基于外部ID的中文实体对齐分析*
——以中国科学院院士Wikidata数据子集为例
2020-05-11王瑞云贾君枝
王瑞云 贾君枝
命名实体识别是人工智能自然语言处理领域的一项重要的基础研究,主要任务是识别出文本中的人名、地名和机构名[1,2]。而中文命名实体的识别比其他语言更为困难,近年有研究者利用最新的深度学习技术解决命名实体识别问题,采用深度学习框架和神经网络结构实现了命名实体特征的自动学习[3-5]。深度学习虽然能够高效地学习多粒度语言单元间复杂的语义关联,但对自然语言的深度理解亟需复杂知识的支持,需要实现从字面意思到言外之意的跃迁。
命名实体对齐是把自然语言文本中识别出来的实体与现有知识库的实体进行匹配,包括两个方面:一是识别不同来源同一名称的实体是否为实际语义上的同一个实体,二是识别有哪些不同的名称实体实际指代同一实体。2014年开始在线运行的国际图书馆合作项目——虚拟国际规范档(VIAF),在多个国家图书馆之间实现了上述两方面的实体对齐工作。中国国家图书馆(NLC)和中国高等教育文献保障系统(CALIS)管理中心开展的名称规范档项目,已经实现在规范档记录内部对同一实体不同名称的聚集,但是还缺乏不同知识库间同名规范记录的实体对齐,且聚簇深层实体对齐需要领域知识的支持。基于实体属性关系构建知识图谱是当前实体对齐中的重要解决方案,已有一些重要成果投入应用,如维基百科(Wikipedia)、维基数据(Wikidata)和关联开放数据云(LOD)等。国外研究者利用Wikipedia的海量数据构建自动抽取的语料库,并利用其中的多语言知识映射来提高跨语言命名实体识别效果[6,7]。实体对齐技术包括基于文本相似度的对齐和基于关联数据语义的对齐,基于关联数据语义的实体对齐包括实体模式对齐和实例对齐两个层次。贾君枝等学者基于词表映射方法研究知识库间实体类和属性的实体模式层的对齐[8,9]。刘晓娟等构造基于DBPedia的中英文命名实体词典,利用关联数据的语义关系对候选命名实体进行对齐[10]。Qingheng Zhang等学者基于知识图谱嵌入技术研究跨知识图谱间的实体对齐,改进传统知识图谱嵌入框架,在典型数据集Dbpedia、Wikidata和Yago上进行实验验证[11]。贾君枝和Lingbing Guo等学者分别利用LOD中跨知识库的OWL:Sameas关系研究跨知识库的实体对齐[12,13]。上述跨知识库间实体对齐研究都采用了100,000对以上的实体对进行对齐,但是研究的实体大部分是英文命名实体;而本文实体对齐研究的实体限制为中文学术命名实体这一实体子集,旨在建立和完善中文知识库实体与外部知识库实体的对齐。
对中文命名实体的跨知识库实体对齐的研究还处于起步阶段,很多中文权威网站(如中国科学院官网、国家自然科学基金委员会官网等)处于“孤岛”的状态,关联数据发布应用还不充分,大量的实体语义知识掩藏在海量的异构文本中。这不利于机器理解和自动抽取,不方便外部知识库链入对齐。同时,中文网站也没有主动与外部知识库进行实体对齐,外文知识库对中文知识库的实体对齐占比极低,这些不足成为中文命名实体对齐研究的弱项。本文利用RDF自动查询工具SPARQL从Wikidata抽取中国科学院院士(个人实体的子类——顶层学者)的语义信息,在院士实例的细粒度层次,利用Wikidata现有的中文学者的关系链,初步构建中文院士实体到Wikidata的跨知识库的实体对齐;然后利用Wikidata给出实体的外部ID,扩充构建中文实体与外部ID所属的知识库间的实体对齐;最后重点利用实体的外部ID特征及其相关特征的关系,尤其是院士与VIAF中实体对齐的关系,构建中文命名实体院士到VIAF的实体对齐,以期为中文学术领域命名实体知识库的构建以及中文命名实体跨知识库实体对齐提供参考方法。
1 基于码属性的实体语义表示
码属性引用了关系数据库的相关概念,是能唯一地标识一个实体的属性集。很多知识库为内部的每个实体分配一个永久ID作为该实体的码属性,可以在知识库内部唯一地标识这个实体,该ID称为实体的内部ID。在跨知识库实体对齐时,该ID称为引用知识库实体的外部ID。
1.1 外部ID 的起源与发展
