集成遗传算法在特征基因选取中的应用
2020-05-11江健生
江健生,汪 妍
(1.安庆师范大学a.计算机与信息学院,b.安徽省智能感知与计算高校重点实验室,安徽安庆246133;2.上海市浦东新区人民医院肿瘤科,上海201299)
基因表达谱是一个高维度数据集,其为肿瘤诊断提供一定的有用信息[1]。常被用于高维数据集特征选取的有Filter(过滤式)和Wrapper(包装式)方法[2]。其中:Filter方法从数据自身特点出发,利用样本可分性指标评定特征的重要性,选取有效分类特征;Wrapper方法则利用分类模型的内部结构信息,根据分类模型的输出,在特征空间中搜索最佳特征集合,选取结果优于Filter方法,但时间开销大。已有学者利用Filter方法的计算复杂度小和Wrapper方法的准确度高的优点,将二者结合进行特征基因选取,如Pirgazi等[3]基于Filter和Wrapper方法,利用Relief方法、IWSSr方法和随机蛙跳算法(SFLA)的混合方法,在大规模基因数据集中选取有效特征;Hameed等[4]在高维数据集上使用Filter-Wrapper组合和嵌入式(LASSO)特征选择方法选取特征基因;Sahu[5]利用信息增益技术和改进的二进制粒子群优化(IBPSO)分别用于Filter和Wrapper方法,取得较好基因分类效果。
集成特征选取方法源自集成学习算法,在变化的特征选取环境(如不同的特征选取算法、不同的样本数据、不同的样本特征或不同的特征选取器)中选取不同的特征集合,通过集成这些特征集合得到最佳的分类特征[6]。遗传算法基于生物进化思想模拟自然界的遗传过程,种群的染色体通过选择、交叉和变异等操作过程进化至下一代,其空间搜索和全局寻优能力使之适宜完成高维数据集的特征选取[7],也被用于基因表达谱数据集的特征基因选取中,搜索具有丰富类别信息、能决定样本类别的关键特征基因[8]。鉴于此,本文结合Filter和Wrapper方法,提出一种适于高维基因表达谱数据集的集成遗传特征选取方法,以SVM(支持向量机)的分类结果作为个体适应度函数的参数,在5个高维肿瘤基因表达谱中进行集成遗传特征基因选取实验,以期提高基于分类模型的遗传特征选取方法性能。
1 基于Filter方法的噪声基因过滤
数据集的数据特征可分为4类:信息特征、冗余特征、无关特征和噪声特征[9]。噪声特征不含样本类别信息,对识别样本类别起负作用。因此,在特征选取之前需进行噪声特征过滤。Tang等[9]根据式(1)所示的特征相关性指标,合并标准差相对较小的正类特征集合S+和负类特征集合S-,即用SR=S+⋃S-过滤噪声特征。

式中:σi,σi+,σi-分别是第i个基因在所有样本、正类样本、负类样本中表达值的标准差;Ri+,Ri-分别为正类、负类相关性指标,这里仅考虑类内分布紧密的特性,忽略特征在正类、负类样本中的期望分布。这样,即便某些高相关性指标的特征也可能因为其在异类间期望差异太小而无法提供更多的分类信息。
根据特征在正类、负类样本中的期望分布,定义特征在异类样本中的相对分离指标Ei如

其中mi+和mi-分别是第i个基因在正、负类中表达值的期望。由式(2)筛选出正、负类期望分离程度相对较高的特征集合SE。
综合考虑基因表达谱数据集的训练集中基因在类内和类间的分散情况过滤噪声基因。计算基因的正类、负类相关性指标,过滤低于正类、负类的相关性指标阈值的基因,形成基因集合SR;再根据基因在正类、负类样本中的期望分布,筛选正、负类期望分离程度相对较高的基因集合SE;通过合并基因集合SFilter=SR⋂SE保证过滤后的基因集合具有丰富的样本类别信息,将SFilter作为后面的特征基因选取范围。
2 基于Wrapper方法的集成遗传算法特征选取
2.1 改进遗传算法的特征基因选取
遗传算法的个体由一组定长的二进制码组成,个体长度与特征基因搜索范围内的基因个数相等,每个个体代表一种特征基因选取方案。个体的二进制码值代表其对应位置的基因是否被选中:“1”表示选中,“0”表示未选中。初始种群中个体的二进制码值是随机设置的,二进制码值“1”决定遗传算法的特征基因搜索范围。为保证更多的基因进入遗传算法的搜索范围,在遗传算法的初始阶段,个体中码值为“1”的元素应占个体80%以上。
个体适应度函数以其选取基因集合的分类性能为核心参数,同时,将基因集合的维数设置为适应度函数的另一个重要参数,鼓励基因集合向低维的方向进化。式(3)定义的适应度函数f(S,g)可保证遗传算法选出低维的高质量的基因集合。

