基于机器视觉的碳纤维预浸料表面缺陷检测方法
2020-05-08路浩,陈原
路 浩, 陈 原
(山东大学 机电与信息工程学院, 山东 威海 264209)
碳纤维是含碳量高于90%的无机高分子纤维,既具有碳材料的固有本征特性,又兼具纺织纤维的柔软可加工性,是目前已大量生产的高性能纤维中具有最高比强度和最高比模量的纤维[1]。碳纤维预浸料是碳纤维行业的下游产品,经过再加工可被广泛应用于航空航天、汽车、体育器材等各个领域。据数据统计,2018—2022年全球航空航天碳纤维预浸料市场规模将保持在9.0%以上的增长速度,同时在汽车轻量化和新能源汽车的带动下,2018—2022年全球汽车用碳纤维预浸料市场将保持30%以上的增速[2]。
随着需求量的迅猛增长,市场对产品质量的要求也更加严格。在生产过程中由于需要涂膜、热压、冷却、覆膜、卷曲等多道工艺反复处理,碳纤维预浸料表面会出现裂缝、毛团和孔洞等缺陷。针对这些缺陷,目前主要采用人工检测方法,效率低,工人长期工作易疲劳,易出现漏检和误检。另外,也可采用红外热波、超声和微波等检测方法,但红外热波检测速度慢,无法满足快速生产线;超声检测在探头处需要耦合剂,会对材料造成二次污染;微波检测更适用于检测碳纤维材料内部的缺陷,对材料表面缺陷检测并不理想[3]。以上检测方法需要检测对象保持静止,检测完一个区域后,再检测另一个区域,额外地增加了检测时间,降低了生产效率。
随着机器视觉的不断发展和完善,国外许多公司针对纺织物表面存在的缺陷,设计了多种机器视觉自动检测系统。例如:美国Ingersoll Machine Tools公司开发了一套基于机器视觉的自动铺丝在线检测系统[4];以色列EVS公司开发了I-TEX 2000织物检测系统,该系统对单色织物具有良好的检测效果[5];瑞士Uster公司开发了Fabriscan自动验布系统,可在实时检测的同时对缺陷的数量类型进行统计和保存[6]。但以上检测系统都只能检测特定产品,不具有通用性,无法完全地将其应用于碳纤维预浸料的表面缺陷检测,且这些检测系统大多是基于传统的目标检测算法,在复杂光照条件下,检测速度和精度还有待进一步提高。
近年来,卷积神经网络的发展为图像的识别提供了一种新途径,基于卷积神经网络的目标检测算法迅猛发展,已在多个应用领域取得成功。2016年Redmon等[7]发表了题名为“You only look once: unified, real-time object detection”的论文(简称YOLO),开创了单阶段目标检测算法。针对YOLO算法的不足,2017年Redmon等[8]提出了YOLOv2算法,其检测速度要远大于快速区域卷积神经网络(Fast R-CNN)和最快区域卷积神经网络(Faster R-CNN)等双阶段目标算法[9],使用者可在速度和精度之间进行权衡。针对碳纤维预浸料的表面缺陷,本文采用YOLOv2目标检测算法,设计了一种基于机器视觉的碳纤维预浸料表面缺陷的自动检测系统,可自动提取缺陷特征,大大提高了视觉检测系统的精度和鲁棒性。
1 系统组成与原理
图1示出本文所开发的碳纤维预浸料表面缺陷检测系统。该系统是基于机器视觉技术和图像处理方法来实现的。该检测系统由线扫描相机、光源、碳纤维预浸料、滚筒、工控机和编码器等组成,可自动采集碳纤维预浸料的表面图像,并通过图像处理和YOLOv2目标检测算法判断碳纤维预浸料表面是否存在缺陷。
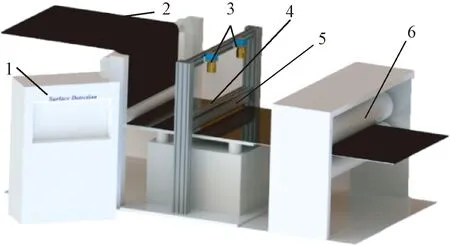
1—工控机; 2—碳纤维预浸料; 3—线扫相机; 4—编码器; 5—光源; 6—滚筒。图1 碳纤维预浸料的表面缺陷检测系统Fig.1 Surface defect detection system of carbon fiber prepreg
当碳纤维预浸料开始生产时,会带动编码器上的滚轮滚动,此时编码器会向线扫描相机输入触发信号,触发相机开始拍照。线扫描相机通过连续扫描,每隔一段距离将扫描的像素信息合成一张图像,完成图像的连续采集。停止生产时,编码器滚轮停止滚动,则相机停止采集图像。图像采集完成后,采用相应的算法对图像进行处理,并判断碳纤维预浸料表面是否存在缺陷并输出结果。
2 图像采集
获取图像数据是视觉系统检测的第1步。碳纤维预浸料在生产时不断向前运动,面阵工业相机会出现漏拍,且采集到的图像会出现模糊,无法用于后期处理,所以,本文采用线扫描相机代替面阵相机来获取图像数据。实验用碳纤维预浸料的幅宽为 1 300 mm,检测精度要求不小于0.25 mm。由于碳纤维预浸料的幅宽较大,无法通过1个线扫描相机获取整个幅宽的图像数据,所以本文研究将幅宽分为2个部分,分别使用2台线扫描相机采集图像。由检测精度推出相机的分辨率要求不小于 2 600像素(幅宽/检测精度),因此,选择加拿大Dalsa P2-22-04K40 型线扫描工业相机,该相机的分辨率为 4 096 像素,相机像元为7.04 μm,行频为18 kHz。镜头选用尼康AF35 mm,使用F型接口与相机相连,焦距为35 mm,最大光圈为f/1.4。光源采用美国Advanced illumination公司产的1 400 mm高亮条形LED光源,可为系统提供高亮度、高均匀、高稳定的光照环境。
根据线扫描相机成像原理,按照式(1)计算出相机的标准工作距离[10]:
(1)
式中:μ为相机像元,mm;N为相机分辨率,像素;f为相机焦距,mm;w为相机拍摄区域碳纤维预浸料的幅宽,mm;d为相机标准工作距离,mm。
根据上述参数确定相机的安装位置:相机安装高度为800 mm。2个相机均匀分布,每个相机负责的预浸料幅宽为650 mm,安装在负责区域的正中央,相机间距离为650 mm。光线须经过一层磨砂亚克力板散射,所以选择光源安装高度为 20~30 mm,以保证每个区域内的光照均匀。线扫描相机采集图像存在的几种主要缺陷如图2所示。

