基于聚类的星系光谱分析*
2020-05-12张健楠赵永恒
张 茜,张健楠,赵永恒
(1. 中国科学院国家天文台,北京 100101;2. 中国科学院大学,北京 100049;3. 中国科学院光学天文重点实验室 (国家天文台),北京 100101)
星系光谱分类对于研究星系的形成与演化具有重要意义。传统星系分类方法包括:基于形态学的哈勃分类法,根据星系外形将星系分为椭圆星系、旋涡星系、棒旋星系和不规则星系;基于颜色的分类法,文[1]分析斯隆数字巡天(Sloan Digital Sky Survey, SDSS)数据时发现颜色星等图服从双峰分布,蓝色星系和红色星系各有峰值,双峰之间为绿谷;基于光谱的BPT诊断图[2]的分类方法,经过多年的改进形成了基于线强比诊断图的分类方法,目前常用的经验分割线有文[3]提出的用于识别纯恒星形成星系(Star-Forming, SF)的分割线,文[4]提出的用于识别纯活动星系核星系的分割线[4],以及文[5]和文[6]分别提出的用于区分低电离核发射线区(Low-Ionization Nuclear Emission-Line Region, LINER)星系和Seyfert2星系的分割线。
大型巡天项目的实施为天文领域提供了海量光谱数据,例如2dF, 6dF, RAVE, SDSS, LAMOST, GAIA等,其中LAMOST DR5发布的星系光谱多达15万余条,必须研究光谱自动分类技术用于大规模光谱数据的分类研究。传统的基于谱线检测或BPT图的星系光谱分类方法需要进行星族成分合成,由于此过程复杂且耗时,不适用于海量光谱数据的处理,无法直接用于光谱自动分类。相比之下,基于机器学习的光谱自动分类方法更适用于海量天文数据的分析研究。目前有许多机器学习方法成功应用于天体分类,包括监督型和无监督型分类方法。无监督型分类方法有主成分分析法,它广泛应用于星系光谱的识别与分类,例如斯隆巡天项目中的光谱处理系统就是利用星系光谱主成分进行识别[7],另外,文[8]成功将k均值方法应用于星系光谱分类,分类结果能很好地体现星系的演化过程。监督型分类方法有许多,例如文[9]使用基于Fisher判别分析的有监督特征提取方法对类星体和正常星系分类,文[10]使用支持向量机方法对活动天体和非活动天体分类。
聚类属于无监督型方法,具有算法简单、收敛速度快和准确率高的特点。聚类主要依赖于数据特征进行自动分类,过程独立且受主观因素影响小,相较于监督型方法,不需要提供已有标签数据进行训练,同时聚类结果中数量较少的簇有助于发现稀有天体。本文针对LAMOST DR5中星系光谱数据,设计了双层聚类方法对星系光谱进行聚类分析。
1 双层聚类方法
针对星系光谱的特点和不同聚类算法的特点,提出了双层聚类方法对星系光谱进行聚类分析。第1层采用k均值聚类算法[11]将星系光谱分为吸收线星系和发射线星系,k均值聚类算法简单,能够快速收敛,对于大数据处理具有伸缩性,适用于大规模星系光谱处理。第2层采用CLARA聚类算法[12]将发射线星系分为5个子类,CLARA算法简单,对噪声不敏感,适用于大规模数据处理。
1.1 k均值聚类算法
k均值(k-means)聚类算法的核心内容是将数量为n的样本划分为k类,并且每个样本点到聚类中心的距离平方和最小。
k-means算法基本步骤如下:
输入:n个样本和聚类个数k。
输出:将样本划分为k类。
(1)从n个样本中选取k个初始点作为初始聚类中心;
(2)计算每个样本点与聚类中心的距离,将样本划分到距离它最近的聚类中心所属的类;
(3)重新计算每一类中所有样本点的平均值作为新的聚类中心,并计算每个样本点到它所在类的聚类中心的距离平方和D;
(4)判断聚类中心和D是否改变,若改变,更新聚类中心后重复(2)、(3)步,否则聚类结束。