式中:g为遗传算法的进化代数;S为第g代个体的选取的基因集合;pS为被选基因集合的分类性能;dS为基因集合维数;dy为动态惩罚因子,为避免进化初期因基因集合维数降低过快而丢失重要特征,进化初期惩罚因子数值较小,后期逐渐变大。为防止进化因适应度变化过小而停滞不前,借鉴模拟退火算法,在适应度函数中加一个分母项0.999 99g。鉴于数据集中异类样本分布不均,分别用基因集合在训练集中支持向量机(SVM)分类AUC(接收者工作特征曲线下的面积)值评价基因集合的分类性能。
为防止遗传算法掉入局部极小,引入禁忌搜索算法,并用前k代最优个体信息组成禁忌表。为提高遗传算法效率,建立由个体信息及其选取的基因集合在训练集中的SVM分类AUC值组成对照表,避免进化过程中对相同的基因集合进行重复的性能分析,提高进化后期(因个体长度较小,产生重复个体的概率较大)的进化效率。当两代种群的最优个体适应度差值小于某任意小正数时,或者进化到指定最大遗传代数时,遗传算法终止,最后一代种群中最优个体1码(码值为1)对应的基因为被选的特征基因。
2.2 基于SVM的集成遗传特征选取
集成遗传特征基因选取的初始阶段,在基因搜索范围SFilter中随机产生N组初始种群,进行选取、交叉和变异操作,经过遗传进化得到N个最优个体。随机初始种群保证各遗传算法基因搜索范围的多样性,有益于改善集成遗传特征基因选取方法的鲁棒性,提高被选特征基因的分类性能。
SVM特别适合于维数高、样本数少的扁平数据集的样本分类[10]。遗传算法的个体适应度函数以其选取的基因集合的SVM分类结果为核心参数,SVM分类结果是基于线性核函数的SVM分类器在训练集中进行5 倍交叉校验的分类AUC 值。集成N次遗传算法进化最优个体,用最优个体对应基因集合的SVM 分类AUC值加权基因集合的基因,汇总N个最优个体对应的基因权重,以基因权值评价基因对样本分类的重要性。基因权值w(F)的集成求和公式如

式中:F为每轮候选基因集合;Gi表示第i个遗传算法的初始种群进化后的最优遗传个体对应的基因集合;A(Gi)为第i个基因集合在训练集中的SVM分类AUC值。
用AUC值加权进化后的种群中最优个体对应的基因,集成后的基因权值既能体现基因在N次遗传算法中被选的频数,又能反映基因对样本分类的贡献。这种集成加权方法比简单地统计基因被选频数的方法更能量化基因所含的样本类别信息,选取出代表样本类别的关键特征基因。
2.3 集成遗传特征选取FSEGA方法
在反向递归过程中用集成遗传算法选取基因表达谱的特征基因,见图1。数据集样本被按3∶1∶1随机分配至训练集、校验集和独立测试集。在训练集中对过滤噪声后的特征集合SFilter采用集成遗传算法进行特征选取,根据(4)式汇总基因的权值,保留权值较高的50%基因组成候选基因集合;然后,基于该候选基因集合,重新采用集成遗传算法进行特征选取,刷新基因的权值,再由高权值的基因组成维数更低的、新的候选基因集合。重复上述过程,生成一组维数渐低的候选基因集合。
为客观评价每个候选基因集合承载的类别信息,在校验集中进行分类测试。用训练集训练分类器识别校验集的样本类别,以分类AUC值衡量候选基因集合的分类性能,分类AUC值最高的候选基因集合为最佳基因集合,其含有的类别信息量最高。分类测试模型选用SVM和KNN(K近邻算法)分类器,考察候选基因集合的分类性能,防止候选基因集合过拟合于遗传算法适应度函数中所用的SVM分类模型,保证选出的最佳特征基因集合有较好的分类能力。集成遗传特征选取方法的流程图见图1,实验重复20次。

