对结果进行了比较。测试集选取WIDER FACE数据集中的300幅图片,每20 000次进行一次测试,检测效果如表2所示。
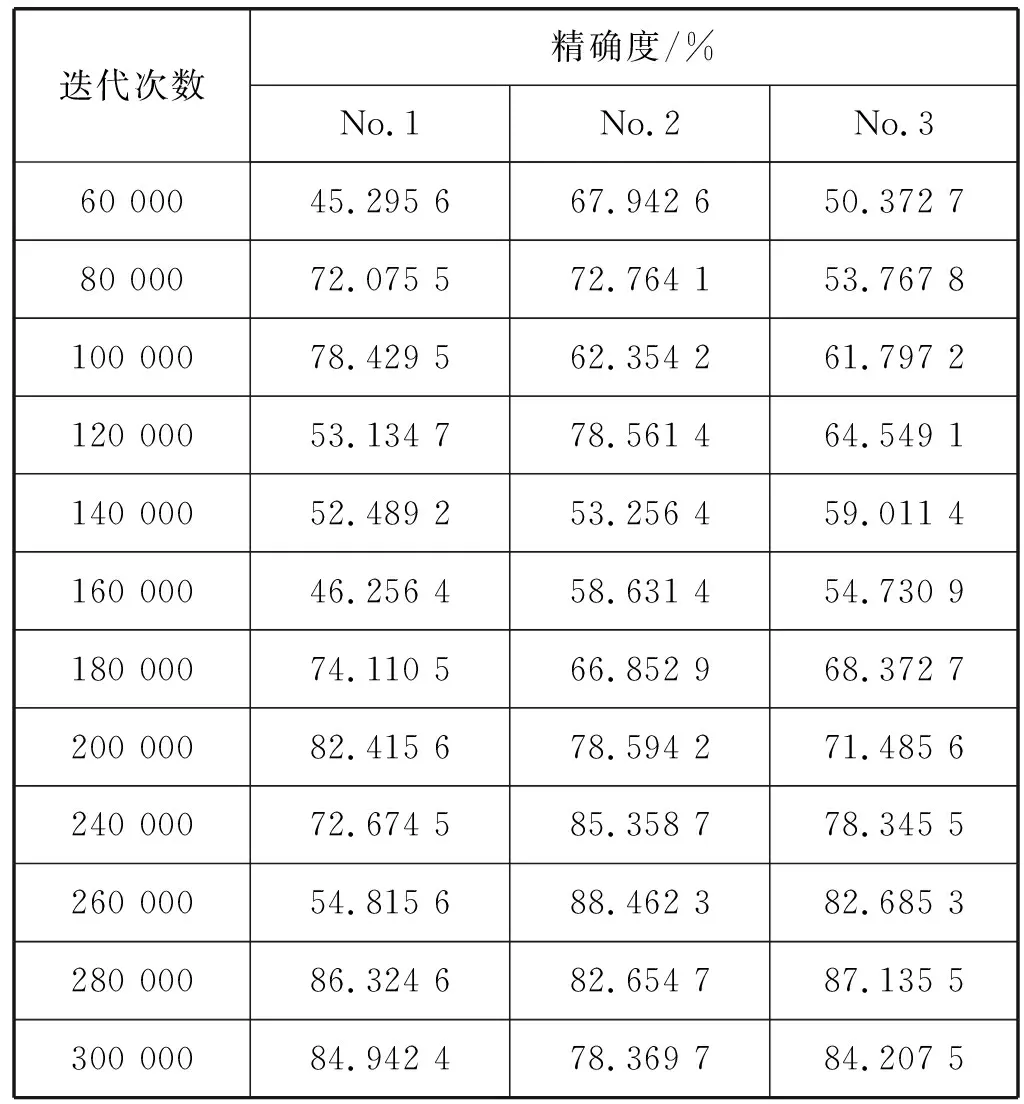
表2 三种网络的测试精确度
由表2可知,使用No.2网络结构获得了人脸检测的最佳结果。该网络第一个卷积层有16个卷积核,输入分辨率为416×416像素。
本文使用其他30 000幅图像的训练数据集对该网络进行了进一步的训练,最多训练600 000次,进一步测试该网络的结果没有显示出任何显著的改进,最佳精度仍为88.46%。
3.2 人脸检测实时性实验
为了验证本文提出的方法在人脸检测过程中具有较好的适用性,本文采用WIDER FACE数据集和FDDB数据集进行了实验,并将数据集分为训练集和测试集,每帧检测一次,实验采用的数据集如表3所示。
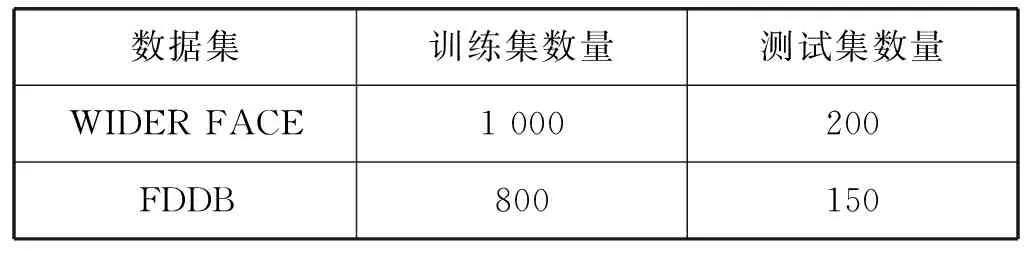
表3 实验数据集