影响聚类效果的因素有很多,k值的选取、初始聚类中心的选取方法以及距离度量方法都影响聚类效果。k值的选取方法包括凭经验选取和按密度选取。挑选初始聚类中心常用的方法有4种:(1)随机选取k个样本作为初始聚类中心;(2)随机采用样本空间中10%的数据做预聚类,预聚类的初始聚类中心也是随机挑选的;(3)根据样本的取值范围均匀地随机选取k个聚类中心;(4)考虑权重的k-means++方法,随机选取第1个聚类中心后,计算所有点到聚类中心的距离,将距离作为权重选择下一个聚类中心,目的是使距离大的点被选中的概率更大,然后重复选取k个聚类中心。距离度量方法有欧氏距离、曼哈顿距离、余弦距离和相关距离等。
本文聚类实验中,在考虑光谱的特点并对比多种距离后,选取相关距离作为距离度量方法,相关距离为d=1-ρ,其中ρ为相关系数,用于判断随机变量X与Y的相关程度,其表达式为
(1)
其中,cov(X,Y)为X与Y的协方差;E(X)为X的期望;D(X)为X的方差;ρ取值范围为[-1, 1],绝对值越大,表明X与Y的相关度越高。
1.2 CLARA聚类算法
K-means聚类算法对噪声敏感度高,k中心点(k-medoids)[13]聚类是对k-means的改进,k-means算法更新聚类中心是求取类内平均值,而k-medoids将每个点代替聚类中心,降低离群点对聚类结果的影响。
k-medoids算法基本步骤如下:
输入:n个样本和聚类个数k。
输出:将样本划分为k类。
(1)从n个样本中选取k个初始点作为初始聚类中心;
(2)计算所有样本点到聚类中心的距离,将样本划分到距离最近的聚类中心所在的类;
(3)随机选择一个非聚类中心点,计算此点代替原聚类中心的总代价,重复此步骤直到所有非聚类中心点都被判断过;
(4)判断每个非聚类中心点代替原中心点的总代价,若有小于0的,从中挑选出总代价最小的一个所对应的非聚类中心点,将此点作为新的聚类中心;
(5)重复(3)、(4)步,直到聚类中心点不变,聚类结束。
判断能否用新的非聚类中心点Oh代替原聚类中心点Oi,对于每一个非中心点Oj都要满足如下规则:无论Oj原来属于Oi类还是另一个Om类,当Oh替换Oi后,Oj会分配给距离它最近的类,可以是Oi或Om,也可以是新的类Oh。
新的非聚类中心点Oh代替原聚类中心点Oi的总代价是所有非中心点对象产生的代价之和。计算公式如下:
(2)
其中,Cjih表示Oj在Oi被Oh代替后产生的代价,即Oj到原聚类中心的距离与Oj到新聚类中心的距离之差。若总代价为负,Oi能被Oh替换,若总代价为正,则说明原聚类中心Oi不需要变化。
由于k-medoids聚类算法需要穷举类内点以达到寻找最优解的目的,此方法只适用于小规模数据。CLARA是对k-medoids聚类算法的改进,用抽样样本代表全部数据计算聚类中心,能够应用于大规模数据聚类。
CLARA算法基本步骤如下:
输入:n个样本,聚类个数k,抽样次数m。
输出:将样本划分为k类。
(1)重复m次从全部样本中抽取(40 + 2k)个样本,每次重复执行(2)~(4)步骤;
(2)对此样本集使用k-medoids聚类,选出k个聚类中心;
(3)计算全部样本中每个非聚类中心点到聚类中心的距离,将其划分到距离最近的聚类中心所在的类;
(4)计算(3)步中的总代价,若小于当前值,则此聚类中心作为最佳聚类中心应用于全部样本,否则返回步骤(1),开始下一循环。
2 星系光谱聚类实验
2.1 数据预处理
本文采用的数据是从LAMOST DR5的153 093条星系光谱中随机选取的30 000条光谱。
因为缺少相应的测光设备,LAMOST采用相对流量定标,即选择质量较好的F型矮星作为标准星,得到仪器的响应曲线,但是这些标准星的红化可能导致连续谱的不确定性,因此,需要对光谱进行重定标。本文采用斯隆的u, g, r, i, z波段的petrosian星等,在一定程度上校正LAMOST的连续谱。
重定标之后对光谱进行退红移处理,将其移至静止波长后,对光谱进行重采样,采样波长区间为360~900 nm,采样间隔为0.1 nm。
为降低噪声、环境等因素的影响,需要对光谱进行流量标准化,本文采用Sunit标准化方法。假设x是一条光谱,记为x=(x1,x2,…,xn)T,它是n维欧氏空间中的一个向量,流量标准化方法为[9]
(3)