外部ID对应知识库中的内部ID。内部ID是知识库为每个实例分配的内部唯一标识符,相当于数据库中能唯一区别实体的码,在知识库内部能唯一地确定一个实体。内部ID与知识库的机构域名、路径一起定义该实体的统一资源识别符URI。例如,华罗庚院士在Wikidata的内部ID 为Q590111,维基数据永久域名为https://www.wikidata.org,存放实体类资源的路径entity,构成维基数据华罗庚URI为https://www.wikidata.org/entity/Q590111。其他知识库如VIAF等也采用同样的URI定义实体资源。在此基础上,跨知识库实体对齐时,外部用户和合作伙伴可以根据知识库内部ID自动构建引用该实例资源的URI,方便外部知识库的实体对齐和实体引用。
外部ID(维基数据中称External-ID)是语义网关联数据技术的应用要求和发展成果。关联数据最高级标准要求,在RDF中尽可能提供到可用外部知识库实体ID的链接[14]。外部ID是内部ID经过实体对齐函数的映射结果,是内部ID代表的实体在外部知识库中对应实体的ID。实际的同一实体在对齐的两个知识库之间形成对应的ID对(内部ID、外部ID),相当于RDF三元组(内部ID TheSameAS 外部ID)。如果知识库在每个实体RDF陈述三元组中给出该实体在外部知识库中的ID(本文中的外部ID就是此种用法),以及外部知识库固定的域名路径,就可以自动构造出外部知识库中实体的URI。外部ID是知识库的构建者(或委托的第三方)根据知识库内部海量知识和底层的本体逻辑关系,实时运行实体对齐算法后提供的实体实例级对齐运算结果,实体外部ID是知识库实体对齐的最重要信息。
基于内部ID和外部ID的属性应用促进了知识库间的实体对齐和互操作。首先,知识库中基于ID的实例URI定义格式与传统URI定义相比,更加持续和稳定,同时使用固定域名路径和ID的组合URI命名方式,更方便外部知识库进行引用;其次,知识库可以更好地参加知识库间协作项目,进行实时的知识库间实体对齐计算;最后,有利于采用RDF语法描述并发布实体实例与外部知识库外部ID的实例对齐结果。目前提供外部ID实体对齐的知识库主要有VIAF、Wikidata和LOD等。
1.2 国内外知识库实体语义表示的比较
关于本文研究的中国科学院院士数据的来源,国内本地知识库使用的是中国科学院官网、百度百科的中国科学院院士分类子集。这两个国内知识库在院士资源的权威性、正确性和更新的及时性方面与国外知识库相比有相当大的优势,但是在基于语义网的知识表示方面与国外知识库Wikidata存在一定的差距,具体如表1所示。
表1 国内外三个知识库语义表示的比较

中国科学院官网百度百科Wikidata权威性最高较高(源于官网+自有信息+用户编辑贡献)较高(源于集成的Wikipedia多种语言站点+用户编辑贡献)语言简体中文简体中文多语言,大部分包含简体中文标签用户应用登录,3—4层目录超链接,不提供用户服务的工具1.按实体名称检索2.中科院院士列表超链接1.按名称检索2.按ID检索3.SPARQL检索知识表示HTMLHTML以RDF 为基础的多种数据表示结构化无结构化半结构化结构化实体识别文本,无实体识别多类型的实体识别,内部ID基于本体层次类的实体识别,内部全局实体ID实体对齐无内部ID,无外部ID无对齐的外部实体ID有实体对齐的外部ID
中国科学院官网是院士信息的权威来源机构,在权威性、及时性方面有其他两个来源数据不可比拟的优势,是其他来源数据的参考来源和最终的验证标准。但是其知识表示没有采用先进的语义网技术,有着“数据孤岛”的局限。中国科学院官网中的院士信息访问是逐层超链接的:首页->院士->学部->院士列表->单个院士信息[15]。单个院士页面包括URI、照片图像、个人简介文本三部分。个人简介描述是全文本,没有进行实体识别表示和实体对齐。
百度百科知识库整体上采用维基技术,提供两种查询应用方式:一是查询“中国科学院”机构实体,在内容网页找到分学部的院士姓名列表并连接到个人实体资源;二是直接按院士个人姓名查询个人主页。每个个人实体资源以个人姓名作为内部ID,增加域名路径构建。如百度百科华罗庚URI定义为https://baike.baidu.com/item/华罗庚;实体资源包含实体标识和链接的超文本内容[16],如下所示:
华罗庚(1910.11.12—1985.6.12),出生于江苏常州金坛区,祖籍江苏丹阳。数学家,中国科学院院士,美国国家科学院外籍院士,第三世界科学院院士,联邦德国巴伐利亚科学院院士。中国第一至第六届全国人大常委会委员。
学术著作:《堆垒素数论》《优选学》《高等数学引论》《从杨辉三角谈起》
……
其中江苏常州、金坛区、丹阳、数学家、中国科学院、美国国家科学院、第三世界科学院院士、第六届全国人大常委会等文本标注了百度百科知识库的实体实例;《堆垒素数论》《优选学》《高等数学引论》《从杨辉三角谈起》等著作实体可以利用关联数据技术与图书馆机构知识库中的著作实体关联。上述标注出的每个实体都关联到百度知识库内部的一个实体条目,如“https://baike.baidu.com/item/堆垒素数论”是堆垒素数论的实体关联的实体条目[17]。但这些关联都是知识库内部的自链,没有到外部知识库的外部ID的跨知识库对齐,甚至没有列出到百度自己的“百度学术”知识库的跨库实体对齐。而国内的CALIS知识库中引用了到外部百度百科的实体URI对齐,国外的Wikidata中甚至有少量到百度学术的外部ID引用的实体对齐。由于得不到百度的回应,外部知识库到百度知识库的外部ID引用数量一直处于很低的水平。
Wikidata是基于维基百科的开放关联数据项目,其中所有实体都分配唯一持久的以Q开头的数字序列ID为内部ID。每个实体内部包含大量的RDF三元组(h实体,关系,t实体),其中h实体和t实体都采用Wikidata内部实体ID,构建Wikidata的内部实体关系。Wikidata适应关联开放数据的发展要求,在Wikipedia的基础上增加了外部ID映射,描述知识库内各实体与外部实体的对齐关系,尤其是到著名的规范控制知识库的实体对齐。双向促进作用下,这些外部著名知识库也随后给出自己知识库的实体与Wikidata的ID对齐关系,极大地促进了跨知识库的实体对齐。
2 基于外部ID的实体对齐研究
2.1 Wikidata中国科学院院士数据选取
中国科学院院士是中国科学研究水平最高的学术团体,在国内外有很高的知名度和引用率,国内外多个知识库都包含大量的中国科学院院士实体。但国内知识库的院士实体表示缺少语义关系,无法进行语义推理。学术成果仓库VIAF中的实体包含大量的学术实体对齐关系,但机构实体数量和语义关系偏少,且又缺乏基于语义的查询工具,所以本文选取Wikidata知识库抽取研究数据。
Wikidata有基于本体的实体语义层次框架,其中“中国科学院”机构语义信息丰富,机构下有更细粒度实体为中国科学院的学部。学部通过部分属性关联到中国科学院,并与每个院士通过院士的会员属性关联,形成语义关系链(实体—会员关系—学部会员,学部会员—部分关系—中国科学院院士),根据该关系链构建Wikidata的中国科学院院士子图。Wikidata为方便用户使用提供了SPARQL查询应用,可以根据用户的具体需求设计图模式的查询方案,定制用户感兴趣的个性化数据。所以本文选择Wikidata的SPARQL应用,研究中国科学院院士的外部ID信息,尤其是学术领域知识库VIAF的外部ID。
经过多次调试,本文精心设计对中国科学院院士的Wikidata的SPARQL查询方案,包括匹配模式和结果显示两部分。匹配模式为三个条件的交集:a.实体类型属于个人实例;b.实体的会员属性为某个学术机构;c.该学术机构是中国科学院的学科分部(而不是分支机构)。结果选取实体ID、实体标签、学部ID、学部标签、出生时间、去世时间、外部ID个数、链接维基百科站点个数、陈述个数、外部VIAF ID、博士生导师、受教育机构等属性和关系。具体的SPARQL查询代码如下,查询结果得到了2235行12列的数据[18]。
PREFIX wd:
PREFIXwdt:
PREFIXwikibase:
PREFIXbd:
SELECT ?item ?itemLabel ?mem ?memLabel ?birthLabel ?deathLabel ?ids ?sites ?states ?VIAFIDLabel ?docLabel ?edu
WHERE
{?item wdt:P31 wd:Q5.