图2 碳纤维预浸料的表面缺陷Fig.2 Surface defects of carbon fiber prepreg.(a) Normal; (b) Crack; (c) Hairball; (d) Hole
3 图像处理
3.1 图像预处理
碳纤维预浸料表面缺陷检测系统安装在覆膜工序之前,冷却工序之后。在冷却过程中,由于树脂涂抹不均匀和冷却不完全,会使碳纤维预浸料表面蒙上一层白雾,严重影响缺陷目标的检测。
通过图像数据的简单灰度缩放可去除白色树脂的影响,但同时会将缺陷目标一同去除,图像无法用于后期处理。碳纤维预浸料和其表面缺陷只有黑白 2种颜色,无其他杂色,因此,本文将采集到的RGB三通道图像转化为灰度图像,简化图像的后期处理;然后,通过将白色树脂转化为白雾,基于暗通道先验图像去雾方法去除白雾;最后,通过灰度缩放对图像进行增强。
暗通道先验图像去雾方法是基于大气光散射模型所构建的,主要由入射光衰减模型和环境光成像模型组成[11]。本文将白色树脂对碳纤维预浸料的影响转化为大气中散射颗粒对相机成像的影响,通过求取光线透射率和大气光值,由式(2)求取无雾图像。
I(x)=J(x)t(x)+A(1-t(x))
(2)
式中:I(x)为采集到的有雾图像;J(x)为要获得的无雾图像;t(x)为透射率,描述光线的透雾能力;A为图像中无穷远处的大气光值。
通过去雾后获得的图像虽然没有了干扰,但缺陷目标灰度值较小,对比度较差,需通过灰度缩放进一步实现图像的增强。图像去雾增强前后的对比图如图3所示。