图1 集成遗传特征选取方法的流程图Fig.1 Flow chart of FSEGA method
3 实验结果与分析
在Colon,Acute LeukeMia,Multiple Myeloma,DLBCL和Prostate 5个肿瘤特征基因表达谱数据集中进行集成遗传特征选取实验,数据集样本按3∶1∶1 随机分配至训练集、校验集和独立测试集。在噪声基因过滤中,经过多次过滤和特征基因选取实验,确定5个基因表达谱数据集的噪声基因过滤参数,见表1。

表1 5个基因表达谱数据集及其噪声基因过滤参数Tab.1 Five gene expression profile data sets and their noise gene filtering parameters
为客观评价集成遗传特征选取方法的性能,避免因样本分配不均产生的偏置对特征选取方法的评判,分别对5个基因表达谱数据集特征基因选取20次。同时,对于同一数据集,基于相同的训练集、校验集和独立测试集及相同适应度函数进行单遗传特征基因选取实验,即遗传算法的适应度函数同样建立在SVM分类基础上。遗传算法由100 个个体组成种群,进化最大代数为50,选取、交叉、个体变异概率分别为0.8,0.5,0.05。禁忌搜索算法的禁忌长度(Tubo size)取最大遗传进化代数的平方根近似值8。
3.1 特征选取方法的稳定性分析
特征选取的稳定性是特征选取方法的重要性能之一[11]。文中使用Saeys 等[12]提出的基于相似度方法定义的稳定性指标,表2 为集成遗传特征选取方法和单遗传特征选取方法在5 个数据集中20 次特征基因选取实验的特征基因选取稳定性指标。由表2可看出,对于5种特征基因表达谱数据集,集成遗传特征选取方法的稳定性指标均高于单遗传特征选取方法的稳定性指标,表明本文提出的集成方法有效提高了遗传算法选取特征基因的稳定性。
3.2 特征基因集合的分类性能分析
独立测试集独立于特征基因选取过程之外,能客观地测试最佳特征基因集合的分类性能。为进一步客观验证被选出的最佳特征基因集合的分类性能,用训练集训练的SVM和KNN分类器识别独立测试集样本类别。表3为对于5个基因表达谱数据集,分别使用集成遗传特征选取方法和单遗传特征选取方法在20次特征基因选取实验中,获取的最佳特征基因集合在独立测试集中的分类结果,平均值为5个基因表达谱数据集在SVM和KNN两个分类器下获得期望值和标准差的平均。

