基于多指标加权分析的航空客户价值预测模型
2020-05-11姚雨虹杨小兵
姚雨虹,杨小兵
(中国计量大学 信息工程学院,浙江 杭州 310018)
随着信息社会的蓬勃发展,人们的出行需求随之增加,从而给航空业带来了很多机遇。乘机需求的增加也给航空业带来了弊端。面对不同的区域多样化的市场需求,各个航空公司面临巨大的竞争压力,航空公司所产生的客户数据是非常多的。工作人员无法从海量的数据中快速定位新的客户类别,不能及时识别高价值客户和潜在有价值的客户。此时急需新的数据处理技术定位精准的客户,以保持行业竞争的优势。
在众多客户关系管理的模型分析中,RFM模型分析是比较受欢迎的分析方法。Arthur Hughes研究所在1994年提出RFM模型,其中R、F、M分别表示为近度(Recency)、频率(Frequency)、金额(Monetary)3个变量[1]。R表示用户在最近的一次购买时间,时间越近,该用户也越可能有反应购买去产品或体验服务。F表示用户在一段时间内的购买次数,次数越多,该用户也越可能有反应购买去产品或体验服务。M表示一段时间内用户购买的金额,金额越大,对企业带来的利益也越大。
孙瑛等[2]使用RFM模型建立了客户价值计量模型。杨彬实现了双阶段客户关联分类[3],包志强等[4]建立RFA模型,对百度外卖客户进行细分;曾小青改进RFM指标,建立多指标客户细分模型[5]。国外研究有BAECKE等[6]运用RFM模型在短时间内提高公司利润;DURSUNA[7]运用数据挖掘技术对酒店客户进行客户价值评估,并提出针对RFM指标进行改进。因为在传统的RFM模型中,F和M之间存在强线性关系,在航空业中,相同的消费金额(M)的不同客户对航空业的价值也是不同的,且RFM模型的特征只有3维,所以传统的RFM模型对航空业不能达到理想的效果,会影响最终客户价值预测的准确性。权明富等[8]从客户全生命周期的角度出发,开发出一套最终客户价值评估指标体系,即从客户当前价值和潜在价值角度,划分出不同的客户类别。本文在RFM模型的基础上提出了多维度全面性的航空公司客户预测价值的指标体系。