在去除无法进行重定标和红移为坏值的光谱后,剩余27 272条星系光谱用于聚类实验。
2.2 聚类实验
使用k-means聚类算法和CLARA聚类算法对LAMOST DR5中星系光谱进行聚类。实验分为两层,第1层用k-means将星系光谱分为吸收线星系和发射线星系,第2层用CLARA将发射线星系光谱细分类。
第1层,使用k-means聚类算法,将预处理后的27 272条星系光谱分为发射线星系和吸收线星系。以年老恒星为主的早型星系的光谱以吸收线为主,发射线很弱甚至无法被探测到,相对年轻的晚型星系中有一部分与早型星系相似,发射线很弱,更晚型的星系中吸收线逐渐失去主导地位,发射线越来越明显。为使发射线和吸收线特征更为突出,将光谱去除连续谱。采用中值滤波方法拟合连续谱,用光谱流量减去连续谱得到谱线信息,对谱线信息进行聚类。
考虑到还有同时具有发射线和恒星成分的一类星系,选取k值为3,用k-means++方法获取初始聚类中心,使用相关距离作为距离度量方法。
第2层,使用CLARA聚类算法,将第1层聚类得到的发射线星系再进行细分类。连续谱可以反映一部分发射线星系的特征,因此,这一层聚类不需要去除连续谱。选取r波段信噪比大于5的共12 689条星系光谱,为避免天光线的影响,用中值滤波法去噪,滤波窗口宽度为5。考虑到一部分样本仅在波长为360~790 nm有流量值,且CLARA聚类算法依赖于样本点,所以选择360~790 nm范围内的光谱进行实验。
抽样次数为100,使用相关距离作为距离度量方法。为选取较优的k值,图1是簇内误差平方和随k值变化的曲线,依据肘部法则,在k=5时观察到明显肘型,因此选取k=5。

图1 簇内误差平方和随k值变化图
Fig.1 The graph of SSE changing withkvalue
3 星系光谱聚类结果分析
3.1 第1层聚类结果分析
K-means聚类算法将27 272条星系光谱分为3簇cluster1, cluster2, cluster3,通过每一簇的聚类中心(图2)可以看出其星系类型。发射线星系光谱以发射线为主,cluster1发射线明显,为恒星成分很弱的强发射线星系,吸收线星系光谱的吸收线占主导地位,发射线很弱甚至无法被探测到,由此看出cluster2属于吸收线星系,cluster3发射线弱,为有恒星成分的弱发射线星系。

图2 第1层聚类的聚类中心。(a), (b), (c)分别为cluster1, cluster2和cluster3的聚类中心
Fig.2 The clustering centers of the first layer. The clustering center of cluster1, cluster2and cluster3are shown on (a), (b) and (c)
为探究聚类的稳定性,将k-means聚类方法应用于不同信噪比子集,分别从27 272条星系光谱中取r波段信噪比大于5、10、15、20的4个子集,分别包含23 465、15 593、9 120、5 166条光谱。将k-means用于每个子集,得到的聚类中心见图3,图3中4行图分别为r波段信噪比大于5、10、15、20的4个子集的聚类中心,为了便于比较,将得到的聚类中心分别按发射线星系、吸收线星系和弱发射线星系排列,3列分别为cluster1, cluster2和cluster3簇的聚类中心,mem表示此类所含样本个数,由不同子集的聚类中心都能反映出发射线星系、吸收线星系和弱发射线星系,由图3可以看出,k-means聚类算法能够稳定聚类出这3种星系。

图3 不同信噪比子集的聚类中心。4行由上至下分别为r波段信噪比大于5、10、15、20的4个子集的聚类中心,3列分别为每个子集的3个聚类中心,其中mem表示此类所含光谱数