表2 2种特征选取方法的稳定性指标Tab.2 Stability index of two feature selection methods
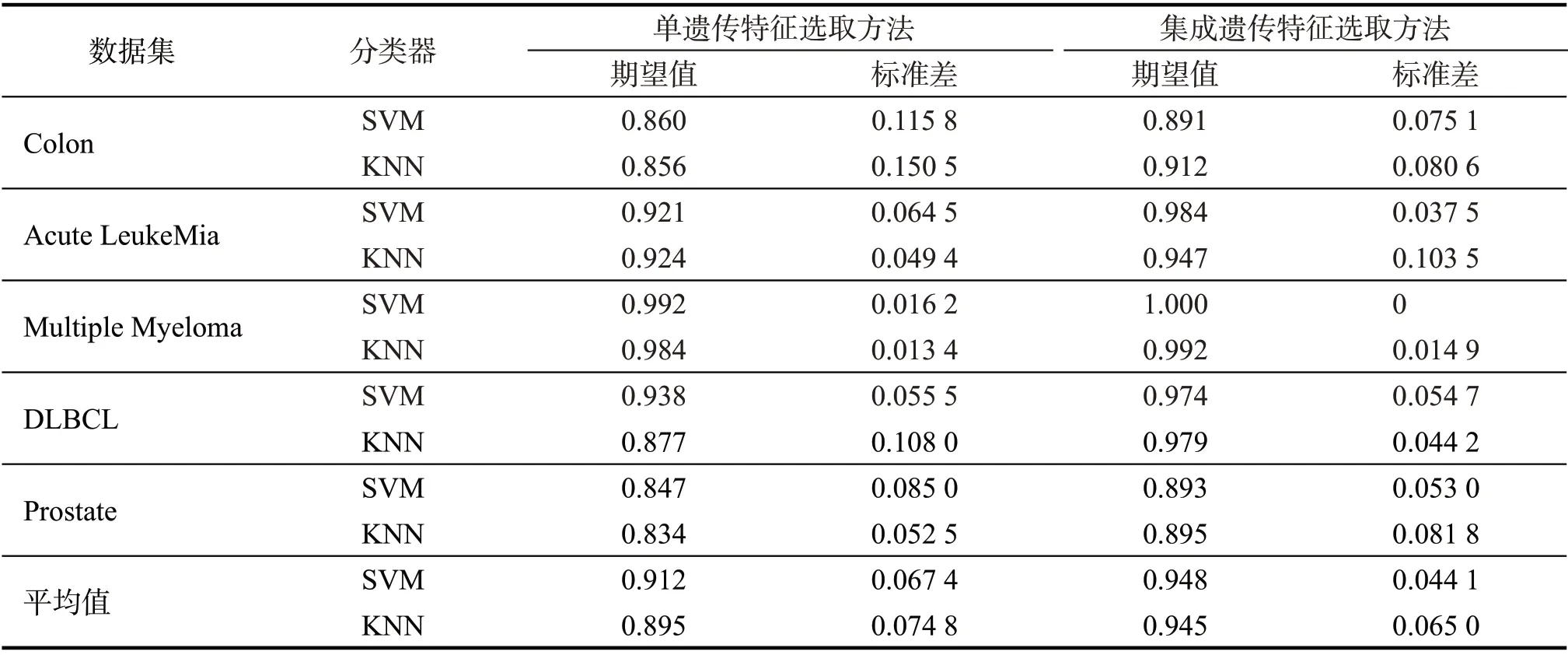
表3 最佳特征集合在独立测试集中的分类结果Tab.3 Classification performance of the selected feature gene subsets on independent test set
由表3可知:集成遗传特征选取方法在5个基因表达谱数据集里选取的特征基因在SVM和KNN两个分类器下分类AUC期望值数据均优于单遗传特征选取方法,表明集成遗传特征选取方法选取出的特征基因的类别识别能力优于单遗传算法特征选取方法选取的特征基因;同时,单遗传特征选取方法选取的特征基因集合的分类AUC值标准差多数比集成遗传特征选取方法选取的特征基因集合的分类AUC值标准差高,表明后者选取的特征基因集合分类稳定性比前者好。
3.3 特征基因及其差异表达分析
选取肿瘤基因表达谱样本分类特征的目的是找出肿瘤中普遍异常表达的基因,探讨肿瘤中普遍呈现出的、不同于正常组织细胞的基因表达特征存在的可能性。特征基因在异类样本组织中的表达水平与其对样本类型识别能力直接相关,可通过特征基因在异类样本中的差异表达情况分析肿瘤在基因表达上的特点[13]。特征基因在正类和负类样本中的表达均值为Ei+和Ei-,其在异类样本间差异表达水平Δi=Ei+-Ei-,Δi≥0 表明该特征基因在正类样本中相对于负类样本呈现上调表达,Δi <0 表明该基因在正类样本中呈现下调表达。上述表达可视为特征基因在异类样本间的表达模式,说明肿瘤组织在基因表达上的特异性。
图2为采用SVM的集成遗传特征选取方法,在5个数据集中选取的20个最佳特征集合中频度最高的前10个特征基因在原始数据集中的访问码及其在不同类型样本中的差异表达情况,其中纵坐标Δ表示特征基因在两类样本中的表达差异。由图2 可以看出,以Colon 数据集为例,基于SVM 的FSEGA 方法选取的前10 个特征基因中有4 个特征基因(T78104,M76378,D31716,U25138)呈上调表达,有6 个特征基因(T51023,T59878,T56604,T51261,T65758,H05899)呈下调表达。文献[14-18]的研究结果表明选取的特征基因中M76378,U25138,T51023,T56604,T51261等基因与结肠癌相关,这些基因在两类样本中的表达水平差异反应了结肠癌组织和正常组织在基因表达上的特异性。特征基因在异类样本中的差异表达也表明集成遗传特征选取方法的有效性和可行性。

图2 FSEGA方法在5个基因数据集上选取特征基因的差异情况Fig.2 Differences of feature genes selected from five gene data sets by FSEGA method
4 结 论
针对基因表达谱数据集的特征基因选取问题,结合Filter方法和Wrapper 方法,提出集成遗传特征选取方法,研究分类模型对集成遗传特征选取方法的影响。同时选用SVM和KNN两个分类器从候选基因集合中选取最佳特征基因集合,有利于防止被选特征基因集合过拟合于集成遗传算法适应度函数中的分类模型,提高特征选取方法的鲁棒性。特征选取实验表明,本文提出的集成特征选取方法可提高以分类结果为适应度函数的遗传算法的特征基因选取性能,选取的特征基因集合含有丰富类别信息,重复性较好,提高了肿瘤特征基因选取的稳定性和鲁棒性。