在分类算法方面,随机森林算法的预测准确率较高,在各个领域应用广泛。在医学领域,杨云等研究随机森林算法提高胎儿先天性心脏病诊断质量的方法[9],ZOLBANIN等[10]在考虑并发癌症的情况下,运用随机森林基础算法提高预测准确性;王斌等[11]研究在预测重症手足口病具有较大的价值。在客户管理领域,丁君美等[12]改进随机森林算法将其应用于电信业客户流失预测中,于晓红等[13]将随机森林算法运用在P2P网贷信用风险样本中。在服务业领域,随机森林算法应用也广泛,杨森彬[14]将随机森林算法与线性回归算法结合,预测餐饮客流量,提高预测准确率。
近些年来,相当多数量的学者在航空领域进行了研究,但是存在模型单一、数据清洗方式粗暴、预测性能较低等问题。传统的客户价值评估模型针对数据预处理方面的研究较少,FarshidAbdi等[15]在保险行业运用LOF算法对数据进行数据清洗以提高分类准确性。本文在数据清洗方面进行改进,提出采用KNN算法、LOF算法、孤立森林算法等多种数据清洗方法得到多个数据集。为提高预测模型的准确性,本文又在指标权重方面有所改进,从某航空公司客户全生命周期维度出发,选择合适的当前价值指标和潜在价值指标,多重迭代指标权重改变其指标权重,采用DBSCAN算法对客户进行聚类,分为价值不同的5个类别。最后阶段将随机森林算法应用到客户等级预测中,根据随机森林预测性能作为最终评价指标,确定最终选择数据集对应的数据清洗方法和对应的指标权重,构建最终预测客户等级的评估模型。根据准确率(Accuracy)、精确率(Precision)、召回率(Recall)、ROC曲线等性能评价方法,与传统模型进行对比,体现出本文预测模型的优势。
1 评估模型算法介绍
1.1 数据清洗方式
1.1.1 K-近邻(KNN)缺失值处理
KNN缺失值处理,先利用KNN算法计算缺失值临近的K个数据,缺失值的值为选择的临近K个数据的均值。
1.1.2 局部异常因子算法(LOF算法)
LOF算法是基于密度的的经典算法,其最主要的地方是关于数据点密度的刻画。其算法的本质是检测一个数据点的异常程度并不能看它的绝对局部密度,而是看它与周围邻近点的相对密度。
