基于社区居民健康大数据预测高血压的患病风险
2020-05-11周阳王妮黄艳群
周阳 王妮 黄艳群

摘要:目的 利用居民健康大數据预测高血压的患病风险,并分析高血压相关的重要因素。方法 基于社区公共卫生系统数据集,利用机器学习中的Logistic回归、随机森林和支持向量机算法建立高血压患病风险预测模型,并比较三者的预测性能,另通过随机森林中的基尼系数下降法分析高血压患病的影响因素。结果 支持向量机模型的准确率(87.00%)、精确率(85.00%)、召回率(88.00%)、F1值(0.88)和ROC曲线下面积(0.932)优于随机森林模型(85.00%、84.00%、87.00%、0.87和0.929)和Logistic回归模型(83.00%、85.00%、81.00%、0.81和0.920)。Gini系数分析显示,冠心病、年龄、糖尿病和教育水平在预测高血压患病风险中具有重要作用;现教育水平、职业类型、其他慢病、婚姻情况、体重指数、父亲患有高血压、母亲患有高血压、饮酒、饮食偏咸、吸烟、锻炼在预测高血压患病风险中具有一般作用;性别、饮食偏素、饮食偏甜、饮食偏油、饮食偏辣在预测高血压患病风险中作用不大。结论 支持向量机预测模型的预测高血压患病风险最优。文化程度低、合并患有冠心病、糖尿病和其他慢病、有家族史和老年人为高血压易患人群,针对此类人群应重点关注体重指数、饮酒和饮食习惯(偏咸)方面。
关键词:高血压;机器学习;社区居民健康档案;基尼系数下降法
中图分类号:R544.1 文献标识码:A DOI:10.3969/j.issn.1006-1959.2020.06.001
文章编号:1006-1959(2020)06-0001-05
Abstract:Objective To predict the risk of hypertension by using big data of residents' health and analyze the important factors related to hypertension. Methods Based on the data set of community public health system, using Logistic regression, random forest, and support vector machine algorithms in machine learning to establish a prediction model for the risk of hypertension, and compare the prediction performance of the three models; In addition, the influencing factors of hypertension were analyzed by Gini coefficient decline method in random forest. Results SVM model's accuracy (87.00%), accuracy (85.00%), recall (88.00%), F1 value (0.88), and area under the ROC curve (0.932) are better than the random forest model (85.00%, 84.00%, 87.00%, 0.87, and 0.929) and Logistic regression models (83.00%, 85.00%, 81.00%, 0.81, and 0.920). Coronary heart disease, age, diabetes, and education level play an important role in predicting the risk of hypertension; current education level, occupation type, other chronic diseases, marital status, body mass index, father with hypertension, mother with hypertension, drinking, eating a salty diet, smoking, and exercising have a general role in predicting the risk of hypertension. Gender, diet, vegan, sweet, oil, and spicy diets have little effect on predicting the risk of hypertension. Conclusion The support vector machine prediction model is the best predictor of the risk of hypertension. People with low education level, co-existing coronary heart disease, diabetes and other chronic diseases, family history, and the elderly are susceptible to hypertension. Targeting this group of people should focus on body mass index, drinking, and eating habits (salty).