?item wdt:P463 ?mem.
?mem wdt:P749* wd:Q530471.
?item wikibase:identifiers ?ids.
?item wikibase:sitelinks ?sites.
?item wikibase:statements ?states.
optional {?item wdt:P569 ?birth.}
optional {?item wdt:P570 ?death.}
optional {?item wdt:P214 ?VIAFID.}
optional {?item wdt:P184 ?doc.}
optional {?item wdt:P69 ?edu.}
SERVICEwikibase:label { bd:serviceParam
wikibase:language "[AUTO_LANGUAGE],en" }
}order by ?mem desc(?VIAFID)?itemLabel
以上获取的数据与中国科学院官网数据进行比较验证,发现自动抽取的Wikidata存在以下细小的错误:院士的学部分类比官网多了中国工程院院士和中国哲学社会科学院院士两个分类。这两个分类在历史上与中国科学院院士有很深的渊源,但将其与现在的中国工程院院士和中国社会科学院官网的院士信息对照,召回率R分别为23.8%和23.7%,召回率太低。而中国科学院其他六个学部数据的召回率R为88.1%,没有覆盖的院士基本上是2015年和2017年当选,这些院士的信息没有在Wikidata中及时更新院士属性。但这也基本覆盖了中国科学院院士,基本上可以接受该数据的可信性。本文对照中国科学院官网的所有院士,选取Wikidata查询到的中国科学院六个学部的院士实例为研究对象数据集,投影消除与外部实体对齐关系较小的列,去除冗余后得到本文后续的研究数据为1307行10列的CSV数据集。
通过维基数据的实体标签和中文知识库的实体姓名的文本相似性比较,本文初始阶段构建中文知识库的1307位院士到Wikidata知识库的外部ID对齐,初步对齐的院士占总体人数的88.1%。下面进一步以Wikidata为中介,分析Wikidata的关系子图,建立到其他知识库的外部ID对齐,再进一步重点构建到VIAF的外部ID对齐。
2.2 Wikidata中国科学院院士数据特征
上述获取的院士信息包括三部分:第一部分是基本信息,包括实体编码、名称标签、学部编码、学部标签、出生日期、去世日期;第二部分包括三个数量型特征:院士实体对齐的外部ID个数(ids)、不同语种的Wikipedia站点个数(sites)和实体的全部陈述个数(states),此部分数据是本文研究的重要内容,其定义见下文2.3.1节;第三部分是实体对齐到外部知识库VIAF的外部ID,它本身是外部ID的一个特殊实例,是本文最重要的目标分类变量数据。
VIAF知识库中的实体资源实际上是一个实体对齐的聚簇信息,包括了众多到国家图书馆的规范名称的关联映射,如图1所示的著名院士华罗庚的VIAF图书馆实体ID聚簇信息[19]包含了20个到国家图书馆的外部ID实体对齐的关联。VIAF与Wikidata实体的外部ID交集有10个,仅出现VIAF而不在Wikidata的有12个,只在Wikidata而不在VIAF聚簇的有14个,两个知识库的实体对齐具有很大的互补性。由于VIAF包含了大量的到图书馆知识库的实体对齐关联,本文后续在Wikidata众多外部ID个数(ids)中选取VIAF ID作为目标分类研究院士信息的外部关联实体对齐,不足之处在于本文初始的检索结果中有VIAF关联的只有226位比较知名的资深院士,占院士总数量的17.3%,占比偏低。后文将详细分析有VIAF链接的院士的Wikidata特征,以及如何通过重定向推理计算构建间接的VIAF实体对齐。

图1 华罗庚院士的VIAF关联数据
2.3 三个数量型特征分析
2.3.1 特征的定义与解释