图3 图像预处理Fig.3 Image pre-processing.(a) Original image; (b) Dehazing image; (c) Enhanced image
3.2 图像目标识别
本文采用YOLOv2目标检测算法来识别碳纤维预浸料表面缺陷,算法基本架构如图4所示。与传统的目标检测算法相比,YOLOv2算法不需要人工设计特征提取算子,检测速度更快,应用范围更广。与双阶段目标检测算法相比,YOLOv2算法不需要生成区域候选框,将对象检测转化为回归问题,直接从输入图像确定图像中对象的类别和位置,具有更好、更强、更快的检测性能[12]。在世界级计算机视觉挑战赛PASCAL(pattern analysis, statical modeling and computational learning)专用的视觉目标分类数据集VOC(visual object classes)上,YOLOv2算法与其他目标检测算法的性能对比[8]得到:YOLOv2算法与其他算法平均精度均值接近,但图像处理速度远远超过了其他算法;且其多尺度训练模式,实现了算法速度和准确度之间的平衡。

1—图像特征提取分类; 2—图像识别(边界框预测); 3—非极大值抑制; 4—边界框回归。图4 YOLOv2目标检测算法的框架Fig.4 Algorithm framework of YOLOv2
3.2.1 图像特征提取分类
识别碳纤维预浸料表面图像中的缺陷目标,第1步需要提取图像特征。本文采用Darknet-19卷积神经网络提取图像特征,与牛津大学视觉组(visual geometry group)设计的VGG-16和Google公司设计的GoogleNet等卷积神经网络相比,该网络具有更快的训练速度,且在世界图像识别最大数据库ImageNet数据库上,该网络的top-1准确率达到72.9%,top-5准确率达到91.2%。Darknet-19网络由19个卷积层和5个最大池化层组成。该神经网络使用了较多的3×3卷积核,在每次池化操作后将通道数翻倍,同时使网络全局平均池化,将1×1卷积核置于3×3卷积核之间,用来压缩特征[13]。Darknet-19网络在每个卷积层后均加入一个批量标准化层,可稳定模型训练,加速模型收敛,正则化模型[14]。Darknet-19卷积神经网络的结构如表1所示。将224 像素×224 像素分辨率的图像输入网络后,经过卷积和池化操作获得图像目标特征,最终输出目标特征图。