整个算法涉及到4个概念,K-近邻距离是指在距离数据点x最近的几个点中,第K个最近的点与x之间的距离。
x(k)表示的是训练样本x(i)中距离x第k近的样本。从x到x′可达距离是指从x到的直线距离为||x-x′||。若x′比x(k)距离x更近,那么可达距离为||x-x(k)||,对应的公式为
RDk(x,x′)=max(||x-x(k)||,||x-x′||)。
(1)
局部可达密度是指从x(i)到x的可达距离平均值的倒数,对应的公式为
(2)
LOFk(x)是x(i)的局部可达密度的平均值与x的局部密度的比。LOF(x)的值与x成正比关系,LOF(x)越大,x的异常度也会随之变大。当x(i)周围的密度比较高而x周围的密度比较低,则局部异常因子就会比较大,这时x会被当作异常值处理。对应的公式为
(3)
1.1.3 孤立森林(IsolationForest)算法
孤立森林是一个基于Ensemble的快速异常检测方法,该算法的目的是从所有数据中寻找异常值,具有较高的精确度。
1)首先从所有数据中随机选择m个点作为根节点;2)再随机指定一个属性,在当前节点中随机生成该属性的一个阈值p;3)以点p生成一个超平面,当数值的属性值大于阈值,则将该数值划分到超平面的右侧,反之将数值划分到超平面的左侧;4)重复以上步骤,当孩子节点达到限定高度或者孩子节点只有一个数据则停止划分。
生成t颗iTree树组合成孤立森林,对于数量x,首先遍历每一颗iTree,计算x最终落在每一颗iTree的树的高度,最后用每颗树的高度平均值来判断该数据是否异常,低于每个数值的高度平均值的数值为异常值。
1.2 具有噪声的基于密度的聚类方法
具有噪声的基于密度的聚类方法(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)是基于密度的聚类算法,与文献[16]采用的K-Means算法相比,DBSCAN算法对初始值不敏感,不容易陷于局部最优,不用输入类别K,不仅仅局限于处理凸样本集,还可发现任意形状的聚类簇。DBSCAN算法主要步骤如下:
