基于深度卷积生成对抗网络的图像识别算法
2020-05-11刘恋秋
刘恋秋
(重庆财经职业学院,重庆 402160)
1 引 言
生成对抗网络(GAN)是近年来最受关注的无监督式神经网络之一,该模型功能强大且应用场景广泛,最常见的应用是图像生成。在GAN的框架中[1],结果的生成是通过对抗过程不断进化,在GAN中同时有两个模型训练:捕获数据分布的生成模型G以及估计数据分布的判别模型D。生成器G的训练目标是骗过判别器D,换言之最大化D犯错误的概率;D的目标则是最大化自己的正确率。该框架本质上是一个博弈过程,最终收敛于纳什均衡。在空间上,对于生成器G和判别器D,如果使用零和博弈的loss函数,当D训练完美达到1/2时,D就无法再分辨出真实数据和生成数据,也就无法再给G提供梯度。
为了进一步提升GAN的稳定性和识别效率,有很多学者都提出了自己的优化方案,提出了虚拟批量标准化的算法,利用批量训练数据的方式显著改善网络性能。Radford提出了深度卷积生成对抗网络(DCGAN)的算法[2],该算法将GAN的概念扩展到卷积神经网络中,可以生成更高质量的图片。在此基础上,Sailimans等在近红外光谱(NIR)图像的场景下提出了着色 DCGAN模型[3],该方案的核心是针对NIR图像将其划分为RGB 3个通道,再利用DCGAN的模型分别进行训练,进一步提升了识别的准确率。但是针对大部分的图像处理而言,基于深度卷积生成对抗网络的图形识别算法仍存在收敛速度慢、训练过程不够稳定的缺点。本文提出了融合加权Canny算子和Prewitt算子的深度卷积生成对抗网络算法[4],该加权算子对多个方向进行卷积,从而初始化输入图片参数,有效减少了噪声的干扰。
2 深度卷积神经网络算法
卷积神经网络又简称卷积网络(CNN),该模型主要用于处理网格状结构数据的特殊网络结构[5-8]。该模型是受到猫的视觉皮层细胞研究的启发,模仿其神经结构然后提出了感受野(Receptive Field)的概念。卷积神经网络将时序信息等单一变量的信息作为一维的数据格式,而图片、位置等信息则被认为是二维的数据格式。卷积神经网络在推出后,取得了巨大的成功。吕永标基于深度学习理论,将图像去噪过程看成神经网络的拟合过程,构造简洁高效的复合卷积神经网络,提出基于复合卷积神经网络的图像去噪算法,该算法由2个2层的卷积网络构成,分别训练3层卷积网络中的部分初始卷积核,缩短阶段网络的训练时间和增强算法的鲁棒性,最后运用卷积网络对新的噪声图像进行有效去噪。实验表明,文中算法在峰值信噪比、结构相识度及均方根误差指数上与当前较好的图像去噪算法相当,尤其当噪声加强时效果更佳且训练时间较短[9]。王秀席等针对现有车型识别算法耗时长、特征提取复杂、识别率低等问题,引入了基于深度学习的卷积神经网络方法。此方法具有鲁棒性好、泛化能力强、识别度高等优点,因而被广泛使用于图像识别领域。在对公路中的4种主要车型(大巴车、面包车、轿车、卡车)的分类实验中,改进后的卷积神经网络LeNet-5使车型训练、测试结果均达到了98%以上,优于传统的SIFT+SVM算法,其算法在减少检测时间和提高识别率等方面都有了显著提高,在车型识别上具有明显优势[10]。随着大数据时代来临以及GPU并行计算速度的飞速发展,卷积神经网络本身不断优化(ReLU激活函数取代Sigmoid函数,Dropout思想的提出),其计算效率得到了大幅度提升。许赟杰等针对常用的激活函数在反向传播神经网络中具有收敛速度较慢、存在局部极小或梯度消失的问题,将Sigmoid系和ReLU系激活函数进行了对比,分别讨论了其性能,详细分析了几类常用激活函数的优点及不足,并通过研究Arctan函数在神经网络中应用的可能性,结合ReLU函数,提出了一种新型的激活函数ArcReLU,既能显著加快反向传播神经网络的训练速度,又能有效降低训练误差并避免梯度消失的问题[11]。