在全体数据集上,不考虑院士的基本属性,分析三个数量型特征与目标分类的相关关系,这三个数量型特征的定义和描述如下:
ids:Wikidata中的External-ID的个数。每个External-ID将实体对齐到一个外部知识库的ID,相当于一个实体基于owl:theSameAs的实体对齐RDF陈述。ids值越大,从Wikidata到外部知识库同一实体对齐的个数(外部关联数)越大。例如已故院士华罗庚外链知识库ID个数有26个,包括:VIAF ID,美国国会图书馆LC ID,德国GND ID,中国的Calis ID、NLC ID、ISNI,数学谱系项目编码和Freebase数据库编码等26个规范名称知识库ID。上述外部ID都是国家级的规范名称数据库的编码,具有相当高的规范性和权威性,用户可信度高。在跨知识库的关联中,有着较大的链入和链出数,可以通过这些外部ID,间接计算得到与其他知识库的实体对齐。
sites:不同语种的Wikipedia站点个数,每个站点链接该实体条目不同语言的资源网页,例如上述华罗庚院士的维基站点有14个,包括德语、英语、法语、西班牙语、日语、简体中文等不同语种的华罗庚院士的维基百科实体关联。
states:实体的全部陈述的个数。每一个陈述可以用RDF三元组表示实体的一个属性或关系的事实。例如上述华罗庚院士实体的全部陈述个数为65个,包括如表2所示陈述。表2中每行表示一个陈述,每个元素都是一个URI,第二列“主体”表示华罗庚院士的Wikidata编码,第三列“谓词”是Wikidata的属性或关系,第四列“值”大部分都是URI,表示与主体有关系的维基数据内部实体ID或外部知识库实体ID。为便于理解,第三、四列给出标签代替Wikidata属性或实体ID编码。陈述个数越多,实体的属性关系语义越丰富。
表2 华罗庚的陈述RDF三元组

序号主体谓词值1Q590111(华罗庚)Instance of个人2Q590111member of中国科学院数学物理学部3Q590111educated at清华大学4Q590111educated at剑桥大学5∗Q590111VIAF ID36979742…………
注:带*的第5行第4列,RDF陈述的值36979742,即维基数据Q590111实体的外部ID
上述第5条RDF陈述描述一条谓词为VIAF ID的三元组,等价于两个知识库Wikidata和VIAF的实体对齐三元组:
wd:Q590111 owl:theSamelAs VIAF:36979742
内部ID冒号前面的字符串为实体对齐两个知识库域名URI中固定部分域名路径的简写前缀,前缀为知识库域名的简短略写,用户可以参考维基数据SPARQL界面提供的标准前缀。
2.3.2 特征的分布
对数据集中所有实体的上述三个数量型特征进行统计分析,结果可视化数据箱图如图2所示,并在图3中给出三个数量特征概率分布的密度图。
从图2和图3可以看出,这三个特征都是左偏分布的,均值都远大于中位值,均值受到极端大值影响比较大。左偏最严重的为ids,最小值、下四分位甚至与中位数重合,都为极端小值0;上线异常值分界点(上四分位+1.5*四分位间距=1+1.5*1)为3,大于3的异常大的数据个数232,占17.8%,是具有高研究价值的数据。
从图3可以看出,上述三个特征值大致服从指数分布,只有右端尾部少数节点的三个特征值较大,大多数节点的三个特征值都很小,分别为0、1、9。陈述个数states值9远小于百度百科中的内容,甚至下四分位以下的院士属性个数少于中科院官网可以提取的陈述数。产生上述问题的原因在于我国当前与国外知识库的协作还处于初始阶段,国外知识库的中文个人名称只能间接来自境外网站,而不是来自中国本地的知识库,所以很多院士的陈述数属性偏少,而跨知识库的实体对齐的ids更少。但这种情况会随着中文命名实体知识图谱构建的完善和中国对外交流的发展而逐步改善。