Fig.3 The clustering centers of differentSNRsubsets. The four rows from top to bottom are the cluster centers of the four subsets with r-band SNR greater than 5, 10, 15, and 20, and the three columns are the three cluster centers of each subset, wherememindicates the number of data in the cluster
计算每一条光谱与每个聚类中心的距离,第i个簇clusteri的每一个样本与第j个聚类中心centerj的距离统计图见图4,其中,3列图分别为3个簇中每一个样本与聚类中心的距离统计图,不同颜色代表不同信噪比的数据集。整体来看,clusteri与其本身的聚类中心距离相较于其他聚类中心更近。由图4中左列可以看出,簇cluster1与center1的距离靠近0,与另两个聚类中心距离远,明显的3个峰表明第1个簇与另两个簇区分度明显。簇cluster2和cluster3在同一信噪比子集下,距离其本身的聚类中心距离更近,如图中第2列cluster2在信噪比大于0时(红色),距离center1-3的统计图峰值分别为1、0.65、0.8。虽然簇cluster2和cluster3与其类内聚类中心的距离分布没有接近0,但是从不同信噪比子集下的距离分布可以看出,随着信噪比的提高,簇cluster2和cluster3与其类内聚类中心的距离越来越靠近0,如cluster2-center2图中,随着信噪比的提高,峰值从0.65降至0.4。
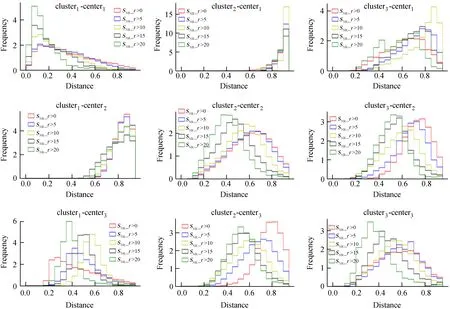
图4 第1层聚类簇与聚类中心的距离统计图。图为第i个簇clusteri的每一个样本与第j个聚类中心centerj的距离统计图,颜色表示不同信噪比的数据集
Fig.4 The distance statistical graph of the clusters and the cluster centers of the first layer. The figure shows the distance statistics of each sample of thei-th cluster clusteriand thej-th cluster center centerj, and the colors represent different signal-to-noise ratio data sets
每个样本与聚类中心相关距离分布代表着类内距离分布,类内光谱的叠加得到的聚类中心信噪比提高,与相对信噪比较低的样本数据的相关性达不到1,所以,cluster2-cneter2和cluster3-center3的距离分布没有接近0。从这个分布情况也可以看出,cluster2和cluster3的类内分布不够紧致。
将此聚类结果与传统分类方法的结果进行比较。传统的区分吸收线星系和发射线星系常使用S/Nλ≥3作为判断依据,这里S/Nλ为谱线λ的信噪比。文[3-4]筛选发射线星系对Hα,Hβ,[O III]λ5007和[N II]λ6585 4条谱线都采用S/Nλ≥3的筛选条件,但文[6]发现,对4条谱线都进行筛选会使一些弱发射线星系被忽略,所以本文只对Hα进行筛选。
聚类结果中cluster1和cluster3为发射线星系,cluster2为吸收线星系,与用Hα分类的结果进行比较(表1),聚类结果与用Hα分类的结果一致的数目在聚类每一类中的占比分别为97.79%、80.80%、84.52%。对于全部数据,k-means聚类结果中有89.0%的星系与Hα分类结果一致。

表1 k-means聚类结果与Hα筛选结果数目比较
每个簇的光谱颜色星等图见图5,黄色散点为全部光谱样本分布,黑色散点为每一簇中光谱的分布。颜色星等图服从双峰分布,两端分布为红色和蓝色部分,过渡区为绿谷,可以明显看出发射线星系cluster1分布在蓝色区域,吸收线星系cluster2分布在红色区域,具有弱发射线的cluster3分布在绿谷,这符合早型星系大多为红色,晚型星系大多为蓝色的基本规律。
