卷积自注意力编码过滤的强化自动摘要模型
2020-05-09徐如阳曾碧卿韩旭丽
徐如阳,曾碧卿,韩旭丽,周 武
1(华南师范大学 计算机学院,广州 510631)2(华南师范大学 软件学院,广东 佛山 528225)
1 引 言
文本摘要是应对信息过载的利器,广泛用于各项自然语言处理任务,例如新闻标题生成和多文档摘要融合[1]等.文本摘要的目标是从长文本中获得重要的信息,输出具有代表性且能保留原文主要思想的文本序列.目前文本摘要面临的主要挑战是如何评价和选择原文中关键的信息,如何过滤冗余信息,以及如何生成通顺可读的摘要.
早期的文本摘要技术主要包括手工规则[2]、以及统计机器学习技术[3]、以及语法树[4]等,这些方法存在3个缺点:1)需要花费大量的人力进行特征标注;2)通用性不足,即生成的摘要通常具有领域局限性;3)不能概括文章的核心思想.随着大数据与人工智能技术在各个领域的延伸,使用神经网络的方法已经在文本摘要任务上取得长足的进步.这些方法使用端到端模型对原文进行编码,然后将其解码为一个摘要[5].自动文本摘要方法主要有两种:抽取式(extractive)和生成式(abstractive).抽取式方法采用特定的评分规则和排序方法,从原文本中选取一定数量重要的句子组成摘要,该方法可以确保输出句子的语法正确,但是抽取的句子之间通常具有语义独立性,因此不利于读者理解整篇文章的意图.与抽取式摘要不同,生成式摘要能够获取文本的上下文信息,根据原文的核心思想重构摘要,确保生成的摘要具备语义相关、可读性强等特点,故该文采用生成式方法完成文本摘要任务.
近年来,基于注意力的序列到序列(sequence to sequence,seq2seq)框架[6]在生成式文本摘要任务上取得了显著的进展,seq2seq的解码器可根据编码器状态的注意力得分抽取信息[7].seq2seq框架最早应用于机器翻译任务上,但是自动摘要与机器翻译任务的主要区别在于原文本与目标输出之间没有位置对齐的关系,将seq2seq直接用于文本摘要会导致编码器的输出中包含噪声,影响注意力得分的计算[8],导致生成的摘要出现语义无关,语句不通顺的问题,进而会直接影响读者理解原文本内容,对读者具有误导作用.
循环神经网络(Recurrent Neural Network,RNN)由于具有良好的序列依赖关系提取能力,在文本摘要任务上得到广泛应用,与基于卷积神经网络(Convolutional Neural Network,CNN)的模型相比,基于RNN的模型在推理阶段(即测试阶段)容易出现梯度消失的情况[9].此外,RNN在训练的过程中下一个时刻编码的输出由上一时刻真实输出的词嵌入、隐藏状态及上下文向量计算得到,但是在测试阶段,模型并不确定上一时刻生成真实词汇的词嵌入,而是根据上一时刻预测的词作为输入生成下一个词,导致错误不断累积,引发曝光偏差(Exposure Bias)[10]的问题.例如表1中是当前广泛使用的基于RNN的序列到序列模型[11]生成的摘要,该模型生成的摘要不仅存在没有准确把握原文核心思想的问题,同时也存在句内重复和语句不通顺的问题,产生的摘要更是扭曲了事实,这种类型的自动摘要系统在实际场景中几乎毫无用处.
表1 传统seq2seq生成摘要案例
Table 1 Generating summarization case of traditional seq2seq

Source:UNK and the China meteorological administration Tuesday signed an agreement here on long-and short-term cooperation in pro-jects involving meteorological satellites and satellite meteorology.Reference:UNK China to cooperate in meteorology.Seq2Seq:weather forecast forecast for major China citys.