图2中三个特征值处于异常大值的实体是拥有丰富外部ID的质量高的实体,可以为建立中文学者命名实体对齐提供有参考价值的数据。表3给出了按照外部id个数排序前15名的中国科学院院士名单(包括官网中的已故院士,Wikidata中这些院士所属学部为生前官网所属的学部),可以看出前15位院士的三个特征值都同时处于异常大值部分,都拥有VIAF ID。根据基本属性分析,这些院士都是学部委员级的资深院士,其中10名是已故院士,且排名大都靠前;一共只有5名(33%)健在院士,排名第一的杨振宁为外籍院士。上述分析说明Wikidata中著名资深院士的数据质量远高于新当选的年青院士,中国科学院官网及国内第三方机构应尽可能提供关联数据格式,发布实时更新的本地数据,以便更好地发布及时权威的本地信息,推动与国外知识库的对齐和互操作。

图3 外部关联id个数、维基站点个数、陈述个数分布密度
表3 External-Id个数排名前15位的中国科学院院士信息

ID姓名学部ID出生日期去世日期idssitesstatesVIAF IDQ181369杨振宁Q461394951922/10/1326794222662938Q590111华罗庚Q461394951910/11/121985/6/1226146536979742Q71874梁思成Q461511671901/4/201972/1/924146282960963Q333500钱学森Q461394951911/12/112009/10/3122335579422641Q926125吴文俊Q461394951919/5/122017/5/719114246730008Q15916846郝柏林Q461394951934/6/262018/3/7153319004075Q534717吴征镒Q461467091916/6/132013/6/201511378306343Q699428杨钟健Q461487311897/6/11979/1/15151539307170346Q323594苏步青Q461394951902/9/232003/3/171553915868981Q10884754任咏华Q461451151963/2/101342976632538Q2601552王元Q461394951930/4/291342761608445Q704575裴文中Q461487311904/12/31982/9/1813123553026642Q707276李四光Q461487311889/10/261971/4/291394439740861Q4843133白春礼Q461451151953/9/261253678620387Q552928路甬祥Q461511671942/4/281273578445914
2.4 基于VIAF ID的目标分类特征分析
2.4.1 基于VIAF ID分类的确定
由于VIAF是全球著名图书馆的名称规范档的关联知识库,是学术领域比较著名的知识库,它对著名学者及其著作和代表作品进行名称规范化关联。VIAF本身关联了全球200多个图书馆机构的规范档,所以与VIAF的同一实体对齐就意味着与多个著名图书馆的规范档的实体对齐。所以本研究选取Wikidata中的VIAF ID同一实体对齐为目标分类,根据每个实体包含的VIAF ID值是否为空分为两类:如果VIAF ID有ID值,分类值为1,表示该实体可以关联到图书馆规范名称库,获取图书馆的作品信息;否则分类值为0,表示当前没有直接的VIAF ID的关联。
2.4.2 目标分类与数值特征的关系
本研究中目标分类与上述2.3部分三个数量特征的关系,分别可视化为散点图,如图4所示。图4中左图为sites和ids平面分布散点图,右图为states和ids散点图。这两个散点图都体现出有VIAF关联的分类样本居于分布图的右上方,没有VIAF关联的处于左下方,中间有少量的交叉区域。
从图4的两个散点图可以看出,y轴ids对目标分类的正向相关作用明显比x轴上的维基站点或陈述个数两个特征要强,y轴上部数据更可能有VIAF同一实体链出。ids个数与其VIAF链出的关系,如表4所示。