1)判断输入对象是否为核心对象;
2)找出核心对象的E领域内所有的密度可达点;
3)所有的输入对象都判断完成;
4)重复①至③步骤,直到所有核心对象的E领域内所有密度可达点都找到最大密度相连对象集合;
5)所有的核心对象的E领域都遍历完成。
1.3 随机森林算法
随机森林(Random Forest)算法是决策树预测器的组合,每棵树的生成都依赖于一个独立采样的随机向量值,这些随机向量具有相同的分布,每棵树独立运算得到分类结果,然后投票得到最后的分类结果。
随机森林的主要步骤是:1)从样本集中用Bootstrap策略随机抽取n个样本;2)从所有的属性中随机抽取K个属性,并通过计算每个节点的信息增益(或者基尼不纯度),选择每个节点的最优属性作为最佳节点;3)重复以上步骤建立m颗决策树组成随机森林;4)生成的m颗决策树对其数据进行分类,然后通过投票的方式决定数据所属的类别。
2 数据来源与模型分析
2.1 数据来源与数据清洗
本文数据为某航空公司2015-04-01至2017-03-31的客户信息,数据集有44维特征和62 988个数据,但是并不是所有的变量和数据都用于此研究。通过总结航空公司的客户消费属性,结合前人研究的结果,在文献[16]选择5个指标的基础上(L-客户关系,R-消费时间间隔,F-飞行次数,M-飞行总里程数,C-飞行折扣率),构建适用于航空公司的预测客户等级模型,将当前价值和潜在价值作为客户价值衡量的两个要素(当前价值即为客户本身的消费为航空公司带来的当前利润,潜在价值是对未来的预期,客户将来给航空公司带来的利润)大致可以分为7个变量。其中类别编号为D、R、F为当前价值,类别编号为L、P、G、A为潜在价值。客户消费能力变量是指客户平均消费金额,平均消费金额越高说明该客户给航空公司带来的利润越高,如表1。

表1 价值指标选择Table 1 Value indicator selection