针对RNN的缺陷和seq2seq存在的曝光偏差问题,本文在seq2seq的基础上提出一种基于自注意力卷积门控单元的生成式摘要方法(Convolutional Self-Attention Gated Encoding Model,CSAG),用于更好地提取文本局部特征表示和全局特征表示.为避免部分关键信息经过门控机制时被视为非关键信息而被过滤的问题,将指针机制应用于CSAG模型,以提升模型捕获信息的能力,并解决未登录词的问题.此外引入强化学习方法[12]用于解决曝光偏差的问题.论文的贡献主要如下:
1)提出了一种自注意力卷积门控单元的编码过滤方法,使用叠加的卷积神经网络架构提取编码器输出的局部特征,构成当前时刻的句内局部特征.利用多端自注意力机制可以获取当前特征表示和其他特征表示之间的关系,使得该模型既能学习n-gram局部特征,又能从多角度、多层次学习全局的特征表示.
2)将自省序列训练用于基于自注意力卷积门控编码的自动摘要模型(Reinforced Convolutional Self-Attention Gated Encoding Model,RL-CSAG)训练之中,将以往工作中使用的最大似然交叉熵损失和策略梯度强化学习的奖励相结合,并利用不可微的摘要度量指标ROUGE对模型进行优化,从而避免模型出现曝光偏差问题.
3)在Gigaword1http://catalog.ldc.upenn.edu/ldc2012t21数据集上的多组对比实验结果表明,本文提出的模型具有较好的特征捕获能力,在ROUGE-1、ROUGE-2、ROUGE-L三个度量指标上分别提升了2.1%、1.8%和1.2%.通过多组新闻标题生成案例研究表明,模型在性能明显提升的同时,也改善了句内重复和语义无关问题.
2 相关工作
自动文本摘要在压缩原文同时保留其核心思想,研究人员为解决这项挑战性的任务提出了很多的方法,主要分为抽取式方法[13-15]和生成式方法两大类.Rush等[5]以CNN作为编码器,神经网络语言模型(Nerual Network Language Model)作为解码器,并结合注意力机制,在文本摘要任务上取得了重大突破;Chopra等[7]在Rush等[5]基础上使用RNN作为编码器并取得了更好的表现;Nallapati等[11]将解码器用RNN代替形成了完整的RNN seq2seq模型;为解决未登录词的问题,Gu等[16]和Zeng等[17]将复制机制引入seq2seq模型,该机制能够处理未登录词的问题,同时也允许使用更小规模的词汇集;Shen等[18]将句子的长度,句子之间的相似度等信息融入到句子特征向量的计算中,用于构建抽取式自动摘要;Gulcehre等[19]提出了使用软开关来控制是从原文复制还是由解码器生成一个词;Ma等[20]通过提高原文和摘要在表达上的相似性来提升彼此之间的语义相关性;Vaswani等[21]提出了一个完全依赖注意力实现的机器翻译模型,引入了自注意力机制,该机制可以学习模型中的长期依赖关系.
与RNN相比,CNN不仅可以通过并行计算提高训练效率,而且可以避免RNN梯度消失问题.最近,Gehring等[22]提出ConvS2S模型,解码器和编码器均由多个CNN构建,在语言建模和机器翻译任务表现优于基于RNN模型的最佳效果.因此CSAG模型在编码部分融合RNN和CNN,充分利用二者在特征提取任务上各自的优势,以生成高质量的摘要.
强化学习(Reinforcement Learning,RL)用于优化不可微的语言生成度量指标,能够缓解曝光偏差问题.Paulus等[12]将策略梯度强化学习应用于生成式摘要模型,可直接使用不可微的摘要评估指标ROUGE作为强化学习的回报.因此该文结合强化学习提出了RL-CSAG,用于增强模型在训练和测试阶段的一致性,并提升语言的流畅性和稳定性.