从表4可以看出,ids值为0的区域,没有到VIAF直接链接,也不具备推导计算的基础,这部分实体的对齐问题本文暂时不考虑;ids在8及以上,全部具有直接VIAF链接,不需要推导计算,可以直接利用VIAF的信息。中间ids值为1—7的分区出现两个分类的混合,具体分析如下:ids值为1的分区,直接VIAF链接数极小,这符合2.2中VIAF知识库多个关联聚簇特征;ids值为2—3的分区,直接VIAF处于中间状态,具备聚簇关联基础,预估有很大可能推导出VIAF间接关联;ids值为4到7的区间,大多数有直接VIAF链出,预估全部能直接或间接推导出VIAF关联。

图4 三个特征向量与VIAF关联分类的分布关系
表4 ids与直接VIAF分类个数的关系

ids值分区样本院士数直接VIAF个数直接VIAF占比070400%131510.3%2—31004040%4—7807492.5%大于等于87777100%汇总130722617.3%
2.4.3 基于重定向实现与VIAF链接
VIAF知识库为了照顾来源地用户对本地图书馆的使用习惯,提供了利用来源知识库ID重定向到相应的VIAF聚簇的功能。如:Wikidata中,Q10897600刘敦桢院士只有一个External-ID为ISNI:0000 0004 5301 9688,通过VIAF数据源重定向构造到VIAF的实体对齐URI:http://viaf.org/viaf/sourceID/ISNI|0000000453019688,重定向自动进入VIAF实体URI:https://viaf.org/viaf/19680591/,不仅能得到VIAF ID实体对齐,还可以得到VIAF中的17个来源知识库的外部ID。这些关联链接包括VIAF到Wikidata的反向实体对齐,另外还有到其他著名国家图书馆的实体对齐链接:美国LC-n81053811、德国DNB-135553784、法国BNF-11913144、日本NDL-00536020、挪威NTA-162467427等的个人实体对齐关联,同时还可以得到VIAF从上述17个来源知识库动态实时收集的不同语言出版的35本著作的信息。
在上述2.2.2节中发现ids值在1—7的部分,有可能通过上述功能计算构建间接的VIAF实体对齐。为了进一步探索外部ID情况,再次应用SPARQL查询其External-ID的具体情况。第二次检索除了上述的VIAF ID外,又增加了两个外部ID,分别为美国国会图书馆LC、国际标准名称索引ISNI。利用这些外部ID,就可以使用重定向构建间接的VIAF实体对齐,其结果见表5。
表5 利用重定向构建间接VIAF的统计
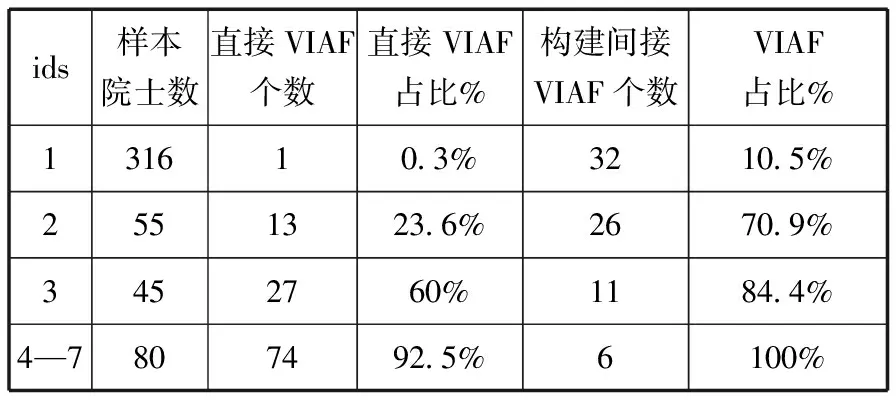
ids样本院士数直接VIAF个数直接VIAF占比%构建间接VIAF个数VIAF占比%131610.3%3210.5%2551323.6%2670.9%3452760%1184.4%4—7807492.5%6100%
表5将ids值分为4种情况,可以看出直接VIAF占比和总体VIAF占比都是ids值的增函数;4个VIAF值的分区都通过重定向构建了间接的VIAF关联,VIAF的个数有了显著的增加,4个分区的VIAF间接关联符合2.4.2节的预估:
ids在4以上的院士,100%都有VIAF的实体对齐。
ids在2、3部分,VIAF的实体对齐的占比也有很大提高,分别提高到70.9%和84.4%。
ids值为1部分,利用LC或ISNI重定向构建了32个间接VIAF,占10.5%,另外有252个实体的外部ID是到中国名人录CV的实体对齐,但是CV知识库中的实体没有与外部知识库的关联。该部分外部ID需要注意的还有到中国国家图书馆和百度学术知识库的外部实体ID对齐14个,这两个是本地中文数据库,具有大量的本地权威规范信息,遗憾的是现阶段本地知识库没有提供到外部知识库的实体ID对齐。还有一些ids值为1,提供到专业知识库的实体对齐,虽然这些专业知识库不再提供进一步的实体对齐信息,但在建立中文实体对齐中也是非常有用的信息。
