云平台任务资源使用状态预测分析研究
2020-05-09任雨林朱金灿
邓 莉,任雨林,朱金灿,何 亨,李 超
1(武汉科技大学 计算机科学与技术学院,武汉 430065)2(智能信息处理与实时工业系统湖北省重点实验室,武汉 430065)3(湖北大学 信息化建设与管理处,武汉 430062)
1 引 言
近年来,云平台因其廉价可扩展的计算资源、稳定高容量的存储空间和随时随地可灵活访问等优势受到广泛地使用.
虽然云平台提供的按需付费方式新颖便捷,能有效地提高工作效率.但是最新的研究[1,2]表明,大多数云设施和商业集群的资源使用率很低,比如:Twitter云平台千台服务器在一个月内的总CPU使用率始终低于20%,然而预留的资源却达到了总资源的80%[3];Google云平台CPU平均使用率在10%~45%之间波动[4].为了提高云平台的资源使用率,一些研究人员改进了云数据中心的调度算法[5],通过建立基于历史数据的预测模型和现有调度模型的组合[6],预测了云数据中心任务未来的资源使用率,结果表明,云平台任务的资源使用预测可以优化任务的资源分配方式,降低数据中心成本,是提高云平台性能和效率的一种有效方法[7,8].
2 相关工作
对云平台任务的资源使用情况的预测展开分析研究,需要大量的相关资源使用数据集,但是由于商业数据的机密性以及公司策略等原因,真实的云平台资源使用数据集较难获得.因此现有的大部分相关研究都是基于仿真数据[9]而展开的,最终的实验结果缺乏说服性.还有些学者针对长时间运行的服务[10]或者高性能计算负载[11]也展开过相关研究,但是真实的云计算平台负载具有多样性,专注于某一种类型的负载进行研究并不能有效提高云平台整体的资源使用率.Cortez E等人[12]于2017年对真实云平台Microsoft Azure中的资源使用情况进行了详细地分析,研究表明了Microsoft Azure云平台的低资源使用率和云平台资源使用率的可预测性,并且使用随机森林回归模型预测虚拟机的资源使用量,但是性能还可以进一步提升.还有研究人员针对云计算环境下基于用户需求进行预测的虚拟机节能分配方法进行过研究[13],但是并没有针对具体任务进行资源预测.Delimitrou C等人[10]于2014年提出离线分析工作负载的方法,先让任务试运行一段时间,通过推荐算法得出其可能的资源使用率,然后重新调度.实际上,离线分析是不可行的,因为在实际生产中,工作负载的输入在任务运行之前通常都是得不到的.Reiss C等人[11]通过对Google云平台数据集的详细分析,发现云平台中运行时间较长的任务资源使用率具有可预测性.Yu等人[14]于2014年提出了使用BP模型预测Google云平台任务的平均CPU使用量的方法,但是Cortez等人[12]于2017年的研究工作表明云平台调度器分配给任务的资源量是按照用户估计的任务最大资源使用量分配的,因此在生产中更需要预测的是任务的最大资源使用量.而且BP模型算法的收敛速度慢,容易陷入局部极值.Islam[15]等人提出了改进的递归神经网络(RNN)的预测方法-长短期记忆网络(LSTM),用于识别云中的应用程序故障.除了上面提到的研究,还有一些学者开展了任务使用模式预测[16]和预测任务的约束特征[17]等工作.T.Mehmood等人[18]把Google云平台中任务的资源使用率分成高中低三个级别,使用分类技术对任务的资源使用率级别进行预测,但是这种分类方式是基于粗粒度的,不能有效地帮助调度器分配资源.
3 预测方法
3.1 云平台任务资源使用特征分析
本节以阿里巴巴云平台1(数据集于2017年发布)任务和Google云平台(数据集于2012年发布[19])任务为例,详细地分析了云平台任务的资源使用特征.