Key words:Hypertension;Machine learning;Community health records;Gini coefficient decline method
根据中国高血压防治指南[1](简称指南),我国高血压患病率呈不断升高的趋势,特别是血压值处于130~139/80~89 mmHg的人群极易进展为高血压。高血压主要分为没有明确发病原因的继发性高血压和原发性高血压,其中后者占发病人群的95%[1]。流行病学研究认为[2],我国的高血压发病主要受高钠低钾饮食、超重与肥胖、过度饮酒和长期精神紧张有关,且在更年期前男性发病率高于女性,更年期后女性发病率高于男性。本文利用健康大数据对以上问题进行分析,采用机器学习算法建立高血压患病风险模型,为医生诊断和居民保健提供参考依据,并进一步通过特征的重要性分析高血压的重要影响因素,现报道如下。
1材料与方法
1.1数据预处理 通过石景山区卫生信息平台选取2018年1月~12月约20万份北京市石景山区居民健康档案,提取居民的年龄、性别、身高、体重、血型、患病情况、文化程度、职业、婚姻状况、药物过敏、暴露史、亲属病史、残疾情况、是否吸烟、是否饮酒、是否锻炼、睡眠状况、饮食习惯等方面的101个特征变量进行描述。所有特征只保留一个重复变量,排除意义不明变量、出现频率小于5%的变量。最终保留了20个特征变量:年龄、性别、糖尿病、冠心病、其他慢病、受教育水平(按照受学历教育的年限划分)、职业类型(分为国家机关、党群组织、企业、事业单位负责人,专业技术人员,办事人员和有关人员,商业、服务业人员,农、林、牧、渔、水利业生产人员,生产、运输设备操作人员及有关人员,军人,学生,其他)、婚姻状况(未婚、已婚、丧偶、离异、未说明的婚姻状况)、父亲是否患有高血压、母亲是否患有高血压、是否吸烟、是否饮酒、是否锻炼身体、饮食是否偏甜、饮食是否偏咸、饮食是否偏油、是否素食、饮食是否偏辣、体重指数(body mass index,BMI)。
1.2预测模型算法及评价