表1 Darknet-19卷积神经网络的结构Tab.1 Architecture of convolutional neural network of Darknet-19
通过上述卷积神经网络提取了图像特征,然后使用特征值对表面缺陷进行分类。本文采用Softmax分类器对碳纤维预浸料表面缺陷进行分类,与其他分类器相比,Softmax分类器收敛速度快,很少出现梯度消失,且更适用于多类别对象的分类。Softmax分类器位于卷积神经网络架构的最后一层,其将多个神经元的输出映射到(0,1)区间内,且这些映射值之和等于1。这样就可将这些映射值理解为概率,最后选取输出节点时,将概率较大的节点作为输出节点,用来预测缺陷目标[15]。Softmax函数计算公式为
(3)
式中,Si为第i个元素的Softmax值,i=1,2,…,j。
3.2.2 图像标识
完成图像特征提取并分类后,下一步任务是标记出图像中的缺陷目标。标记图像常用方法有 2种:一种是通过矩形边界框将目标圈出;另一种是沿目标轮廓对其进行填充。沿目标轮廓填充会导致目标被覆盖,不符合人眼观察习惯。使用矩形边界框标记图像缺陷目标,首先应去除卷积神经网络的全连接层和最后一个池化层,以保证最后卷积层的特征有更高的分辨率。由于大的目标通常会占据图像的中心,采用具有奇数宽和高的特征图更易预测目标。
将特征图划分为13×13网格,每个网格生成 9个锚框(Anchor boxes),用于生成预测边界框。为使算法能更加自动生成Anchor boxes,采用K-means方法对训练集的预测框做聚类分析,并通过定义距离函数消除预测边界框和实际边界框的误差与边界框尺寸存在的关联。通过在VOC和微软公司标注的COCO(Miscrosoft Common Objects in Context)数据集上做聚类分析可发现,随着聚类中心数目的增加,YOLOv2预测边界框的AvgIOU值(AvgIOU为平均重叠度,即训练生成的边界框与人工标注的实际边界框之间的重叠度)不断增加,且采用5个Anchor boxes的YOLOv2算法的预测效果就可超过采用9个Anchor boxes的Faster R-CNN算法[6]。综合考虑模型的复杂度和召回率,本文选取5个Anchor boxes来预测边界框。
1张图像经过上述处理后,特征图被划分为 13×13 的网格,每个网格生成5个不同比例的Anchor boxes,每个Anchor boxes包含5个预测值(tx、ty、tw、th、t0),用于计算预测边界框的坐标、宽高和置信度,计算公式为:
(4)
式中:(bx,by)为预测边界框的坐标;bw、bh分别为预测边界框的宽和高;cx和cy为预测框中心坐标所在的网格距离左上角第1个网格的横向和纵向距离,单位为1;pw和ph为Anchor boxes的宽和高,tw和th经指数化处理后,与pw和ph相乘即得到预测边界框的宽和高;σ(t0)为预测框的置信度;σ()为sigmoid激活函数,tr和ty经sigmoid函数处理后,得到数值在0~1之间;object为缺陷目标,Pr(object)当Anchor boxes包含目标时为1,不包含目标时为0;IOU为重叠度计算。
3.2.3 非极大值抑制
为解决一个目标被多次检测的问题,本文采用非极大值抑制方法。经过以上步骤后,最可能包含目标的边界框会出现多个,每个边界框的置信度不同,如图5所示。本文所采用的非极大值抑制方法首先从所有的边界框中找出置信度最大的框;然后依次计算其与剩余框的重叠度,如果重叠度大于设定的阈值,则剔除该框;重复以上步骤,直至处理完所有的边界框[16]。

图5 非极大值抑制过程Fig.5 Process of non-maximum suppression
3.2.4 边界框回归
1张图像经过上述步骤之后,算法会生成1个边界框,如图6所示。深色边框为制作数据集时人工标注的实际边界框,白色边框为算法模型生成的边界框,2个边界框中心没有完全重合,大小也不一致。为使算法生成的边界框定位更加精准,对边界框进行平移和缩放,使2个边界框无限重合。

图6 边界框回归Fig.6 Bounding box regression
3.3 网络训练和图像检测
YOLOv2目标检测算法包含许多类型,如YOLO-VOC和Tiny-YOLO等,这些类型的检测算法具有不同的卷积层、池化层和激活函数。Tiny-YOLO对算法进行了简化,训练时占用内存小,速度更快。本文采用YOLO-VOC和Tiny-YOLO这2种算法对图像数据进行对比训练,确定最适合本文数据的算法类型[17]。
首先将预处理获取的1 000张图像分辨率调整为416 像素×416 像素,其中700张用于网络训练,300张用于图像检测;然后用图像标注软件LabelImg对图像中的缺陷进行人工标注,生成与图像相对应的XML文件;最后将图像与对应的标注文件制作为训练数据集和测试数据集[18]。
算法在具有Nvida Geforce GTX 1080 Ti E5-2680 GPU和Intel i7处理器的平台上运行,平台装有Ubuntu 16.04操作系统,GPU大小为4核 32 G,深度学习框架为Pytorch。根据实验,迭代次数设置为 10 000 即可达到理想效果,平均重叠度曲线图如图7所示。可以看出,随着训练迭代次数的增加,平均重叠度值逐步增加并趋于稳定。同时平均重叠度等于50%时的召回率(评估算法的精度)和平均重叠度等于75%时的召回率也越来越接近1。

