基于文本匹配的电商对话系统设计
2020-05-15郑锡聪凌毓涛李夏雨
郑锡聪,凌毓涛,李夏雨,万 浪
(华中师范大学 物理科学与技术学院,湖北 武汉 430079)
在1955年“学习机器讨论会”上,学者们提出了下棋与计算机模式识别的研究,“人工智能”的雏形初步形成,在次年的达特茅斯会议上,正式提出了“人工智能”一词,并讨论确定了人工智能最初的发展路线与发展目标[1]。现如今,人工智能渗透到各个领域,例如图像处理、语音识别、目标检测、自然语言处理等。文本匹配问题一直是自然语言处理[2]中的热点话题,涉猎领域包括机器翻译[3]、信息检索[4]、复述问题[5]等。传统意义上的文本匹配问题处理手段一般是基于人工提取特征,其焦点问题是如何设置合适的文本匹配算法来学习到最优的匹配模型[6]。Qu等[7]提出了一种基于词频的机械匹配自动分词算法,在忽略5个字以上词语的前提下,以长度为首优先,结合词频进行分词,未匹配字串进一步应用改进的正向和逆向最大匹配法,结合熵率分词分别标注所有可能为词的元素。Jin等[8]提出了一种包含上下文索引、上下文挖掘、上下文匹配的快速文本匹配框架,从索引中直接获取内容的上下文信息从而提高信息提取性能。虽然传统意义上的方法在文本匹配问题上取得了一定的成绩,但是也存在一定的弊端。人工设定的特征提取起来代价很大,需要占用大量的计算机CPU内存,而且过分的依赖于人工设计,鲁棒性不是很好。
近些年来,利用人工智能领域的方法来进行文本匹配也取得了一定的成果。Zhen等[9]提出了一种基于词嵌入与依存关系的文本匹配模型,构建了融合词语语义和词间依存关系的语义表示,通过余弦均值卷积和K-Max池化操作获得相关矩阵,采用LSTM网络来学习匹配程度矩阵和真实匹配程度之间的映射关系。Fu等[10]提出了一种基于自学习文本近邻图框架的深度学习模型来处理短文本问题,使用词嵌入将文本转化为向量并构建文本相似度矩阵以表示文本近邻关系。Wu等[11]提出了多粒度语义交叉模型,通过LSTM模型获得短文本的不同粒度语义表示,然后提取语义匹配信息从而计算语义匹配度。