实际选取的数据源可能因为数据采样的失误、样本忘记被填写等方式造成一个值或多个值缺失。数据源也有可能因为数据输入错误、度量方法对于某些特征不适用、抽样异常等方式造成数据异常。所以在训练一个模型之前需要进行数据清洗,通过数据清洗的方式以提高数据质量,挖掘出有用的数据。常见的数据缺失值处理方式有删除缺失值法、以同一指标的计算结果(均值、中位数、众数等)填充缺失值法、KNN算法、贝叶斯算法等。常见的数据异常值处理方式有LOF算法、孤立森林算法、删除异常值法、以同一指标的计算结果(均值、中位数、众数等)填充异常值法等。
本文实验采用KNN算法对数据进行缺失值处理,并使用LOF算法和孤立森林算法对每条数据进行检测,发现异常值将其删除。通过三种不同的数理清洗方式获得三组不同的数据集。
2.2 指标权重分析与模型构建
为了提高预测模型的准确性,本文针对指标权重方面进行改进,如图1。改进算法如下:
1)赋予当前价值指标权重0.1;
2)赋予潜在价值指标权重0.1;
3)数据集中每个数据当前价值指标对应的值乘以对应权重,潜在价值指标对应的值乘以对应的权重,形成新的数据集;
4)使用DBSCAN算法给每个数据打上类别标签;
5)使用随机森林算法计算预测的准确率,如果计算出的预测准确率比之前的最高准确率高,则该准确率替换为最新的最高准确率;
6)跳转到2),重复步骤3)~5),直到潜在价值权重值为1,则跳转到1);
7)重复步骤2)~5),直到当前价值指标权重为1,经过对比得出最高准确率对应的指标权重。
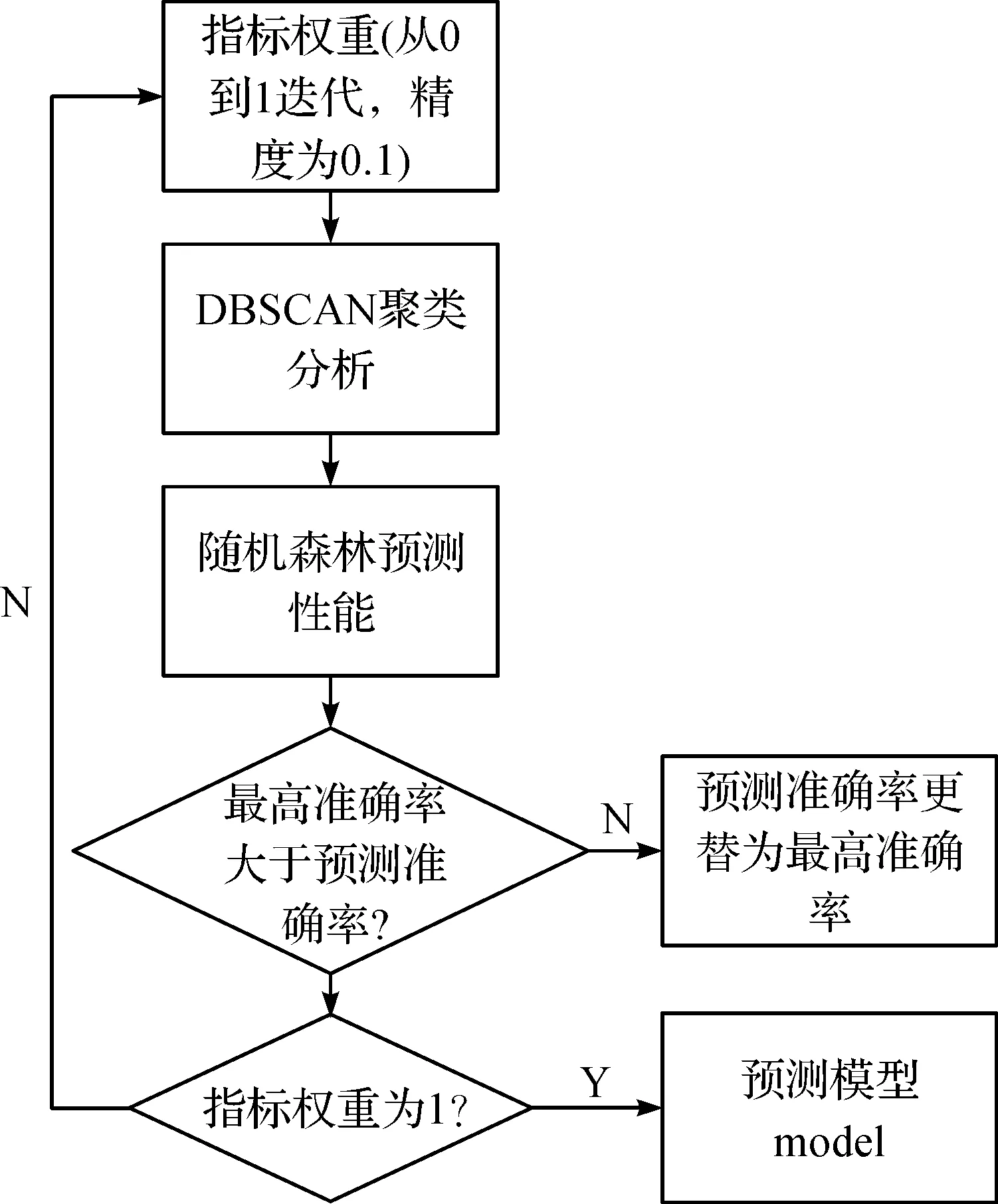
图1 指标加权的局部最优预测模型Figure 1 Index-weighted local optimal prediction model
本文通过三种不同数据清洗方法生成三组不同的数据集经过图1的流程分别求出局部最高准确率对应的预测模型1,2,3,最后比较模型1,2,3得出最终的客户价值预测模型。如图2。
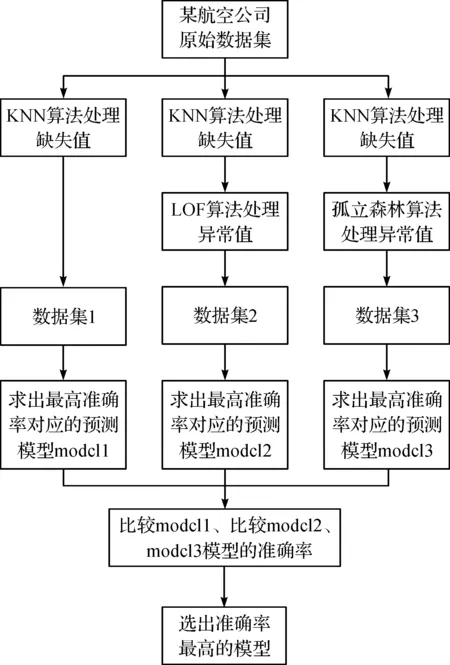
图2 最终客户价值预测模型Figure 2 Final customer value forecasting model
2.3 分类性能评价方法