图1(a)描述了Google云平台中JobId为3418309、TaskId为0的任务在连续114个小时内的最大CPU使用率的变化情况.图1(b)描述了Google云平台中JobId为3418309、TaskId为1的任务在连续114个小时内的最大CPU使用率的变化情况.从图1可以看出,在大多数情况下,这两个任务在某一个时间点的最大CPU使用率都与附近时间点该任务的最大CPU使用率比较接近,而且时间点越接近,相应的资源使用率相差越小.在少数情况下CPU使用率也会有突变,例如图1(a)中的任务在第104个小时的CPU使用率突然增大到第103个小时的5倍.因此仅仅通过前段时间的最大CPU使用率变化情况,并不能准确预测出这种在某个时间点具有较大突变性的任务的资源使用率.图1(b)中编号为1的任务的最大CPU使用率也具有较为明显的突变性,在11个时间点都发生了较大的突变.因此,在预测任务未来的资源使用率时,不仅仅需要考虑到附近的最大CPU使用率,还需要考虑到任务的历史资源使用的波动情况.
同时,从图1(a)和图1(b)可以看出,编号为0的任务的最大CPU使用率波动情况和编号为1的任务的最大CPU使用率波动情况有很大不同.编号为1的任务最大CPU使用率在连续的114个小时内的突变较为频繁,变化的幅度时大时小.而编号为0的任务的最大CPU使用率虽然只突变了1次,CPU使用率增加的幅度却很大.这2个任务的CPU资源使用特征差别比较大,如果采用同一种预测模型,会影响最后的预测效果.
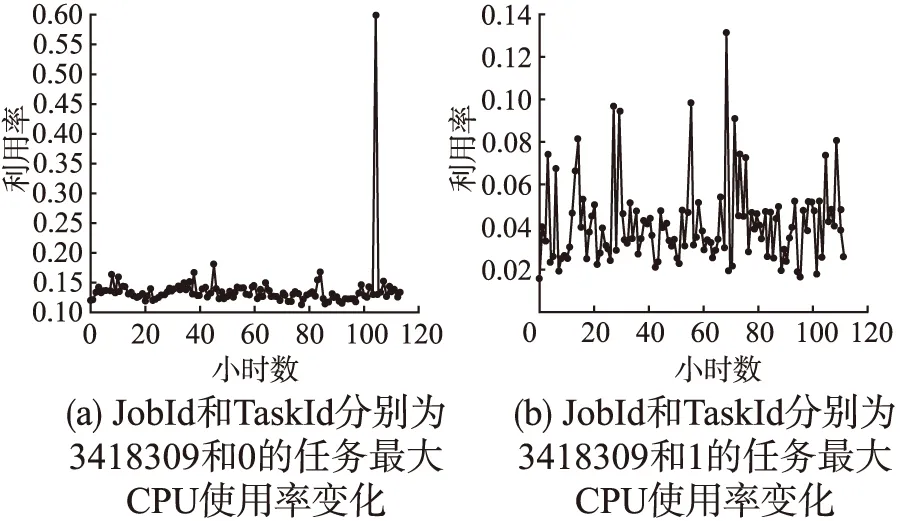
图1 Google云平台中随机抽取的2个任务的资源使用率变化Fig.1 Resource usage changes of two randomly selected tasks in Google cloud platform
图2描述了阿里云平台平均CPU使用率大于等于30%和平均使用率小于30%的在线服务的最大CPU使用率的累积分布函数(Cumulative Distribution Function,CDF)图.从该图可以得出,当平均CPU使用率超过30%时,有50%的在线服务的最大CPU使用率超过50%.当在线服务的平均CPU使用率低于30%时,有99%的在线服务的最大CPU使用率不超过40%.因此,若云平台任务的平均CPU使用率较低,则其在整个生命周期内的最大CPU使用率很大可能也比较低.