ids值为0的部分,没有外部ID可供借鉴,但很多院士实体提供了到Wikipedia多语言站点的外部链接;602个院士只有一个到中文Wikipedia站点链接,该站点由国外机构创建,本文获取的可利用信息较少;拥有两种语言站点链接的有95项,可以利用其中的英语Wikipedia站点链接构建到其相关站点Dbpedia的外部ID链接。
总体来说,在本文院士数据集中,首先直接包含VIAF外部ID的有226个,在总体数据集中占比17.3%;再通过VIAF知识库对来源知识库重定位功能,另外计算出75个间接到VIAF的实体对齐关系,为这些实体增加了与VIAF的实体对齐。无论是直接还是重定向计算得到与间接VIAF的实体对齐,都可以构建院士实体到这些国家图书馆的命名实体对齐关系,丰富与院士实体关联的书目作品信息。
3 结果与讨论
通过本文第1和2部分的分析,我们得到中国科学院院士的实体对齐总体可分三个层次:
第一层次,进行国内知识库间的实体对齐。在百度百科和中国科学院的院士知识库进行高准确且覆盖率为100%的院士实例层的一对一的实体对齐,其首要工作是中国科学院官方机构(或委托的第三方)将每位院士资源的URI持续固定化,方便其他知识库引用;然后对院士的文本信息进行结构化和语义化转变,方便其他知识库的实体对齐;最后,百度百科需要利用自身资源完善与百度学术的显式实体对齐,并与中国科学院官方网站进行一对一的实例层实体对齐。国内其他知识库对其收录的每一位院士构建到百度百科或中国科学院官方院士知识库的实体对齐和实体引用。
第二层次,国内知识库可以利用2.1节语义查询方法,构建与Wikidada的一对一的实体对齐。本文中该实体对齐的准确率很高,依赖Wikidata的院士实体的member of属性值的准确率,属性值准确率可以通过Wikidata的用户编辑和专家委员会审核得到保证;院士实体对齐的覆盖率为88.9%,可以接受。覆盖率的提高可以通过Wikidata中中国科学院院士信息的及时收录更新和member of属性的准确赋值实现。本层次的初步实体对齐以很高的准确率和较高的召回率实现了中文知识库命名实体与第一个国外知识库的实体对齐;更深层次可以Wikidata知识库为中介,进行第三层次的与国外知识库的对齐。
第三层次,利用本文重定向的外部ID对齐方法,在第二层次构建中文知识库院士实体与Wikidata实体的一对一对齐的基础上,为603位院士增加了两个以上跨知识库实体对齐,更重要的是可以为301位院士构建到VIAF的一对一的实体对齐,占总体院士数量的23%,这些实体对齐结果显著地提高了中文知识库的实体对齐成效。
然而当前中国科学院院士与VIAF对齐的覆盖率还远低于国外同类实体,原因如下:一是国内图书馆还没有与VIAF协商完成正式加入VIAF,而且有些中国科学院院士没有著作被国外图书馆收录,这超出了本文研究的范围;另一个原因,也是更重要的原因,虽然Wikidata中显式的外部ID可以为跨知识库的实体对齐提供重要的准确信息,但如同2.4节那些重定向推导得到的新的VIAF实体对齐,说明Wikidtata的外部ID并不完备,还缺失了某些隐含的VIAF外部ID,那么就可能存在某些院士实体缺失了更多隐含的外部ID所表示的实体对齐关系。分析这些缺失隐藏的VIAF实体对齐信息的院士,发现他们基本上在本文表4中ids值为3、2、1的分区,论文下一步将对这部分院士按照ids值从大到小的顺序,采用基于标签、出生日期和更多语义属性对齐的方法构建院士与VIAF中的个人实体对齐。
解决第三层次第二方面的问题是本文下一步的研究方向,着力提高国内知识库院士与VIAF实体对齐的覆盖率,为更多院士实体构建到VIAF的一对一的实体对齐;另外还需要逐步扩大研究学者实体的范围到拥有高级奖项和荣誉等具有较高知名度的学者及其相关的机构和成果。