本文使用的分类评价标准是准确率(Accuracy)、精确率(Precision)、召回率(Recall)、ROC曲线面积。精确率用来评价实为某类客户的检测结果,如某类客户中有多少是被实际检测正确的;召回率是指正确被检索的客户占应该被检索到的客户的客户比例;准确率是所有的样本中被预测正确的样本的比率,由精确率和召回率决定,包括了总体的准确率;精确率、召回率、准确率越大,说明分类效果越好;ROC曲线的x轴为假正例率(FPR),y轴为真正例率(TPR),真正例率是指在实际为正例的样本中,被正确判断为正例之比率,所以真正例率越高越好,假正例率越低越好,曲线距离左上角越近证明分类器效果越好。
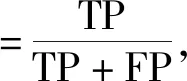
(4)
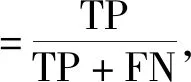
(5)
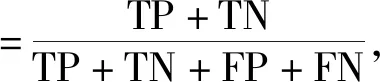
(6)
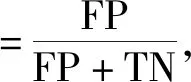
(7)
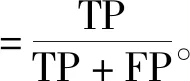
(8)
如式(4)~(8),其中TP为真正类,FP为假正类,FN为假负类,TN为真负类。
3 实验结果分析
为了证明本文的可行性,以Inter-Core i7 2.6Ghz为硬件环境,Python3为实验平台,通过检验变量选择的准确率、精确率、召回率和ROC曲线面积值,评估该预测客户等级模型的性能。
本文采用DBSCAN聚类算法将客户分为5个聚类,运用随机森林算法预测客户价值等级,采用客户关系长度关系、消费时间间隔、飞行次数、飞行折扣率、客户消费能力、会员级别、客户年龄作为自变量,客户等级作为因变量,针对不同的数据集,将本文提及方法建立的模型1,2,3和文献[16]方法建立的模型进行对比,在62 988个数据中,随机抽取7/10(44 092)作为测试集,剩下的3/10(18 896)作为验证集。