1.2.1 Logistic回归模型 将21个潜在的影响因素(如年龄、性别等)作为模型的自变量,是否患高血压作为因变量,模型的输出即某人患高血压的概率。以0.5为概率分界点,若模型的输出概率>0.5,则判为患高血压。
1.2.2随机森林 利用随机森林(random forest,RF)预测高血压的患病风险,另通过增加随机噪声,利用平均基尼系数(Giniindex,GI)下降程度衡量单个输入变量(特征)对预测结局的重要性,GI下降越多说明相应变量越重要[3]。将所有样本的结局分为两类,即患高血压和不患高血压,特征j在决策树节点m中的重要性,即节点m分枝前后GI的化量,其中节点m的GIm定义为:
其中pm1和pm2分别为节点m中第一类和第二类样本所占比例,特征j在随机森林中所有决策树的所有节点中的重要性之和经过归一化后,即为特征j基于Gini系数的重要性。
1.2.3支持向量机 采用支持向量机(support vector machine,SVM)常用的高斯核函数进行分析:
k(x,y)=exp(-x-y2/2×σ2)(2)
1.2.4模型性能的评价 预测模型的性能评价指标主要有准确率、精确率、召回率、F1值和ROC曲线下面积。在二分类问题下,一个预测可能产生4种不同的结果,即真阳性(true positive,TP)、真阴性(true negative,TN)、假阳性(false positive,FP)和假阴性(false negative,FN)。4种评价指标的计算方法如下:准确率:Acc=(TP+TN)/(TP+TN+FP+FN);精确率:Precision=TP/(TP+FP);召回率:Recall=TP/(TP+FN);F1值:F1=2Precision×Recall/(Precision+Recall)。利用ROC曲线下面积[4]综合评价预测模型的性能。
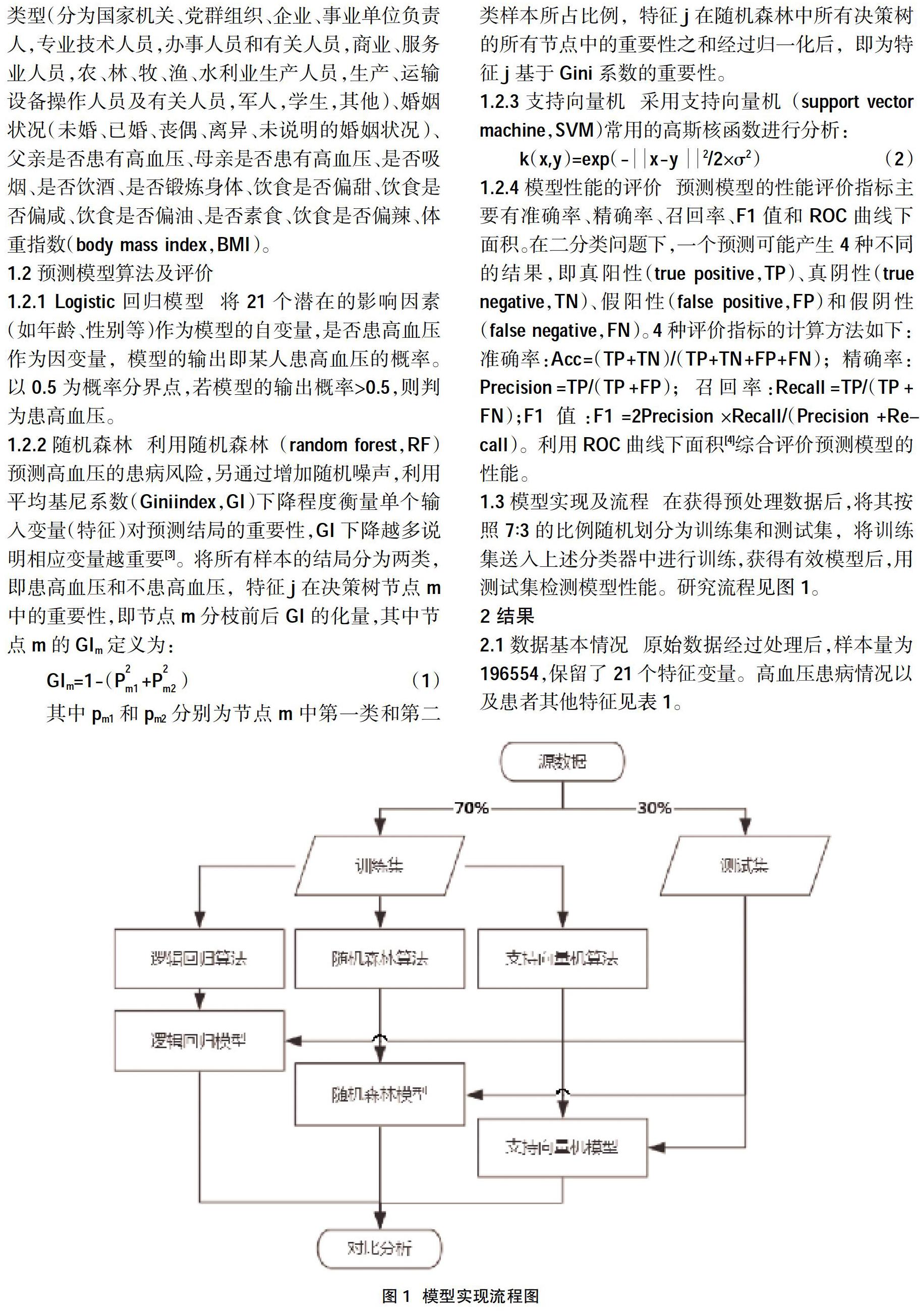
1.3模型实现及流程 在获得预处理数据后,将其按照7∶3的比例随机划分为训练集和测试集,将训练集送入上述分类器中进行训练,获得有效模型后,用测试集检测模型性能。研究流程见图1。