3 生成式自动摘要模型(CSAG)
生成式摘要模型CSAG是基于注意力机制的RNN seq2seq模型提出的,模型的整体结构如图1所示.CSAG模型由3个部分组成:1)双向长短期记忆网络(Long Short Term Memory,LSTM)编码器;2)基于叠加卷积神经网络的多端自注意力门控单元;3)单向LSTM解码器.模型首先使用双向LSTM编码器读取输入序列(x1,x2,…,xn)并构建编码器的状态表示.其次,为了获取每个编码步骤的核心信息,在编码器输出的顶部加入一个卷积门控单元,对所有编码器输出进行卷积操作.受Vaswani等[21]的启发,使用多端自注意力机制(self-attention)鼓励模型从多角度、多层次学习长期依赖关系,获取编码器局部-全局的特征表示;在卷积门控单元输出的顶端,使用单向LSTM作为解码器.为避免部分关键信息不能通过门控单元,导致摘要中关键信息缺失的问题,模型在解码阶段引入指针机制[19]来复制原文中子序列,以辅助解码输出,并解决未登录词的问题.
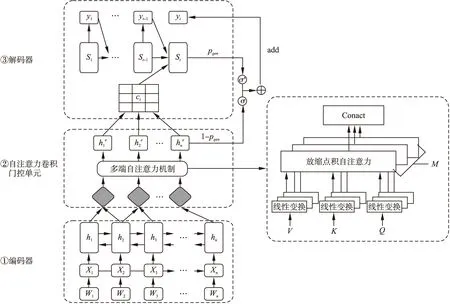
图1 卷积自注意力门控机制的生成式摘要模型Fig.1 Abstractive summarization model based on convolutional self-attention gated mechanism
3.1 句子编码器
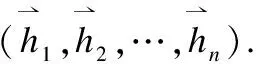
(1)
(2)
3.2 多端自注意力卷积门控单元
在基于seq2seq的机器翻译模型中,编码器用于将输入句子映射到向量序列,解码器将向量序列解码为句子[6].之前研究人员同样将seq2seq框架应用于文本摘要[5,7,11]任务中,但与机器翻译不同:1)在文本摘要中除了常见单词外,输入句子和输出摘要之间并没有对齐的关系;2)文本摘要需要保留句子的重要信息,舍弃不重要的信息,而机器翻译需要保留输入输出文本的所有信息.
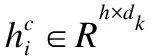
(3)
其中fconv函数表示卷积操作.
长期依赖关系可以帮助模型发现语言中包含一些内部特征,如短语结构和句内关系等.受Vaswani等[21]工作的启发,在卷积模块输出层应用自注意力(Self-Attention)机制,在不增加计算复杂度的情况下鼓励模型学习长期依赖关系,以捕获编码器输出的全局特征信息.本文采用放缩点积注意力[21](scaled dot-product attention)对卷积模块的输出Q和KT执行点积操作,为每个时刻的局部特征表示和全局信息之间建立联系.考虑到一个放缩点积注意力无法从不同角度、不同层面捕获编码状态的特征,所以模型使用多端注意力机制(Multi-head Attention)充分挖掘特征信息.图1给出了多端注意力的计算流程,首先在不共享参数的情况下对卷积模块输出Q,K,V做线性变换,然后重复M次放缩点积注意力计算,将每层的输出的结果进行拼接.
(4)
headi=Attention(QW1,KW2,VW3)
(5)
MultiAttention=head1⊕head2…⊕headM
(6)


gate=δ(Wg(MutiAttention(Q,K,V))+bg)
(7)
(8)
其中,δ表示sigmoid激活函数,Wg是一个可学习的参数,bg是一个偏置项.
经过自注意力卷积门控单元的处理,CSAG利用卷积神经网络学习到全文的n-gram的局部特征表示,利用多端自注意力机制可以从多角度和多层次学习输入文本的长期依赖关系和全局特征信息,使得模型能够正确理解输入文本的核心思想,并生成语义相关、可读性较好的摘要.通过特征融合、过滤,模型会有选择地删除和保留某些特征信息,且能有效避免由于注意力滞留造成的句内重复的问题.
3.3 句子解码器
在多端自注意力卷积门控单元后使用一个带有注意力机制的单向LSTM作为句子的解码器,以生成原文本的摘要.

st=LSTM(xt-1,ct-1,st-1)
(9)
(10)
其中,Wd是一个权重矩阵,bd是一个偏差向量.