进入21世纪可以说是进入了“电商时代”[12],淘宝、京东、拼多多等电商平台占据了重要的市场份额[13-14]。一个强大的电商系统为了节约人力开销自然离不开自然语言处理任务,本文针对电商系统中常见客服问答设计了一款电商对话系统,以解决基本的电商问答中的文本匹配问题。
1 网络系统结构
本设计的核心思想是将输入的文本数据分析综合后作为DSSM网络系统的输入进行训练,检验测试环节是否表现良好。因此系统主要分为3个模块:① 数据处理模块;② DSSM模型搭建模块;③ 测试模块。每个模块主要的操作流程如图1所示。
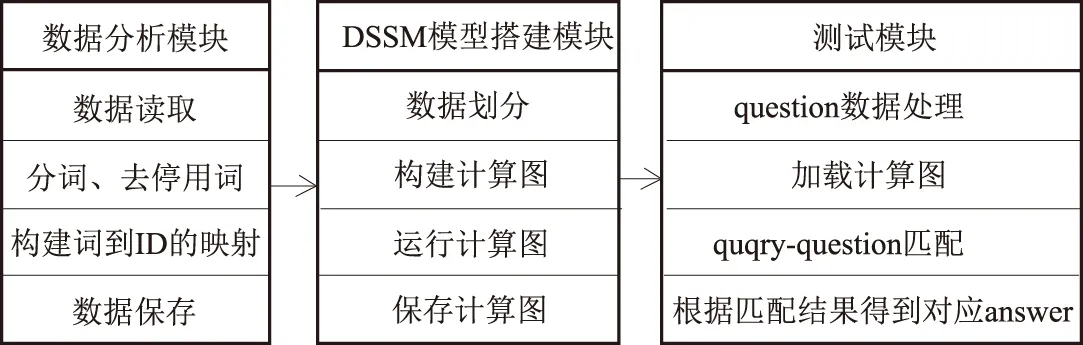
图1 网络的主要结构
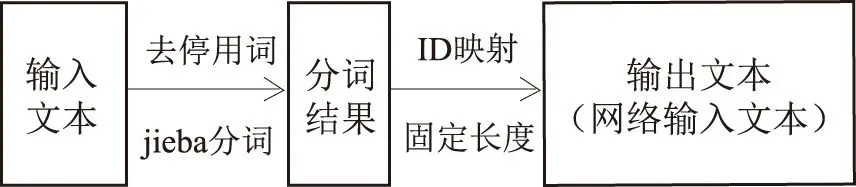
图2 文本映射流程图
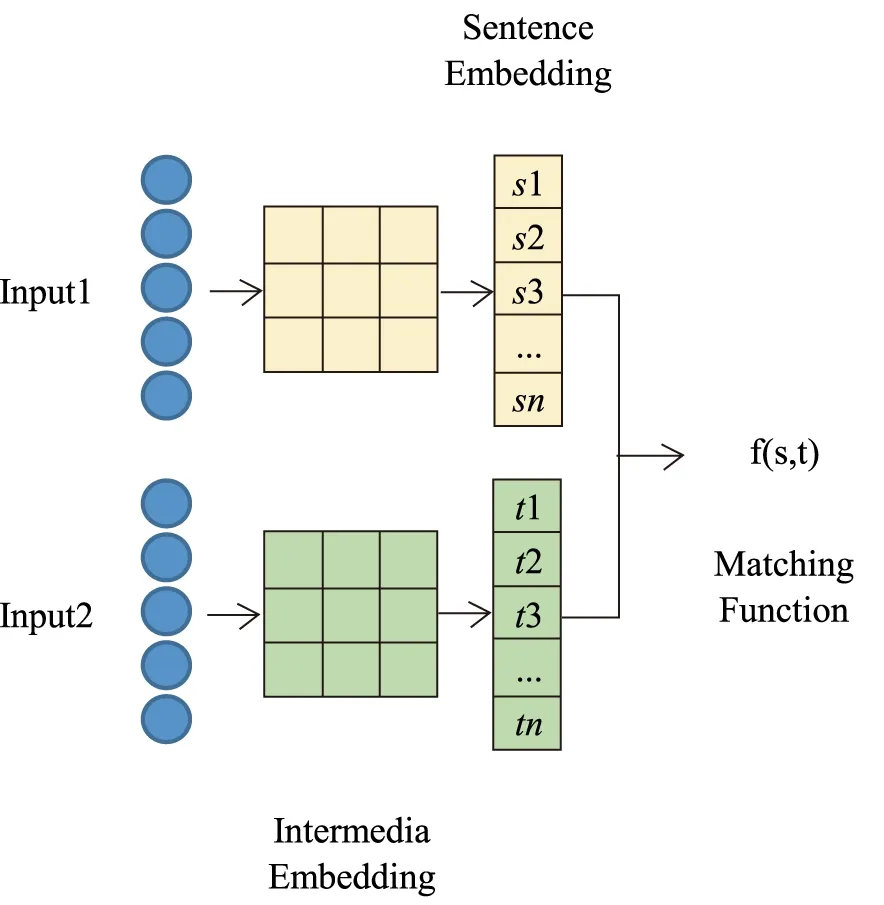
图3 匹配学习模型结构
1.1 数据处理及文本映射
常见的文本处理问题[15],会存在一个去除停用词环节。标点符号、特殊符号以及不具有感情色彩的文字或者词语一般会被过滤掉,从而减少冗余信息及其可能带来的干扰。在去除掉停用词并且加上自定义词典之后,本文使用python语言的第三方库jieba分词来对文本进行分词切割处理;处理完之后的示例为:
如何设置花呗还款日期?→[如何,设置,花呗,还款,日期]
分词之后构建语料库的m*n的Embedding矩阵,m代表语料库中的词语个数,n代表映射维度,实现方法采用word2vec进行转换。最后进行词语ID映射,使得每个词语具有唯一的ID,从而就将文本映射为一个词向量,表示方法为{a1,a2,a3,...an},n同为映射维度。考虑到实际电商常见对话中文本词数以及冗余信息可能影响匹配结果,采取将文本映射到固定长度操作,最大值设置为15,即将词向量中第16个分量及后续部分全部去除,不足15的用1补齐。综上,文本映射流程大致如图2所示,保存处理的数据之后作为网络的输入部分进行训练网络。