2结果
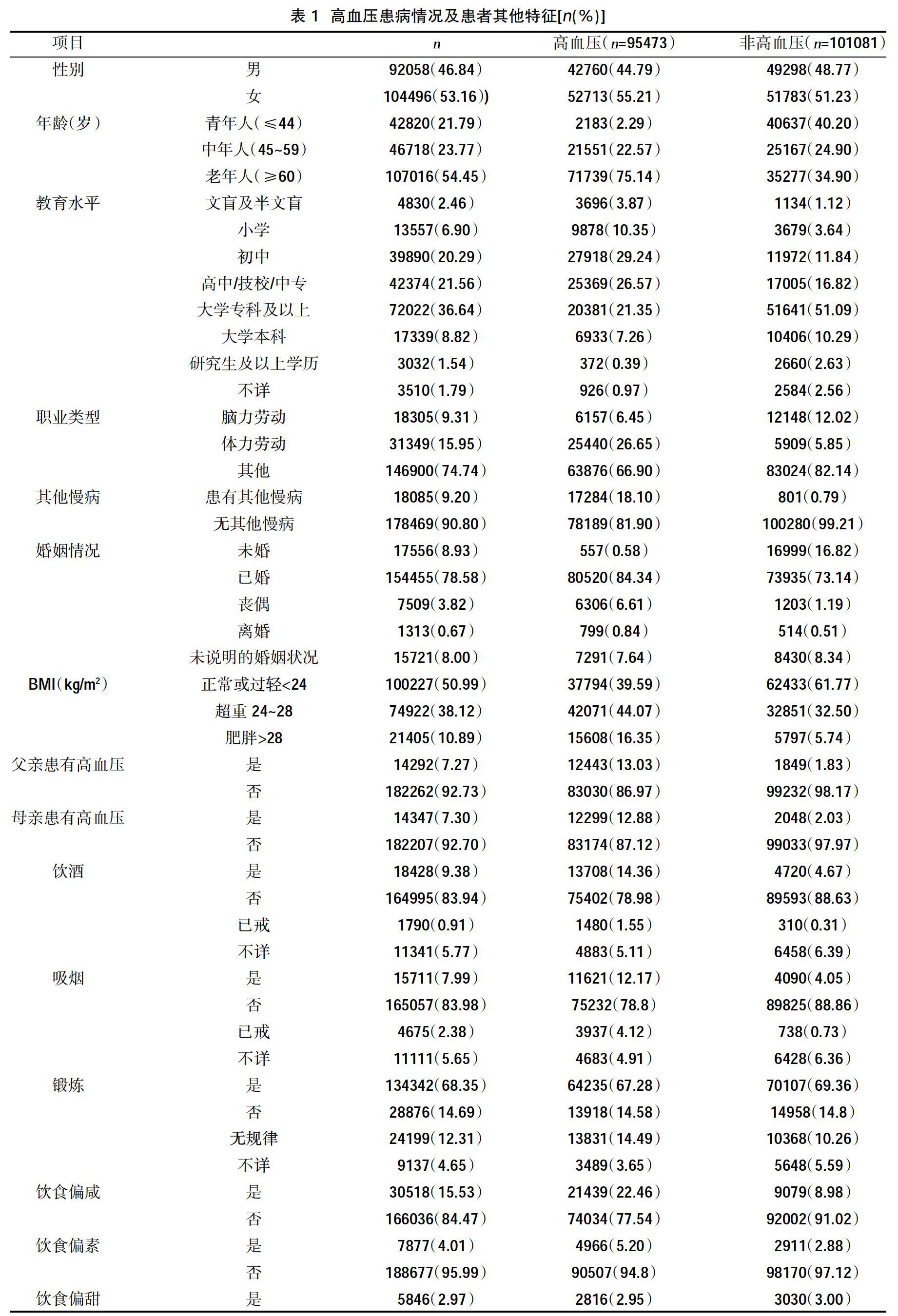
2.1数据基本情况 原始数据经过处理后,样本量为196554,保留了21个特征变量。高血压患病情况以及患者其他特征见表1。
数据进行疾病预测研究的价值。随机森林是一种基于决策树的集成学习算法,它将多棵决策树组合起来,因此性能通常优于单棵决策树。连巧龄等[9]利用决策树模型探究社区老年人高血压患病状况及其影响因素,结果显示决策树预测类别与实际类别的符合率为74.0%,灵敏度为71.8%,特异度为78.3%,ROC曲线下的面积为0.750。本研究中随机森林的预测模型的符合率为85.00%,ROC曲线下面积达0.929。支持向量机模型是一种统计学习模型,适用于高维特征空间的分类问题。本研究中支持向量机模型的准确率可达87.00%,ROC曲线下面积达0.932,高于随机森林和Logistic回归模型,表现出了优异的预测性能。由此可知,患病风险的预测效果与采用模型有关,特别是针对大规模医疗健康数据,选择适用于具体预测任务的预测模型至关重要。
郭明贤等[10]研究发现,农村老年原发性高血压的发生与超重、高盐饮食、慢性病、文化程度等可控制因素密切相關,也与家族遗传不可控制因素相关。杨静等[8]研究发现,老年人群BMI、腰围、腰高比、内脏脂肪指数和身体圆润指数水平增加会提高高血压发病风险。连巧龄等[9]研究发现,肥胖、腹型肥胖、月收入3000元以上、吸烟、饮酒、不参与锻炼、嗜咸饮食、A型性格、有高血压家族史是福州市社区老年人群高血压患病的危险因素。本研究利用随机森林模型中的基尼系数计算特征的重要性,结果显示冠心病、年龄、糖尿病和教育水平在预测高血压患病风险中具有重要作用;现教育水平、职业类型、其他慢病、婚姻情况、体重指数、父亲患有高血压、母亲患有高血压、饮酒、饮食偏咸、吸烟、锻炼在预测高血压患病风险中具有一般作用;性别、饮食偏素、饮食偏甜、饮食偏油、饮食偏辣在预测高血压患病风险中作用不大,可见文化程度低、合并冠心病、糖尿病和其他慢病、有家族史和老年人为高血压易患人群,应提醒患者及家属和医护人员在BMI、饮酒和饮食习惯(偏咸)方面加以注意和控制。