表2是3种数据清洗方法对应的数据集和文献[16]对应的数据集基于随机森林算法的预测客户价值模型的预测结果。从表2可得,4个预测模型的精确率分别为99.665%、99.515%、99.383%、97.944%,准确率分别为99.653%、99.433%、99.328%、98.361%,召回率分别为99.493%、99.311%、99.226%、97.725%,3个数值均以从大到小排序呈现。比较以上模型,验证了本实验设计的模型均比文献[16]实验模型预测准确率要高。根据表2实验结果所得,模型3基于随机森林的预测准确率最高,所以本文选取模型3为最终的预测模型。
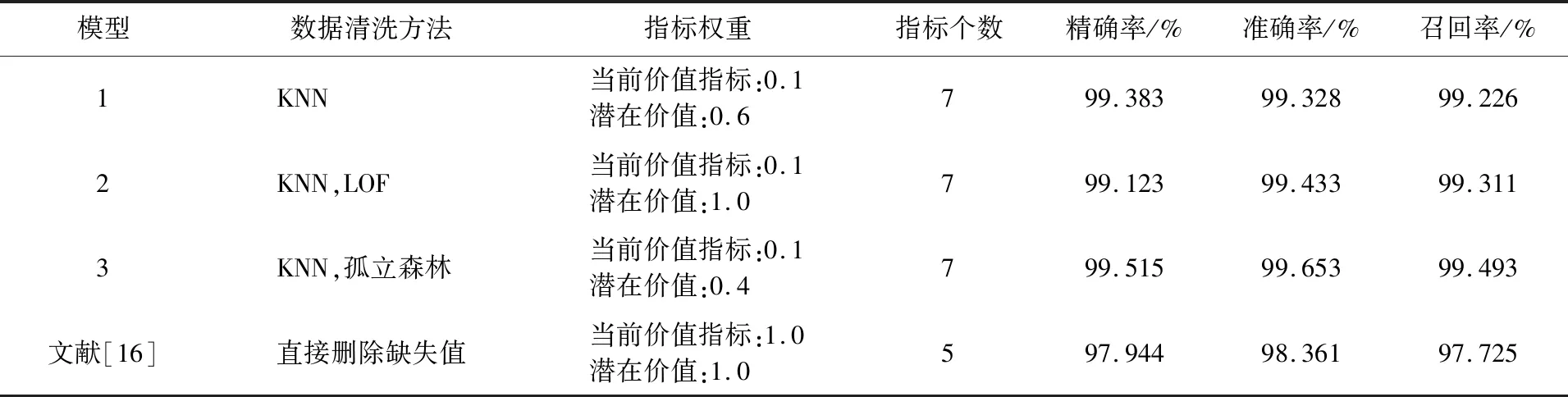
表2 不同清洗方法的预测模型和文献[16]模型对比Table 2 Comparison result between the prediction models for different cleaning methods and the reference model
图3是本文实验建立的不同模型与文献[16]实验模型对应的ROC曲线和AUC的值,ROC曲线不会受到样本的影响,分类效果相对稳定。AUC是ROC曲线所围住的面积,AUC越大,则分类效果越好。AUC为1表示为最佳的分类器,AUC为0.5是最差的分类器。从图3可以看出本文提出的模型AUC的值更大,预测的效果更好。
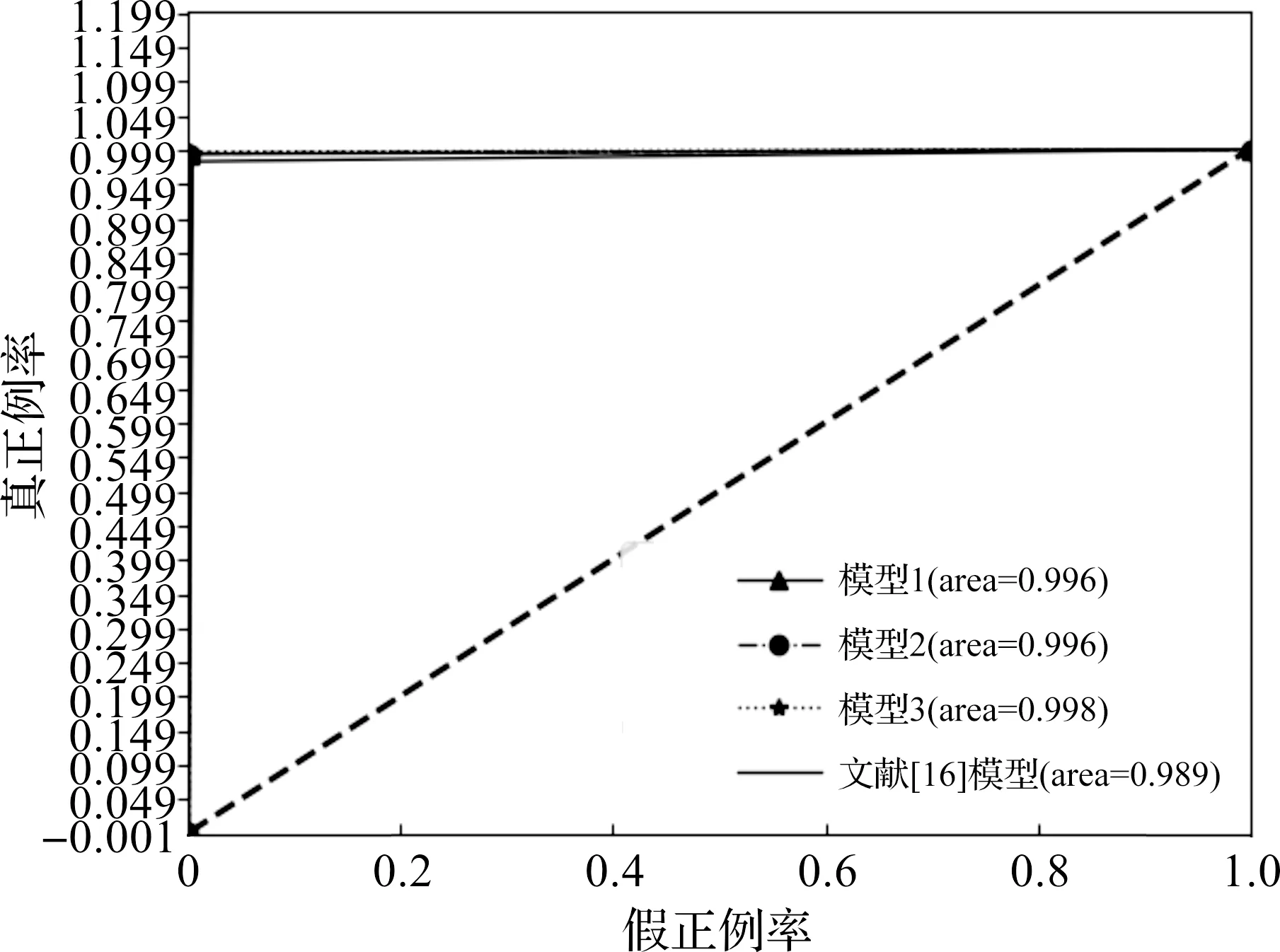
图3 不同清洗方法的预测模型和文献[16]模型ROC曲线图对比Figure 3 Comparison of ROC curve between prediction model of different cleaning methods and the reference model
综上所得,最终客户价值预测模型为模型3,模型3的准确率、精确率、召回率、AUC比文献[16]高,因此本文设计的实验预测效果更佳。