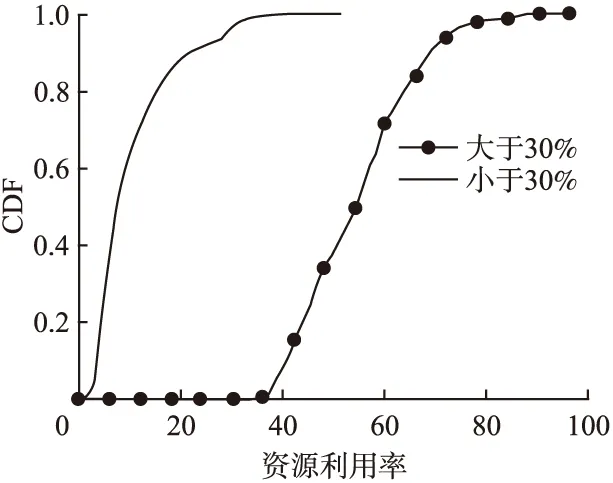
图2 阿里云平台中在线服务的最大CPU使用率和平均CPU使用率之间的关系Fig.2 Relationship of the maximum and average CPU usage of online services in Ali cloud
图3描述了Google云平台随机抽取的生产优先级和其他优先级的任务在连续24小时内的资源使用状况(将优先级为9-11的任务定义为生产优先级任务).分析该图发现生产优先级任务的CPU使用率在0.2~0.3之间波动,而其他优先级任务的CPU使用率基本低于0.1.由此可知具有不同优先级的任务可能会具有完全不同的资源使用率.
3.2 任务资源使用预测方法
用户申请的CPU资源量都是基于对任务使用的最大资源量的估计,然而任务实际使用的资源量远远低于用户申请的资源量,这也是云平台任务资源使用率低的原因之一.因此本文预测的是云平台任务未来一个小时的最大CPU/内存使用率(如果预测的时间段过短,由于任务的资源使用在较短时间内可能发生较大变化,预测的结果不能有效地帮助云平台调度器分配资源,而预测时间段过长,依旧会导致云平台资源的浪费,因此本文预测的是任务未来1个小时的资源使用率).通过3.1节对云平台任务资源使用特征的分析,本文提出任务资源使用预测方法REPO-TASK(REsource Prediction method fOr TASKs,REPO-TASK),如图4所示.

图3 Google云平台生产优先级和其他优先级任务在连续24小时内的CPU使用状况Fig.3 CPU usage of tasks with production priority and other priority on Google cloud platform during 24 hours
基于云平台多个任务的历史资源使用信息,通过分析云平台任务的资源使用情况提取初步任务资源使用特征,然后使用稀疏自编码模型进一步提取特征,接着使用K-medoids聚类方法对任务进行聚类,并对每一个任务类别使用改进的随机森林回归模型进行训练,最后,基于给定的任务在最近一段时间内的资源使用率历史信息,就可以利用训练好的模型预测出该任务在未来一段时间内的最大资源使用率.
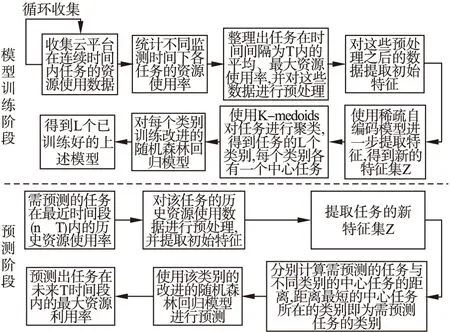
图4 任务最大资源使用率预测方法REPO-TASKFig.4 Prediction method REPO-TASK of tasks′ maximum resource usage
3.3 数据预处理及特征提取
由于云平台跟踪数据主要是定期通过RPC远程过程调用收集,当监控系统或者主机超载时,一些跟踪数据可能会丢失,本文对这些缺失的字段采取向前填充的方法.
本文在3.1节对云平台任务资源使用特征的分析表明任务的最大资源使用率不仅和靠近当前时间的任务资源使用率有关,还和其前段时间的资源使用波动情况、平均资源使用率以及任务的优先级密切相关.因此本文提取了任务的平均CPU使用率、前n个小时的加权最大CPU使用率(公式(1))、最大CPU使用率公平性指数[20](公式(2))以及任务的优先级等特征.