深度卷积神经网络包含以下几个核心部分:
(1)局部感知。图像的空间联系中局部的像素联系比较紧密,而距离较远的像素相关性则较弱。因此,每个神经元其实只需对局部区域进行感知,而不需要对全局图像进行感知。
(2)权值共享。在上述的局部连接中,每个神经元都有对应的参数,再进行卷积完成特征提取。例如,假设神经元都对应50个参数,共2 000 个神经元,如果这10 000个神经元的25个参数都是相等的,则参数量就变为25个。把这25个参数对应卷积操作,完成了特征提取。在卷积神经网络中相同的卷积核的权值和偏置值是一样的。同一种卷积核按照固定对图像进行卷积操作,卷积后得到的所有神经元都使用同一个卷积核区卷积图像,都是共享连接参数。因此,权值共享减少了卷积神经网络的参数数量。
(3)卷积。该步骤利用卷积核对图像进行特征提取。卷积过程本质上是一个去除无关信息,留下有用信息的过程。其核心就是卷积核的大小步长设计和数量的选取。个数越多提取的特征越多,但网络的复杂度也在增加,如果特征数量太少又不足以描述特征。在该步骤中的卷积核的大小影响网络结构的识别能力,步长决定了采取图像的大小和特征个数。
(4)池化。在卷积神经网络中,池化层一般在卷积层后,通过池化来降低卷积层输出的特征向量维数。池化过程最大程度地降低了图像的分辨率,同时降低了图像的处理维度,但又保留了图像的有效信息,降低了后面卷积层处理复杂度,大大降低了网络对图像旋转和平移的敏感性。一般采用的池化方法有两种:平均池化(Mean pooling)和最大池化(Max pooling)。平均池化是指对图像目标局部区域的平均值进行计算,将其作为池化后该区域的值;最大池化则是选取图像目标区域的最大值作为池化后的值。
3 基于深度卷积生成对抗网络的图像识别
3.1 图像预处理
为了能够提升图像训练效率,对图像进行预处理,流程如下:
(1)假设给出图像I,首先对其进行归一化处理,假设有像素为128×128的图像I,将其归一化为In∈[0,1]128,128,3;
(2)利用Canny算子和Prewitt算子的加权综合,对图像进行进一步的卷积预处理,提取核心特征。
3.2 训练流程
采用DCGAN的(G,D)架构,生成器G是一个编码解码的CNN结构,判别器D是一个步长卷积方案,不断重复进行下采样来完成二分分类[12]。在每次训练的地带中,我们都随机采样一批训练数据,对每个训练图像I我们运行生成器,接着用判别器来进行分类,然后计算损失和更新的参数。
为了减少训练过程,本文将训练过程分为3个阶段,每个阶段定义一个损失函数:
LMSE(I)=‖MΘG(I)‖,
(1)
LD(I)=-[lnD(I)+ln(1-D(G(I)))] ,
(2)
LG(I)=LMSE(I)-αlnD(G(I)),
(3)
第一个训练阶段通过损失函数LMSE(I)不断升级调整生成器的权重,第二阶段则使用LD(I)来调整生成器的权重,第三阶段过程类似,但是α是作为经验值,根据不同的场景而变化。
3.3 网络结构
在生成器G的网络结构中,我们采用传统的编码器-解码器结构,以及扩张的卷积来增加神经元的感受野。对于判别器D,我们将图像沿垂直方向分为左右两部分,分别为Il、Ir,为了产生出预测结果Id,判别器需要分别计算Dg(Id)、Dl(Il)、Dl(Ir),最后生成判别器的概率p,生成器和判别器的网络参数如表1~5所示。