(11)
其中,We是一个权重矩阵.
对相关性权重做归一化处理,得到第i个词的注意力权重,根据每个词的注意力权重可以得到第t个目标词的上下文向量:
(12)
(13)
指针机制[23]是一种有效处理未登录词的方法,在解码过程中,pgen作为一个软开关,控制解码器从词汇表vocab中生成一个单词或从原文拷贝单词.pgen定义为:
(14)
pvocab(wt)=p(yt|y (15) (16) Teacher forcing算法[24]用于最小化CSAG每个解码步骤的最大似然损失Lml: (17) 与摘要评估指标ROUGE相比,最小化公式(17)的目标函数通常不会产生最优的效果. 一方面是由于存在曝光偏差[10].在训练过程中,模型由真实的输出序列来预测下一个单词,而在推理过程中,模型根据上一时刻预测的单词作为输入,生成下一个单词.因此,在推理过程中,每一步的误差会不断累积,导致生成的摘要质量下降. 另一方面是由于摘要的灵活多样性.最大似然函数奖励输出和参考摘要完全相同的模型,惩罚那些输出文本与参考摘要不一致的模型,而这些输出的大多数文本在意义表达上是和参考摘要是一致的.虽然给出多个参考摘要可以缓解这种误差,但对给定参考摘要的阐述方式还有多种.最小化公式(17)目标函数恰好忽略了摘要灵活性的本质.而ROUGE提供了更灵活的评估方式,让模型更多的关注语义,而不是词级别的对应关系. (18) 最后,通过梯度下降算法更新模型的参数. 实验所用数据集为带注释的Gigaword,该数据集曾被Rush等[5]用于文本摘要任务的评估.Gigaword语料库将新闻文章的第一句话和新闻标题配对产生,即新闻第一句话作为原文本,人工书写的新闻标题作为参考摘要.利用Rush等发布的脚本(1)http://github.com/facebook/NAMAS构建训练集和验证集,该脚本执行多项文本规范化操作,包括词语切分、字母小写、将所有的数字用#代替,并将词频小于5的词用UNK标签标记.Gigaword共有3.8M万对新闻句子标题对作为训练集,189K对作为验证集.在测试阶段使用与Rush、Chopra等相同的测试集,该测试集包含2000个句子-标题对.Gigaword数据集统计信息如表2所示. 表2 Gigaword数据集统计信息 数据集属性训练验证测试数量3.8M189K2000句子的平均长度31.431.729.7摘要的平均长度8.38.38.8 自动摘要的评价采用官方ROUGE(1.5.5)作为度量指标.通过计算在参考摘要和候选摘要之间的重叠词汇单元来衡量生成摘要的质量,例如unigram,bigram,LCS(最长子序列).按照惯例,采用ROUGE-1(unigram),ROUGE-2(bigram),ROUGE-L(LCS)的F1值进行评估.其中,ROUGE-1和ROUGE-2用于衡量生成摘要的信息量,而ROUGE-L用于衡量生成摘要的可读性. 实验中使用大小为50k的词汇表,词嵌入的维度设置为256,所有的LSTM的隐藏状态维度设置为512.使用Adam优化器,学习率的初始值设置为α=0.03,动量参数设置为β1=0.9,β2=0.999,=10-8,将Dropout rate设置为0.5.解码器部分,设置集束搜索(beam search)大小为6.为了加快模型训练和收敛的速度,将mini-batch的大小设置为64.在卷积自注意力门控单元中,多端注意力的M值设置为8. ABS,ABS+:Rush等[5]首次提出ABS,该模型以CNN作为编码器,并最先将注意力机制应用于文本摘要任务.ABS+在ABS模型的基础上加入一些人工规则,ABS+取得了比ABS更好的效果. Feat2s:Nallapati等[11]使用一个完整的基于RNN的seq2seq模型,并通过加入词性,命名实体识别等规则加强编码器的特征表示. RAS-Elman:Chopra等[7]将单词和单词位置作为输入,使用卷积编码器来处理源信息,并用RNN做解码器进行基于注意力的序列解码. DRGD:Li等[26]在传统seq2seq的模型基础上,结合深度循环生成解码器学习句子内部的结构,保证生成的摘要具有较高可读性. SEASS:Zhou等[27]利用编码器正反向输出的最后一个状态构建句子特征表示,结合选择门控机制控制从编码器到解码器的信息流. PCEQ:Guo等[28]改进生成式摘要模型,提出了一种多任务学习方法.