图4以混淆矩阵的形式表示模型3的性能,可以直观地描述模型3的预测性能,其中每一行显示真实值的性能,每一列是预测值的性能。在6 508名实际为类别0客户中,有6 493名被预测为类别0客户,预测的精确率为99.769%;4 772名实际为类别1客户中,有4 746名被预测为类别1客户,预测的精确率为99.455%;4 679名实际为类别2客户中,有4 675名被预测为类别2客户,预测的精确率为99.915%;837名实际为类别3客户中,有823名被预测为类别3客户,预测的精确率为98.327%;211名实际为类别4客户中,有211名被预测为类别4客户,预测的精确率为100%。
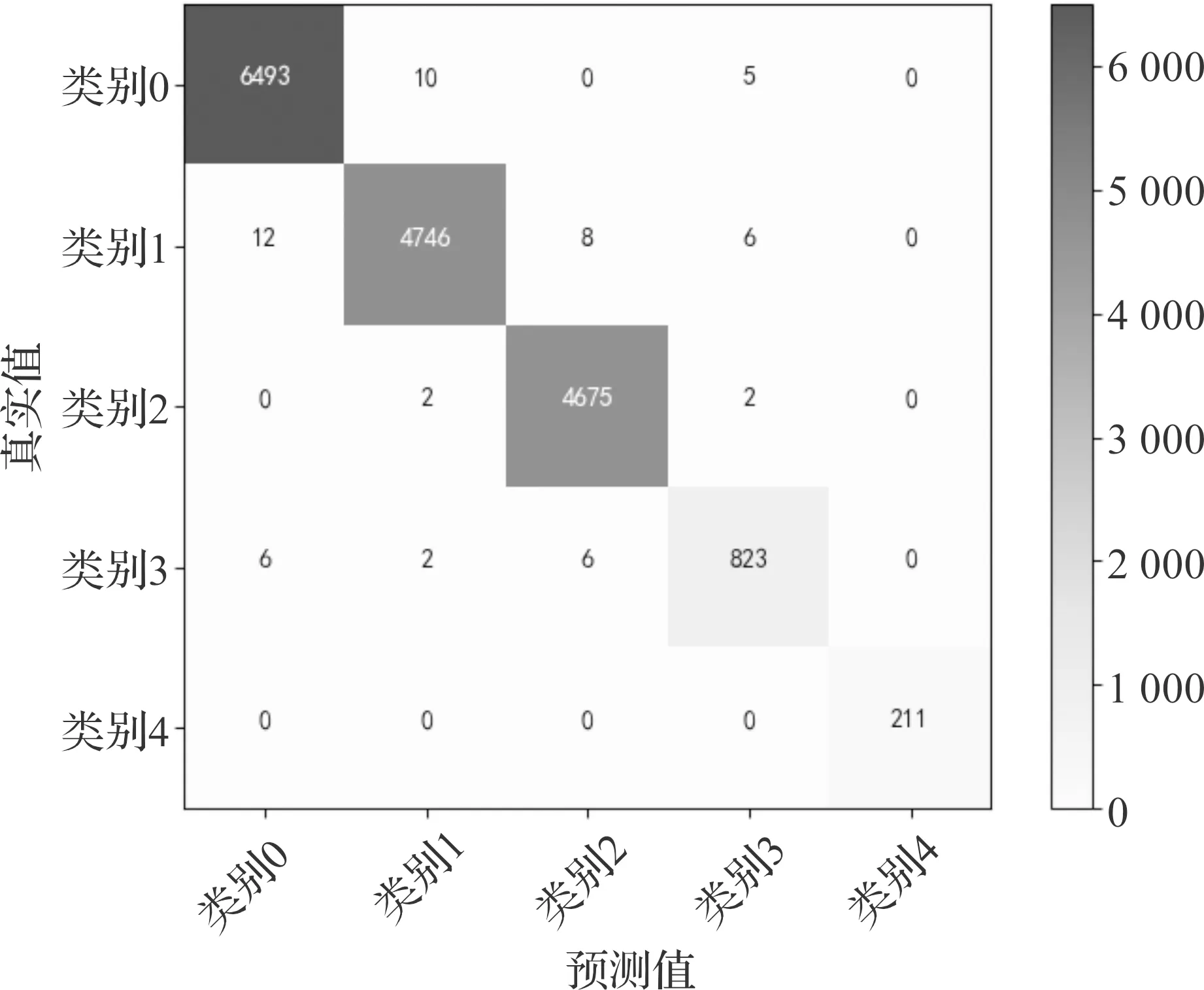
图4 模型2混淆矩阵结果图Figure 4 Model 2 confusion matrix result graph
对于一个新用户可输入用户信息至模型3,可以快速判断用户类别。输入消费时间间隔、飞行次数、飞行折扣率、客户消费能力、会员级别、客户年龄、客户关系长度关系的信息,通过随机森林算法直接求得预测管理结果。具体的部分客户价值分析结果如表3。
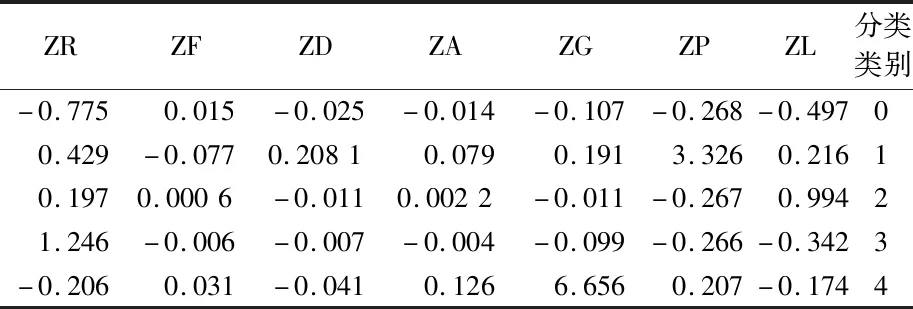
表3 具体的客户价值预测分析结果Table 3 Specific customer value prediction analysis results
根据上述的实验结果,我们可以得到以下结论:
1)针对现有客户信息,改变当前价值和潜在价值指标的权重可以有效地提高随机森林预测的准确率;
2)模型3以KNN森林处理缺失值,孤立森林算法处理异常值,当前价值指标和潜在价值指标的权重分别为0.1,0.4,并通过随机森林森林建立的预测客户价值模型。输入一个新用户信息可以准确定位该客户价值,预测效果较好,对航空公司的预测管理具有一定的适应性。
4 结 语
本文从客户全生命周期角度建立的模型,有效改进了RFM模型的缺点。通过不同的数据清洗方法,同时修改客户价值指标的权重,并结合随机森林算法,为航空公司评估哪些有可能成为他们的客户提供新的思路。
本文以航空公司客户信息为例,从企业的角度出发,分析不同类别的客户给企业带来利润。采取差异化营销策略,重视高价值客户,挽留潜在价值客户,抛弃低价值客户,节约企业花费成本,提高客户满意度。