采用表3中的训练集分别对Faster R-CNN、本文改进的YOLOv3、文献[9]和YOLOv3进行训练,图5列出了实验结果。由图5(a)和(b)可以看出,Faster R-CNN和本文改进的YOLOv3检测方法能很好地检测出人脸。由图5(c)可以看出文献[9]的检测方法出现了人脸漏检情况。由图5(d)可以看出YOLOv3不仅漏检了部分人脸,而且识别框出现了偏差。

(a) Faster R-CNN (b) 改进YOLOv3
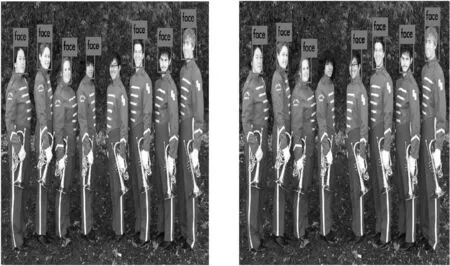
(c) 文献[9] (d) YOLOv3图5 人脸检测结果图
通过对比实验[15],四种方法的检测结果如表4所示。可以直观地看出本文方法在人脸检测实时性方面的优势。
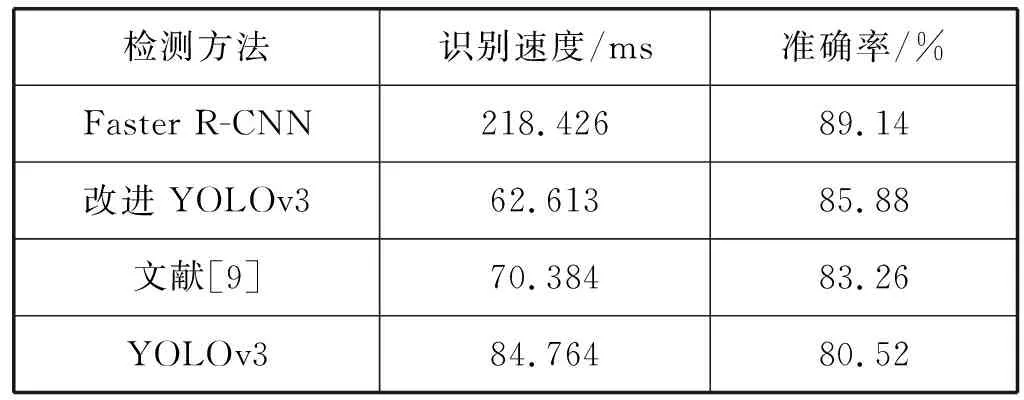
表4 实验结果对比表
在进行验证实验的同时得出了四种方法的召回率曲线[16],如图6所示。可以看出,本文改进的YOLOv3具有较强的适应能力。