图5 第1层聚类结果的颜色星等图。(a), (b), (c)分别为cluster1, cluster2和cluster3的颜色星等图,其中黄色散点为全部光谱样本,黑色散点为每一类光谱样本
Fig.5 Plots of u-g vs. g-r of the first layer of clustering. The plots of u-g vs. g-r of cluster1, cluster2and cluster3are shown on the left, middle and right. The yellow scatter points is the whole spectral samples and the black scatter points is the spectrum of each class
由实验结果可以看出,k-means聚类算法可以快速高效地将星系光谱聚类为吸收线星系和发射线星系,对于大规模数据,k-means聚类也能快速收敛,聚类结果能够体现星系的物理性质,与传统的分类结果基本一致,因此,k-means聚类方法对星系分类是可行的,聚类中心可以为星系自动分类系统提供模板,与基于谱线分析得到的高信噪比模板相比,此模板抗噪性更强。
3.2 第2层聚类结果分析
用CLARA聚类将第1层聚类中的发射线星系分为emi1-emi5共5个子类,其数目及类型见表2,其聚类中心是类内的一条光谱(图6第1列)。
与第1层聚类相同,计算每一条光谱与每个聚类中心的距离,得到第i个簇clusteri的每一个样本与第j个聚类中心centerj的距离统计图,结果表明,每个簇到其聚类中心最近,接近于0,到其他聚类中心相对较远,每个簇对5个聚类中心的距离统计图都有5个明显峰值,可以表明类间区分度明显。

表2 第2层聚类结果
聚类结果与BPT图分类相比较,用BPT分类法求每一类中每条光谱的类型。BPT图分类方法基于线强比,需要测量Hα,Hβ,[O III]λ5007和[N II]λ6585 4条谱线的线强。普遍认为星系光谱是由多种恒星光谱组合而成,首先用星族分析软件STARLIGHT拟合星系光谱中的恒星成分,之后用原星系光谱减去拟合谱,得到包含发射线、噪声和低频背景成分的光谱,然后用窗口宽度为201的中值滤波去除低频背景成分,最后分别使用单高斯拟合Hβ和[O III]λ5007线,用多高斯拟合[N II]λ6548、Hα、[N II]λ6585 3条谱线,利用(4)式计算线强,其中λ1和λ2为谱线对应波长的两端点,FI(λ)为观测流量,FC(λ)为连续谱。
(4)
由于星族成分合成过程对光谱质量要求较高和部分发射线太弱导致无法高斯拟合等问题,仅有8 122条发射线星系光谱用BPT方法求得其类型,emi1-emi5对应BPT分类结果见表3。将每一类结果在BPT图中表示(图6中列),其中,背景密度图是所有发射线星系的BPT图分布,红色散点是每一类中所有光谱在BPT图中对应的点。
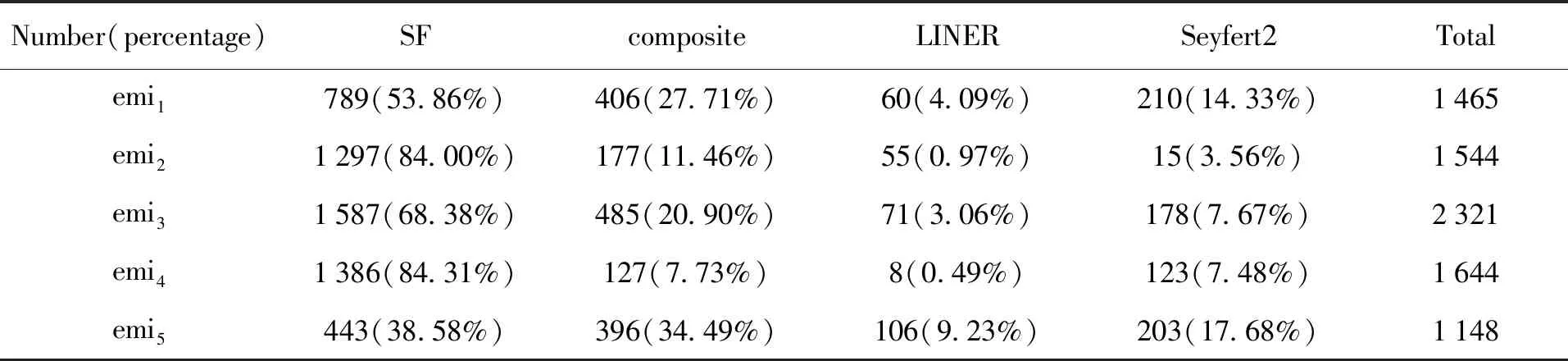
表3 第2层聚类结果与BPT图分类法的结果比较
图6第2列BPT图中,红色的经验分割线为文[3]提出的纯恒星形成星系分割线,简称K03(公式5),此线以下为恒星形成星系。蓝色分割线为文[4]提出的纯活动星系核分割线,简称K01(公式6),此线以上为活动星系核,混合型星系位于K03与K01分割线之间。绿色分割线为文[6]提出的用于区分Seyfert2和LINER的分割线,简称CF10(公式7),此线以上为Seyfert2星系,以下为LINER星系。
log10([O III]/Hβ)=0.61/[log10([N III]/Hα)-0.05]+1.3 ,
(5)
log10([O III]/Hβ)=0.61/[log10([N III]/Hα)-0.47]+1.19 ,
(6)
log10([O III]/Hβ)=0.01log10([N III]/Hα)+0.48 .