图7 碳纤维预浸料表面缺陷的训练结果Fig.7 Training results of carbon fiber prepreg surface defect
为提高网络的鲁棒性,选择YOLOv2算法的多尺度训练模式。在网络训练时,每迭代10次,网络会随机选择不同尺寸的图像,可实现准确率和速度之间较好的平衡。2类算法在本文训练数据集上训练的结果如表2所示,Tiny-YOLO算法多尺度训练的结果如表3所示。

表2 YOLOv2模型的训练结果对比Tab.2 YOLOv2 model training results comparison
注:mAP为算法平均精度均值。

表3 Tiny-YOLO多尺度训练结果Tab.3 Tiny-YOLO multi-scale training results
由训练结果可知,2个算法的mAP值非常接近,但YOLO-VOC的训练时间远超过Tiny-YOLO,且通过对Tiny-YOLO多尺度训练,416 像素×416 像素分辨率的图像具有更好的训练效果。
为检测算法的检测能力,使用测试数据集输入训练好的Tiny-YOLO算法模型进行检测。结果显示,每幅图像的检测速度不超过0.1 s,最快达到 0.06 s/幅,检测速度远远超过了人工。缺陷检测结果如图8所示。结果共分为5组,每组分别包含裂缝、毛团和孔洞3种缺陷的检测精度。

图8 碳纤维预浸料表面缺陷的检测结果Fig.8 Detect results of carbon fiber prepreg surface defects. (a) Crack defect inspection results; (b) Hair mass defect detection results; (c) Hole defect detection results
4 结果分析
本文对碳纤维预浸料表面缺陷检测系统的检测结果进行统计可知:裂缝缺陷检出率为96%,准确率为100%;毛团缺陷检出率为95%,准确率为98%;孔洞缺陷检出率为94%,准确率为97%。通过观察分析:裂缝缺陷为长条状,极易与其他2种缺陷区分,不会出现误检现象,但对于较细的裂缝,会出现漏检;毛团缺陷由于个别较模糊,对比度较小,导致检出率没有裂缝高,且会出现较小的毛团误判为孔洞的现象;孔洞缺陷规则可分辨率高,但一般较小,导致检出率低于毛团,且会出现较大孔洞误判为毛团现象。针对以上现象,通过调整Tiny-YOLO算法的细粒度特征,在卷积神经网络中加入Passthrough layer层,将浅层特征图连接到深层特征图,提高模型对较小缺陷的检测效果,系统的最终检测效果如表4所示。可知,本文系统对3种缺陷的检出率和误检率均达到了工业应用标准。
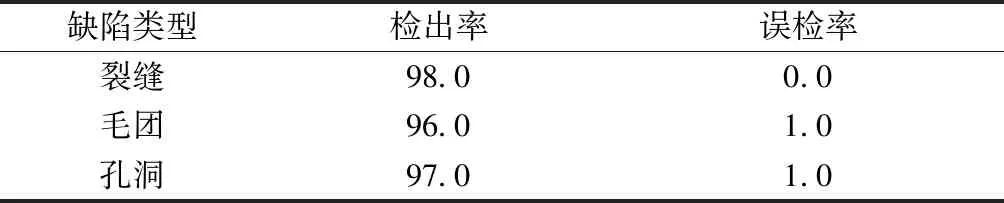
表4 系统检测效果Tab.4 System detect effect %
5 结 论
针对碳纤维预浸料表面存在的缺陷,本文采用YOLOv2目标检测算法,设计了一种基于机器视觉的碳纤维预浸料表面缺陷自动检测系统。系统采用高分辨率线扫描相机采集图像,采用暗通道先验去雾的方法对图像进行预处理,然后基于YOLOv2目标检测算法对图像进行处理,识别图像中的缺陷目标。YOLOv2与其他目标检测算法相比,不仅具有较高的检测精度,且具有较高的检测速度。实验显示,该系统可很好地完成缺陷检测任务,达到实时检测的要求。在以后的工作中将不断完善系统的功能,提高系统各方面的性能,为碳纤维预浸料表面缺陷自动检测的研究提供帮助。