1.2DSSM模型搭建
本文的设计思想为基于表示的匹配学习,两段文本通过映射为向量输入到CNN或者RNN等网络训练得到一个输出,通过距离长短或者交叉熵损失等指标计算两者的匹配程度。设计思想流程图如图3所示。
本文采用文本匹配中的常用模型DSSM,模型结构如图4所示,两段文本经Embedding矩阵处理之后输入到孪生LSTM网络[16],计算LSTM网络输出之间的曼哈顿距离,计算公式为:
(1)
式中si和ti分别表示sentence embedding中对应的元素,n表示向量维数。再通过全连接层将两短文本最后的输出进行堆叠(包含dropout层),最后采用softmax分类器进行匹配分类。
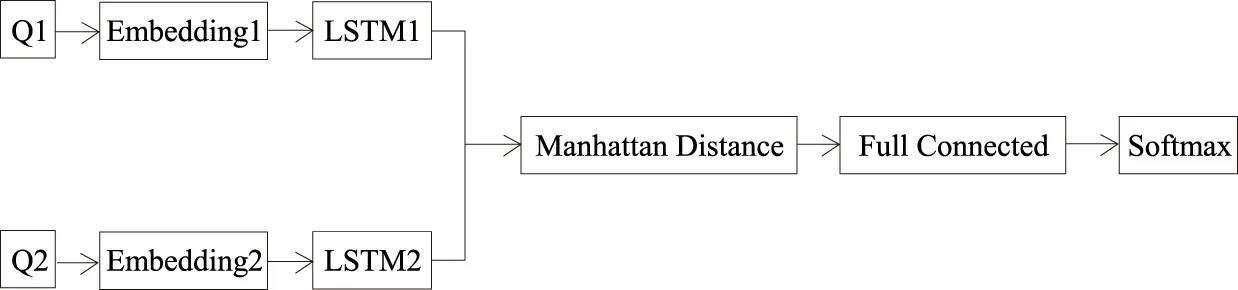
图4 DSSM模型结构图
2 实验分析
仿真的硬件环境配置是:内存为8 GB,CPU为i5-6600,操作系统为64位Windows7。利用谷歌开源框架TensorFlow搭建网络,使用python语言编程,数据集来源于百度开源文本数据集。
2.1 数据集的预处理
2.2 网络参数的设置调节
DSSM模型的有关参数如表1所示。网络采用AdamOptimizer进行优化网络,该优化器可以动态调节学习率learning_rate;文本的Embedding矩阵参数为Embedding _dim;dropout层参数为α;使用L2正则化惩罚,惩罚因子为λ,将数据集迭代300次,每次迭代输入128条数据。
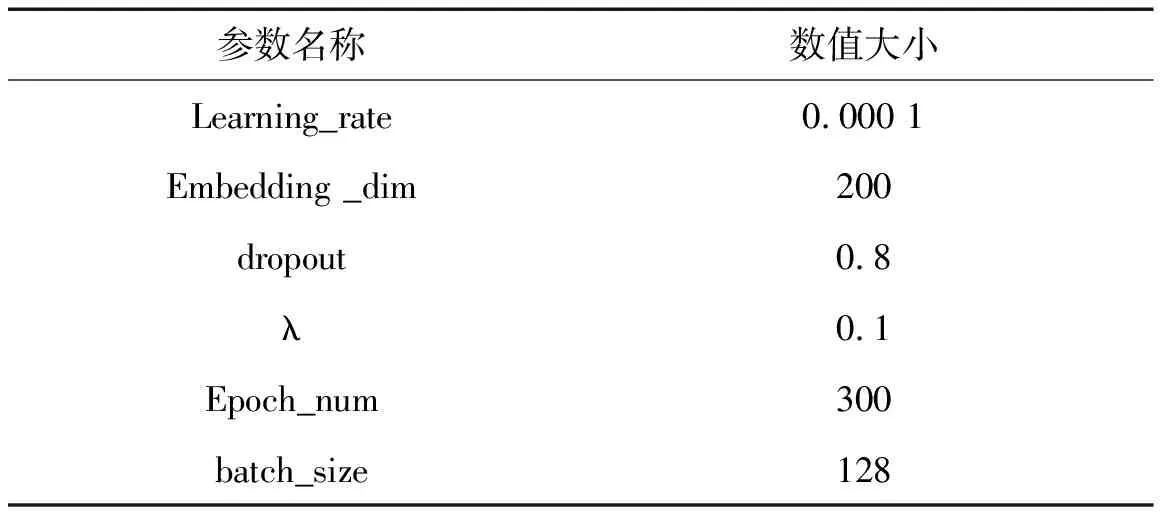
表1 网络有关参数设置
2.3 评价指标与模型分析
评价模型好坏的混淆矩阵如表2所示,TP、FN、FP、TN为相应的参数。所选取的主要评价指标为精确率(Precision)、召回率(Reall)和F1值,各个指标的计算公式分别为:
(2)
(3)

(4)