综上所述,基于支持向量机的预测模型的性能最为优异,此外文化程度低、合并患有冠心病、糖尿病和其他慢病、有家族史和老年人为高血压易患人群,针对此类人群应重点关注体重指数、饮酒和饮食习惯(偏咸)方面。
参考文献:
[1]中国高血压防治指南修订委员会,高血压联盟(中国),中华医学会心血管病学分会中国医师协会高血压专业委员会, 等.中国高血压防治指南( 2018年修订版)[J].中国心血管杂志,2019,24(1):24-56.
[2]王鸿.原发性高血压的病因研究进展[J].中国医药指南,2014(21):85-86.
[3]黎成.基于随机森林和ReliefF的致病SNP识别方法[D].西安电子科技大学,2014.
[4]邹忠兰,张爱华,杨敬源,等.肝生化指标在燃煤型砷中毒中诊断价值ROC曲线评价[J].中国公共卫生,2016,32(6):861-865.
[5]刘阳,孙华东,张艳荣,等.基于支持向量机的糖尿病预测模型研究[J].哈尔滨商业大学学报(自然科学版),2018,34(1):61-65.
[6]白江梁,张超彦,李伟,等.某医院体检人群糖尿病预测模型研究[J].实用预防医学,2018,25(1):116-119.
[7]孙涛,徐秀林.基于机器学习的医疗大数据分析与临床应用[J].软件导刊,2019(11):1-5.
[8]杨静,王飞,韩煦,等.人体测量学指标与老年人群高血压发病风险的前瞻性队列研究[J].中华预防医学杂志,2019,53(3):272-278.
[9]连巧龄.基因与环境因素对社区老年人原发性高血压患病状况及控制的影响[D].福建医科大学,2015.
[10]郭明贤,周亚东,张桂红.陕西农村老年高血压病的患病率与危险因素分析[J].心脑血管病防治,2015,15(4):309-311.
收稿日期:2019-12-19;修回日期:2020-01-22
编辑/杜帆