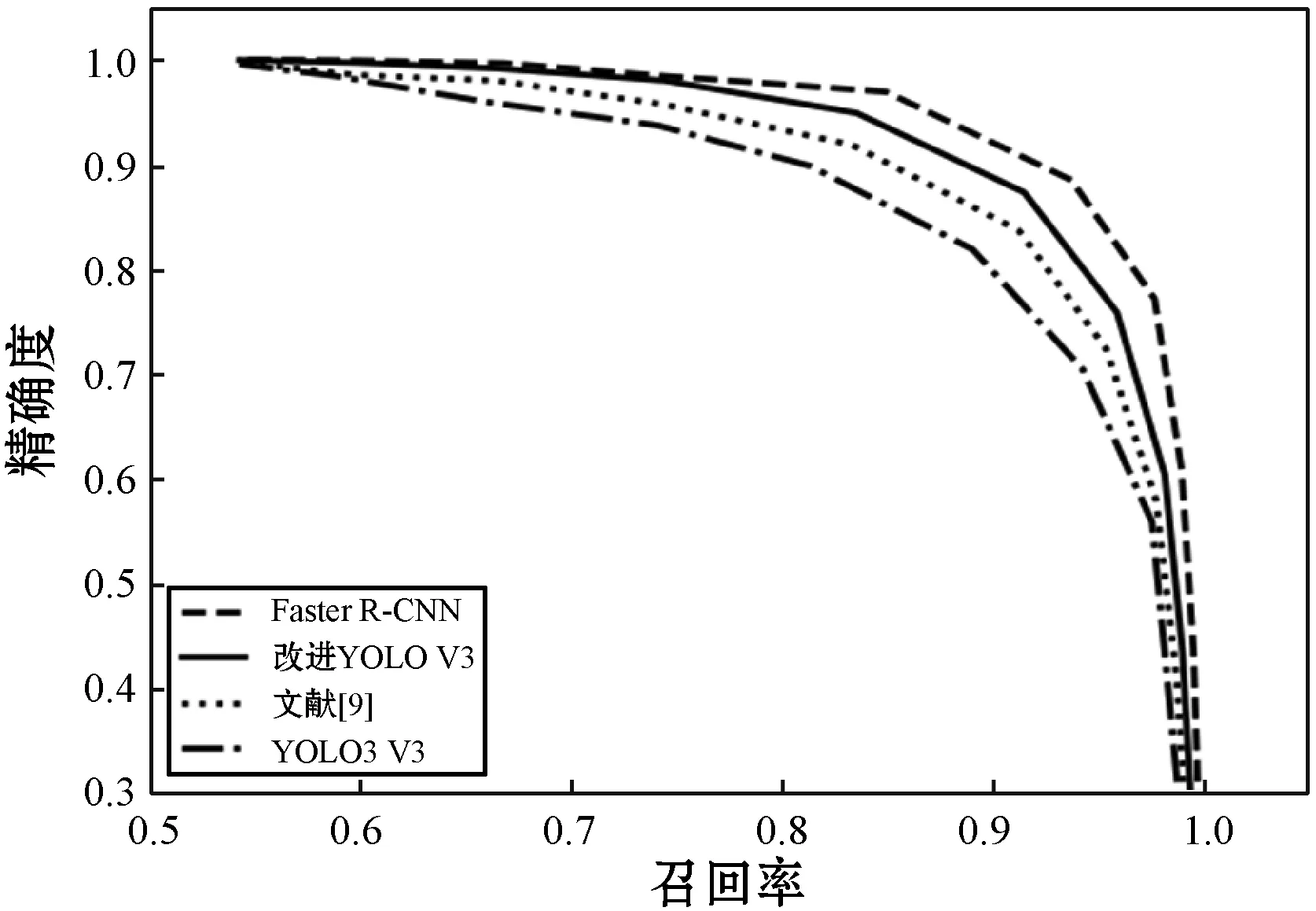
图6 召回率曲线
综合可知,Faster R-CNN和本文改进的YOLOv3的人脸检测准确率高于其他两种方法,Faster R-CNN在检测时需进行RPN网络特征提取,故检测速度比本文人脸检测方法慢。因此本文改进的YOLOv3在人脸检测方面优于其他检测方法,在保持较高的检测准确率的同时,具有良好的实时性。
4 结 语
本文通过改变第一层卷积层的卷积核数目,设计了3种基于Darknet-53的卷积神经网络,并在WIDER FACE数据集上进行训练。实验结果表明,本文方法能够从数据集中有效地检测出数据集中的人脸,在第2种网络结构中得到的准确度最高,为88.46%。该网络结构第1个卷积层中有16个卷积核,输入分辨率为416×416像素。此外,除了保持人脸检测的高准确率,本文方法检测速度更快,每帧处理时间为62.613 ms,因此具有良好的速度和精度平衡。这些特性使本文方法适合于人脸实时检测。