(1)
其中n表示选取的前n个小时的历史资源使用率,x1、x2、…、xi分别表示按时间先后次序排列的最大CPU/内存使用率.
(2)
其中n和xi所代表的含义和公式(1)相同.
表1即为从云平台任务资源使用数据提取的全部特征.为了消除这些特征值的差别,使不同特征具有可比性,本文使用最大最小标准化对不同的特征进行处理,见公式(3),其中MIN表示某个特征在所有样本中的最小值,MAX表示某个特征在所有样本中的最大值,x表示某个样本的特征值,x′表示处理后的样本特征值.
(3)
本文将在方法评估部分通过实验来分析所提取的(3n+3)个特征对于预测任务未来CPU/内存使用率的重要性.
表1 云平台任务资源提取的特征
Table 1 Features extracted from task resource
usage in cloud platform

特征编号特征内容1连续60分钟内平均处理器/内存使用率2连续60分钟内最大处理器使用率3连续60分钟内最大内存使用率4任务的优先级5前n个小时加权最大处理器/内存使用率6前n个小时最大处理器/内存使用率公平性指数
得到任务的3*(n+1)个特征后,本文采用稀疏自编码模型进一步提取特征.稀疏自编码模型包含输入层、隐含层和输出层.输入层到隐含层的映射关系可以看作是一个编码过程,通过映射函数把输出向量映射到隐含层.从隐含层到输出层的过程相当于一个解码过程,把隐含层通过映射函数“重构”输入层.对于每一个输入样本,经过自动编码器之后会转化为一个对应的输出向量.当自动编码器训练完成,输入与输出基本相同,则对应的隐含层的输出可以看作是输入的一种抽象表达,可以用于表示提取输入数据的特征.
3.4 任务资源使用率预测模型
现已提出的用于预测云平台任务的资源使用率预测模型有BP模型和LSTM模型.BP模型具有高度自学习和自适应的能力,数学理论已证明其具有实现任何复杂非线性映射的功能,然而BP神经网络算法的收敛速度慢,容易陷入局部极值.LSTM模型是RNN模型的一个优秀变种,非常适用于处理与时间序列高度相关的问题,但是训练时间过长,会导致不能及时的预测出任务的资源使用率,从而影响云平台调度器的性能.本文针对上述问题提出了改进的随机森林回归模型,改进的随机森林回归模型拥有随机森林模型[21]不容易出现过拟合、训练时间较短、预测效果好等优点,同时更加符合云平台任务的资源使用特征,具有较好的预测性能.
随机森林回归模型使用CART回归决策树作为弱分类器,本文针对云平台任务资源使用率的特征,同时保证SLA协议,对CART决策回归树算法改进为算法1.
算法1.CART回归决策树改进算法.
输入:云平台任务数据集D.
输出:改进的CART回归决策树T(x).
①遍历数据集D上的所有特征j,遍历每一个特征下所有可能的取值或者切分点s,使用切分点s把当前的数据集分为R1和R2两部分,C1和C2分别为R1和R2内所有样本目标变量的算术平均值,yi为样本xi对应的目标值.在云平台中,服务提供商需要保证SLA协议,选择最佳特征值对(j,s)分割数据集时,不仅要最小化平方误差,还要使任务的资源使用预测值不低于实际值,因此我们对最佳特征值对(j,s)的选择方法进行了改进,具体如公式(4)所示.
(4)
其中:
(5)
(6)
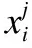
(7)
③递归对上述2个区域重复步骤①、②,直至每一个区域都不能再次划分为止.
④最后可以得到M个区域R1,R2,…,RM,每个区域的输出值分别为:c1,c2,…,cM,改进的CART回归决策树模型表示为公式(8).
(8)
4 方法评估
使用Google云平台跟踪数据集进行实验,评估本文提出的云平台任务最大资源使用率预测方法REPO-TASK的性能,同时验证本文提出的改进的随机森林回归模型的有效性,最后通过实验评估本文提取的云平台任务CPU使用特征的重要性.