结合问题生成和句子语义生成辅助任务,进行突出信息检测和文档逻辑推理,并在此基础上加入了指针覆盖机制[23]. Pointer:在基于注意力机制的序列到序列模型的基础上加入指针机制用于解决未登录词的问题.该文将Pointer模型作为基线模型. 对比模型及本文提出模型在Gigaword数据集上的实验结果如表3所示,CSAG模型是本文提出的基于卷积自注意力门控编码模型,RL-CSAG是加入强化学习后的模型.右上角数字表示模型提出的年份.表3对比模型部分,将在ROUGE-1,ROUGE-2,ROUGE-L上表现最佳的结果加粗显示. 表3 模型对比实验结果 模型ROUGE-1ROUGE-2ROUGE-LABS201529.611.326.4ABS+201529.811.927.0Feat2s201632.715.630.6RAS-Elman201635.316.632.6DRGD201736.317.633.6SEASS201736.217.533.6PCEQ201836.017.833.6Pointer34.316.432.0CSAG36.418.233.2RL-CSAG36.818.034.1 本文实现的两组模型和7个对比模型的实验结果如表3所示,由表3可知: 1)CSAG模型在性能上优于大多数的对比模型,且在ROUGE-1上对比最佳模型DRGD高出0.1%,在ROUGE-2上对比最佳模型PECQ高出0.4%.加入强化学习之后,模型在ROUGE-1和ROUGE-L指数上得到提升,且这两个指标均高出对比模型最佳结果0.5%.证明该文提出的模型为生成高质量摘要做出了一定的贡献. 2)与基线模型Pointer相比,CSAG在3个度量指标上分别高出基线模型2.1、1.8和1.2个百分点,证明CSAG能够提取出文本中的潜在特征信息,生成更优质的摘要. 3)加入强化学习得到RL-CSAG之后,RL-CSAG模型性能在CSAG基础上有了进一步的提升,在ROUGE-1、ROUGE-L两个度量指标上,RL-CSAG分别提升了0.4%和0.9%.在ROUGE-L上的大幅提升,说明基于自省序列训练强化学习方法能够帮助模型生成更具可读性的摘要. 4)从3个评估指标来看,CSAG模型生成的摘要能够在多个维度上准确领会输入文本的核心思想,说明该文提出的卷积自注意力门控单元能模拟人类处理信息的方法.先抓住局部重点信息,在局部信息和全局信息之间建立联系,再从全局层面以多角度不同层面进行归纳,而不是对单词进行简单的拼凑,故生成的摘要具有较好的连贯性、流畅性和语义相关性. 为了对实验结果做进一步分析,该文将RL-CSAG与Pointer模型生成的摘要进行比较,表4中显示了原文本、参考摘要、模型生成的摘要.从这些案例中可以看出,RL-CSAG可以捕捉到一些与参考摘要相一致的核心信息.例如,案例1生成的摘要“australian fm says dialogue with dprk important”与参考摘要基本一致,但是Pointer只将原文中这件事的场景(“Australia's foreign minister shelve the opening of an embassy in Pyongyang”)给抽取出来,未能真正捕获文本的核心内容,且产生了扭曲的事实.案例中RL-CSAG将“foreign minister”简化成“fm”,表明RL-CSAG更好地学习了文本中的潜在信息.案例2中RL-CSAG生成的摘要和参考摘要在语义上高度吻合,而Pointer模型虽然有多个单词和参考摘要相同,可以在测试中获得较高的ROUGE评分,但是生成的摘要不仅语句不通顺,而且存在严重的语法错误.