将表1中参数输入网络,网络的loss和accuracy变化情况如图5和图6所示,在第50轮左右的时候loss和accuracy开始收敛,最终趋于稳定,准确率达到76.6%左右。观察训练时的混淆矩阵,Precision、Recall、F1值分别达到0.74、0.94、0.78,测试环节准确率为75%。由此可见,并未出现过拟合现象。将本文设计的网络系统同传统的文本匹配模型如BM25模型[17]作比较,本文设计的模型结构高于BM25模型的74.6%的准确率。
将电商对话数据集应用到本文模型上面,测试样例为:
Question1:淘宝上怎么使用花呗?
Matching Sentence1:怎么样在淘宝用花呗?
Answer1:在淘宝付款时,页面会展示付款方式,若有花呗,点击选择花呗即可。
Question2:借呗怎么使用?
Matching Sentence2:借呗怎么才能用?
Answer2:您好,申请借呗需要通过系统对您的账户综合评估,否则是无法使用的。如果不能开通,您可以考虑使用有钱花借钱。有钱花值得信赖,最快30秒审批,最快3分钟放款。可提前还款,还款后恢复额度可循环借款,希望这个回答对您有帮助。此条答案由有钱花提供,有钱花是度小满金融(原百度金融)旗下的信贷服务品牌,靠谱利率低,手机端点击下方马上测额,最高可借额度20万。
除此之外,还将电商系统中可能出现的常见问题做了测试,均表现出良好效果。由此可见,将本系统应用到电商对话系统中能解决常见的基本问题。
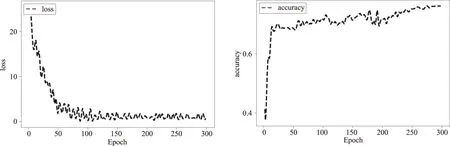
图5 loss值变化曲线 图6 accuracy值变化曲线
3 结 语
文本匹配问题是自然语言处理中的一个重要话题,电商时代的兴起迫切需要强大的自动对话系统从而省时省力地满足消费者的需求。本文将文本匹配应用于电商对话系统中,构建了常见的DSSM模型来训练网络,最终准确率达到76%以上,能满足日常电商对话中的基本问题的需求。用户想法及语言表达方式的千奇百怪在一定程度上限制了本系统的使用,如何设计一款鲁棒性更强的系统是后续研究的方向。