4.1 实验环境和数据集
4.1.1 实验环境
实验采用4核CPU(CPU的型号为I5-4590),内存容量为8G(DDR3)的win7操作系统.实验数据集使用2012年发布的Google云平台跟踪数据集,本文只使用该数据集中的Google云平台任务资源使用数据表和任务事件表.
4.1.2 Google云平台任务数据集
鉴于监控Google云平台资源使用的系统初期不是很稳定,本文选择从第18天开始的监视数据[14].Reiss C等人[16]表明预测云平台任务的资源使用率时,调度程序可以安全地忽略运行时间短的作业,因此本文选择运行时间不少于18个小时的任务[14]进行实验.最后得到了60963个任务的资源使用率数据.
4.2 Google云平台任务资源使用预测
准确预测云平台任务的资源使用情况对于提高云平台资源使用率具有重要的作用.本节分别使用BP模型、LSTM模型[22]、随机森林模型、改进的随机森林模型和REPO-TASK方法预测Google云平台任务的最大CPU使用率.实验具体流程为:
①测试上述模型分别使用任务前多少个小时的资源使用率数据预测下一个小时的资源使用率时效果最佳.
②测试BP神经网络模型和LSTM模型的最佳学习率.
③使用步骤①得到的最佳参数在改进的随机森林模型上进行实验.
④使用REPO-TASK方法进行实验.
⑤比较所有模型的最终结果,得到最佳模型.
⑥使用最佳模型测试不同的特征组合对任务最大CPU使用率预测性能的影响.
任务资源使用率预测的性能使用MAE(公式(9))和云平台任务预测性能函数PEFOT(Performance Evaluation Function fOr Tasks,PEFOT)(公式(10))进行评估.其中,yi表示样本i的目标真实值,Yi表示样本i的目标预测值.m表示样本总数.
(9)
(10)
(11)
图5(a)和图5(b)分别描述了BP模型和LSTM模型使用任务前n个小时的资源使用率预测未来一个小时的最大CPU使用率时PEFOT和MAE值的变化情况(n取值情况同上).从这两个图可以看出,当n取6时,BP模型和LSTM模型的PEFOT值和MAE值均最小,分别为5.655,0.0066和4.8748,0.0052.
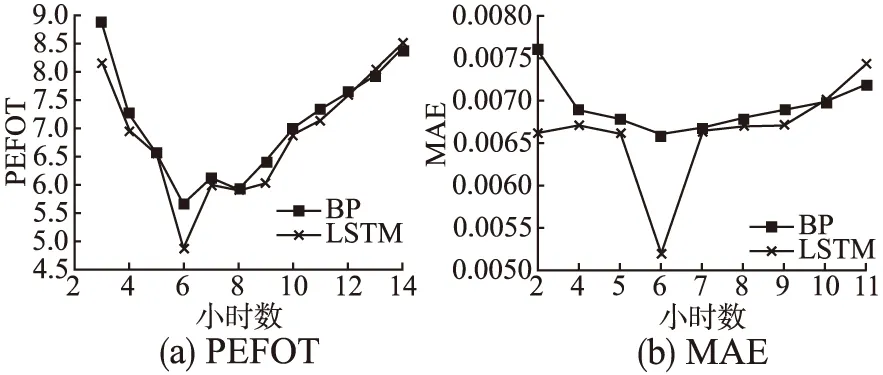
图5 模型BP和LSTM预测时不同历史时间段长度对预测结果的影响Fig.5 Effect of different historical duration on prediction results when predicting using BP and LSTM
图6(a)和图6(b)分别描述了随机森林回归模型(RF)使用任务前n个小时的资源使用率预测未来一个小时的最大CPU使用率时PEFOT和MAE值的变化情况,横坐标代表小时数.从这两个图可以看出,当n取6时,随机森林回归模型得到最小的PEFOT值和MAE值,分别为2.942和0.00078.