通过上述案例的对比分析,说明该文提出RL-CSAG模型具有较好的特征表示捕获能力,能够在序列数据中从多角度、不同层次提取更有效、更复杂的潜在信息.因此,RL-CSAG生成的摘要与真实摘要的内容具有较好的一致性.此外RL-CSAG生成的摘要可读性较好、内容重复度低. 表4 模型生成案例分析 案例1:continued dialogue with the democratic people 's republic of korea is important although australia’s plan to open its embassy in pyongyang has been shelved because of the crisis over the dprk’s nu-clear weapons program,australian foreign minister alexander downer said on friday.参考:dialogue with dprk important says australian foreign ministerPointer:Australia's foreign minister shelve the opening of an embas-sy in Pyongyang.RL-CSAG:australian fm says dialogue with dprk important.案例2:the #### tung blossom festival will kick off saturday with a fun-filled ceremony at the west lake resort in the northern taiwan county of miaoli,a hakka stronghold,the council of hakka affairs-lrb-cha-rrb-announced tuesday.参考:#### tung blossom festival to kick off Saturday.Pointer:tung blossom festival on Saturday at the west lake holiday.RL-CSAG:#### tung blossom festival to kick off in Miaoli. 该文在序列到序列模型的基础上结合强化学习理论提出卷积多端自注意力编码过滤模型RL-CSAG,用于生成式自动文本摘要研究.CSAG模仿人工书写摘要的行为,分阶段从不同角度概括上下文信息,生成摘要.利用自省序列训练缓解曝光偏差问题,提升模型性能.在开源英文数据集Gigaword上实验结果表明,RL-CSAG在ROUGE度量指标上取得较大提升,同时模型生成的摘要具有较高的语义相关性、可读性. 实验主要是基于短文本的摘要生成,未来工作中将尝试在长文本或多文档的数据集上评估该文提出的模型,并探索能提升强化学习稳定性的方法.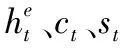
4 强化学习
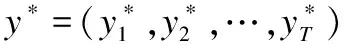
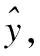
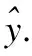
5 实 验
5.1 数据集
Table 2 Gigaword dataset statistics
5.2 评价指标
5.3 实验参数设置
5.4 对比模型
Table 3 Performance comparison of models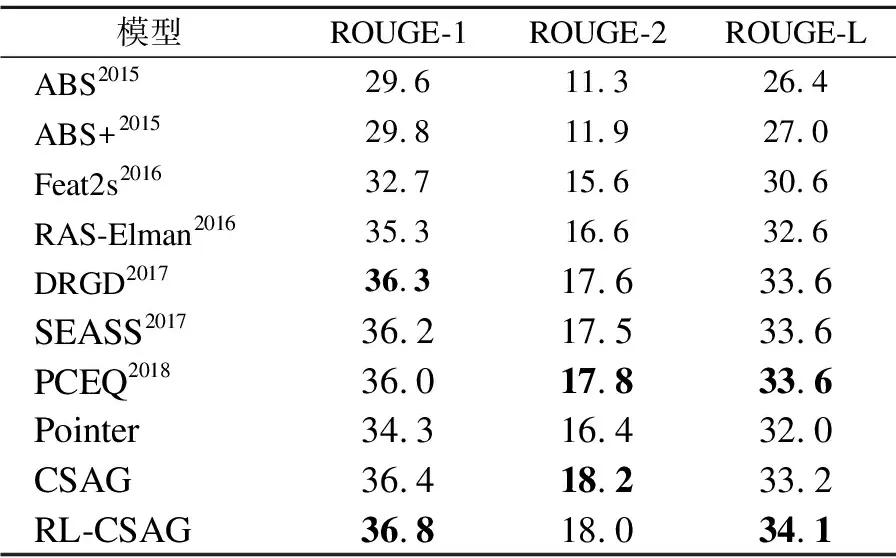
5.5 案例研究
Table 4 Case analysis of generated summarization
6 结 论