(7)
从聚类结果的BPT图和表3中各类星系的数量可以看出,emi1大部分分布在K01分割线之下,包括恒星形成星系和混合型星系;emi2大部分在K03分割线之下,有84.00%光谱为恒星形成星系;emi3与第1类相似,大部分为恒星形成星系,包含少量活动星系核;emi4位于K03分割线之下,有84.31%的光谱为恒星形成星系,不同于第2类,emi4的[O III]λ5007与Hβ的线强比偏大,对应聚类中心光谱,emi4相较emi2发射线更强,连续谱更平缓,吸收线成分更弱;emi5中有61.42%的星系为复合型星系和活动星系核,与emi2和emi4这两类恒星形成星系相比,emi5的聚类中心光谱的恒星成分占主导地位,发射线很弱,而emi2和emi4的聚类中心中发射线很强,占主导地位。整体来看恒星成分越少,发射线越强,星系在BPT图中分布越偏向于恒星形成星系,这符合恒星形成星系的特点,这类星系具有大量恒星形成区,能够观测到来自中央区域的强窄发射线,这在emi2和emi4的聚类中心光谱中也有所体现。
画出聚类结果的颜色星等图(图6第3列),黄色散点是包括吸收线星系在内的所有星系光谱对应的颜色星等图,黑色散点是第2层聚类中每一类对应的颜色星等图。从emi2和emi4可以看出SF更偏向于蓝色,且发射线越强颜色越蓝,emi1和emi3属于绿谷,emi5更偏向于红色,这与目前提出的活动星系核更可能为早型星系的观点[11]一致。同时,从emi2,emi4到emi1,emi3最后到emi5,随着活动星系核数量的增加,在颜色星等图上反映出从蓝色到红色的变化过程,这与文[14]提出的活动星系核活动抑制了恒星的形成,因此,与它可能是星系颜色穿越绿谷的原因这一观点一致。
BPT图分类方法步骤复杂,对光谱质量要求高,实验第2层中发射线星系能全部被CLARA算法划分,而BPT图只能分类出其中的一大部分,由此可以看出CLARA算法的优越性。CLARA算法对光谱质量要求低,不需要拟合恒星成分,方法简单有效,针对大规模星系光谱能够快速有效分类,适用于大规模数据自动分析处理,同时分类结果能够很好地反映星系的演化过程。

图6 第2层聚类的聚类中心、BPT图和颜色星等图。(a), (b), (c)列分别为聚类中心、BPT图和颜色星等图,1~5行分别为emi1-emi5类。BPT图中黑色背景密度图为全部发射线星系样本分布,红色散点为每一类的光谱样本,颜色星等图中黄色散点为全部光谱样本,黑色散点为每一类光谱样本
Fig.6 The clustering centers, u-g vs. g-r plots and BPT diagram of the second layer of clustering.The left, middle, right column are clustering centers, BPT diagram and u-g vs. g-r plots, and lines 1-5 are emi1-emi5. In the PBT diagram, the black background density map shows the sample distribution of all emission line galaxies, and the red scatter points is sample distribution of emi1-emi5. In the u-g vs. g-r plots, the yellow scatter points is the whole spectral samples and the black scatter points is the spectrum of each class
4 结 论
针对LAMOST DR5星系光谱数据,使用k-means聚类算法成功将星系光谱分为吸收线星系和发射线星系,与基于谱线检测的分类结果基本一致。k-means聚类算法简单高效,适用于大规模星系光谱自动分析处理,聚类结果能够很好地反映星系的性质,与传统分类结果基本一致,因此,聚类方法对星系分类是可行的,聚类中心能够为星系光谱自动分类提供3种类型模板,相较于基于谱线分析得到的高信噪比模板,聚类中心作为模板抗噪性更强。
使用CLARA聚类算法将发射线星系细分类,结果与BPT图分类和颜色星等图分类结果存在预期的相关性,能够反映星系的演化过程。CLARA聚类算法对光谱质量要求较低,不需要拟合恒星成分,方法简单有效,能够直接依据谱线特征实现自动聚类,适用于大规模数据自动分析处理,能够为光谱自动分类提供模板。
致谢:郭守敬望远镜(大天区面积多目标光纤光谱望远镜, LAMOST)是中国科学院建设的国家重大科学项目。该项目由国家发展和改革委员会提供资金。LAMOST由中国科学院国家天文台运营和管理。