使用图6得到的随机森林模型的最佳历史时间段长度,然后在改进的随机森林回归模型上进行实验,得到PEFOT和MAE值分别为1.834和0.000589.

图6 模型RF预测时不同历史时间段长度对预测结果的影响Fig.6 Effect of different historical duration on prediction results when predicting using RF
最后使用本文提出的REPO-TASK方法进行实验,结果如图7、图8和表2所示.从图7可以看出将所有任务聚成4类时,实验结果最好,PEFOT和MAE值分别为1.0394和0.000492.将本文提出的方法和其它方法进行对比,实验结果如表2所示.从该表可以看出,REPO-TASK方法的预测效果最好.
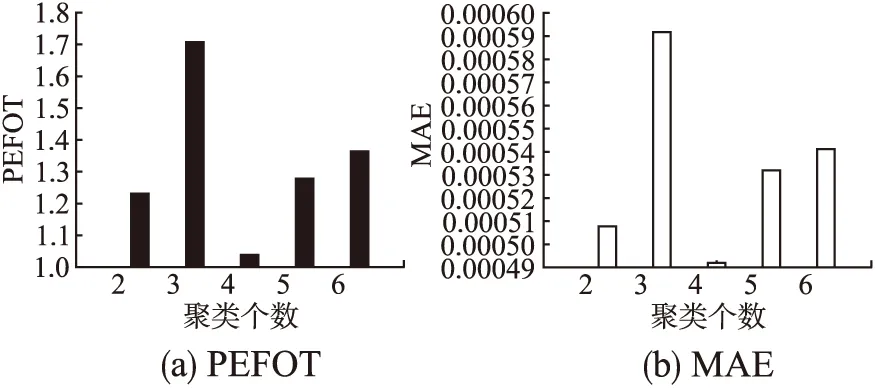
图7 REPO-TASK方法中聚类数量对预测性能的影响Fig.7 Effect of the number of classification on prediction performance when using REPO-TASK method
图8(a)和图8(b)分别描述了REPO-TASK方法使用不同的特征组合进行实验时对应的PEFOT值和MAE值.图中横坐标代表三种不同的特征组合,特征组合1表示仅仅用任务的前6个小时的平均CPU/内存使用率、最大CPU使用率和最大内存使用率作为特征;特征组合2表示在特征组合1的基础上添加了任务最大CPU/内存的加权平均值和公平性指数;特征组合3表示在特征组合2的基础上添加了任务的优先级特征.分析图8(a)和图8(b)可以得出,使用特征组合3预测任务未来一个小时最大CPU使用率效果最好.
表2 不同预测方法的PEFOT和MAE值
Table 2 Values of PEFOT and MAE when using
different prediction methods

模 型PEFOTMAEBP[14]5.6550.0066LSTM4.87480.0052随机森林回归模型[12]2.9420.00078改进的随机森林回归模型1.83440.000589REPO-TASK方法1.03940.000492

图8 REPO-TASK方法中不同特征组合对预测性能的影响Fig.8 Effect of different feature combinations on prediction performance when using REPO-TASK
5 总结和展望
在云计算蓬勃发展的今天,云平台任务的资源使用率预测逐渐成为提高云平台资源使用率的重要手段.然而云环境的不确定性、动态性和突变型使云平台的资源使用预测较为困难.
本文针对上述问题提出了云平台任务未来的资源预测方法REPO-TASK,综合了K-medoids无监督聚类算法、稀疏自编码模型和改进的随机森林回归模型.该方法的PEFOT值相对于其他已提出的模型平均降低了3.2591.根据云平台任务的资源使用特征改进了随机森林回归模型,其PEFOT值相对于随机森林回归模型平均降低了1.1076.
未来准备结合本文的工作,研究将工作负载分配给计算机和CPU的算法,为不同配置的计算机和CPU分配和重新调整工作负载,以实现更好的资源利用和可接受的资源争用.