表1 卷积层1Tab.1 Convolution layer 1

表2 卷积层2Tab.2 Convolution layer 2
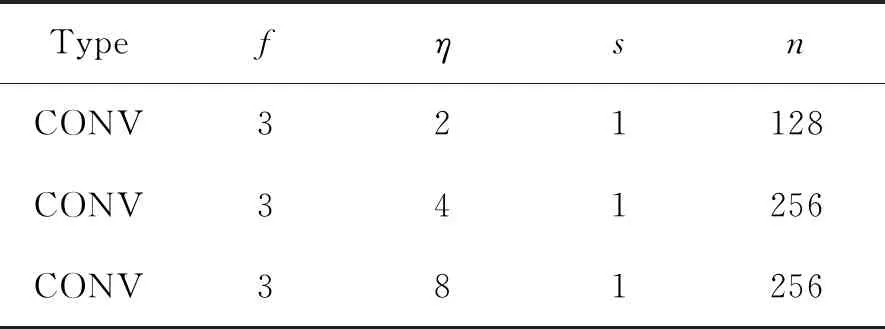
表3 卷积层3Tab.3 Convolution layer 3

表4 输出Tab.4 Output

表5 判别器参数表Tab.5 Discriminator parameter table
4 结果与讨论
考虑到深度卷积网络的计算成本,本文主要利用GPU的并行计算能力,采用5台Inter(R)I7-8700K,64 G内存,NVIDIA RTX 24 G GPU计算机,利用TensorFlow[13]平台实现本文提出的算法并运行。
4.1 CIFAR-100数据集
本文采用的CIFAR-100数据集包含大量的测试图片[14]。与CIFAR-10不同的是,CIFAR-100有100个分类,其中每个类都包含500个训练图像和100个测试图像,每个图像都带有两个标签。使用本文2.3节提出的模型实现生成器和
判别器,首先对数据集中的图像进行预处理,将图片进行归一化,再利用Canny算子和Prewitt算子的加权,最后作为训练模型的输入。在生成器的全连接层中加入Dropout,在预处理的3个阶段,由于CIFAR-100的前景背景相对复杂多变,因此T1设置为20 000,T2为3 000,T3为10 000,α为0.006,实验总共运行了25 h,进行了50个epoch。在训练过程中,判别器的损失函数逐渐下降,而生成器的损失函数逐渐上升,最终判别器以微弱优势战胜了生成器。最终检测效果如图1所示。在与其他经典方法的对比中,其收敛的速度更快,检测率也更优,如表6所示。
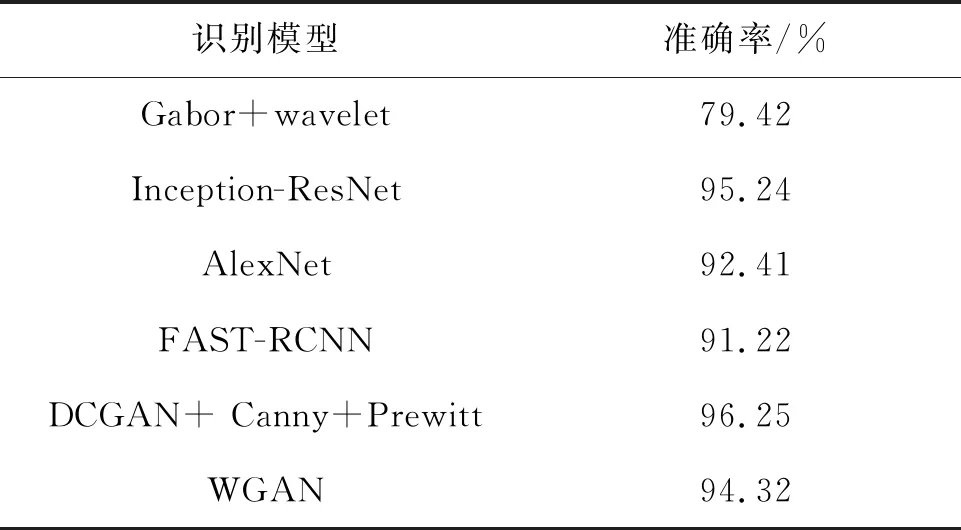
表6 CIFAR-100图像集实验准确率Tab.6 Experimental accuracy of CIFAR-100 image set

图1 CIFAR-100生成器迭代结果Fig.1 Iterative results of CIFAR-100 generator
4.2 LFW实验
LFW是一个人脸识别专用的图像训练集[15],有2 845张图片,每张图片中包含多个人脸,共有5 171个人脸作为测试集。测试集范围包括不同姿势、不同分辨率、旋转和遮挡等图片,基本能呈现人脸表情的各种状态,同时包括灰度图和彩色图。本文采用灰度图进行实验。由于整个数据集相对较小,同时前景相对简单,因此预处理时间消耗较小,T1设置为1 000,T2为2 000,T3为10 000,α为0.005,实验共运行4 h,进行了50个epoch。在迭代过程中随着epoch的增大,生成器产生的图片越加清晰精准,质量不断提升,结果如图2所示。
从表7中可以看到,本文采用的DCGAN+softmax+centermax的模型优于传统的DCGAN模型,在相对较小的数据集中,具备更强的特征提取能力;本文提出的模型的检测率优于其他有监督和无监督算法,证明了本文方法的可行性。

图2 LFW生成器头像迭代结果Fig.2 Iterative results of LFW generator
表7 LFW图像集实验识别准确率
Tab.7 Experimental recognition accuracy of LFW image set

识别模型准确率/%AlexNet87.52Inception-ResNet88.74Gabor+wavelet79.71Fast-RCNN83.31DCGAN82.56DCGAN+Canny+Prewitt89.54
5 结 论
提出了一个基于深度卷积对抗网络的模型,利用该模型对训练完成后的判别器进行特征提取并用于图像识别。利用Canny算子和Prewitt算子进行图像预处理,同时将训练划分为3个阶段设置不同的训练参数,提高了分类算法的内聚性。在WILDERFACE和LFW数据集上进行实验,结果表明相对于其他传统检测算法,本文提出的模型在LFW识别准确率达到89.54%,CIFAR-100上达到96.25%,证明了本文提出的模型在图像检测领域的可行性。
